记录一次学习通接口分析
记录一次学习通接口分析
- 所需用到的工具
- 登录接口的分析
-
- 总结
- 课程页面的分析
-
- 总结
- 课程章节的内容分析
-
- 总结
- 观看视频分析
-
- 获取jobid、objectId和otherInfo的值:
- 获取duration、dtoken的值:
- 获取enc的值
- 总结
所需用到的工具
在这次的逆向分析中我所用到主要是两大工具:
- Charles抓包工具(这款工具我觉得不错值得一试)
- https://curlconverter.com/python/这个网站能够非常方便的把curl命令转换成相应的python代码,当然,它不只限于python语言
登录接口的分析
学习通的登录网站:http://passport2.chaoxing.com/login?fid=&refer=
通过抓包工具抓包分析我们可以得到如下图的数据包:
 在这图片中我可以得到如下主要信息:
在这图片中我可以得到如下主要信息:
| 参数名 | 值 |
|---|---|
| URL | http://passport2.chaoxing.com/fanyalogin |
| uname | 加密过的账号信息 |
| password | 加密过的密码信息 |
现在我主要的是如何其破解这个加密信息,我打算去查看网站所加载的js代码,其中肯定有加密的算法
我通过浏览器的开发者工具来查找:
 通过图片我发现两个非常值得注意的文件:
通过图片我发现两个非常值得注意的文件:
- crypto-js.min.js
- login.js?v=2022117
crypto-js.min.js是谷歌开发的一个纯JavaScript的加密算法类库,就是说我的账户及密码都是通过调用这个js文件来进行加密的。
login.js?v=2022117,我知道login是登录的意思,那这个文件必定有我所需要的某个函数调用crypto-js.min.js来进行加密我的账户及密码。
通过查看login.js?v=2022117的内容:
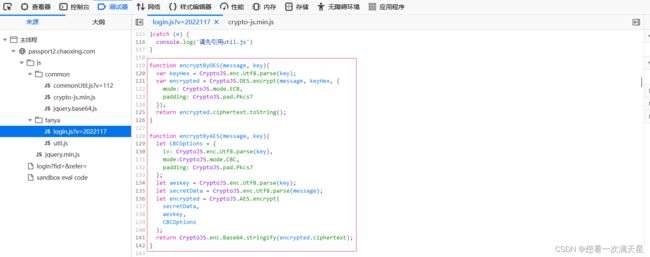 果然不出所料,我发现了调用加密的函数:
果然不出所料,我发现了调用加密的函数:
- function encryptByDES(message, key)
- function encryptByAES(message, key)
通过阅读这段代码,我发现这两个加密函数调用的是经典的加密方式AES加密及DES加密,它们都需要两个参数message和key,message肯定就是我要加密的原文,那现在我不知道key的值,继续阅读这给js文件,看能否找到调用这两个函数的地方
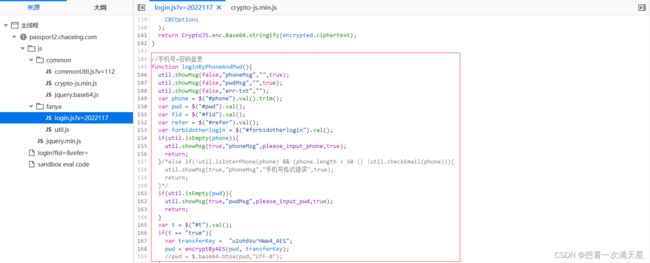 我发现写这个代码的程序员一定是一位负责任的程序员,注释都给我标好了
我发现写这个代码的程序员一定是一位负责任的程序员,注释都给我标好了
因为我是手机号+密码的方式登录,所以我只阅读这段代码,至于其他的登录方式,在这个文件中都已经注释好了,你可以很快的找到对应的代码,通过分析这段代码,我很快的找到我所需要信息,参数key就是图片中的transferKey以及调用的加密函数是encryptByAES
那么现在我只需要验证一下加密过后的密文是否和我抓包德到的密文是否一致
通过浏览器的开发者工具的控制台:
 我发现加密过后的密文和我抓包得到的密文一致,所以是正确的
我发现加密过后的密文和我抓包得到的密文一致,所以是正确的
现在只需要将这个加密函数js代码转换为python代码就可以实现登录了
在python中也有AES加密的库,我所使用的是Crypto这个库,转换为python的代码如下所示:
from Crypto.Cipher import AES
def encryptByAES(message, key):
iv = key.encode('utf-8')
aeskey = key.encode('utf-8')
secretData = message.encode('utf-8')
pad_len = 16 - len(secretData) % 16
secretData += bytes([pad_len]) * pad_len
cipher = AES.new(aeskey, AES.MODE_CBC, iv)
encrypted = cipher.encrypt(secretData)
return base64.b64encode(encrypted).decode('utf-8')
至此有关于学习通的登录接口的分析就完成了
总结
URL:http://passport2.chaoxing.com/fanyalogin
params:
| name | value | 备注 |
|---|---|---|
| fid | -1 | 固定值(登陆成功后为学校的id) |
| uname | 账户通过AES加密后的密文 | 无 |
| password | 密码通过AES加密后的密文 | 无 |
| refer | http%253A%252F%252Fi.chaoxing.com | 固定值 |
| t | true | |
| forbidotherlogin | 0 | 固定值 |
| validate | 空值 | |
| doubleFactorLogin | 0 | 固定值 |
| independentId | 0 | 固定值 |
课程页面的分析
接下来是课程页面的分析:
 通过抓包工具的所获取的数据如下图所示:
通过抓包工具的所获取的数据如下图所示:
 通过分析可以得知这个网站所返回的的响应的内容含有js代码且无法找到所需要的课程信息,说明这个网站并不是我想要的,继续分析所抓取的数据包,
通过分析可以得知这个网站所返回的的响应的内容含有js代码且无法找到所需要的课程信息,说明这个网站并不是我想要的,继续分析所抓取的数据包,
 URL:http://mooc1-1.chaoxing.com/visit/courselistdata
URL:http://mooc1-1.chaoxing.com/visit/courselistdata
这个网址就是我所需要的的网址,它所返回的响应内容有我所需要的课程信息
现在来分析这个网址所需要的
params:
| name | value | 备注 |
|---|---|---|
| courseType | 1 | 我猜测这个值代表的是分页显示,但由于我的课程不多,无法验证 |
| courseFolderId | 0 | 固定值 |
| baseEducation | 0 | 固定值 |
| superstarClass | 空值 | |
| courseFolderSize | 0 | 固定值 |
那现在需要解决的问题是如何去爬取我所需要的信息,我的思路是分析这个网页,让后通过构造xpath语句来爬取我所需要的数据


通过分析这个可以知道所有的课程信息都存放在这个ul标签下,可以通过构造xpath语句来爬取,在这里我主要爬取的信息的是li标签中的clazzid、courseid和personid的属性值,在后续的操作中有用。
在python中可以使用以下代码来爬取:
from lxml import etree
html = etree.HTML(response.text)
html.xpath("//ul[@class='course-list']/li[1]/@courseid")[0]
html.xpath("//ul[@class='course-list']/li[1]/@clazzid")[0]
html.xpath("//ul[@class='course-list']/li[1]/@personid")[0]
至此,对于课程分析的大致结束
总结
URL:http://mooc1-1.chaoxing.com/visit/courselistdata
params:
| name | value | 备注 |
|---|---|---|
| courseType | 1 | 我猜测这个值代表的是分页显示,但由于我的课程不多,无法验证 |
| courseFolderId | 0 | 固定值 |
| baseEducation | 0 | 固定值 |
| superstarClass | 空值 | |
| courseFolderSize | 0 | 固定值 |
利用python的request库去访问这个接口,再利用lxml库的etree构造xpath语句来爬取课程的courseid、clazzid及personid。
课程章节的内容分析
 通过抓包工具获取到的数据包的分析
通过抓包工具获取到的数据包的分析
 URL:https://mooc2-ans.chaoxing.com/mooc2-ans/mycourse/studentcourse
URL:https://mooc2-ans.chaoxing.com/mooc2-ans/mycourse/studentcourse
这个接口负责显示章节的信息
分析它的params参数:
| name | value | 备注 |
|---|---|---|
| courseid | 232610698 | 这个值就是在课程页面分析中所爬取的courseid |
| clazzid | 74269354 | 这个值就是在课程页面分析中所爬取的courseid |
| cpi | 271976939 | 这个值就是在课程页面分析中所爬取的personid |
| ut | s | 固定值 |
| t | 1681187573897 | 13位的时间戳 |
那现在的下一步骤,就是构造xpath语句来爬取我所需要的信息:
我们先分析一下这个接口所返回的响应内容:

 通过分析可以得知所有的章节信息都存放在class="chapter_unit"的div标签下
通过分析可以得知所有的章节信息都存放在class="chapter_unit"的div标签下
在这个页面我所需要爬取的信息只要有一个是
![]() 这个div标签的onclick属性值toOld(‘232610698’, ‘708504528’, ‘74269354’)中的第二个数值708504528(在后续的操作中有用到)
这个div标签的onclick属性值toOld(‘232610698’, ‘708504528’, ‘74269354’)中的第二个数值708504528(在后续的操作中有用到)
至于这个toOld函数,它的源代码是
 阅读这个源代码我们可以得知主要的作用是拼接网址
阅读这个源代码我们可以得知主要的作用是拼接网址
至此这个课程章节的内容分析大致结束
总结
URL:https://mooc2-ans.chaoxing.com/mooc2-ans/mycourse/studentcourse
params:
| name | value | 备注 |
|---|---|---|
| courseid | 232610698 | 这个值就是在课程页面分析中所爬取的courseid |
| clazzid | 74269354 | 这个值就是在课程页面分析中所爬取的courseid |
| cpi | 271976939 | 这个值就是在课程页面分析中所爬取的personid |
| ut | s | 固定值 |
| t | 1681187573897 | 13位的时间戳 |
通过访问这个接口就可以的到章节信息,通过构造xpath语句来获取章节下小节的knowledgeId。
观看视频分析
 通过抓包软件抓包的得到的数据分析:
通过抓包软件抓包的得到的数据分析:
 分析上面的数据包可以得知:
分析上面的数据包可以得知:
https://mooc1.chaoxing.com/multimedia/log/a/271976939/c0350665adaec83f58655b20d929af43
在这个URL中固定的部分只有https://mooc1.chaoxing.com/multimedia/log/a/
271976939这个值就是在课程分析页面中所爬取的personid的值
c0350665adaec83f58655b20d929af43这个可以从另外一个接口获取到先把这个值定义位dtoken
params参数分析:
| name | value | 备注 |
|---|---|---|
| clazzId | 74269354 | 在课程分析中所爬取得到的值 |
| playingTime | 0 | 当前视频所播放的时间单位为秒 |
| duration | 677 | 当前视频的总时间单位为秒 |
| clipTime | 0_677 | 由下划线和duration的值构造而成 |
| objectId | a645fd1f22cdb51bf83b5fa7a646c3f8 | 由另外一个接口获取 |
| otherInfo | nodeId_708504528-cpi_271976939-rt_d-ds_1-ff_1-be_0_0-vt_1-v_6-enc_ce93e570cbc05fe5c12fa6d50f3359ba | 由另外一个接口获取 |
| courseId | 232610698 | 在课程分析中所爬取得到的值 |
| jobid | 1582290717306719 | 由另外一个接口获取 |
| userid | 通过登录接口所返回的cookies中有 | |
| isdrag | 3 | 有5个值,分别代表不同的含义 |
| view | pc | 固定值,pc代表的是电脑,还有其他的值可选 |
| enc | b49885c50863bf25192b61bc594924b8 | 通过md5加密得到的密文 |
| rt | 0.9 | 固定值 |
| dtype | Video | 固定值,Video代表的是视频 |
| _t | 1681190759397 | 13位的时间戳 |
接口返回的响应内容分析:
通过响应内容的分析只要关注返回的isPassed的值就可以了,返回True表示观看该视频任务完成,False表示该视频认为没有完成
那现在只需要获取duration、objectId、otherInfo、jobid和enc的值就可以构造该参数来实现观看视频的过程
获取jobid、objectId和otherInfo的值:
通过抓包工具分析:
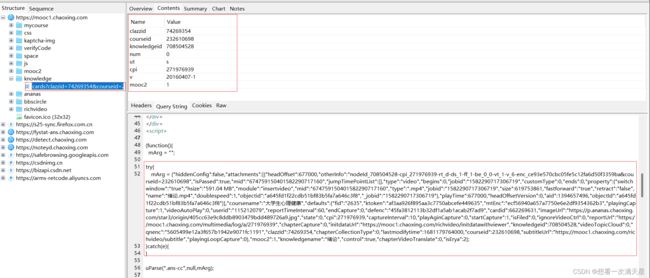 URL:https://mooc1.chaoxing.com/knowledge/cards
URL:https://mooc1.chaoxing.com/knowledge/cards
params:
| name | value | 备注 |
|---|---|---|
| clazzid | 通过课程分析所爬取的数据 | |
| courseid | 通过课程分析所爬取的数据 | |
| knowledgeid | 通过课程内容章节的分析所爬取的数据 | |
| num | 0 | 固定值 |
| ut | s | 固定值 |
| cpi | 通过课程分析所爬取的数据 | |
| v | 20160407-1 | 固定值 |
| mooc2 | 1 | 固定值 |
返回的响应内容可通过正则表达式去匹配获取的到这jobid、objectId和otherInfo的值
获取duration、dtoken的值:
通过抓包工具分析:
 URL:https://mooc1.chaoxing.com/ananas/status/+objectId
URL:https://mooc1.chaoxing.com/ananas/status/+objectId
params:
| name | value | 备注 |
|---|---|---|
| k | 学校的id,通过登录接口返会的cookies有 | |
| flag | normal | 固定值 |
| _dc | 13位时间戳 |
返回的响应内容的分析,这个接口放回的是一个标准的json格式,可以使用json库来处理这个数据来获取duration、dtoken的值
获取enc的值
要获取到enc的值,就要去分析这个值加密的算法,通过分析网址所加载的js文件,最终发现这个加密的算法在videojs-ext.min.js?v=2023-0407-2000发现了加密算法
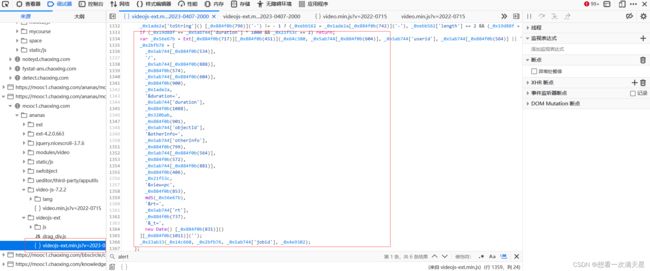 在这个js代码中可以发现这里面有需要观看视频所提交的参数,比如rt、view、otherInfo等,所以可以知道这段代码主要处理观看视频所处理的代码
在这个js代码中可以发现这里面有需要观看视频所提交的参数,比如rt、view、otherInfo等,所以可以知道这段代码主要处理观看视频所处理的代码
我们分析这段代码:
最显眼的看到md5(_0x56e67b),所以我推测可能是MD5加密,而括号里面的
_0x56e67b,查看上面的代码,可以找到它定义的地方
var _0x56e67b = Ext[_0x884f0b(717)][_0x884f0b(451)](_0x64c380, _0x5ab744[_0x884f0b(604)], _0x5ab744['userid'], _0x5ab744[_0x884f0b(564)] || '', _0x5ab744['objectId'], _0x19d88f, _0x884f0b(559), _0x5ab744[_0x884f0b(942)] * 1000, _0x320bab)
分析这个代码可以看出,它是在调用 Ext 对象的 format 方法,并且 Ext 对象的命名空间是 _0x884f0b(717)。而 Ext.format 方法通常用于将字符串模板中的占位符替换为相应的值,这个模板可以包含 {0}, {1}, {2} 等等类似的占位符。在这个代码中,_0x64c380 就是这样一个模板
var _0x64c380 = '[{0}][{1}][{2}][{3}][{4}][{5}][{6}][{7}]'
而我们现在就是要弄清楚它替换的值是那些
我们可以在md5(_0x56e67b)后面几行打上断点,然后点击视频观看

就可以查看加密的文本,然后我们随便去找一个网址去MD5加密这个文本,查看加密后的密文是否和抓包工具所抓到的数据包的enc的密文是否相同就可以判断这是不是加密的明文

 通过图片不难看出我的想法是正确的,加密的名为是:
通过图片不难看出我的想法是正确的,加密的名为是:
[74269354][115212079][1582290717306719][a645fd1f22cdb51bf83b5fa7a646c3f8][24000][d_yHJ!$pdA~5][677000][0_677]
现在我吗就需要分析这个明文是如何去构造的:
分析得到结果为:
[clazzid][userid][jobid][objectid][playingTime*1000][d_yHJ!$pdA~5][duration*1000][clipTime]
还有一个数据isdrag的值:
相关的代码为:
 我们使用同样的方法打上断点,
我们使用同样的方法打上断点,

 但我暂停视频时_0x585ebe=‘pause’;_0x1b9706=2,通过这大致可以得知isdrag
但我暂停视频时_0x585ebe=‘pause’;_0x1b9706=2,通过这大致可以得知isdrag
有五个值:分别是0,1,3,2,4
| value | 备注 |
|---|---|
| 0 | 还没遇到过,所以不知道代表什么 |
| 1 | drag(出现这个是我拖动进度条时出现的) |
| 2 | pause(暂停) |
| 3 | play(播放) |
| 4 | ended(结束) |
至此,关于视频的分析就大致结束了
总结
URL:https://mooc1.chaoxing.com/multimedia/log/a/+personid+/+dtoken
params:
| name | value | 备注 |
|---|---|---|
| clazzId | 74269354 | 在课程分析中所爬取得到的值 |
| playingTime | 0 | 当前视频所播放的时间单位为秒 |
| duration | 677 | 当前视频的总时间单位为秒 |
| clipTime | 0_677 | 由下划线和duration的值构造而成 |
| objectId | a645fd1f22cdb51bf83b5fa7a646c3f8 | 由另外一个接口获取 |
| otherInfo | nodeId_708504528-cpi_271976939-rt_d-ds_1-ff_1-be_0_0-vt_1-v_6-enc_ce93e570cbc05fe5c12fa6d50f3359ba | 由另外一个接口获取 |
| courseId | 232610698 | 在课程分析中所爬取得到的值 |
| jobid | 1582290717306719 | 由另外一个接口获取 |
| userid | 通过登录接口所返回的cookies中有 | |
| isdrag | 3 | 有5个值,分别代表不同的含义 |
| view | pc | 固定值,pc代表的是电脑,还有其他的值可选 |
| enc | b49885c50863bf25192b61bc594924b8 | 通过md5加密得到的密文 |
| rt | 0.9 | 固定值 |
| dtype | Video | 固定值,Video代表的是视频 |
| _t | 1681190759397 | 13位的时间戳 |
可以构造这params来模拟观看视频的过程,通过返回的响应的内容的isPassed的值来判断该视频任务是否完成。