k8s的pod基础
pod概念
pod是k8s中最小的资源管理组件。
pod也是最小化运行容器化的应用的资源管理对象。
pod是一个抽象的概念,可以理解为一个或者多个容器化应用的集合。
在一个pod当中运行一个容器是最常用的方式。在一个pod当中同时运行多个容器,在一个pod当中可以同时封装几个需要耦合的互相协作的容器。这些多个容器共享资源,也可以互相协作组成一个service单位。不论运行一个容器还是多个容器,k8s管理的都是pod而不是容器。
作用
1.一个pod内的容器,必须都运行在同一节点。基于现代容器技术的要求,一个pod运行一个容器,一个容器只运行一个进程。横向扩展,方便扩缩容
2.解耦,一个pod内运行多个容器,耦合度太高,一旦一个进程失败,整个pod将全部失败。实现解耦,基于pod可以创建多个副本实现高可用和负载均衡。
3.管理方便,简单直观。
pod内的容器共享资源。共享机制:
pause作为底层基础容器来提供共享资源的机制。
pause是基础容器,也可以称为父容器。管理pod内容器的共享操作。
pause还可以管理容器的生命周期。
pause容器作用
1、为pod内的所有容器提供一个命名空间
2、启动容器的pid命名空间,每个pod中都作为pid为1的进程(init进程),回收僵尸进程。
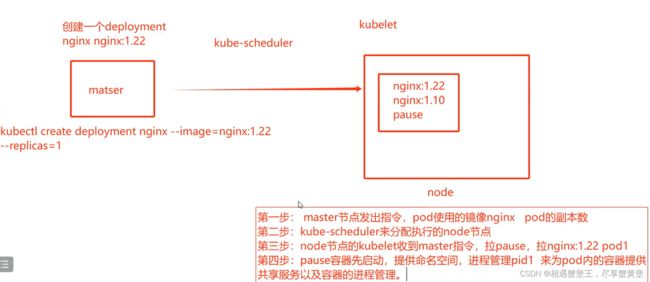
3、创建pod时,先创建pause容器,然后拉取镜像,生成容器,形成pod。
pause容器共享两种资源
网络:
每个pod都会被分配一个集群内部的唯一ip地址。pod内的容器共享网络,pod在集群内部的ip地址和端口。pod内部的容器可以使用localhost互相通信。pod的中容器与外部通信时,从共享的资源当中进行分配。宿主机的端口映射。
存储:
pod可以指定多个共享的volume,pod内的容器共享这些volume。
volume可以是实现数据的持久化。
防止pod重新构建之后文件消失。
pause总结:
每个pod都有一个基础容器pause容器。
pause容器对应的镜像属于k8s集群的一部分。创建集群就会有pause这个基础镜像。
pod里面包含了一个或者多个相关的容器(应用)
pod外再设置一个基础镜像的原因:
1、在一组容器作为一个单元的情况下,难以对整体的容器简单地进行判断及有效地进行行动。比如,一个容器死亡了,此时是算整体挂了么?那么引入与业务无关的Pause容器作为Pod的基础容器,以它的状态代表着整个容器组的状态,这样就可以解决该问题。
2、pod内的容器共享IP共享volume,解决了容器内网络通信的问题,解决了容器内部文件共享的问题。
pod的分类:
自主式pod:pod不会自我修复,pod内容器的进程终止,被删除,缺少资源被驱逐,这个pod没有办法自愈。deployment daemanset。
控制器管理pod:滚动升级,可以自愈(自动重启),可以管理pod的数量以及pod的扩缩容。
pod的生命周期:
1、pending 挂起
pod已被创建,但是尚未被分配到运行的node节点。(节点上资源不够,需要等待其他pod的调度)
2、running:运行中,pod已经被分配到了node节点,pod内部的所有容器都已经启动,运行状态正常,稳定。
3、complete:容器内部的进程运行完毕,正常退出。没有发生错误。
successded:
4、faild:pod中的容器非正常退出。发生了错误,需要通过查看详情和日志来定位问题。
5、UNkown:由于某些原因,k8s集群无法获取pod的状态。APlserver出了问题
6、terminating:终止中,pod正在被删除,里面的容器正在终止。终止过程中,资源回收,垃圾清理,以及终止过程中需要执行的命令。
创建pod的容器分类:
1.基础容器:pause
2.init容器(初始化容器):init c1和2这个过程中。pod的状态init:3/3
3、业务容器
init容器的作用:
1.环境变量可以在创建的过程中为业务容器定制好相关的代码和工具。
2.init容器独立与业务容器,他是单独构建的一个镜像,对业务容器不产生任何安全影响。
3.init容器能以不同于pod内应用容器的文件系统视图运行。secrets的权限。 应用容器无法访问secerts的权限。
总结:init容器提供了应用容器运行之前的先决条件,提供了一种阻塞或者延迟机制来控制应用容器的启动。只有前置条件满足,才会创建pod的应用容器。
1、在pod的启动过程中,容器时按照初始化容器先启动,每个容器必须在下一个容器启动之前,要成功退出。
2、如果运行失败,会按照容器的重启策略进行指定动作,restartPolicy Always never onFailure(非正常退出才会重启)
3、所有的init容器没有成功之前,pod是不会进入ready状态的。init容器与service无法。不能对外提供访问。
4、如果重启pod,所有的init容器一定会重新执行。
5、如果修改init容器的spec(参数),只限制于image,其他的修改字段都不生效(基于deployment)。
6、每个容器的名称都要唯一,不能重复。
生命周期总结
pause容器:底层容器/基础容器
提供pod内容器的网络和存储共享,以及pod内容器退出之后资源回收。
init容器:人为设定的,业务容器启动之间的必要条件。
pod的生命周期:
1、pasue基础容器
2、init容器----全部成功退出-------业务容器
3、poststart prestop 容器的钩子
启动时命令和退出时的命令
4、探针:探测容器的健康状态。伴随pod的整个生命周期(除了启动探针)。
总结:pod就是用来封装容器的,业务是容器。服务也是容器。端口也是容器。
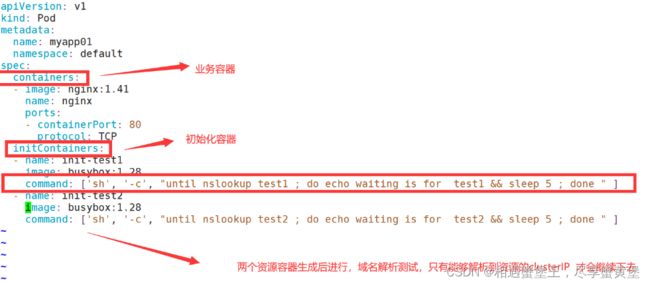
编写业务容器加初始化容器的demo:
vim nginx_init.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp01
namespace: default
spec:
containers:
- image: nginx:1.41
name: nginx
ports:
- containerPort: 80
protocol: TCP
initContainers:
- name: init-test1
image: busybox:1.28
command: ['sh', '-c', "until nslookup test1 ; do echo waiting is for test1 && sleep 5 ; done " ]
- name: init-test2
image: busybox:1.28
command: ['sh', '-c', "until nslookup test2 ; do echo waiting is for test2 && sleep 5 ; done " ]
kubectl apply -f nginx_init.yaml
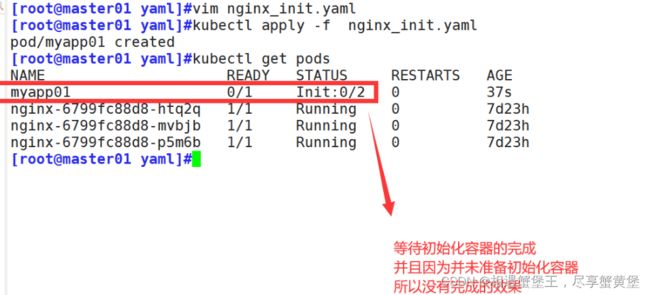

重启策略

Always:只要容器退出,总是重启,无论容器的状态码是否正常。默认策略,可以不加
Never:只要容器退出,不论是否正常,都不重启
OnFailure:只要容器的转态码非0才会重启,正常退出不重启。
只要有一个容器退出,整个pod都会重启,所有容器都会重启
docker的重启策略
never:默认策略,在容器退出时不重启容器。
on-failure:在容器非正常退出时(退出状态非0),才会重启容器。此外on-failure还可以指定重启次数(on-failure:3,在容器非正常退出时重启容器,最多重启3次。)
always:在容器退出时总是重启容器。
unless-stopped: 在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器。
pod的状态说明
1.crashloopbackoff:pod当中的容器退出,kubelet正在重启
2.imagepullbackoff:正在重试拉取镜像
3.errimagepull:拉取镜像出错了(1、网速太慢,2、镜像名字写错了,3、镜像仓库挂了)
4.Evicte:POD被驱赶(node节点的资源不够部署pod,或者是资源不足,kubelet自动选择一个pod驱逐。)
CrashLoopBackOff: 容器退出,kubelet正在将它重启
InvalidImageName: 无法解析镜像名称
ImageInspectError: 无法校验镜像
ErrImageNeverPull: 策略禁止拉取镜像
ImagePullBackOff: 正在重试拉取
RegistryUnavailable: 连接不到镜像中心
ErrImagePull: 通用的拉取镜像出错
CreateContainerConfigError: 不能创建kubelet使用的容器配置
CreateContainerError: 创建容器失败
m.internalLifecycle.PreStartContainer 执行hook报错
RunContainerError: 启动容器失败
PostStartHookError: 执行hook报错
ContainersNotInitialized: 容器没有初始化完毕
ContainersNotReady: 容器没有准备完毕
ContainerCreating: 容器创建中
PodInitializing:pod 初始化中
DockerDaemonNotReady: docker还没有完全启动
NetworkPluginNotReady: 网络插件还没有完全启动
Evicte: pod被驱赶
Pod 容器资源限制
kubectl explain deployment.spec.template.spec.containers.resources
kubectl explain statefulset.spec.template.spec.containers.resources

(1)cpu限制的参数了解
pod对于cpu限制的参数有两种表达形式:
第一种是指定个数的表达形式,例如:1 ,2, 0.5 ,0.2 ,0.3 指定cpu的个数(该个数可以为整数,也可以为小数点后一位的小数)
第二种是以毫核为单位的表达形式:100m 500m 1000m 2000m (这里1000m等价于一个cpu,该方式来自于cpu时间分片原理得来)
cpu时间分片:通过周期性的轮流分配cpu时间给各个进程。多个进程可以在cpu上交替执行。在k8s中就是表示占用的cpu的比率。
(2)memory的表达形式
pod对内存参数的要求十分严谨。对硬件有过研究的朋友,应该会了解到,我们常常提到的GB,MB,TB其实是于实际字节总数是有误差的(原因是GB是以10为底数计量,而真正的换算是以2为底数计量。导致了总量的误差。)而真正没有此误差的单位是Ki Mi Gi Ti
所以k8s中pod资源限制为了对pod的内存限制更为精准,采用的单位是 Ki Mi Gi Ti
实例运用
需求:创建一个deployment资源,镜像使用nginx:latest,创建3个pod副本,镜像拉取策略使用IfNotPresent,重启策略使用Always,容器资源预留cpu 0.25个,内存128MiB,上限最多1个cpu,1g内存
kubectl create deployement nginx-test --images=nginx:latest --dry-run=client -o yaml >test.yaml
vim test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx-test
name: nginx-test
spec:
replicas: 3
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- image: nginx:latest
name: nginx
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "1"
imagePullPolicy: IfNotPresent
restartPolicy: Always
kubectl apply -f test.yaml
#查看pod的资源使用镜像拉取的策略 情况
kubectl describe pod nginx-test
#查看node节点pod资源使用详情
kubectl describe node node02
镜像拉取的策略
首先在资源式声明中存在着imagePullPolicy的字段,它的value决定着k8s创建容器时拉取镜像的方式策略。【此字段所在位置也说明了在声明式yaml中,imagePullPolicy是包含containers中】
kubectl explain pod.spec.containers.imagePullPolicy
IfNotPresent
只有当镜像在本地不存在时才会拉取。(先对本地进行排查,本地有该镜像直接使用,本地没有该镜像则选择在仓库中拉取)
Always
总是从仓库拉取镜像,无论本地是否存在镜像(即使本地中存在我们所指定的相关镜像,该策略也会先从仓库中拉取进行应用)
Never
Kubelet 不会尝试获取镜像。如果镜像已经以某种方式存在本地, kubelet 会尝试启动容器;否则,会启动失败。(如果本地不存在,并不会在仓库中拉取,直接报错)
注意:如果没有显式设定的话, Pod 中所有容器的默认镜像拉取策略是IfNotPresent。但是也存在着默认策略选择Always的情况。
如果你省略了 imagePullPolicy 字段,并且容器镜像的标签是 :latest, imagePullPolicy 会自动设置为 Always。
如果你省略了 imagePullPolicy 字段,并且没有指定容器镜像的标签, imagePullPolicy 会自动设置为 Always。
如果你省略了 imagePullPolicy 字段,并且为容器镜像指定了非 :latest 的标签, imagePullPolicy 就会自动设置为 IfNotPresent。
Pod 容器的探针
存活探针(livenessProbe)探测容器是否运行正常。如果探测失败则kubelet杀掉容器(不是Pod),容器会根据重启策略决定是否重启
就绪探针(readinessProbe)探测Pod是否能够进入READY状态,并做好接收请求的准备。如果探测失败Pod则会进入NOTREADY状态(READY为0/1)并且从所关联的service资源的端点(endpoints)中踢出,service将不会再把访问请求转发给这个Pod
启动探针(startupProbe)探测容器内的应用是否启动成功,在启动探针探测成功之前,其它类型的探针都会暂时处于禁用状态
注意:启动探针只是在容器启动后按照配置满足一次后就不再进行后续的探测了。存活探针和就绪探针会一直探测到Pod生命周期结束为止
kubectl explain pod.spec.containers
探针的探测方式
exec : 通过command字段设置在容器内执行的Linux命令来进行探测,如果命令返回码为0,则认为探测成功,返回码非0则探测失败
httpGet : 通过向容器的指定端口和uri路径发起HTTP GET请求,如果HTTP返回状态码为 >=200且<400的(2XX,3XX),则认为探测成功,返回状态码为4XX,5XX则探测失败
tcpSocket1 : 通过向容器的指定端口发送tcp三次握手连接,如果端口正确且tcp连接成功,则认为探测成功,tcp连接失败则探测失败
探针探测结果有以下值:
Success:表示通过检测。
Failure:表示未通过检测。
Unknown:表示检测没有正常进行。
探针字段
探针(Probe)有许多可选字段,可以用来更加精确的控制Liveness和Readiness两种探针的行为(Probe):
initialDelaySeconds:容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0s,最小值是 0s;
periodSeconds:执行探测的时间间隔(单位是秒),默认为 10s,最小值是 1s,
timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为 1s,最小值是 1s,
successThreshold:探针检测失败后认为成功的最小连接成功次数,默认为 1,在 Liveness和startup探针中必须为 1,最小值为 1。
failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,默认为 3,最小值为 1
探针实验测试
(1)存活探针使用
通过exec方式做健康探测
apiVersion: v1
kind: Pod
metadata:
name: demo-live
labels:
app: demo-live
spec:
containers:
- name: demo-live
image: centos:7
args: #创建测试探针探测的文件
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
initialDelaySeconds: 10 #延迟检测时间
periodSeconds: 5 #检测时间间隔
exec: #使用命令检查
command: #指令,类似于运行命令sh
- cat #sh 后的第一个内容,直到需要输入空格,变成下一行
- /tmp/healthy #由于不能输入空格,需要另外声明,结果为sh cat"空格"/tmp/healthy
容器在初始化后,执行(/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600")首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用 cat 命令输出 healthy 文件的内容,如果能成功执行这条命令一次(默认successThreshold:1),存活探针就认为探测成功,由于没有配置(failureThreshold、timeoutSeconds),所以执行(cat /tmp/healthy)并只等待1s,如果1s内执行后返回失败,探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
通过HTTP方式做健康探测
apiVersion: v1
kind: Pod
metadata:
name: liveness-http
labels:
test: liveness
spec:
containers:
- name: liveness
image: mydlqclub/springboot-helloworld:0.0.1
livenessProbe:
failureThreshold: 5 #检测失败5次表示未就绪
initialDelaySeconds: 20 #延迟加载时间
periodSeconds: 10 #重试时间间隔
timeoutSeconds: 5 #超时时间设置
successThreshold: 2 #检查成功为2次表示就绪
httpGet:
scheme: HTTP # 用于连接host的协议,默认为HTTP。
port: 8081 #容器上要访问端口号或名称。
path: /actuator/health #http服务器上的访问URI。
此外:
host:要连接的主机名,默认为Pod IP,可以在http request head中设置host头部。
httpHeaders:自定义HTTP请求headers,HTTP允许重复headers
Pod 中启动的容器是一个 SpringBoot 应用,其中引用了 Actuator 组件,提供了 /actuator/health 健康检查地址,在pod启动后,初始化等待20s后,livenessProbe开始工作,去请求HTTP://podIP:8081/actuator/health 接口,类似于curl -I HTTP://podIP:8081/actuator/health接口,考虑到请求会有延迟(curl -I后一直出现假死状态),所以给这次请求操作一直持续5s,如果5s内访问返回数值在>=200且<=400代表第一次检测success,如果是其他的数值,或者5s后还是假死状态,执行类似(ctrl+c)中断,并反回failure失败。等待10s后,再一次的去请求HTTP://podIP:8081/actuator/health接口。如果有连续的2次都是success,代表无问题。如果期间有连续的5次都是failure,代表有问题,直接重启pod,此操作会伴随pod的整个生命周期
通过TCP方式做健康探测
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp
labels:
app: liveness
spec:
containers:
- name: liveness
image: nginx
livenessProbe:
initialDelaySeconds: 15
periodSeconds: 20
tcpSocket:
port: 80
TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个 livenessProbe 探针,尝试连接容器的 80 端口,类似于telnet 80端口,如果连接失败则将杀死 Pod 重启容器。
(2)就绪探针使用
livenessProbe+readinessProbe通过httpGet探测方法的实验过程:
本次过程我将nginx的网页目录中index.html修改为test.html。并写下了下面的资源yaml进行测试
apiVersion: v1
kind: Pod
metadata:
name: myapp-test4
spec:
containers:
- image: nginx:1.14
imagePullPolicy: IfNotPresent
name: myapp-test4
ports:
- containerPort: 80
name: http
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 5
periodSeconds: 4
failureThreshold: 2
readinessProbe:
httpGet:
port: 80
path: /test.html
initialDelaySeconds: 1
periodSeconds: 3
failureThreshold: 3
timeoutSeconds: 10
restartPolicy: Always
该过程:
(1)首先是就绪探针在容器重启1s后进行httpGet方式探测,寻找到了 test.html网页验证成功。将该Pod 标记为就绪状态,kubelet 将继续每隔 10 秒运行一次探测。
(2)除此之外我还设置了存活探针,存活探针在容器启动的5s后,进行httpGet探测,因为默认网页被修改的缘故,找不到index.html,随后继续了两次4s间隔的探测,依旧没有发现uri目标网页。根据重启策略重启容器(该过程实际上就是删除原有pod,根据镜像拉取新的pod)。
(3)由于容器被重启,所以一切恢复默认初始化,此时默认的网页目录只存在Index.html,不在存在test.html。所以本次中就绪探针的httpGet进行uri的探测失败,此后期间会做出3次间隔3s的重复探测,最终均为失败。该pod则会进入NOTREADY状态,并且从所关联的service资源的端点(endpoints)中踢出,该pod将彻底称为notready状态,后面的就绪探针也就不在进行探测。
(3)启动探针的使用
启动探针存在的必要:
有时候,会有一些现有的应用在启动时需要较长的初始化时间。 要这种情况下,若要不影响对死锁作出快速响应的探测,设置存活探测参数是要技巧的。 技巧就是使用相同的命令来设置启动探测,针对 HTTP 或 TCP 检测,可以通过将 failureThreshold * periodSeconds 参数设置为足够长的时间来应对糟糕情况下的启动时间。(因为启动探针在启动后,其他的两种探针就会进入短暂的禁用装态,于是给容器启动预留了充足的时间,保证容器中业务启动的顺利进行。而且启动探针只会启动一次,后续工作就完全交给其他两个探针,直到容器的生命周期结束)。
ports:
- name: liveness-port
containerPort: 8080
hostPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
在这里了启动探测,应用程序将会有最多 5 分钟(30 * 10 = 300s)的时间来完成其启动过程。 一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁作出快速响应。 如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy 来执行进一步处置。

Pod 容器的启动和退出动作
postStart 配置 exec.command 字段设置 Linux 命令,实现当应用容器启动时,会执行的额外操作
preStop 配置 exec.command 字段设置 Linux 命令,实现当应用容器退出时,会执行的最后一个操作
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: soscscs/myapp:v1
lifecycle: #此为关键字段
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler >> /var/log/nginx/message"]
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from the prestop handler >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
initContainers:
- name: init-myservice
image: soscscs/myapp:v1
command: ["/bin/sh", "-c", "echo 'Hello initContainers' >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
volumes:
- name: message-log
hostPath:
path: /data/volumes/nginx/log/
type: DirectoryOrCreate
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
声明容器内部的挂载目录
要给这个挂载卷取名字,不同的挂载卷的名字不能重复
readonly:false:可读写
volumes:
- name: message-log
hostPath:
path: /data/volumes/nginx/log/
type: DirectoryOrCreate
声明的是node节点上和容器内的/opt的挂载目录
挂载卷的名称和要挂载的容器内挂载卷名称要一一对应
hostPath:指定和容器的挂载目录
type:Directoryorcreate:如果节点上的目录不存在,自动创建该目录。
#pod会经常被重启,销毁,一旦容器和node节点做了挂载卷,数据不会丢失。
启动和退出的作用:
1、启动可以自定义配置容器的内的环境变量
2、通知机制,告诉用户容器启动完毕
3、退出时,可以执行自定义命令,删除或者生成一些必要的程序,自定义销毁方式以及自动义资源回收的方式以及容器的退出等待时间。