基于互补激光雷达和雷达信号的雾天多模态车辆鲁棒检测
论文地址:Robust Multimodal Vehicle Detection in Foggy Weather Using Complementary Lidar and Radar Signals
论文代码:https://github.com/qiank10/MVDNet
论文摘要
使用激光雷达和摄像头等视觉传感器进行车辆检测是实现自动驾驶的关键功能之一。虽然它们在良好的天气条件下生成具有丰富信息的细粒度点云或高分辨率图像,但它们在恶劣天气(例如雾)中会失败,因为不透明颗粒会扭曲光线并显着降低能见度。因此,依赖激光雷达或摄像头的现有方法在罕见但关键的恶劣天气条件下会出现显着的性能下降。为了解决这个问题,论文采用互补雷达,这种雷达受恶劣天气的影响较小,并且在车辆上普遍使用。
在论文中,提出了多模态车辆检测网络(MVDNet),这是一种两级深度融合检测器,它首先从两个传感器生成 proposal ,然后融合多模态传感器流之间的区域特征以改善最终检测结果。
论文背景
如今,自动驾驶车辆配备了多种传感器模式,例如摄像头、激光雷达和雷达。融合多模态传感器可以克服任何单个传感器的偶尔故障,并且可能比仅使用单个传感器产生更准确的物体检测。现有的物体检测器主要融合了激光雷达和摄像头,它们通常提供丰富且冗余的视觉信息。然而,这些视觉传感器对天气条件很敏感,在雾等恶劣天气下无法充分工作,使得自主感知系统不可靠。

图 a 显示了带有标记的真实车辆的驾驶场景示例。图 b 显示了仅使用因雾而恶化的激光雷达点云检测到的车辆。由于雾的遮挡,顶部最远的两辆车失踪了。
除了激光雷达和摄像头之外,雷达已广泛部署在自动驾驶汽车上,并且具有克服雾天的潜力。具体来说,雷达使用毫米波信号,其波长远大于形成雾、雨和雪的微小颗粒,因此很容易穿透或衍射它们周围。
然而,现有自动驾驶数据集中的雷达仍未得到充分研究,主要是由于与摄像头和激光雷达相比,其数据稀疏。
例如,nuScenes 数据集大约有 35K 个激光雷达点,但每个数据帧中平均只有 200 个雷达点。主要原因是其雷达采用传统的电子可控天线阵列,往往会产生宽波束宽度(3.2°-12.3°)的波束方向图。在 DENSE 数据集中,专有雷达安装在车辆的前保险杠上,然而,其视场角仅为35°。幸运的是,最近的牛津雷达机器人汽车(ORR)部署了带有旋转喇叭天线的雷达,该天线具有高方向性和更精细的空间分辨率(0.9°),并通过机械旋转实现360°视场。

ORR 雷达生成密集的强度图,如图 c 所示,其中每个像素代表反射信号强度。它为雾天条件下的物体检测创造了新的机会。
尽管信息更丰富,ORR 雷达仍然比其视觉对应物(即激光雷达)更粗糙且噪声更大,如图 a 和 c 所示。因此,如果以与激光雷达点云相同的方式处理它,就会出现误报和较大的回归误差。为了在雾天可靠地检测车辆,应该利用激光雷达(可见范围内的细粒度)和雷达(不受雾天影响)的优点,同时克服它们的缺点。
为此,论文提出了 MVDNet,一种用于恶劣雾天条件下车辆检测的多模态深度融合模型。
MVDNet 由两个阶段组成。第一阶段分别从激光雷达和雷达生成proposal。第二阶段通过注意力对两个传感器的特征进行自适应融合,并使用 3D 卷积进行时间融合。这种后期融合方案允许模型生成足够的建议,同时将融合集中在感兴趣区域 (ROI) 内。
如图d所示,MVDNet 不仅可以检测激光雷达点云中被雾遮挡的车辆,还可以拒绝噪声雷达强度图中的误报。

为了验证 MVDNet,我们根据 ORR 的原始激光雷达和雷达信号创建了一个程序生成的训练数据集。具体来说,我们在激光雷达点云中手动生成车辆的定向边界框,利用视觉里程计知识同步雷达和激光雷达,并使用 DEF 中提出的精确雾模型模拟随机雾效果。我们将 MVDNet 与最先进的单独激光雷达探测器或激光雷达和雷达融合 [3] 进行比较。评估结果表明,MVDNet 在雾天条件下的车辆检测方面取得了明显更好的性能,同时所需的计算资源减少了 10 倍。
论文贡献
1.提出了一种深度后期融合探测器,可以有效地利用激光雷达和雷达的互补优势。MVDNet 代表了第一个融合激光雷达和高分辨率 360° 雷达信号进行车辆检测的车辆检测系统。
2.引入了雾天气条件下具有细粒度激光雷达和雷达点云的标记数据集。在所提出的数据集上评估 MVDNet 并证明所提出的融合模型的有效性。
论文相关
根据激光雷达信号进行车辆检测。根据点云的表示,基于激光雷达的目标检测分为两类。
一方面,激光雷达数据默认形式化为点云,可以通过为无序点集设计的架构自然地处理、。基于这些架构,可以实现原始点云的端到端学习。 PointRCNN 使用 PointNet 提取逐点特征,并结合不同阶段的特征来识别前景。然后它会生成建议并完善最终的检测结果。PointPillars 将点分割成柱子,其中使用 PointNet 计算柱状特征以形成伪图像。然后图像被传递到 CNN 主干和 SS 检测头。然而,对于被恶劣天气遮挡的区域,由于那里没有任何点,因此无法学习逐点特征。
另一方面,激光雷达点云可以通过标准图像检测模型进行体素化和处理。 PIXOR 对点进行分割并生成不同高度的占用图。体素表示可以轻松地与其他常规图像数据(例如来自相机和激光雷达的图像数据)组合,并在 MVDNet 中得到利用。
由于对比度的损失和可见范围的减少,雾和霾会降低相机和激光雷达等视觉传感器的数据质量。一方面,人们提出了复杂的图像去雾方法以有利于学习任务。这些方法要么使用手工制作的或学习的先验来估计有雾和清晰图像之间的传输图,要么开发端到端的可训练模型。另一方面,关于激光雷达点云去噪的研究很少。由于激光雷达点云的稀疏性,现有的密集3D点云去噪方法不能直接应用于去除雾点。 DROR 利用点的动态空间邻近进行去噪。由于缺乏语义信息,它可能会错误地删除对象的孤立反射。现有的去噪方法无法在没有额外信息的情况下补偿由于雾导致的激光雷达能见度的降低。相比之下,MVDNet 使用高分辨率雷达来对抗雾天,以补充对天气敏感的激光雷达点云。
通过传感器融合进行车辆检测。多模态传感器提供冗余信息,使其能够抵御由于内部噪声和恶劣天气而导致的传感器失真。大多数融合方法都是针对激光雷达和相机提出的,因为它们在公共数据集中可用。 MV3D聚合了多个视图的提案。 PointFusion结合激光雷达和相机的特征向量来预测车辆的 3D 边界框。
雷达作为自主感知的附加方式最近越来越受到关注, DEF开发了一种带有激光雷达、摄像头和雷达的早期融合探测器。但DEF的雷达质量较低,导致雷达单独工作时性能较差。此外,DEF的雷达和摄像头视角较窄,探测器是专门为前视设计的,适应360°探测并非易事。 RadarNet在早期特征提取阶段通过 CNN 融合稀疏雷达点和激光雷达点云,以检测 360° 视角中的物体,并进一步将稀疏雷达点与检测结果关联起来以完善运动预测。 LiRaNet 还在早期阶段将稀疏雷达点与激光雷达点云和道路图融合,以预测检测到的车辆的轨迹。
相比之下,MVDNet 的目标是在雾天条件下进行稳健的车辆检测。为了实现这一目标,论文利用了最先进的成像雷达,其分辨率比 RadarNet 和 LiRaNet 中使用的分辨率要高得多,并提出了一种有效的深度后期融合方法来组合雷达和激光雷达信号。
论文内容
问题建模

(a) 不受雾影响的同步雷达强度图;(b) 32 m 以内截断的原始点云;© 具有散射雾点(红色)且可见范围缩小的雾点云。
雾的不利影响已得到很好的测量和建模。上图举例说明了效果,其中使用 [雾模型(雾密度为 0.05 m−)对来自 ORR 激光雷达(Velodyne HDL-32E 激光雷达)的点云进行雾化。
1.由于其透射率低于晴朗空气,雾会在两个方面扭曲激光雷达点云:
(i)远处物体反射的激光被衰减,变得太弱而无法被激光雷达捕获,导致可见范围缩小。
(ii) 不透明雾反向散射激光信号,导致散射雾点(图 c 中的红点)。
这些不利影响可能会导致误报和误检测,如图 1b 所示。相比之下,雾对雷达来说几乎是透明的 [14, 1]。但由于其信号波长较长且波束宽度较宽,雷达本质上比激光雷达具有较低的空间分辨率。因此,迄今为止,雷达主要用于运动/速度跟踪。
新兴的成像雷达,例如 ORR 中使用的 NavTech CTS350-X ,可以实现具有与低级激光雷达相当的分辨率和密度的点云。例如,图 a 显示了 ORR 雷达的鸟瞰强度图示例。突出的强度峰值对应于道路上的主要物体(例如车辆、墙壁等),并且与激光雷达对应物很好地匹配。
MVDNet 本质上将雷达强度图与激光雷达点云深度融合,以利用它们的互补功能。如图所示,MVDNet 由两个阶段组成。区域提议网络(MVD-RPN)从激光雷达和雷达输入中提取特征图,并从中生成提议。区域融合网络(MVD-RFN)池化并融合两个传感器帧的区域特征,并输出检测到的车辆的面向边界框。
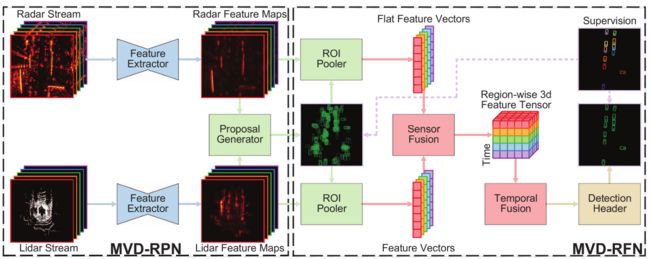
MVD-RPN BackBone
特征提取器
MVDNet 使用两个具有相同结构的特征提取器来处理激光雷达和雷达输入。但由于更多的激光雷达输入通道,激光雷达部分的特征通道数量增加了一倍。

如图 a 所示,特征提取器首先使用 4 个3×3卷积层以输入分辨率提取特征。然后,它通过最大池化将输出下采样 2 倍,并进一步以较粗的分辨率提取特征。
从鸟瞰角度来看,车辆只占据很小的区域。具体来说,ORR中的车辆平均尺寸为 2.5 m×5.1 m,仅占据 13×26 像素区域,输入分辨率为 0.2 m。对鸟瞰图进行下采样使得区域特征容易在后续提案生成器中受到量化误差的影响。
因此,MVDNet 通过转置卷积层对粗粒度特征图进行上采样,并通过跳跃链接将输出与细粒度特征图连接起来。每个特征提取器应用于相应传感器的所有 H H H 个输入帧并生成一组 H H H 个特征图。
提案生成器

如图(b),提案生成器将 H H H 个特征图流作为输入,并稍后生成 MVD-RFN 的建议。
由于移动车辆在不同的传感器帧中处于不同的位置,MVDNet 不是从每个帧的特征图单独生成建议,而是连接每个传感器的所有帧的特征图,并通过卷积层融合它们。为了充分利用各个传感器,每个传感器的融合特征图被单独使用来推断客观性分数并回归具有 K 个预定义锚点的提案位置。最后,两个传感器生成的建议通过非极大值抑制(NMS)进行合并。
MVD-RFN Multimodal Fusion
MVD-RPN 生成的提案在 RoI 池化器中用于创建区域特征。对于每个提案,池化操作应用于每个帧和传感器的特征图中的区域,产生 2 H C × W × L 2HC×W×L 2HC×W×L 特征张量,其中 C C C 是特征图中的通道数, W × L W × L W×L 是 2D 池化尺寸。然后,MVDNet 通过两个步骤融合每个提案的特征张量,即传感器融合和时间融合,如图 c 所示。

传感器融合
传感器融合融合了同步激光雷达和雷达帧对的特征张量。直观上,激光雷达和雷达并不总是同等重要,应相应地权衡它们的贡献。例如,完全被雾遮挡的车辆返回零激光雷达点,因此激光雷达的特征张量的权重应该较小。相反,雷达强度图中某些背景区域的强峰值可能类似于车辆的强度峰值。在这种情况下,应利用激光雷达特征的提示来减轻该区域周围的雷达特征的权重。
MVDNet 通过扩展注意力块来自适应地融合激光雷达和雷达特征。它将展平的特征张量 x i n {\text x}_{in} xin 作为输入,计算两个 embeding 空间 θ θ θ 和 φ φ φ 之间的相似度,并使用相似度为第三个嵌入空间 g g g 创建注意力图,以生成残差输出,即
x o u t = σ ( ( W θ x i n ) T W ϕ x i n ) W g x i n + x i n (1) \tag1 \text{x}_{out}=\sigma((\boldsymbol W_{\theta} \text x_{in})^T\boldsymbol W_{\phi} \text x_{in})\boldsymbol W_{g} \text x_{in} + \text x_{in} xout=σ((Wθxin)TWϕxin)Wgxin+xin(1)
其中 W θ , W ϕ , W ϕ \boldsymbol W_{\theta}, \boldsymbol W_{\phi}, \boldsymbol W_{\phi} Wθ,Wϕ,Wϕ分别是到嵌入空间 θ θ θ、 φ φ φ、 g g g 的线性变换, σ σ σ 表示 softmax 函数。
如图 c 所示,传感器融合的每个分支都由两个注意力块组成。虽然自注意力在各个传感器内应用注意力,但交叉注意力在对应传感器的指导下进一步应用注意力。具体来说,对于任一传感器 s 0 ∈ { l i d a r , r a d a r } s_0 \in \{lidar,radar \} s0∈{lidar,radar} 及其对应传感器 s 1 s_1 s1:
x s 0 ′ = σ ( ( W θ x s 1 ′ ) T W ϕ x s 1 ′ ) W g x s 0 ′ + x s 0 ′ (2) \tag2 \text {x}_{s_0}^{'} = \sigma((\boldsymbol W_{\theta} \text x_{s_1}^{'})^T\boldsymbol W_{\phi} \text x_{s_1}^{'})\boldsymbol W_{g} \text x_{s_0}^{'} + \text x_{s_0}^{'} xs0′=σ((Wθxs1′)TWϕxs1′)Wgxs0′+xs0′(2)
其中 x ′ \text x^{'} x′ 表示每个分支的自注意力输出的特征向量。来自两个传感器交叉注意力的输出特征向量被重塑回特征张量并连接以进行时间融合。
时间融合
时间融合进一步合并不同帧的参与特征张量。
如图 c 所示,MVDNet 没有使用时序和内存密集型循环结构,而是沿新维度连接不同帧的参与特征张量以形成 4D 特征张量,并应用 3D 卷积层以允许沿时间维度交换信息。最后一个卷积层压缩时间维度并输出融合的特征张量。然后,MVDNet 展平融合的特征张量并将其传递到全连接层以推断最终检测的客观分数和回归位置,如图 d 所示。

论文总结
论文引入了 MVDNet,以便在恶劣的雾天条件下实现车辆检测。 MVDNet 通过传感模式和时间维度的深度后期融合,利用激光雷达和雷达的互补优势。为了评估 MVDNet,引入了一种新颖的程序生成训练数据集,其中包含空间细粒度机械雷达和激光雷达。实验结果表明,与现有的单独激光雷达或多模态方法相比,MVDNet 始终保持较高的检测精度,尤其是在雾天条件下。