TensorRT优化部署(三)------ONNX注册算子
系列文章目录
第一章 TensorRT优化部署(一)–TensorRT和ONNX基础
第二章 TensorRT优化部署(二)–剖析ONNX架构
第三章TensorRT优化部署(三)------ONNX注册算子
文章目录
- 系列文章目录
- 前言
- 一、什么是ONNX注册算子
- 二、出现导出ONNX不成功时解决办法:
-
- 2.1 unsupported asinh算子
- 2.2 unsupported asinh算子另一种方法
- 三、Onnx-graph-surgeon
-
- 3.1 Onnx-graph-surgeon是什么
- 3.2 Onnx-graph-surgeon与onnx.helper异同
- 总结
前言
主要介绍ONNX注册算子相关内容,该内容为专栏内容,可进专栏查看其他相关章节
一、什么是ONNX注册算子
ONNX注册算子是指将PyTorch中的自定义算子(Operator)注册到ONNX中,使得这些自定义算子可以在其他框架中运行。
二、出现导出ONNX不成功时解决办法:
模型部署中常见的几类困难有:模型的动态化;新算子的实现;框架间的兼容
-
修改opset版本
{ 查看不支持算子在新的 o p s e t 中是否被支持 在不使用自己搭建的 p l u g i n 时,查看 o n n x − t r t 中算子是否被支持 查看官方文档 ( h t t p s : / / g i t h u b . c o m / o n n x / o n n x / b l o b / m a i n / d o c s / O p e r a t o r s . m d ) \left\{ \begin{array}{l} 查看不支持算子在新的opset中是否被支持\\ \\ 在不使用自己搭建的plugin时,查看onnx-trt中算子是否被支持 \\ \\ 查看官方文档(https://github.com/onnx/onnx/blob/main/docs/Operators.md)\\ \end{array}\right. ⎩ ⎨ ⎧查看不支持算子在新的opset中是否被支持在不使用自己搭建的plugin时,查看onnx−trt中算子是否被支持查看官方文档(https://github.com/onnx/onnx/blob/main/docs/Operators.md) -
替换pytorch中某些算子组合
把某些算子替换成onnx可识别的 -
在pytorch登记onnx某些算子
有可能onnx中有支持,但没有被登记
-
直接修改Onnx创建plugin
{ 使用 o n n x − s u r g e o n 一般是用在加速某些算子上使用 \left\{ \begin{array}{l} 使用onnx-surgeon\\ \\ 一般是用在加速某些算子上使用 \\ \end{array}\right. ⎩ ⎨ ⎧使用onnx−surgeon一般是用在加速某些算子上使用
2.1 unsupported asinh算子
sample_asinh.py
import torch
import torch.onnx
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = torch.asinh(x)
return x
def infer():
input = torch.rand(1, 5)
model = Model()
x = model(input)
print("input is: ", input.data)
print("result is: ", x.data)
def export_norm_onnx():
input = torch.rand(1, 5)
model = Model()
model.eval()
file = "../models/sample-asinh.onnx"
torch.onnx.export(
model = model,
args = (input,),
f = file,
input_names = ["input0"],
output_names = ["output0"],
opset_version = 12)
print("Finished normal onnx export")
if __name__ == "__main__":
infer()
# 这里导出asinh会出现错误。
# Pytorch可以支持asinh的同时,
# def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
# 从onnx支持的算子里面我们可以知道自从opset9开始asinh就已经被支持了
# asinh is suppored since opset9
# 所以我们可以知道,问题是出现在PyTorch与onnx之间没有建立asinh的映射
# 我们需要建立这个映射。这里涉及到了注册符号函数的概念.
export_norm_onnx()
显示opset version不支持
![]()
修改成12以后,依然显示不支持

查看官方文档后可以发现Asinh是支持opset9的。所以问题是出现在PyTorch与onnx之间没有建立asinh的映射,我们需要建立这个映射。

虽然onnx支持asinh,但是pytorch2onnx没有建立起桥梁。所以需要使用onnx注册算子,首先创建一个算子的符号函数用来登记,再将符号函数与Pytorch中的算子进行绑定,即所谓的“注册算子"。
• 创建symbolic符号函数,从而创建一个onnx operator
• 注册这个onnx operator,并让它与底层的aten中的asinh实现绑定
注意:(symbolic符号函数中的参数,需要严格遵循pytorch中的定义)
sample_asinh_register.py
import torch
import torch.onnx
import onnxruntime
from torch.onnx import register_custom_op_symbolic
# 创建一个asinh算子的symblic,符号函数,用来登记
# 符号函数内部调用g.op, 为onnx计算图添加Asinh算子
# g: 就是graph,计算图
# 也就是说,在计算图中添加onnx算子
# 由于我们已经知道Asinh在onnx是有实现的,所以我们只要在g.op调用这个op的名字就好了
# symblic的参数需要与Pytorch的asinh接口函数的参数对齐
# def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
def asinh_symbolic(g, input, *, out=None):
return g.op("Asinh", input)
# 在这里,将asinh_symbolic这个符号函数,与PyTorch的asinh算子绑定。也就是所谓的“注册算子”
# asinh是在名为aten的一个c++命名空间下进行实现的
# 那么aten是什么呢?
# aten是"a Tensor Library"的缩写,是一个实现张量运算的C++库
register_custom_op_symbolic('aten::asinh', asinh_symbolic, 12)
# 这里容易混淆的地方:
# 1. register_op中的第一个参数是PyTorch中的算子名字: aten::asinh
# 2. g.op中的第一个参数是onnx中的算子名字: Asinh
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = torch.asinh(x)
return x
def validate_onnx():
input = torch.rand(1, 5)
# PyTorch的推理
model = Model()
x = model(input)
print("result from Pytorch is :", x)
# onnxruntime的推理
sess = onnxruntime.InferenceSession('../models/sample-asinh.onnx')
x = sess.run(None, {'input0': input.numpy()})
print("result from onnx is: ", x)
def export_norm_onnx():
input = torch.rand(1, 5)
model = Model()
model.eval()
file = "../models/sample-asinh.onnx"
torch.onnx.export(
model = model,
args = (input,),
f = file,
input_names = ["input0"],
output_names = ["output0"],
opset_version = 12)
print("Finished normal onnx export")
if __name__ == "__main__":
export_norm_onnx()
# 自定义完onnx以后必须要进行一下验证
validate_onnx()
注意:
aten::xxx
• c++的一个namespace,pytorch的很多算子的底层都是在aten这个命名空间下进行以c++进行实现的。
onnx_symblic
• 负责绑定
• 绑定pytorch中的算子与aten命名空间下的算子的一一对应
2.2 unsupported asinh算子另一种方法
sample_asinh_register2.py
import torch
import torch.onnx
import onnxruntime
import functools
from torch.onnx import register_custom_op_symbolic
from torch.onnx._internal import registration
_onnx_symbolic = functools.partial(registration.onnx_symbolic, opset=9)
# 另外一个写法
# 这个是类似于torch/onnx/symbolic_opset*.py中的写法
# 通过torch._internal中的registration来注册这个算子,让这个算子可以与底层C++实现的aten::asinh绑定
# 一般如果这么写的话,其实可以把这个算子直接加入到torch/onnx/symbolic_opset*.py中
@_onnx_symbolic('aten::asinh')
def asinh_symbolic(g, input, *, out=None):
return g.op("Asinh", input)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = torch.asinh(x)
return x
def validate_onnx():
input = torch.rand(1, 5)
# PyTorch的推理
model = Model()
x = model(input)
print("result from Pytorch is :", x)
# onnxruntime的推理
sess = onnxruntime.InferenceSession('../models/sample-asinh2.onnx')
x = sess.run(None, {'input0': input.numpy()})
print("result from onnx is: ", x)
def export_norm_onnx():
input = torch.rand(1, 5)
model = Model()
model.eval()
file = "../models/sample-asinh2.onnx"
torch.onnx.export(
model = model,
args = (input,),
f = file,
input_names = ["input0"],
output_names = ["output0"],
opset_version = 12)
print("Finished normal onnx export")
if __name__ == "__main__":
export_norm_onnx()
# 自定义完onnx以后必须要进行一下验证
validate_onnx()
三、Onnx-graph-surgeon
3.1 Onnx-graph-surgeon是什么
Onnx-graph-surgeon是一种创建/修改onnx的工具。
- 更加方便的添加/修改onnx节点
- 更加方便的修改子图
- 更加方便的替换算子
下载安装
pip install nvidia-pyindex
pip install onnx-graphsurgeon
3.2 Onnx-graph-surgeon与onnx.helper异同
Onnx-graph-surgeon中的IR表示
Onnx.helper中的IR表示(Intermediate Representation)中间件表示
gs帮助隐藏了很多信息,node属性以前使用AttributeProto保存,在gs中统一用dict来保存。
使用原生的gs创建onnx
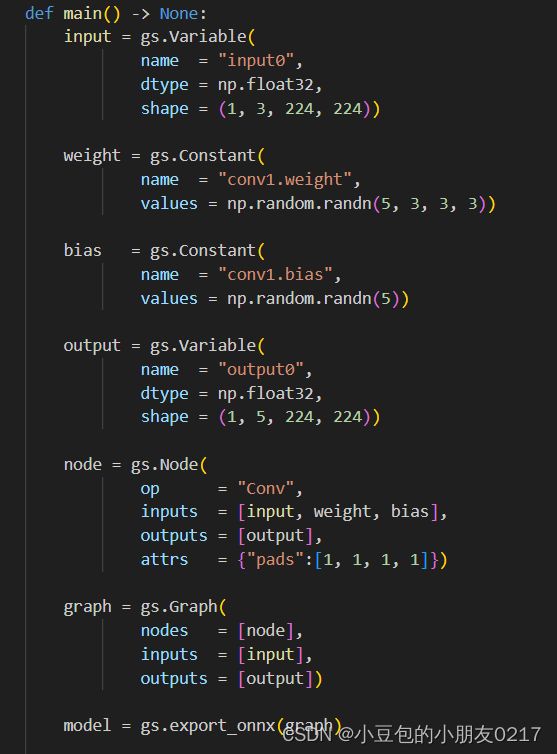
gs可以自定义一些函数去创建onnx,使整个onnx的创建更加方便,可以自己创建算子来构建
代码如下:
import onnx_graphsurgeon as gs
import numpy as np
import onnx
#####################在graph注册调用的函数########################
@gs.Graph.register()
def add(self, a, b):
return self.layer(op="Add", inputs=[a, b], outputs=["add_out_gs"])
@gs.Graph.register()
def mul(self, a, b):
return self.layer(op="Mul", inputs=[a, b], outputs=["mul_out_gs"])
@gs.Graph.register()
def gemm(self, a, b, trans_a=False, trans_b=False):
attrs = {"transA": int(trans_a), "transB": int(trans_b)}
return self.layer(op="Gemm", inputs=[a, b], outputs=["gemm_out_gs"], attrs=attrs)
@gs.Graph.register()
def relu(self, a):
return self.layer(op="Relu", inputs=[a], outputs=["act_out_gs"])
#####################通过注册的函数进行创建网络########################
# input (64, 64)
# |
# gemm (constant tensor A(64, 32))
# |
# add (constant tensor B(64, 32))
# |
# relu
# |
# mul (constant tensor C(64, 32))
# |
# add (constant tensor D(64, 32))
# 初始化网络的opset
graph = gs.Graph(opset=12)
# 初始化网络需要用的参数
consA = gs.Constant(name="consA", values=np.random.randn(64, 32))
consB = gs.Constant(name="consB", values=np.random.randn(64, 32))
consC = gs.Constant(name="consC", values=np.random.randn(64, 32))
consD = gs.Constant(name="consD", values=np.random.randn(64, 32))
input0 = gs.Variable(name="input0", dtype=np.float32, shape=(64, 64))
# 设计网络架构
gemm0 = graph.gemm(input0, consA, trans_b=True)
relu0 = graph.relu(*graph.add(*gemm0, consB))
mul0 = graph.mul(*relu0, consC)
output0 = graph.add(*mul0, consD)
# 设置网络的输入输出
graph.inputs = [input0]
graph.outputs = output0
for out in graph.outputs:
out.dtype = np.float32
# 保存模型
onnx.save(gs.export_onnx(graph), "../models/sample-complicated-graph.onnx")
gs中最重要的一个特点,在于我们可以使用gs来替换算子或者创建算子,后面可以与TensorRT plugin绑定,实现算子的加速或者不兼容算子的实现。
总结
本章介绍了ONNX注册算子相关的内容,后续将继续分析代码细节,关于开源源码导出onnx的整个流程,该内容为专栏内容,后续将继续补充。