Hive内容分享(三):Hive 架构思想和设计原理
目录
前言
Hive
Hive的架构
MapReduce 实现 SQL 的原理
Hive 如何实现 join 操作
Hive命令说明
Hive函数使用
尾声
前言
今天为大家推荐的是梦想家的 Hive 架构思想和设计原理,希望对大家有启发。
Hive
MapReduce 虽然只有 map 和 reduce 这两个函数,但几乎可以满足任何大数据分析和机器学习的场景。不过,复杂的计算可能需要使用多个 job 才能完成,这些 job 之间还需要根据其先后依赖关系进行作业的编排,开发比较复杂。
在 Hadoop 出现之前,大部分的数据分析人员基本都用 SQL 语句分析数据库中的数据,如果让这些数据分析人员重新学习一下 Hadoop 支持的开发语言,将会耗费巨大的人力成本和学习成本。
所以,就有聪明的小伙伴想到,如果能根据 SQL 自动生成 MapReduce,就可以极大降低大数据技术在数据分析领域的应用门槛。
基于这样的一个需求场景,Hive 横空出世。
Hive的架构
首先让我们来看下 Hive 的架构 。

-
Hive可以通过CLI,JDBC和 ODBC 等客户端进行访问。除此之外,Hive还支持 WUI 访问
-
Hive内部执行流程:解析器(解析SQL语句)、编译器(把SQL语句编译成MapReduce程序)、优化器(优化MapReduce程序)、执行器(将MapReduce程序运行的结果提交到HDFS)
-
Hive的元数据保存在数据库中,如保存在MySQL,SQLServer,PostgreSQL,Oracle及Derby等数据库中。Hive中的元数据信息包含表名,列名,分区及其属性,表的属性(包括是否为外部表),表数据所在目录等。
-
Hive将大部分 HiveSQL语句转化为 MapReduce 作业提交到 Hadoop上执行;少数 HiveSQL 语句不会转化为MapReduce作业,直接从DataNode上获取数据后按照顺序输出。
知晓了架构,我们接下来通过一条常见的 SQL 语句,来看看 Hive 是如何将其转换成 MapReduce 来计算的。
MapReduce 实现 SQL 的原理
SELECT pageid,
age,
count(1)
FROM pv_users
GROUP BY pageid, age;
就像所展示的一样,这是一条很常见的 SQL 统计分析语句,用于统计不同年龄的用户访问不同网页的兴趣偏好,具体数据输入和执行的结果示例如图所示:

看这个示例我们就会发现,这个计算场景和 WordCount 很像。事实上也确实如此,我们可以用 MapReduce 完成这条 SQL 的处理。

这样一条很有实用价值的 SQL 就被很简单的 MapReduce 计算过程处理好了。
map 函数输出的 key 是表的行记录,value 是 1,reduce 函数对相同的行进行记录,也就是针对具有相同 key 的 value 集合进行求和计算,最终得到 SQL 的输出结果。
Hive要做的就是将SQL翻译成MapReduce程序代码。实际上,Hive内置了很多Operator,每个Operator完成一个特定的计算过程,Hive将这些Operator构造成一个有向无环图DAG,然后根据这些Operator之间是否存在shuffle将其封装到map或者reduce函数中,之后就可以提交给MapReduce执行了。
Operator 组成的 DAG 如下图 所示,这是一个包含 where 查询条件的 SQL,where 查询条件对应一个 FilterOperator。
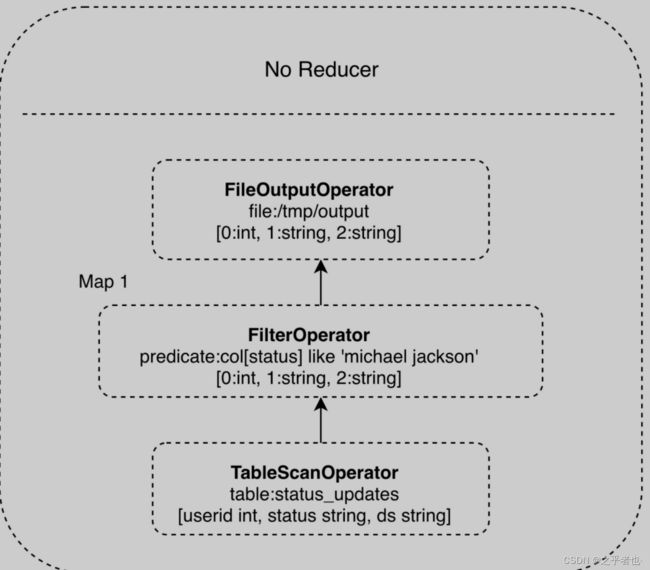
值得注意的是,有些 HiveQL 语句不会被 Hive 转化成 MapReduce 作业,Hive 只会从 DataNode 将数据获取到了之后,按照顺序依次输出。
select * from user;
Hive 如何实现 join 操作
除了上面这些简单的聚合(group by)、过滤(where)操作,Hive 还能执行连接(join on)操作。
比如现在来了一个需求。
有 2 张表,一张 是 page_view 页面浏览记录表,一张是 user 用户表
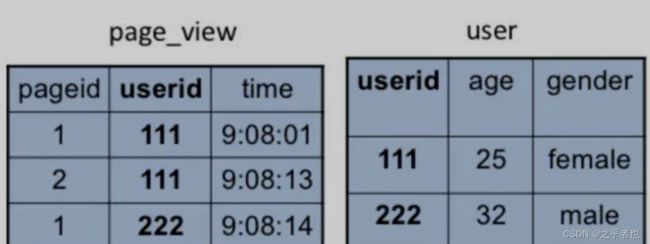
如果我想收集到每个页面浏览用户的age信息,该如何获取。
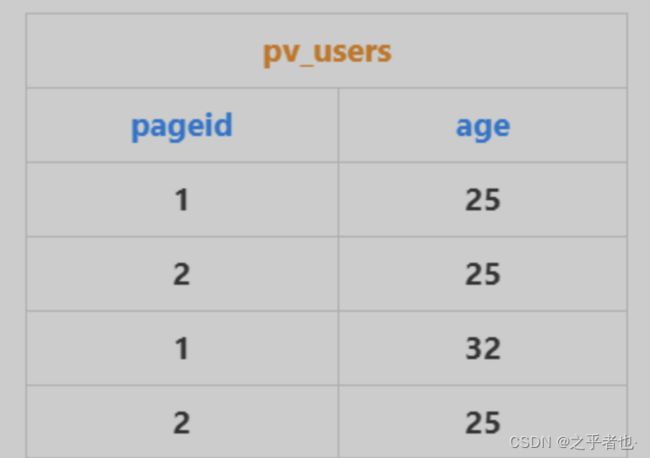
很明显,这两张表都有一个相同的字段 userid,根据这个字段可以将两张表连接起来,生成我们最终想要的结果表 pv_users ,SQL 命令是
SELECT pv.pageid, u.age
FROM page_view pv
JOIN user u
ON (pv.userid = u.userid);
同样,这个 SQL 命令也可以转化为 MapReduce 计算,连接的过程如下图所示。

从图上看,join 的 MapReduce 计算过程和前面的 group by 稍有不同,因为 join 涉及两张表,来自两个文件(夹),所以需要在 map 输出的时候进行标记,比如来自第一张表的输出 Value 就记录为 <1, X>,这里的 1 表示数据来自第一张表。这样经过 shuffle 以后,相同的 Key 被输入到同一个 reduce 函数,就可以根据表的标记对 Value 数据求笛卡尔积,用第一张表的每条记录和第二张表的每条记录连接,输出就是 join 的结果。
所以我们如果打开 Hive 的源代码,看 join 相关的代码,会看到一个两层 for 循环,对来自两张表的记录进行连接操作。
Hive命令说明
在 Hive 提供的所有连接方式中,命令行界面是最常见的一种。用户可以使用 Hive 的命令行对 Hive 中的数据库,数据表和数据进行各种的操作。
Hive函数使用
Hive内部支持大量的函数,可以通过 SHOW FUNCTIONS 查看Hive的内置函数。灵活地运用 Hive 提供的函数能够极大地节省数据分析成本。Hive函数主要包含数学函数,集合函数,类型转换函数,日期函数,条件函数,字符串函数,聚合函数 和 表生成函数等。
调优向来都非常重要,无论是面试复习,还是实际工作,都少不了和它打交道。
例如,从建表设计层面,我们可以考虑到利用分区表/分桶表优化,选择选择合适的压缩格式。
从 HQL语法和运行参数层面,我们可以采用 查看Hive执行计划,列剪裁,谓词下推,分区剪裁,合并小文件 等方式 ...
从 Hive架构层面,我们可以采用 启用本地抓取,本地执行优化,JVM重用,并行执行 等方式
尾声
在实践中,工程师其实并不需要经常编写 MapReduce 程序,因为网站最主要的大数据处理就是 SQL 分析,也因此 Hive 在大数据应用中的作用非常重要。
后面随着 Hive 的普及,我们对于在 Hadoop 上执行 SQL 的需求越加强烈,对大数据 SQL 的应用场景也多样化起来,于是又开发了各种大数据 SQL 引擎。
例如 Cloudera 也开发了 Impala,这是一种运行在 HDFS 上的 MPP 架构的 SQL 引擎。和 MapReduce 启动 Map 和 Reduce 两种执行进程,将计算过程分成两个阶段进行计算不同,Impala 在所有 DataNode 服务器上部署相同的 Impalad 进程,多个 Impalad 进程相互协作,共同完成 SQL 计算。在一些统计场景中,Impala 可以做到毫秒级的计算速度。
还有后面我会为大家介绍的 SparkSQL,此外,大家还希望在 NoSQL 的数据库上执行 SQL,毕竟 SQL 发展了几十年,积累了庞大的用户群体,很多人习惯了用 SQL 解决问题。于是 Saleforce 推出了 Phoenix,一个执行在 HBase 上的 SQL 引擎 ....
Hive 本身的技术架构其实并没有什么创新,数据库相关的技术和架构已经非常成熟,只要将这些技术架构应用到 MapReduce 上就得到了 Hadoop 大数据仓库 Hive。但是想到将两种技术嫁接到一起,却是极具创新性的,通过嫁接产生出的 Hive 可以极大降低大数据的应用门槛,也使 Hadoop 大数据技术得到大规模普及。