Python急速入门——(第八章:字符串)
Python急速入门——(第八章:字符串)
- 1.字符串的创建与驻留机制
- 2.字符串的常规操作
-
- 2.1字符串查询操作
- 2.2字符串的大小写转换
- 2.3字符串内容对齐操作方法
- 2.4字符串劈分
- 2.5字符串判断
- 2.6替换与合并
- 3.字符串比较
- 4.字符串的切片操作
- 5.格式化字符串
- 6.字符串的编码转换
1.字符串的创建与驻留机制
1.字符串:在Python中字符串是基本数据类型,是一个不可变的字符序列。
字符串的定义:
a = 'Python'
b = "Python"
c = '''Python'''
d = """Python"""
# 4个id相同
print(id(a))
print(id(b))
print(id(c))
print(id(d))
可以用单引号,双引号,和三引号来定义。
2.字符串驻留机制:
仅保留一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。
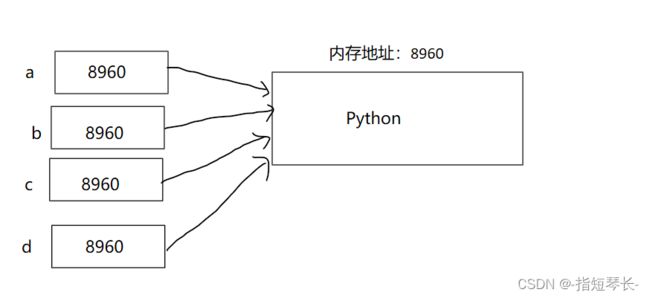
1)驻留机制的几种情况(命令行交互模式)
-
字符串的长度为0或1时。
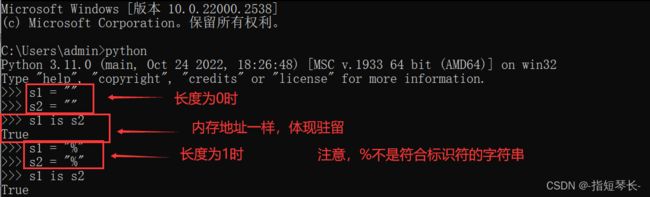
-
符合标识符的字符串。(含有字母,数字,下划线的字符串,称为符合标识符的字符串)

-
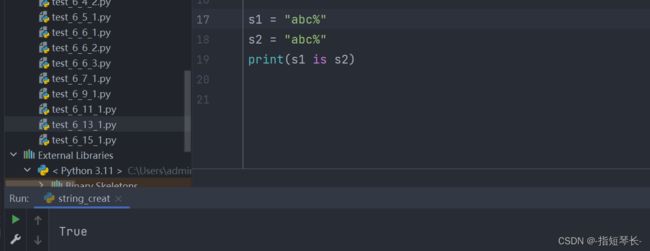
字符串只在编译时进行驻留,在运行时不驻留。
虽然Python是解释性语言,但是实际上它的解释器也可以理解成一种编译器,他负责将Python代码编译成字节码,也就是.pyc文件。
- [-5, 256]之间的整数数字。

Python提供了一个sys的类,可以强制两个字符串指向同一个类。

2)为什么不使用pycharm演示?
pycharm会进行优化,只要内容相同就会进行驻留,做了一个强制处理。
3.字符串驻留机制的优缺点:
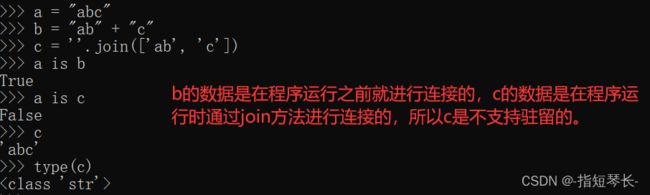
1)当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的;
2)在需要进行字符串拼接式建议使用str类型的join()方法,而非+,因为join()方法是先计算出最终需要的字符串长度,然后再拷贝,只创建一次对象。而+号在拼接字符串的时候,会先开辟一块空间,把+号左边的字符串和+号右边的字符串合起来放在新开辟的空间内,这样有几个+号,就会开辟几次空间。明显join()的效率更高。
2.字符串的常规操作
2.1字符串查询操作
| 方法名称 | 作用 |
|---|---|
| index() | 查找子串substr第一次出现的位置,如果查找的子串不存在,则会抛出ValueError |
| rindex() | 查找子串substr最后一次出现的位置,如果查找的子串不存在,则会抛出ValueError |
| find() | 查找子串substr第一次出现的位置,如果查找的子串不存在,则返回-1 |
| rfind() | 查找子串substr最后一次出现的位置,如果查找的子串不存在,则返回-1 |
# 字符串的查询操作
s = "hello hello"
print(s.index('lo')) # 3
print(s.find('lo')) # 3
print(s.rindex('lo')) # 9
print(s.rfind('lo')) # 9
print(s.find('x')) # -1
# print(s.index('l0')) # 报错
建议大家使用find或rfind,因为这两个函数就算找不到目标子串,也不会直接终止程序。
2.2字符串的大小写转换
| 方法名称 | 作用 |
|---|---|
| upper() | 把字符串中所有字符都转成大写字母 |
| lower() | 把字符串中所有的字符都转成小写字母 |
| swapcase() | 把字符串中所有大写字母转成小写字母,把所有小写字母都转成大写字母 |
| capitalize() | 把第一个字符转换成大写,把其余字符转换成小写 |
| title() | 把每个单词的第一个字符转成大写,把每个单词的剩余字符转成小写 |
测试upper()和lower():
s = "hello, world"
a = s.upper() # 转成大写之后,会产生一个新的字符串对象
print(a, id(a))
print(s, id(s))
b = s.lower() # 即使转换之后b和s的值相同,但还是会产生一个新的字符串对象
print(b, id(b))
print(s, id(s))
输出:
HELLO, WORLD 2879126492208
hello, world 2879125214384
hello, world 2879126520624
hello, world 2879125214384
测试剩余的函数:
s2 = "hello, Python"
print(s2.swapcase())
print(s2.capitalize())
s2 = "hello, python"
print(s2.title())
输出:
HELLO, pYTHON
Hello, python
Hello, Python
2.3字符串内容对齐操作方法
| 方法名称 | 作用 |
|---|---|
| center() | 居中对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于等于实际宽度则返回原字符串 |
| ljust() | 左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于等于实际宽度则返回原字符串 |
| rjust() | 右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于等于实际宽度则返回原字符串 |
| zfill() | 右对齐,左边用0填充,该方法只接受一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身 |
# 字符串对齐
s = "hello world" # 共11位
print(s.center(20, '*'))
print("左对齐")
print(s.ljust(20, '*'))
print(s.ljust(10, '*')) # 设置宽度小,返回原字符
print("右对齐")
print(s.rjust(20, '*'))
print(s.rjust(20)) # 不写参数默认用空格填充
print("右对齐,使用0填充")
print(s.zfill(20))
print(s.zfill(10))
print('-8910'.zfill(8)) # 会填充到-号后面
输出:
****hello world*****
左对齐
hello world*********
hello world
右对齐
*********hello world
hello world
右对齐,使用0填充
000000000hello world
hello world
-0008910
2.4字符串劈分
| 方法名称 | 作用 |
|---|---|
| split() | 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表;可以通过参数sep指定劈分字符串的劈分字符;通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大劈分之后,剩余的子串会单独作为一部分 |
| rsplit() | 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表;可以通过参数sep指定劈分字符串的劈分字符;通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大劈分之后,剩余的子串会单独作为一部分 |
s = 'hello world Python'
lst = s.split() # 默认是以空格为分割符
print(lst)
s1 = 'hello|world|Python'
print(s1.split(sep='|'))
print(s1.split(sep='|', maxsplit=1))
print('--------------------------------')
'''rsplit()从右侧开始劈分'''
s = 'hello world Python'
s1 = 'hello|world|Python'
print(s.rsplit())
print(s1.split('|'))
print(s1.rsplit('|', 1))
输出:
['hello', 'world', 'Python']
['hello', 'world', 'Python']
['hello', 'world|Python']
--------------------------------
['hello', 'world', 'Python']
['hello', 'world', 'Python']
['hello|world', 'Python']
2.5字符串判断
| 方法名称 | 作用 |
|---|---|
| isidentifier() | 判断指定的字符串是不是合法的标识符 |
| isspace() | 判断指定的字符串是否全部由空白字符组成(回车、换行、水平制表符) |
| isalpha() | 判断指定的字符串是否全部由字母组成 |
| isdecimal() | 判断字符串是否全部由十进制数组成 |
| isnumeric() | 判断指定的字符串是否全部由数字组成 |
| isalnum() | 判断指定字符串是否全部由字母和数字组成 |
测试代码:
s = "hello,python"
print('1.', s.isidentifier()) # False
print('2.', 'hello'.isidentifier()) # True
print('3.', '张三'.isidentifier()) # True
print('4.', '张三_123'.isidentifier()) # True
print()
print('5.', '\t'.isspace()) # True
print('6.', '\n'.isspace()) # True
print()
print('7.', 'abc'.isalpha()) # True
print('8.', '张三'.isalpha()) # True 汉字是字母
print('9.', '1张三'.isalpha()) # False
print()
print('10.', '123'.isdecimal()) # True
print('11.', '123四'.isdecimal()) # False 汉字4不是十进制数
print('12.', 'ⅡⅡⅡ'.isdecimal()) # False 罗马数字不是十进制数
print('13.', '123'.isnumeric()) # True
print('14.', '123四'.isnumeric()) # True 汉字数字是数字
print('15.', 'ⅡⅡⅡ'.isnumeric()) # True 罗马数字也是数字
print('16.', 'abc1'.isalnum()) # True
print('17.', '张三123'.isalnum()) # True
print('18.', 'abc!'.isalnum()) # False
2.6替换与合并
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 字符串替换 | replace() | 第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的新字符串,参与替换的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数 |
| 字符串的合并 | join() | 将列表或元组中的字符串合并成一个字符串 |
s='hello,Python'
print(s.replace('Python', 'Java'))
s1='hello,Python,Python,Python'
print(s1.replace('Python', 'Java', 2)) # 只替换两回
print()
lst=['hello', 'java', 'Python']
print('|'.join(lst)) # 使用 | 去连接
print(''.join(lst)) # 使用空字符串去连接,相当于把元组中的字符串直接拼接起来
print()
print('*'.join('Python')) # 把字符串当成可迭代序列,用 * 拼接每一个字母
输出:
hello,Java
hello,Java,Java,Python
hello|java|Python
hellojavaPython
P*y*t*h*o*n
3.字符串比较
1.字符串的比较操作:
1)运算符:>,>=,<,<=,==,!=
2)比较规则:从第一个字符依次向后比较,直到出现两个字符不相等时,这两个字符的比较结果就是字符串的比较结果。
3)比较原理:两个字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord()可以得到指定字符的原始值;与内置函数ord()对应的是内置函数chr(),调用内置函数chr()时指定原始值可以得到对应的字符。
print('apple'>'app') # True
print('apple'>'banana') # False ,相当于97>98 >False
print(ord('a'), ord('b')) # 输出97 98
print(ord('李')) # 输出26446
print(chr(97), chr(98)) # 输出a b
print(chr(26446)) # 输出 李
'''== 比较的是 value , is 比较的是id是否相等'''
a=b='Python'
c='Python'
print(a==b) # True
print(b==c) # True
print(a is b) # True
print(a is c) # True
4.字符串的切片操作
字符串是一个不可变对象,切片操作将产生新的对象。其余细节和列表的切片一样,这里就不细讲了。
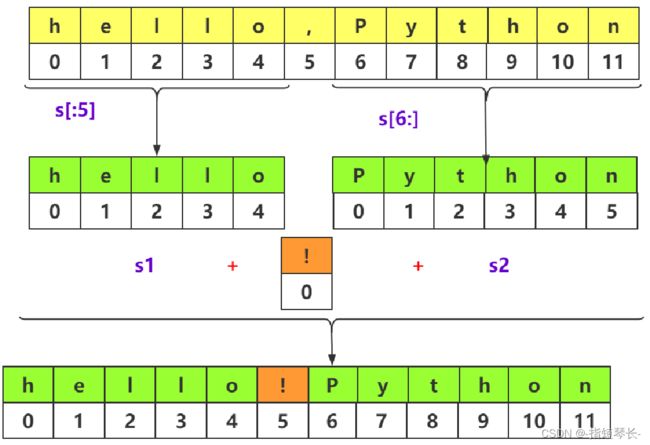
根据上图写一段测试代码:
s = 'hello,Python'
s1=s[:5] # 由于没有指定起始位置,所以从0开始切
s2=s[6:] # 由于没有指定结束位置,所以切到字符串的最后一个元素
s3='!'
newstr = s1+s3+s2
print(s1)
print(s2)
print(newstr)
print('-------一共有5个字符串参与了操作--------')
print(id(s))
print(id(s1))
print(id(s2))
print(id(s3))
print(id(newstr))
输出:
hello
Python
hello!Python
-------一共有5个字符串参与了操作--------
2645922698736
2645922890352
2645922891888
140705059338496
2645922892016
完整的切片语法展示:
print('------------------切片[start:end:step]-------------------------')
s = 'hello,Python'
print(s[1:5:1]) # 从1开始截到5(不包含5),步长为1
print(s[::2]) # 默认从0 开始,没有写结束,默认到字符串的最后一个元素 ,步长为2 ,两个元素之间的索引间隔为2
print(s[::-1]) # 默认从字符串的最后一个元素开始,到字符串的第一个元素结束,因为步长为负数
print(s[-6::1]) # 从索引为-6开始,到字符串的最后一个元素结束,步长为1
输出:
------------------切片[start:end:step]-------------------------
ello
hloPto
nohtyP,olleh
Python
5.格式化字符串
1.为什么需要格式化字符串,看下面的一个需求:

疫情时,大家都需要写这样一个外出证明,如图,只有xxx的地方是可以改变的字符串,其他地方都是固定的,那这就相当于字符串的拼接。但是字符串的拼接操作会产生很多新的字符串,会造成内存空间浪费。这时候就需要使用格式化字符串。
2.三种方式:
1)%做占位符
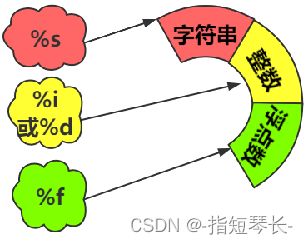
2){}做占位符

# % 做占位符
name = '张三'
age = 20
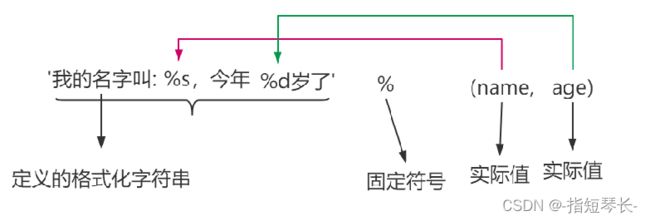
print('我叫%s,今年%d岁' % (name, age))
# {} 做占位符
print('我叫{0},今年{1}岁'.format(name, age))
# 第三种形式
# f - string
print(f'我叫{name},今年{age}岁') # 最开头要加个f
输出:
我叫张三,今年20岁
我叫张三,今年20岁
我叫张三,今年20岁
3.带精度和宽度的格式化字符串:
1)使用%
print('0123456789') # 方便查看输出数据的占位情况
print()
print('%10d' % 99) # 10表示的是宽度,整个输出占10位,右对齐,左边补空格
print('%-10d' % 99) # 左对齐
print('%.3f' % 3.1415926) # .3表示是小数点后三位
#同时表示宽度和精度
print('%10.3f' % 3.1415926) # 一共总宽度为10,小数点后 3位
print('%-10.3f' % 3.1415926) # 左对齐
输出:
0123456789
99
99
3.142
3.142
3.142
2)使用{}
# 使用花括号
print('{0}'.format(12))
print('{0:.3}'.format(3.1415926)) # .3表示的是一共是3位数,不带进位
print('{:.3f}'.format(3.1415926)) # .3f表示是3位小数
print('{:10.3f}'.format(3.1415926)) # 同时设置宽度和精度,一共是10位,3位是小数
print('{:<10.3f}'.format(3.1415926)) # 使用<左对齐
输出:
12
3.14
3.142
3.142
3.142
6.字符串的编码转换
1.为什么需要字符串的编码转换?
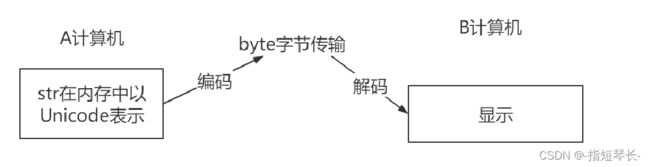
在网络中传输数据时要以字节形式传输,也就是二进制数据。字符串要根据编码表变成二进制数据来传输,接收时也要用对应的编码表来解码二进制数据。
2.编码与解码的方式
编码:将字符串转换为二进制数据。
解码:将二进制数据转换成字符串类型。
用encode来编码,用decode来解码:
# 字符串的编码转换
s='天涯共此时'
#编码
print(s.encode(encoding='GBK')) # 在GBK这种编码格中 一个中文占两个字节
print(s.encode(encoding='UTF-8')) # 在UTF-8这种编辑格式中,一个中文占三个字节
#解码
#byte代表就是一个二进制数据(字节类型的数据)
byte=s.encode(encoding='GBK') # 编码
print(byte.decode(encoding='GBK')) # 解码
byte=s.encode(encoding='UTF-8')
print(byte.decode(encoding='UTF-8'))
输出:
b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1'
b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6'
天涯共此时
天涯共此时
编码格式和解码格式一定要对应,这一块的知识在Python爬虫中会用到。