详解Java中的原子操作
第1章:什么是原子操作
大家好,我是小黑,面试中一个经常被提起的话题就是“原子操作”。那么,到底什么是原子操作呢?在编程里,当咱们谈论“原子操作”时,其实是指那些在执行过程中不会被线程调度机制打断的操作。这种操作要么完全执行,要么完全不执行,没有中间状态。这就像是化学里的原子,不可分割,要么存在,要么不存在。
举个简单的例子,想象一下,小黑在网上银行转账给朋友。这个操作要么完整完成——钱从小黑的账户转到朋友账户,要么根本就不发生——钱还在小黑的账户里。如果转账过程中出现问题,系统不会说“转了一半的钱”,要么就是全转了,要么就是一分没转。这就是原子操作的一个生活实例。
在Java中,原子操作尤为重要,尤其是在多线程环境中。想象一下,如果小黑在操作一个共享变量时,这个操作被其他线程打断,那会发生什么?可能会导致数据不一致,或者更糟糕的情况。因此,保证操作的原子性在并发编程中是非常重要的。
第2章:Java中原子操作的基础
要理解Java中的原子操作,首先得了解一下Java内存模型(JMM)。简单来说,JMM是一种抽象的概念,它描述了Java在内存中如何存储共享变量以及这些变量如何在多线程间交互。JMM定义了线程和主内存之间的关系,以及如何通过同步来保证共享变量的可见性和顺序性。
在多线程环境中,每个线程都有自己的工作内存,用于存储使用中的共享变量的副本。当线程对这些变量进行读写操作时,它们实际上是在操作这些副本。只有通过同步操作,这些变量的值才会真正地在主内存和工作内存间传递。
那么,原子操作和JMM有什么关系呢?原子操作保证了在单个操作中,变量的读取、修改和写回都是不可分割的。这就确保了即使在多线程环境中,这些操作也能保持一致性和正确性。
让咱们来看一个简单的Java代码示例,展示非原子操作的问题:
public class Counter {
private int count = 0;
public void increment() {
count++; // 非原子操作
}
public int getCount() {
return count;
}
}
在这个例子中,count++看似是一个简单的操作,但实际上它包含了三个步骤:读取count的值,增加1,然后写回新的值。在多线程环境中,如果两个线程同时执行increment()方法,它们可能读到同一个count值,结果就是count只增加了1,而不是2。这就是非原子操作可能带来的问题。
第3章:Java原子类概览
原子类的基本概念
原子类,顾名思义,就是用来进行原子操作的类。在Java中,这些类提供了一种线程安全的方式来操作单个变量,无需使用synchronized关键字。原子类的操作是基于CAS(Compare-And-Swap,比较并交换)机制实现的,这是一种轻量级的同步策略,比传统的锁机制更高效。
常见的原子类
让咱们来看几个常用的原子类:
AtomicInteger:提供了一个可以原子性更新的int值。AtomicLong:和AtomicInteger类似,但它是针对long类型的。AtomicBoolean:提供了一个可以原子性更新的boolean值。AtomicReference:提供了一个可以原子性更新的对象引用。
AtomicInteger的使用示例
来看个例子,如何使用AtomicInteger:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 原子性地增加count的值
}
public int getCount() {
return count.get();
}
}
class Main {
public static void main(String[] args) {
AtomicCounter counter = new AtomicCounter();
// 模拟多线程环境
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
counter.increment();
}).start();
}
// 等待所有线程完成
try {
Thread.sleep(2000); // 等待足够长的时间以确保所有线程都执行完毕
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("最终计数: " + counter.getCount()); // 正确输出1000
}
}

在这个示例中,AtomicCounter类使用了AtomicInteger来保证count的增加操作是原子的。这就解决了之前提到的非原子操作可能导致的问题。无论多少线程同时调用increment()方法,每次调用都会安全地将count增加1。
第4章:深入探讨原子类的实现原理
CAS机制简介
CAS机制包含三个主要的操作数:内存位置(V)、预期原值(A)和新值(B)。操作的逻辑是:“我认为V应该是A,如果是,就把V更新成B,否则,不做任何操作。”这个过程是原子的,意味着在这个操作执行期间,没有其他线程可以改变这个内存位置的值。
CAS的优点和挑战
CAS的主要优点是它提供了一种无锁的方式来实现并发控制。相比于传统的锁机制,CAS通常能提供更好的性能,并减少了死锁的风险。
但CAS也有它的挑战。其中一个主要问题是“ABA问题”。如果一个变量原来是A,变成了B,然后又变回A,使用CAS的线程可能会错误地认为这个变量没有被其他线程修改过。为了解决这个问题,Java提供了AtomicStampedReference类,它通过维护一个“时间戳”来记录变量的修改次数。
CAS在AtomicInteger中的应用
来看一个具体的例子,展示AtomicInteger是如何利用CAS机制的:
public class CASExample {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
int currentValue;
int newValue;
do {
currentValue = count.get(); // 获取当前值
newValue = currentValue + 1; // 计算新值
} while (!count.compareAndSet(currentValue, newValue)); // CAS操作
// 如果当前值不等于预期值,则循环尝试,直到成功
}
public int getCount() {
return count.get();
}
}
class Main {
public static void main(String[] args) {
CASExample example = new CASExample();
// 模拟多线程环境
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
example.increment();
}).start();
}
// 等待所有线程完成
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("最终计数: " + example.getCount());
}
}
在这个例子中,increment()方法用一个do-while循环来保证增加操作的原子性。如果在执行CAS操作时,当前值不是预期值,意味着其他线程已经修改了这个值,那么循环会继续,直到成功更新。
通过这种方式,AtomicInteger确保了即使在高并发的环境下,增加操作也是原子的,保证了数据的一致性和线程安全。
第5章:原子操作与并发编程
原子操作在并发编程中的应用
在并发编程中,原子操作确保了当多个线程尝试同时更新同一个变量时,这个变量的值不会丢失或者损坏。这对于维护数据的一致性和程序的稳定性至关重要。
案例分析
让我们通过一个具体的案例来看看原子操作是如何工作的。假设咱们需要编写一个程序,来统计一个网站的访问量。在高并访问量的情况下,可能有成百上千的用户同时访问这个网站,这时就需要一个能够安全地处理多线程并发访问的计数器。
使用非原子操作的计数器可能会导致一些访问量丢失,因为当多个线程同时读取和更新计数器的值时,一些更新可能会被覆盖。而使用原子操作的计数器可以确保每次访问都被准确地记录。
import java.util.concurrent.atomic.AtomicInteger;
public class WebsiteVisitsCounter {
private AtomicInteger visitsCount = new AtomicInteger();
public void visit() {
visitsCount.incrementAndGet(); // 原子操作
}
public int getTotalVisits() {
return visitsCount.get();
}
}
class Main {
public static void main(String[] args) {
WebsiteVisitsCounter counter = new WebsiteVisitsCounter();
// 模拟1000个用户同时访问网站
for (int i = 0; i < 1000; i++) {
new Thread(counter::visit).start();
}
// 等待线程结束
try {
Thread.sleep(2000); // 假设足够的时间让所有线程执行完毕
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("总访问量: " + counter.getTotalVisits()); // 应该输出1000
}
}
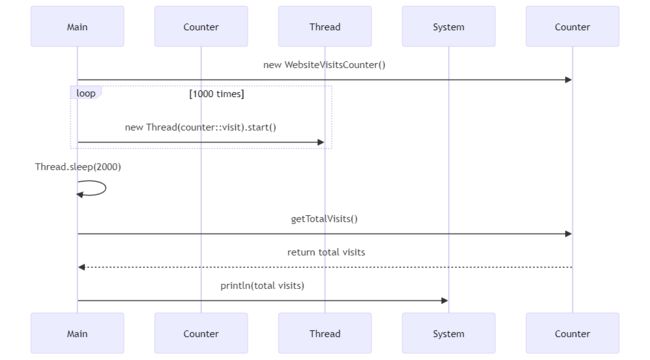
在这个例子中,WebsiteVisitsCounter使用了AtomicInteger来确保访问次数的计数是准确的,即使在高并发的情况下。每次调用visit方法都会安全地增加visitsCount,无论多少线程同时访问它。
第6章:原子类的性能考量
原子类与传统同步机制的性能比较
传统的同步机制,比如使用synchronized关键字,通过锁来控制对共享资源的访问。这种方法简单直观,但在高并发环境下可能导致性能瓶颈。原因是当一个线程持有锁时,其他所有需要这个锁的线程都必须等待,这就可能导致大量线程处于等待状态,从而降低了应用程序的整体性能。
相比之下,原子类利用CAS(Compare-And-Swap)机制来实现同步。这种机制不需要阻塞线程,因此在处理高并发数据时通常能提供更好的性能。但CAS也不是完美无缺的,特别是在高冲突环境下,频繁的CAS操作可能会导致性能下降,这种情况被称为“自旋”。
性能分析实例
让我们通过一个简单的实验来比较使用synchronized和原子类的性能差异。假设有一个简单的计数器,咱们分别用synchronized方法和AtomicInteger来实现,然后比较它们在多线程环境下的性能。
public class SynchronizedCounter {
private int count = 0;
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
}
public class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
public int getCount() {
return count.get();
}
}
在这个例子中,SynchronizedCounter使用synchronized关键字来保证计数器的线程安全,而AtomicCounter则使用AtomicInteger。如果咱们在一个高并发的环境下测试这两个计数器,通常会发现AtomicCounter的性能要优于SynchronizedCounter。原因在于synchronized会引起线程的阻塞和唤醒,而AtomicInteger利用CAS实现非阻塞的同步。
第7章:原子类的高级用法
AtomicReference的使用
AtomicReference类提供了一种方式来原子性地更新对象引用。这意味着咱们可以安全地在多线程环境中更改对象引用,而无需担心线程安全问题。
来看一个AtomicReference的例子:
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceExample {
private AtomicReference<String> currentSetting = new AtomicReference<>("默认设置");
public void updateSetting(String newSetting) {
currentSetting.set(newSetting);
}
public String getSetting() {
return currentSetting.get();
}
}
class Main {
public static void main(String[] args) {
AtomicReferenceExample example = new AtomicReferenceExample();
// 模拟多线程环境更新设置
new Thread(() -> example.updateSetting("自定义设置1")).start();
new Thread(() -> example.updateSetting("自定义设置2")).start();
System.out.println("当前设置: " + example.getSetting());
}
}
在这个例子中,AtomicReferenceExample类使用AtomicReference来保持currentSetting的线程安全。无论多少线程尝试更新这个设置,AtomicReference都能确保操作的原子性。
AtomicStampedReference的使用
AtomicStampedReference类是对AtomicReference的一个扩展,它解决了所谓的“ABA问题”。除了对象引用之外,AtomicStampedReference还维护了一个“时间戳”,这个时间戳在每次对象更新时都会改变。
来看一个AtomicStampedReference的例子:
import java.util.concurrent.atomic.AtomicStampedReference;
public class AtomicStampedReferenceExample {
private AtomicStampedReference<String> currentSetting =
new AtomicStampedReference<>("默认设置", 0);
public void updateSetting(String newSetting) {
int stamp = currentSetting.getStamp();
currentSetting.compareAndSet(currentSetting.getReference(), newSetting, stamp, stamp + 1);
}
public String getSetting() {
return currentSetting.getReference();
}
}
class Main {
public static void main(String[] args) {
AtomicStampedReferenceExample example = new AtomicStampedReferenceExample();
// 模拟多线程环境更新设置
new Thread(() -> example.updateSetting("自定义设置1")).start();
new Thread(() -> example.updateSetting("自定义设置2")).start();
System.out.println("当前设置: " + example.getSetting());
}
}
在这个例子中,每次更新currentSetting时,时间戳stamp都会增加。这就意味着即使一个值从A变成B再变回A,时间戳也会反映出这个变化,从而避免了ABA问题。
第8章:总结
原子操作的重要性
在多线程编程中,原子操作是确保数据一致性和线程安全的关键。通过原子类,如AtomicInteger、AtomicBoolean、AtomicReference等,Java提供了一种有效的方式来进行线程安全的操作,无需担心数据损坏或者线程冲突的问题。这对于构建高效且健壮的并发应用程序至关重要。
原子类的高效性
我们还讨论了原子类相比传统锁机制(如synchronized)在性能上的优势。特别是在高并发环境下,原子类能够提供更好的性能,减少资源的等待时间,从而提高程序的整体效率。
面临的挑战和应对策略
尽管原子操作提供了许多优势,但它们也面临着一些挑战,比如在高冲突环境下的性能问题。为了应对这些挑战,Java持续在发展中,引入了更多高级原子类,如AtomicStampedReference,来解决这些问题。