DBSCAN聚类代码实现
目录
一、引言
1.什么是DBSCAN?
2、所需库:
3、所需数据:
二、代码阶段
1、读取数据
2、提取特征
3、训练DBSCAN模型(详见:算法,函数具体参数)
4、取出标签
5、给数据加入标签一列
6、排序
7、评估模型并输出
8、运行结果:
三、总结
一、引言
1.什么是DBSCAN?
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的空间聚类算法。它是一种无监督学习算法,用于将数据点划分为不同的聚类簇,同时能够发现任意形状和大小的聚类。详见:DBSCAN
例如: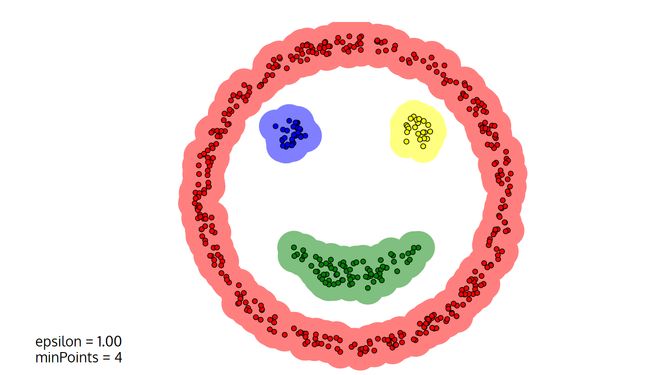
、这个图像就是DBSCAN实现的结果,分为了四个类。
2、所需库:
import pandas as pd
#导入Pandas库,并将其命名为pd,以便后续使用Pandas的功能来处理数据。
import numpy as np
#导入NumPy库,并将其命名为np,以便后续使用NumPy的数值计算功能。
from sklearn import metrics
#从Scikit-Learn库中导入metrics模块,该模块包含了各种用于度量模型性能的工具。
from sklearn.cluster import DBSCAN
#从Scikit-Learn库中导入DBSCAN聚类算法,DBSCAN是一种密度聚类算法。3、所需数据:
data.txt的数据为:
name calories sodium alcohol cost
Budweiser 144 15 4.7 0.43
Schlitz 151 19 4.9 0.43
Lowenbrau 157 15 0.9 0.48
Kronenbourg 170 7 5.2 0.73
Heineken 152 11 5.0 0.77
Old_Milwaukee 145 23 4.6 0.28
Augsberger 175 24 5.5 0.40
Srohs_Bohemian_Style 149 27 4.7 0.42
Miller_Lite 99 10 4.3 0.43
Budweiser_Light 113 8 3.7 0.40
Coors 140 18 4.6 0.44
Coors_Light 102 15 4.1 0.46
Michelob_Light 135 11 4.2 0.50
Becks 150 19 4.7 0.76
Kirin 149 6 5.0 0.79
Pabst_Extra_Light 68 15 2.3 0.38
Hamms 139 19 4.4 0.43
Heilemans_Old_Style 144 24 4.9 0.43
Olympia_Goled_Light 72 6 2.9 0.46
Schlitz_Light 97 7 4.2 0.47
二、代码阶段
1、读取数据
beer = pd.read_table('data.txt',sep=' ',encoding='utf8',engine='python')
#数据的分隔符sep为空格,使用UTF-8编码(encoding)进行解码。函数从名为'data.txt'的文件中读取数据,并将结果存储在名为beer的DataFrame中。数据的分隔符为空格,使用UTF-8编码进行解码。
2、提取特征
X=beer[['calories','sodium','alcohol','cost']]
#取出名为'calories','sodium','alcohol','cost'四列从beer中选择'calories'、'sodium'、'alcohol'和'cost'这四列作为特征,存储在名为X的DataFrame中
3、训练DBSCAN模型(详见:算法,函数具体参数)
db=DBSCAN(eps=20,min_samples=3).fit(X)
#创建参数半径为20,密度为3的DBSCAN模型,并训练使用DBSCAN算法进行聚类,设置参数eps=20和min_samples=3,并将X数据拟合到模型中。
4、取出标签
labels=db.labels_#获取标签
获取聚类的标签,存储在名为labels的数组中。
5、给数据加入标签一列
beer['cluster']=labels
#加入标签列
将聚类标签列添加到beer的DataFrame中,命名为'cluster'。
6、排序
beer.sort_values('cluster')
#按cluster列排序对beer DataFrame按'cluster'列进行排序(这里需要注意,排序操作并没有在原地进行,需要将其结果赋值给一个变量)。
7、评估模型并输出
score=metrics.silhouette_score(X,beer.cluster)
#计算数据X的轮廓系数得分
print(score)
#输出轮廓系数得分使用metrics.silhouette_score()函数计算数据X的轮廓系数得分,传入聚类标签列beer.cluster作为参数,并将轮廓系数得分打印出来。
8、运行结果:
![]()
三、总结
这段代码主要完成了对数据的聚类操作,并计算了聚类结果的轮廓系数得分。轮廓系数用于衡量聚类结果的紧密度和分离度,得分越接近1表示聚类效果越好。