kettle的基本介绍和使用
1、 kettle概述
1.1 什么是kettle
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
1.2 Kettle核心知识点
1.2.1 Kettle工程存储方式
- 以XML形式存储
- 以资源库方式存储(数据库资源库和文件资源库)
1.2.2 Kettle的两种设计
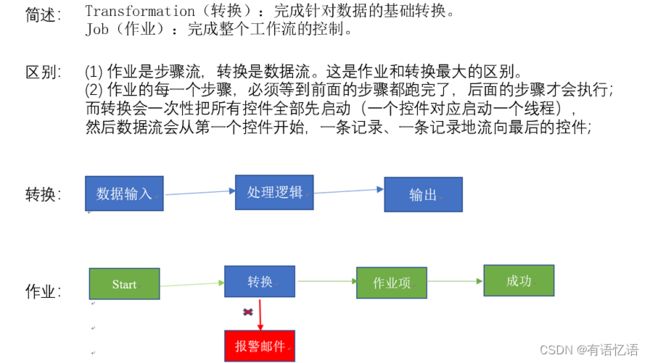
1.2.3 Kettle的组成

1.3 kettle特点

2、 kettle安装部署和使用
2.1 kettle安装地址
官网地址
https://community.hitachivantara.com/docs/DOC-1009855
下载地址
https://sourceforge.net/projects/pentaho/files/Data%20Integration/
2.2 Windows下安装使用
2.2.1 概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
2.2.2 安装
- 安装jdk
- 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
- 双击Spoon.bat,启动图形化界面工具,就可以直接使用了
2.2.3 案例
- 案例一 把stu1的数据按id同步到stu2,stu2有相同id则更新数据
(1)在mysql中创建两张表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
(2)往两张表中插入一些数据
mysql> insert into stu1 values(1001,‘zhangsan’,20),(1002,‘lisi’,18), (1003,‘wangwu’,23);
mysql> insert into stu2 values(1001,‘wukong’);
(3)在kettle中新建转换
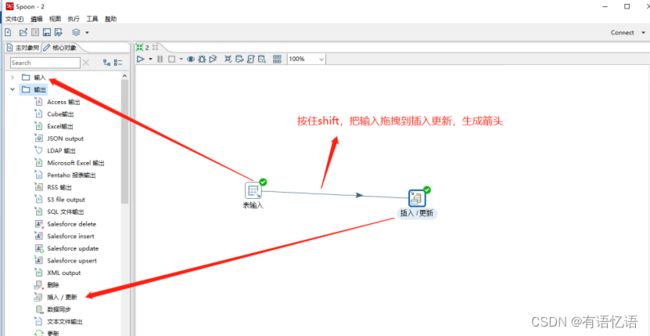
(4)分别在输入和输出中拉出表输入和插入/更新
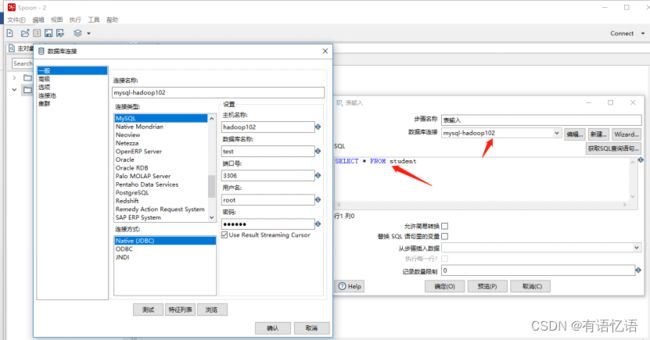
(5)双击表输入对象,填写相关配置,测试是否成功
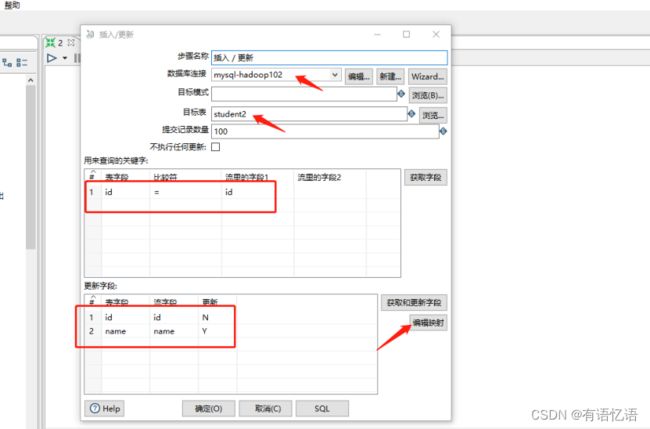
(6)双击 更新/插入对象,填写相关配置
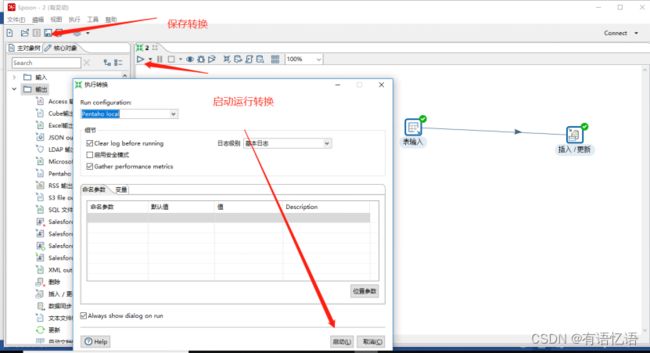
(7)保存转换,启动运行,去mysql表查看结果
注意:如果需要连接mysql数据库,需要要先将mysql的连接驱动包复制到kettle的根目录下的lib目录中,否则会报错找不到驱动。
- 案例2:使用作业执行上述转换,并且额外在表student2中添加一条数据
(1)新建一个作业
(2) 按图示拉取组件
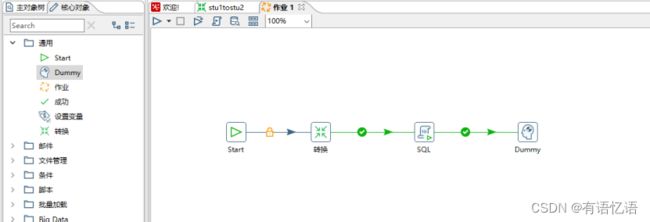
(3)双击Start编辑Start
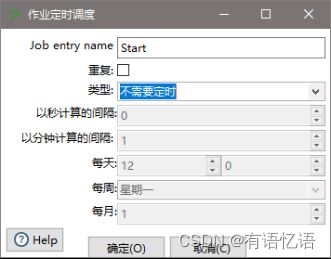
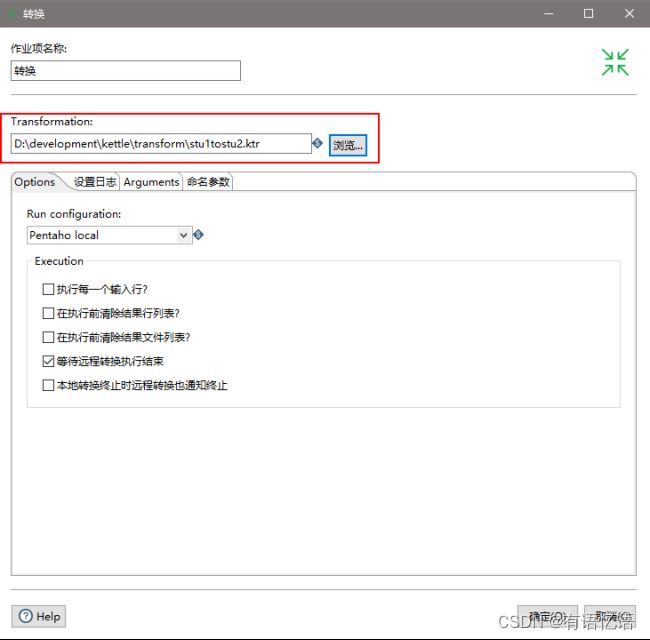
(4)双击转换,选择案例1保存的文件
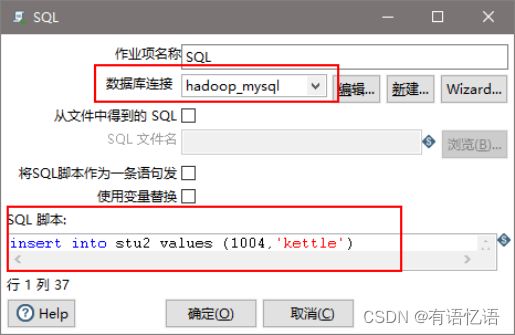
(5)双击SQL,编辑SQL语句
(6)保存执行
3)案例3:将hive表的数据输出到hdfs
(1)因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
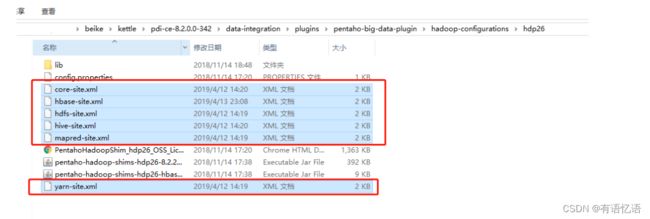
(2)启动hdfs,yarn,hbase集群的所有进程,启动hiveserver2服务
[ybb@hadoop102 ~]$ /opt/module/hadoop-2.7.2/sbin/start-all.sh
开启HBase前启动Zookeeper
[ybb@hadoop102 ~]$ /opt/module/hbase-1.3.1/bin/start-hbase.sh
[ybb@hadoop102 ~]$ /opt/module/hive/bin/hiveserver2
(3)进入beeline,查看10000端口开启情况
[ybb@hadoop102 ~]$ /opt/module/hive/bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000(回车)
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: ybb(输入ybb)
Enter password for jdbc:hive2://hadoop102:10000:(直接回车)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000>(到了这里说明成功开启10000端口)
(4)创建两张表dept和emp
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
(5)插入数据
insert into dept values(10,'accounting','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON');
insert into emp values
(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),
(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),
(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),
(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
(6)按下图建立流程图
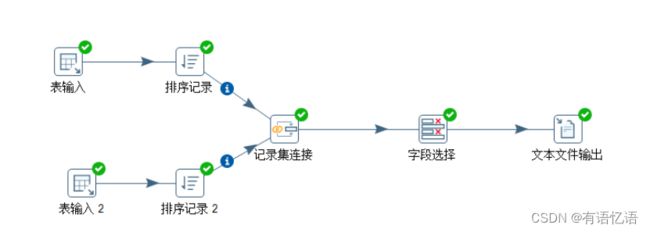
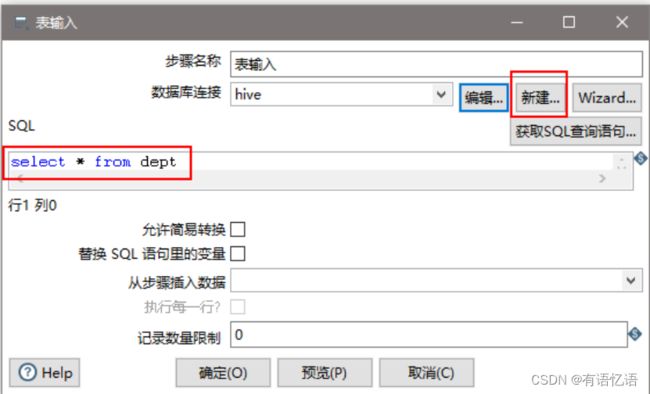
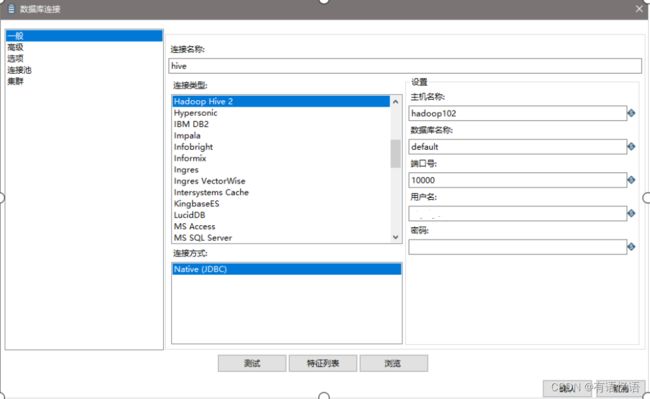
(7)设置表输入,连接hive
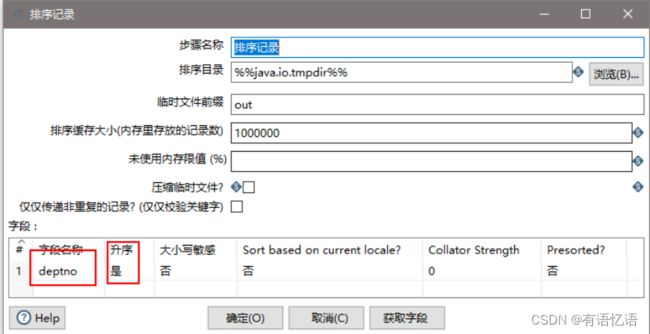
(8)设置排序属性
(9)设置连接属性
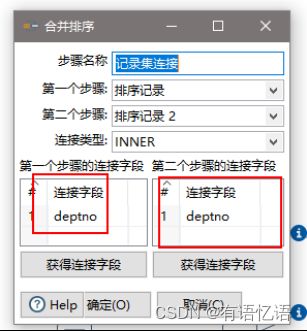
(10)设置字段选择
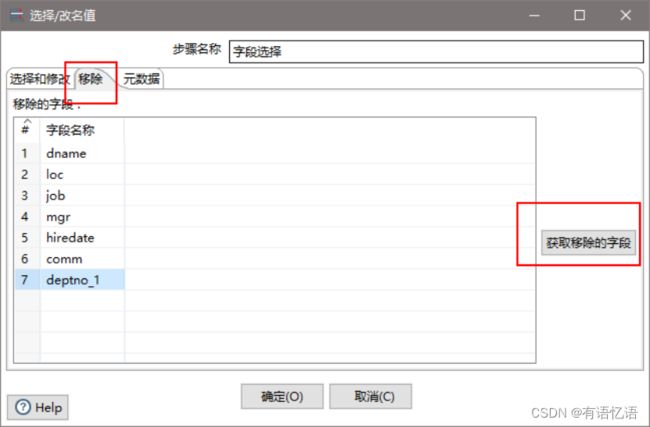
(11)设置文件输出
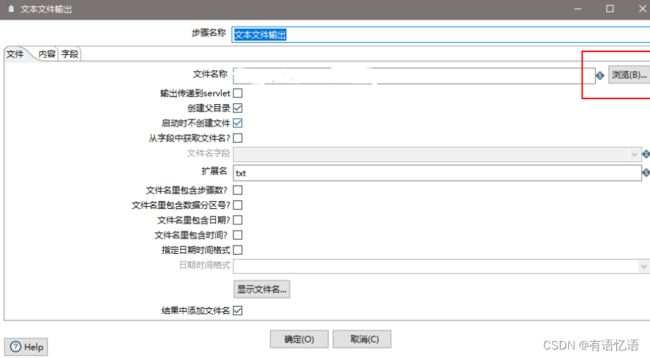
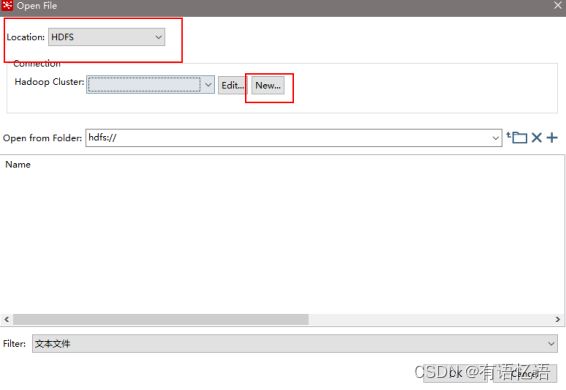
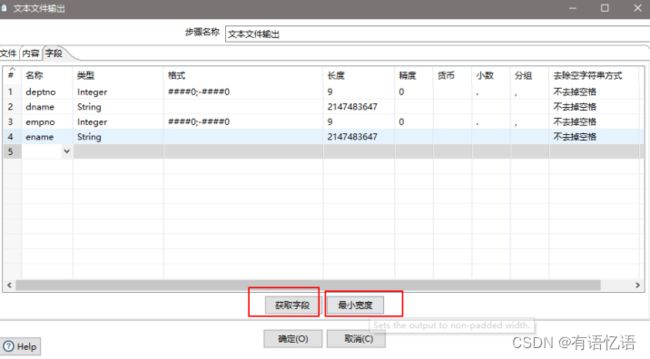
(12)保存并运行查看hdfs
2.3 创建资源库
2.3.1 数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,很容易跨平台使用
1)点击右上角connect,选择Other Resporitory

2) 选择Database Repository
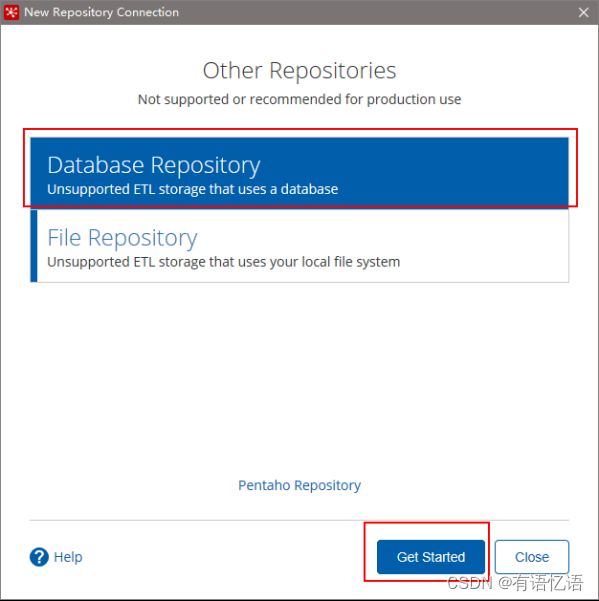
3) 建立新连接
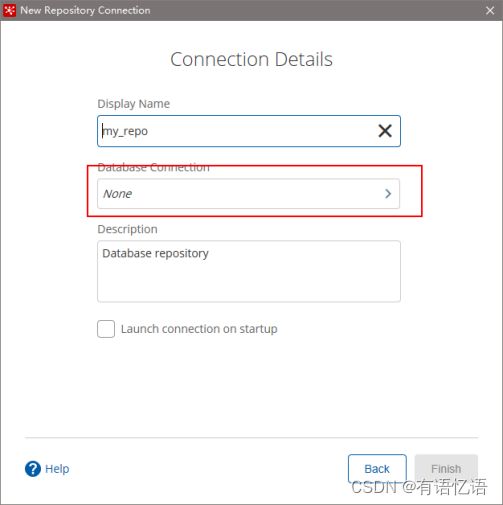
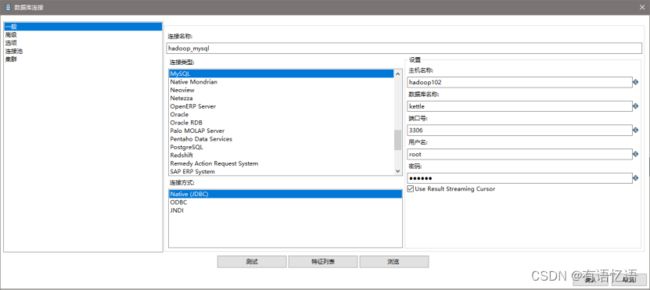
4) 填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成
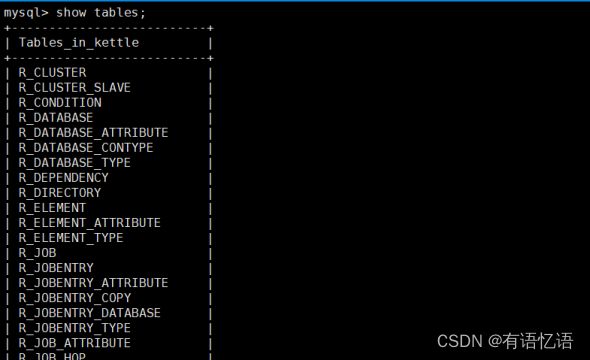
5) 连接资源库
默认账号密码为admin
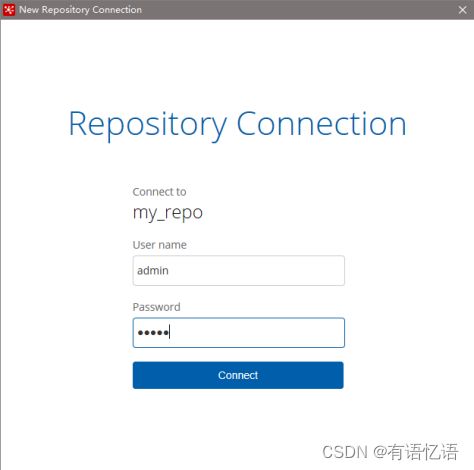
6) 将之前做过的转换导入资源库
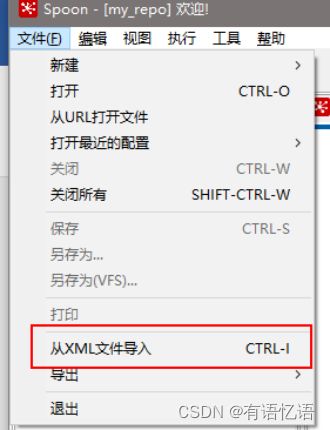
(1)选择从xml文件导入
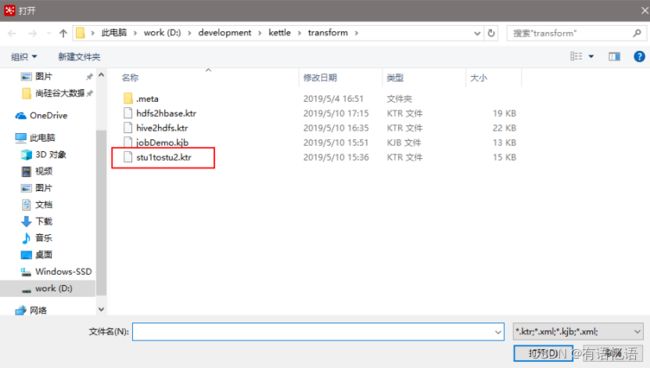
(2)随便选择一个转换
(3)点击保存,选择存储位置及文件名
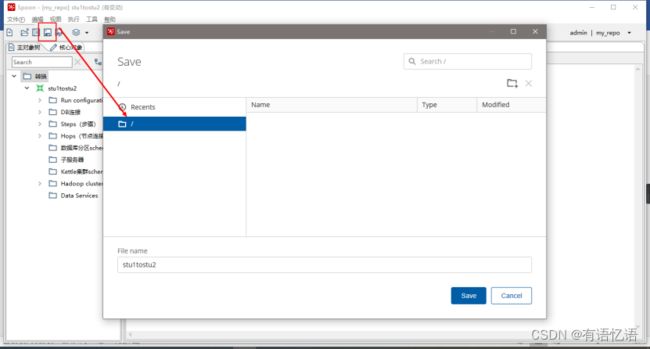
(4)打开资源库查看保存结果
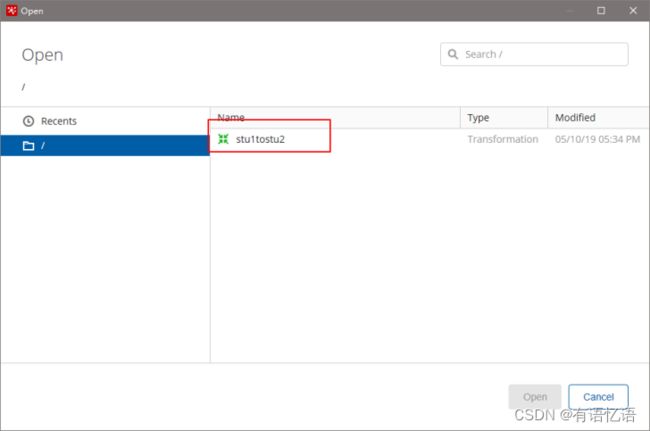
2.3.2 文件资源库
将作业和转换相关的信息存储在指定的目录中,其实和XML的方式一样
创建方式跟创建数据库资源库步骤类似,只是不需要用户密码就可以访问,跨
平台使用比较麻烦
1)选择connect
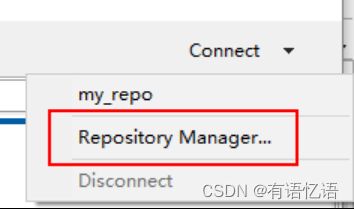
2)点击add后点击Other Repositories
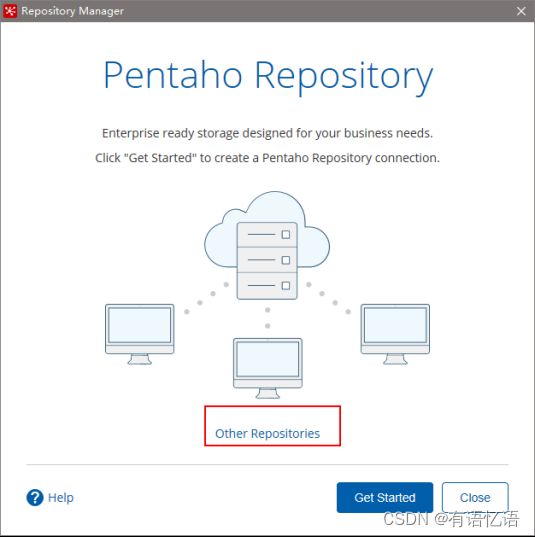
3)选择File Repository
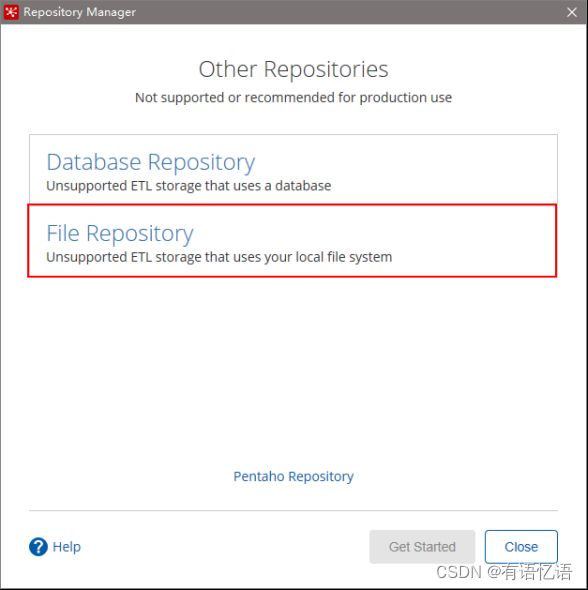
4)填写信息
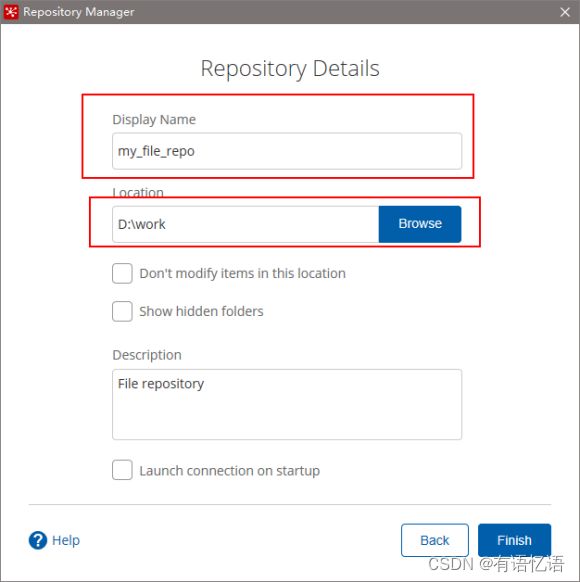
2.4 Linux下安装使用
2.4.1 单机
1)jdk安装
2)安装包上传到服务器,解压
注意:1. 把mysql驱动拷贝到lib目录下
2. 将本地用户家目录下的隐藏目录C:\Users\自己用户名.kettle,整个上传到linux的家目录/home/ybb/下
3)运行数据库资源库中的转换:
[ybb@hadoop102 data-integration]$./pan.sh -rep=my_repo -user=admin -pass=admin -trans=stu1tostu2 -dir=/
参数说明:
-rep 资源库名称
-user 资源库用户名
-pass 资源库密码
-trans 要启动的转换名称
-dir 目录(不要忘了前缀 /)
4)运行资源库里的作业:
记得把作业里的转换变成资源库中的资源
[ybb@hadoop102 data-integration]$./kitchen.sh -rep=repo1 -user=admin -pass=admin -job=jobDemo1 -logfile=./logs/log.txt -dir=/
参数说明:
-rep - 资源库名
-user - 资源库用户名
-pass – 资源库密码
-job – job名
-dir – job路径
-logfile – 日志目录
2.4.2 集群模式
- 准备三台服务器,hadoop102作为Kettle主服务器,服务器端口号为8080,hadoop103和hadoop104作为两个子服务器,端口号分别为8081和8082。
- 安装部署jdk
- hadoop完全分布式环境搭建,并启动进程(因为要使用hdfs)
- 上传解压kettle的安装包
- 进到/opt/module/data-integration/pwd目录,修改配置文件
修改主服务器配置文件carte-config-master-8080.xml
master</name>
hadoop102</hostname>
8080</port>
Y</master>
cluster</username>
cluster</password>
</slaveserver>
修改从服务器配置文件carte-config-8081.xml
master</name>
hadoop102</hostname>
8080</port>
cluster</username>
cluster</password>
Y</master>
</slaveserver>
</masters>
Y</report_to_masters>
slave1</name>
hadoop103</hostname>
8081</port>
cluster</username>
cluster</password>
N</master>
</slaveserver>
修改从配置文件carte-config-8082.xml
master</name>
hadoop102</hostname>
8080</port>
cluster</username>
cluster</password>
Y</master>
</slaveserver>
</masters>
Y</report_to_masters>
slave2</name>
hadoop104</hostname>
8082</port>
cluster</username>
cluster</password>
N</master>
</slaveserver>
-
分发整个kettle的安装目录,xsync data-integration
-
启动相关进程,在hadoop102,hadoop103,hadoop104上执行
[ybb@hadoop102 data-integration] . / c a r t e . s h h a d o o p 1028080 [ y b b @ h a d o o p 103 d a t a − i n t e g r a t i o n ] ./carte.sh hadoop102 8080 [ybb@hadoop103 data-integration] ./carte.shhadoop1028080[ybb@hadoop103data−integration]./carte.sh hadoop103 8081
[ybb@hadoop104 data-integration]$./carte.sh hadoop104 8082 -
访问web页面
http://hadoop102:8080 -
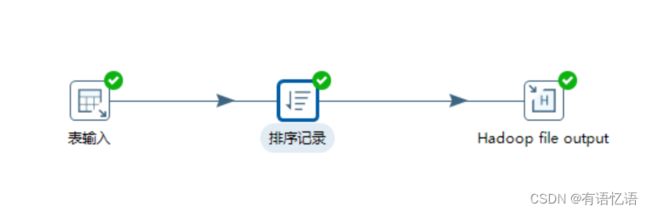
案例:读取hive中的emp表,根据id进行排序,并将结果输出到hdfs上
注意:因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
(1) 创建转换,编辑步骤,填好相关配置
(2) 创建子服务器,填写相关配置,跟集群上的配置相同
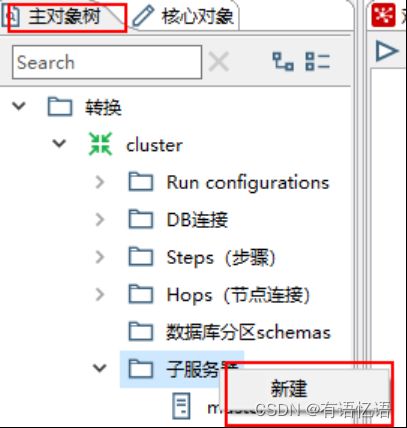
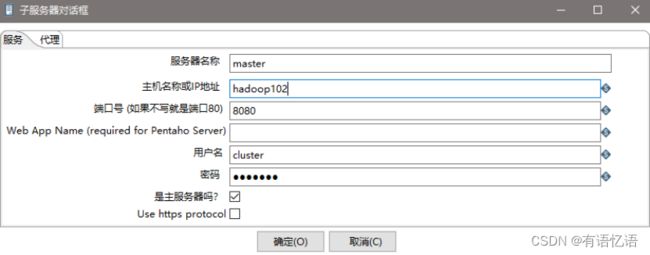
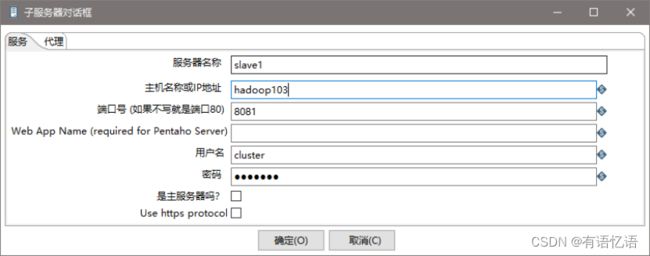
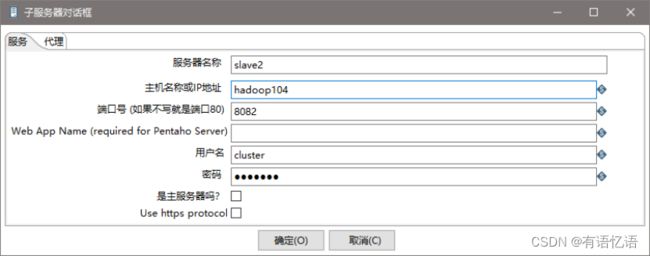
(3) 创建集群schema,选中上一步的几个服务器
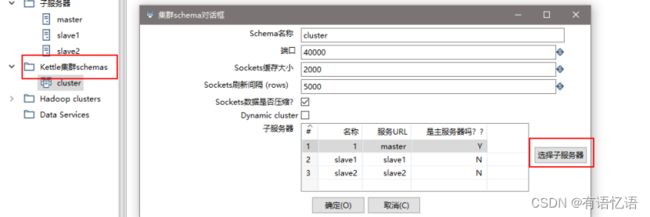
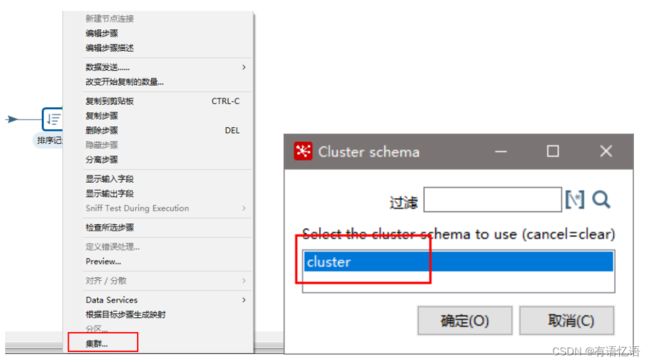
(4) 对于要在集群上执行的步骤,右键选择集群,选中上一步创建的集群schema
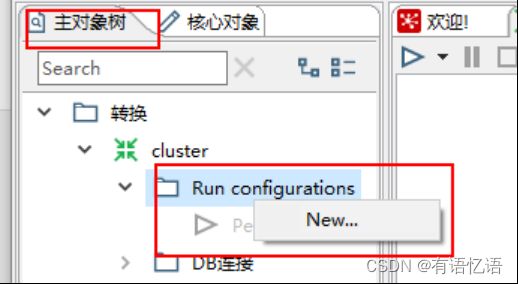
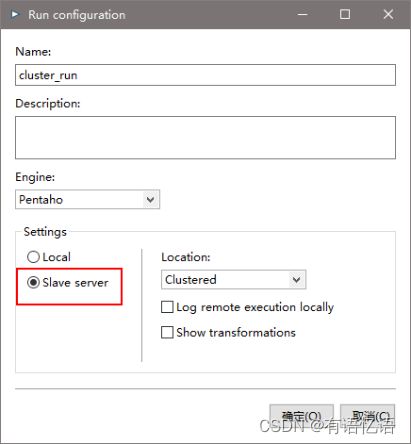
(5) 创建Run Configuration,选择集群模式,直接运行
3、 调优
1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。

参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池;
4、尽量提高批处理的commit size;
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
7、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)。