基于深度学习的篮球战术数据自动采集技术研究——项目展示
1 项目背景
篮球运动除了需要统计如2分投中、2分投篮、3分投中、3分投篮、扣篮、助攻、盖帽、抢断、失误、犯规和得分等技术信息,还需要统计战术信息。现在统计工作大多数是通过手工完成的,这样的统计方式存在着一些缺点,如统计速度比较慢、统计的信息不全面、只能够统计一些简单信息、无法统计出每一次进攻或防守中球员的运动路线和篮球落点等。除了统计技战术数据外,教练员和运动员有时候还需要通过观看某个球队的某一场比赛或者某几场比赛的视频来分析对手的技战术特点。例如,通常情况下,一场比赛之后教练员和队员会反复地观看比赛视频,来发现球队在比赛中的不足之处,同时球队会 对视频进行非线性的编辑。赛后对比赛视频进行非线性编辑需要花费时间,缺乏时效性。
截至目前已有很多的专家学者展开了对篮球视频事件检测和标注工作的研究,产生许多不同的思路。从最初听觉、视觉、文本等单一模态的特征分析方法,到多模态特征结合的视频分析方法;从结合领域特征的检测方法,到利用通用模型的检测方法,篮球视频事件检测技术得到了极大的发展。
为了采集的技战术信息更加全面,为了编辑视频花费更少的时间和更具有时效性,本课题需要研究篮球比赛技战术采集系统。同时需要结合深度学习技术,对运动视频预处理,包括分帧操作、重采样操作等,做到对篮球运动员和篮球定位技术及跟踪;针对视频中篮球运动员的移动特点设计深度学习网络,完成运动员和篮球的定位;在多个视频帧中确定篮球运动员和篮球的运动轨迹,完成运动动作分类识别技术;基于深度学习对跟踪后的序列目标数据进行分类,确定该目标当前进行的动作的类型;做到战术数据自动采集,对当前时间段每个运动员的动作进行统计;最后生成相应的统计分析结果并可视化这些结果。
针对以上要求,本课题将项目需求划分为多个模块,并采取了合理的技术路线,最后能够实现既定的目标。
2 技术路线
2.1 模块化规定
针对项目需求,将整个流程划分为六大模块,模块设计如下:
(1)数据集构建
(2)目标检测设计
(3)多目标跟踪设计
(4)行为识别设计
(5)综合实现针对视频流的球员动作识别
(6)篮球战术数据指标统计可视化
划分模块后,针对每个模块提出最优技术路线解决模块问题,最后综合所有模块形成完整技术路线,完成项目任务。
2.2 技术路线及要求
2.2.1 数据集构建
技术路线:基于PYQT5搭建人机交互性友好的人工标注数据集平台
要求:1.使人工标注更加高效。2. 能够有效管理数据集组织3.导出的数据集能够用于后续模型的训练。
2.2.2 目标检测设计
技术路线:基于pytotch平台搭建yolov5网络模型
要求:
(1)训练要求:能够基于模块1数据集构建的标注文件进行训练,生成权重文件,精度应达到98%以上。
(2)预测要求:能够对于输入而来的视频帧,检测到球员处在一帧图像上的位置并标记。
2.2.3 多目标跟踪设计
技术路线:基于pytorch平台搭建DeepSort网络模型
要求:
(1)训练要求:能够基于模块1数据集构建的标注文件和模块2的目标检测权重文件进行训练,生成权重文件,精度应达到98%以上。
(2)预测要求:能够对于输入而来的视频流,持续跟踪到视频上各个球员的位置并维持球员的id。
2.2.4 行为识别设计
技术路线:基于pytorch平台搭建SlowFast网络模型
要求:
(1)训练要求:能够基于构建好的ava数据集训练,生成权重文件。
(2)预测要求:能够对于输入而来的视频流,间断性的识别出球员的动作信息。
2.2.5 综合实现针对视频流的球员动作识别
技术路线:基于pytorch平台搭建综合Yolov5,DeepSort,SlowFast网络模型。能够持续跟踪球员位置并维持id,识别出动作信息。
要求:能够持续跟踪球员位置并维持id,识别出动作信息。
2.2.6 篮球战术数据指标统计可视化
技术路线:基于PYQT5搭建篮球战术数据指标统计平台
要求:对于输入而来的动作识别视频,能够实现战术数据指标的自动统计及可视化。
2.3 创新点分析
(1)本项目的完整技术路线如图2-1所示:
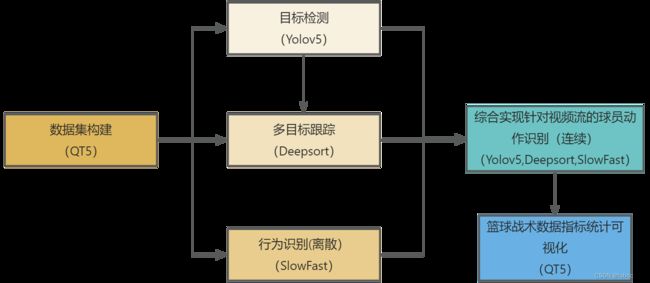
图2-1 技术路线
(2)创新点分析
基于完整技术路线的创新点分析如图3-2所示:
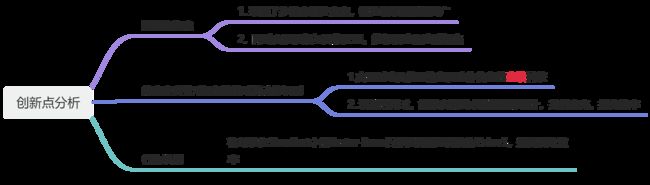
图2-2 创新点分析
3 多模块分析
3.1 数据集构建
3.1.1 前言
构建的数据集是能够实现训练后续模块的基石,所以构建一个符合训练格式的数据集尤为重要。经考察,目前的有关检测,跟踪,行为识别的篮球视频数据集很少,并且现有的标注软件难以有效构建出合理的数据集。综上,本项目利用PYQT5[1]开发了一款自由度高,贴合训练要求,适应多模态的人工数据集标注软件。
3.1.2 基于PYQT5搭建篮球视频标注软件
标注软件共分为两个模块,(1)视频抽帧模块(2)标注模块
(1)视频抽帧模块:
功能描述:用于对输入的视频进行抽帧处理,获取多帧图片,用于数据集的标注。如图3-1

图3-1 视频抽帧模块
(2)标注模块:
功能描述:用于对视频抽帧界面输入而来的图片进行数据集标注,最后导出原始input.csv文件(包含动作信息和位置信息),用于模型训练。如图3-2
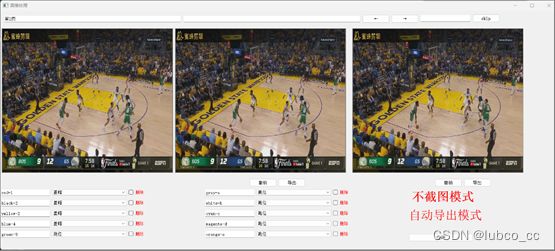
图3-2 标注模块
3.1.3 数据集构建结果
标注完成后,可得到得到原始的input.csv文件,由此可以导出后续模块所需要的xml文件,ava数据集格式文件等训练文件。
Input.csv文件如图3-3:

图3-3 input.csv文件
对文件格式的解释如下:
第1列video_name:记录了标注视频的编号;视频命名格式为xxxx_1.mp4,_ 后面为视频编号;第2列frame_id: 记录了图片的帧数第3-6列x1,y1,x2,y2:记录了框的位置坐标;第7列action_id:记录了动作对应的id;第8列persion_id: 记录了人员标签。
后续如何基于csv格式下的原始数据集形成各个模块所需要的数据集见博客地址[2]
视频演示:
数据集构建
3.2 目标检测[3]设计
3.2.1 前言
有了数据集,首先就是进行目标检测任务。开始是基于Faster-Rcnn[4]来做的,后续发现Faster-Rcnn对比Yolov5[5]在速度上明显处于劣势,为了保证效率,于是采取了Yolov5模型进行训练。
3.2.2 Yolov5模型介绍
模型结构大致如图3-4

图3-4 整体结构
Backbone可以被称作YoloV5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet,输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN可以被称作YoloV5的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV5里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
Yolo Head是YoloV5的分类器与回归器,通过CSPDarknet和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。与以前版本的Yolo一样,YoloV5所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YoloV5网络所作的工作就是特征提取-特征加强-预测特征点对应的物体情况。
3.2.3 基于Yolov5的球员检测
训练过程如图3-5

图3-5 训练过程
检测结果如图3-6(同一场比赛的后200帧)
图3-6 检测结果
3.2.4 检测指标分析
训练mAP值如图3-7所示:

图3-7 Yolov5训练指标
最终map值在0.98左右收敛,所以训练到155代便提前结束(蓝线为本次训练的map变化,黑线是上一次训练的结果)
同样对比Faster-Rcnn训练到155代,如图3-8:

图3-8 Faster-Rcnn MAP值
通过控制变量实验发现yolov5和faster-rcnn在同样训练100张图片,世代为155代的情况下,yolov5在精度和时间效率上的表现都要好于faster-rcnn。
3.3 多目标跟踪[6]设计
3.3.1 前言
在进行完目标检测后,获得了目标检测的权重文件。我们可以输入权重文件信息和数据集及与训练权重,完成多目标跟踪训练任务。并在最后能够对输入的一段篮球视频,对多个球员的位置进行持续跟踪,并维持他们的id。
目前篮球视频的多目标跟踪存在以下问题:
1.形态变化:姿态变化是目标跟踪中常见的干扰问题。运动目标发生姿态变化时, 会导致它的特征以及外观模型发生改变, 容易导致跟踪失败。
2.尺度变化:尺度的自适应也是目标跟踪中的关键问题。当目标尺度缩小时, 由于跟踪框不能自适应跟踪, 会将很多背景信息包含在内, 导致目标模型的更新错误:当目标尺度增大时, 由于跟踪框不能将目标完全包括在内, 跟踪框内目标信息不全, 也会导致目标模型的更新错误。因此, 实现尺度自适应跟踪是十分必要的。
3.遮挡与消失:目标在运动过程中可能出现被遮挡或者短暂的消失情况。当这种情况发生时, 跟踪框容易将遮挡物以及背景信息包含在跟踪框内, 会导致后续帧中的跟踪目标漂移到遮挡物上面。若目标被完全遮挡时, 由于找不到目标的对应模型, 会导致跟踪失败。
4.图像模糊:照强度变化, 目标快速运动, 低分辨率等情况会导致图像模型, 尤其是在运动目标与背景相似的情况下更为明显。因此, 选择有效的特征对目标和背景进行区分非常必要。
本项目采用了deepsort网络模型,可以较为有效的解决上述问题。
3.3.2 DeepSort[7]模型介绍
DeepSort模型大致如图3-9所示:
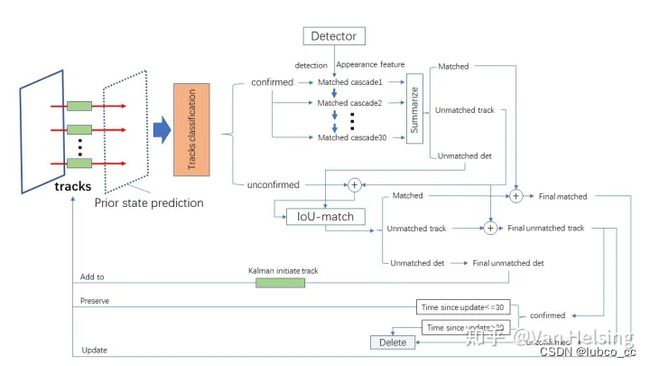
图3-9 DeepSort模型
Deepsort是对于sort的思想,进行的改进算法。SORT算法使用简单的卡尔曼滤波处理逐帧数据的关联性以及使用匈牙利算法进行关联度量,这种简单的算法在高帧速率下获得了良好的性能。但由于SORT忽略了被检测物体的表面特征,因此只有在物体状态估计不确定性较低是才会准确,在Deep SORT中,使用了更加可靠的度量来代替关联度量,并使用CNN网络在大规模行人数据集进行训练,并提取特征,已增加网络对遗失和障碍的鲁棒性。
Deepsort工作流程大致如下:
检测器得到bbox → 生成detections → 卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新。
3.3.3 基于DeepSort的多球员跟踪
跟踪情况如图3-10所示:
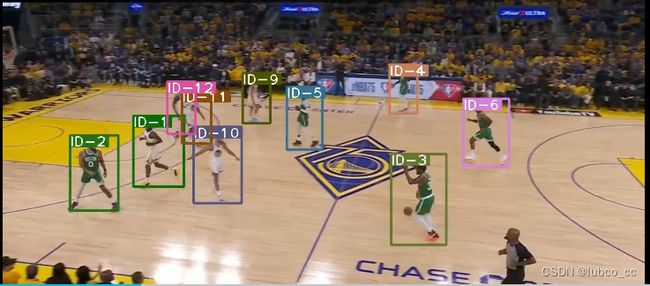
图3-10 跟踪结果
3.3.4 跟踪指标分析
当训练精确度接近于99%时,可以终止训练,得到多目标跟踪权重文件。

图3-11 指标分析
指标分析:由于Deepsort使用的是基于目标检测的方式,多目标跟踪的好坏与目标检测的情况息息相关。所以想要有一个好的多目标跟踪结果,首先需要一个训练效果好的目标检测结果。
视频演示:
篮球视频分析————多目标检测结果
3.4 行为识别设计
3.4.1 前言
要对球员的战术数据进行统计,首先要能够识别球员的动作。本设计采取SlowFast[8]模型,FAIR的pytorchvideo框架结合目标检测和行为分类(Faster R-CNN+SlowFast)实现了行为检测,能够针对输入而来的视频对各个球员的动作信息进行识别。
本项目规定了要识别的动作主要有:
1.观察(observe):指场上球员弯腰(bend)观察场上情况,寻找机会。
2.传球(pass):球员之间传递篮球
3.防守(defense):防守方对持球人员进行阻拦
4.进攻(attack):持球人员通过运球突破防守发起进攻
5.跑位(positioning):在球场上通过运动来寻找机会,跑到有利位置
6.站位(stand):球员在球场上占据一定的位置静止,等待球权或做挡拆动作
7.投篮(shoot):持球人员做投篮动作
3.4.2 SlowFast模型介绍
slowfast网络可以被描述为以两种不同帧速率运行的单流体系结构,但我们使用路径的概念来反映与生物中的Parvo-和Magnocellular对应物的类比。我们的通用架构有一条slow pathway和fast pathway,fast pathway通过横向连接至slow pathway 融合形成slowfast网络。
模型包括:
(1)一条slow pathway,以低帧速率运行,以捕获空间语义;
(2)一条fast pathway,以高帧速率运行,以精细的时间分辨率捕获运动。
fast pathway可以通过减少通道容量而变得非常轻量,但可以学习有用的时间信息用于视频识别。模型在视频动作分类和检测方面都取得了较好的性能,我们的slowfast概念针对性能有很大的改进。并在Kinetics,Charades和AVA等基准上取得了最好的效果。
模型图如3-12所示:
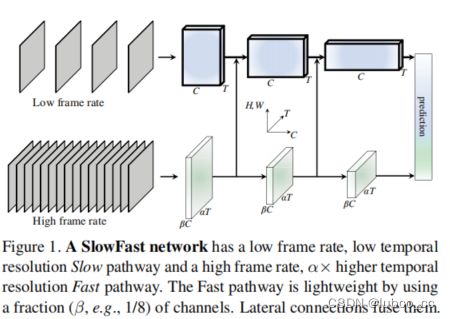
图3-12 slowfast模型
3.4.3 基于SlowFast的球员行为识别
识别结果如下图3-12所示:

图3-13 行为识别信息
视频演示:
篮球战术采集——行为识别检测结果
可以发现,在识别过程中,裁判员和观众的动作也识别了进去,这与Faster-Rcnn目标检测有关。说明目标检测过程的效果并不理想。同时,对于传球与投篮的信息很难识别出来,所以对于快速运动的视频行为识别,需要采用多目标跟踪模式,来使行为类别信息的更加饱满,使动作更易于区分。
3.5 综合实现针对视频流的球员动作识别
3.5.1 前言
FAIR的pytorchvideo框架结合目标检测和行为分类(Faster R-CNN+SlowFast)实现了行为检测,不过pytorchvideo框架下的目标检测框架是其自带的detectron2工具下的Faster R-CNN,速度较慢,且行为检测是不连续的(其将视频分为一小段clip,分别进行行为检测,没有追踪),基于此,我们进行了以下两点改进:
1.利用yolov5替代原生的Faster R-CNN,达到基本实时的处理速度
2.利用追踪,将物体前后类别联系起来,行为类别信息更加饱满(行为类别从离散到连续)
综上,本项目综合yolov5,deepsort,slowfast实现连续性动作识别,使识别效果与可视化程度大大提高。
3.5.2 综合Yolov5,DeepSort,SlowFast实现动作识别
动作识别(截图)如3-13:

图3-14 动作识别(连续)
视频演示:
篮球视频分析yolov5+deepsort+slowfast
3.5.3 识别指标分析
由于训练的数据集数目仍然太小(仅700张图片信息),所以采取前后200帧视频进行动作识别,发现识别效果良好。但存在传球,投篮动作识别不出的问题。分析如下:1.由于传球,投篮的动作过快,导致模型无法识别。2.传球,投篮的数据集过少,学习的效果不够明显。3.网络模型需要优化,加深网络结构。
3.6 篮球战术数据指标统计可视化
3.6.1 基于PYQT5搭建篮球战术数据指标统计可视化平台
篮球战术数据指标统计可视化平台如图3-14:
图3-15 篮球战术数据指标统计可视化平台
视频演示:
篮球战术数据自动采集界面