毕业设计:基于深度学习的人脸识别考勤签到系统 人工智能 python CNN
目录
前言
课题背景和意义
实现技术思路
一、 算法理论基础
1.1 人脸识别算法
1.2 卷积神经网络
二、 数据集
三、实验及结果分析
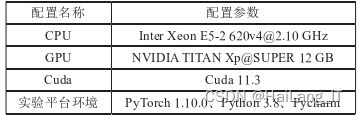
3.1 实验环境搭建
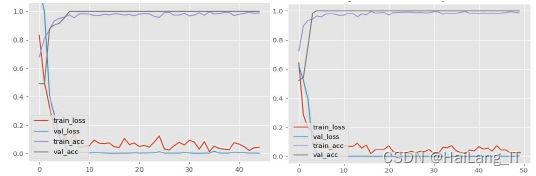
3.2 模型训练
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
基于深度学习的人脸识别考勤签到系统
课题背景和意义
传统的考勤签到系统通常采用卡片、指纹等方式进行身份验证,但这些方法存在易被冒用、漏识等问题。而随着深度学习技术的快速发展,人脸识别作为一种高效、准确且非侵入性的身份验证方法,逐渐引起了广泛关注。可以有效防止他人冒用他人身份进行签到,点,能够实现快速签到并记录考勤数据,提高工作效率,减少人力成本。
实现技术思路
一、 算法理论基础
1.1 人脸识别算法
神经网络可以通过学习的过程自动进行特征学习,不需要依赖人工设计的特征。神经网络通过多层神经元的连接和权重调整,可以从大量的训练数据中学习到人脸的抽象特征表示。这种隐性表达能力使得神经网络能够更好地捕捉人脸图像中的细微特征和上下文信息,从而提高人脸识别的准确性和鲁棒性。

人脸识别领域的规律和规则往往难以直接概念化或定义,也缺乏明确的公理公式。传统的方法往往需要基于先验知识和经验来建立模型和规则,而神经网络方法则不需要对这些规律进行明确的定义。神经网络可以通过学习大量的数据样本来自动发现和学习这些规律的隐性表达,从而实现更加灵活和准确的人脸识别。
相关代码示例:
import torch
import torch.nn as nn
# 神经网络模型
class FaceRecognitionModel(nn.Module):
def __init__(self):
super(FaceRecognitionModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(128 * 56 * 56, 256)
self.fc2 = nn.Linear(256, num_classes)
def forward(self, x):
x = nn.ReLU()(self.conv1(x))
x = nn.ReLU()(self.conv2(x))
x = x.view(x.size(0), -1)
x = nn.ReLU()(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = FaceRecognitionModel()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(num_epochs):
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练信息
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, loss.item()))
# 在测试集上评估模型
with torch.no_grad():
outputs = model(test_inputs)
_, predicted = torch.max(outputs.data, 1)
accuracy = (predicted == test_labels).sum().item() / test_labels.size(0)
print('Test Accuracy: {:.2f}%'.format(accuracy * 100))1.2 卷积神经网络
卷积神经网络(CNN)在人脸识别中的设计包括输入层接收人脸图像,通过卷积层提取局部特征,使用激活函数引入非线性特征,池化层减小特征图的空间维度,批归一化层稳定模型训练,全连接层连接卷积层输出进行分类,Softmax层输出类别概率,使用交叉熵损失函数进行优化训练。通过大规模数据集训练和梯度下降等优化算法,卷积神经网络能够自动学习人脸特征表示,提高人脸识别的准确性和鲁棒性。

在人脸识别系统中,ReLU激活函数被广泛用于提取人脸图像的非线性特征,通过引入非线性表示,解决梯度消失问题,提高计算效率和网络的鲁棒性。其激活值的稀疏性和可解释性也对于结果解释和模型分析非常有帮助。

最大值池化(Max Pooling)是一种常用的池化操作,用于减小特征图的空间维度。最大值池化将特征图划分为不重叠的区域,对每个区域取最大值作为池化后的值。这种操作能够保留最显著的特征,降低特征图的维度,减少模型的计算复杂度,并且在一定程度上提高模型的平移不变性和鲁棒性。最大值池化在人脸识别中常用于提取人脸特征的局部不变性,从而增强模型对人脸图像的识别能力。

相关代码示例:
import torch
import torch.nn as nn
# 最大值池化模块
class MaxPooling(nn.Module):
def __init__(self, kernel_size):
super(MaxPooling, self).__init__()
self.pool = nn.MaxPool2d(kernel_size)
def forward(self, x):
return self.pool(x)
# 示例用法
pool = MaxPooling(kernel_size=2)
input_tensor = torch.randn(1, 3, 64, 64) # 示例输入张量,假设输入尺寸为64x64
output_tensor = pool(input_tensor)
print(output_tensor.shape) # 打印输出张量的形状二、 数据集
数据需求主要是大规模的人脸图片数据集。为此,通过整理和筛选,收集了260,000张图片,其中每个人有1,000张作为训练集,并将图片处理为224x224的RGB格式。另外,为了创建验证集,额外收集了50,000张图片,包含1,000个人,每人有50张图片。为了扩充训练数据,还对训练集图片进行了翻转。整理和总结数据集时,进行了数据预处理、标注、划分和增强等步骤,以确保数据集的一致性、多样性和准确性。这个大规模、多样化和准确标注的人脸图片数据集将为深度学习模型的训练和验证提供有力支持,推动人脸识别领域的研究和发展。

活体人脸检测模型采用了两种不同的输入:尺度归一化后的原始图像和其对应的LBP图像。为了实现这种复合神经网络的设计,需要在样本输入网络之前对图像进行信息提取。
为了设计复合卷积神经网络,通过对比了只输入尺度归一化的原始图像的单一卷积网络和同时输入尺度归一化后的原始图像及其LBP图像的复合卷积网络的模型效果。结果表明,复合卷积网络在验证集上的损失和准确率随着训练代数的增加趋于稳定,表现更好且具有更强的泛化能力。

灰度变换法的原理是通过对原图像中的灰度分布进行扩展,使其覆盖整个灰度级范围。一般情况下,原始的8位灰度图像具有256个灰度级。然而,由于尺度、环境等因素的影响,灰度值可能集中在有限的几个区段。为了解决这个问题,可以使用灰度拉伸技术。灰度拉伸能够将原图像的灰度级范围扩展到256个灰度级,从而提高图像的对比度和细节信息。

三、实验及结果分析
3.1 实验环境搭建
3.2 模型训练
自适应增强的AdaBoost算法基于结构特征,用于构建强分类器,其中包含多个弱分类器。该算法的训练过程中,每一代都会着重增强被弱分类器误划分的图像,并更新图像的权重,直到达到预设的准确率。首先使用Gaussian函数对直方图进行细化处理,以消除Gaussian噪声并使原图像变得平滑。然后,通过对图像进行卷积操作,使用固定模板对模板中心像素点周围的像素值进行加权平均,并用该平均值替换模板中心的像素值。在计算Haar-like特征时,该算法利用积分图(integral image)的概念,基于动态规划思想,遍历一次全图像,以在常数时间内完成大量计算。

活体人脸检测的目标是通过找到活体和非活体攻击之间的差异来设计特征。根据这些差异,可以构建一个能够区分真假面部的卷积神经网络。该网络被压缩以适应移动设备,并提高检测速度。在活体检测之前,需要提供输入视频文件的路径和输出目录,以及面部检测器的路径。还可以预设人脸检测的最小概率(默认为0.5)和检测时略过的帧数(默认为16)。在进行活体检测之前,系统会先确保已检测到人脸。如果定位到人脸,则启动活体检测模型。如果超过5秒未检测到人脸,则显示错误并退出检测模块。

为了构建活体检测模型,需要使用真实人脸和欺骗性人脸的数据集。将面部检测技术应用于这两组图像,以提取每类人脸的感兴趣区域(ROI)。这些ROI将作为输入用于训练活体检测模型。
相关代码示例:
# 处理真实人脸图像
for filename in os.listdir(real_faces_dir):
if filename.endswith('.jpg') or filename.endswith('.png'):
image_path = os.path.join(real_faces_dir, filename)
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行面部检测
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 提取感兴趣区域(ROI)并保存
for (x, y, w, h) in faces:
roi = image[y:y+h, x:x+w]
roi_filename = os.path.splitext(filename)[0] + '_roi.jpg'
roi_save_path = os.path.join(roi_save_dir, roi_filename)
cv2.imwrite(roi_save_path, roi)使用OpenCV工具基于Inception V3网络进行人脸识别训练时,可以分别使用Softmax函数和Triplet函数,并设置相同的参数进行2000代的训练。在训练过程中,可以加入正则化、插入额外的全连接层和使用Dropout技术。此外,选择正确的代价函数和良好的权重初始化方法也非常重要,以确保训练的效果和性能。
最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!