极限学习机原理及Python实现(ELM)
最近在看黄广斌教授的ELM原文,但是原文中的代码链接已经失效,各种途径搜索终于找到了黄教授当时写的代码,但由于是Matlab版本,诸多不便,于是自己动手写了一个Python版本。
基本原理
极限学习机(Extreme Learning Machine,简称ELM)是一种单隐层神经网络,它的主要特点是隐含层节点的权重和偏置系数可以随机生成,生成之后就不再调整,唯一需要确定的是输出层的权重系数 β \boldsymbol \beta β。
假设隐含层输出为 H \boldsymbol H H,输出层的输出(最后输出)为 T \boldsymbol T T,则输出层的权重系数 β \boldsymbol \beta β满足: H β = T \boldsymbol H\boldsymbol \beta = \boldsymbol T Hβ=T, β = H † T \boldsymbol \beta=\boldsymbol H^\dagger\boldsymbol T β=H†T,其中 H † \boldsymbol H^\dagger H†为广义逆。
极限学习机的网络结构很简单,如下图所示。

其中 w \boldsymbol w w和 b \boldsymbol b b分别是隐含层节点的权重系数矩阵和偏置系数向量, β \boldsymbol \beta β是输出层的权重系数矩阵。
假设现在有一组样本 ( X , T ) (\boldsymbol X, \boldsymbol T) (X,T), X \boldsymbol X X表示数据,维度为 n × d n\times d n×d,其中 n n n为样本个数, d d d为特征个数。

T \boldsymbol T T表示标签,维度为 n × t n\times t n×t

如果隐含层节点个数为 m m m,则权重系数矩阵维度为 d × m d\times m d×m
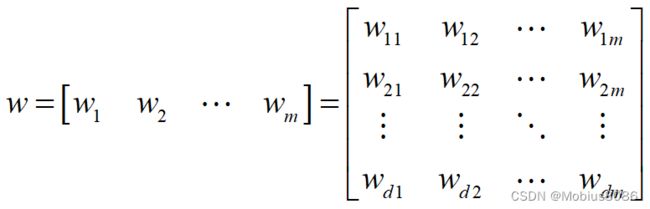
偏置系数矩阵维度为 1 × m 1\times m 1×m

记隐含层节点输出为 H \boldsymbol H H, H = g ( X w + b ) \boldsymbol H = g(\boldsymbol X \boldsymbol w + \boldsymbol b) H=g(Xw+b),其中 g ( ⋅ ) g(·) g(⋅)为激活函数,心细推导的同学可能会发现这里的矩阵维度根部不能相加,一个矩阵加上一个向量,是的!但是在numpy中可以,利用numpy的广播机制可以实现维度相等的矩阵和向量的相加,这里只是偷懒一点点,同时也方便原理的理解,矩阵表示如下:
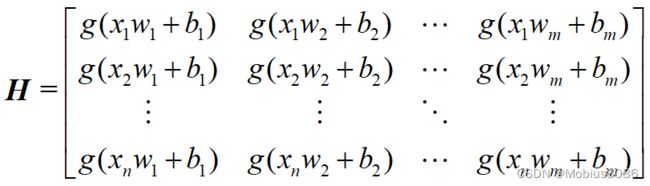
据此,输出矩阵 T = H β \boldsymbol T=\boldsymbol H \boldsymbol \beta T=Hβ。
代码实现
代码实现的过程与上述原理有一点区别的就是隐含层系数矩阵 b \boldsymbol b b,原理推导的过程是一个向量,但是实际过程中为了方便,生成了一个矩阵。
使用的时候将下面代码保存为文件myELM.py
# -*- coding:utf-8 -*-
# keep learning, build yourself.
# author: Lu Huihuang
# 2023/4/14 9:00
import numpy as np
from numpy.linalg import pinv
from sklearn.preprocessing import OneHotEncoder
class ELM:
def __init__(self, hiddenNodeNum, activationFunc="sigmoid", type_="CLASSIFIER"):
# beta矩阵
self.beta = None
# 偏置矩阵
self.b = None
# 权重矩阵
self.W = None
# 隐含层节点个数
self.hiddenNodeNum = hiddenNodeNum
# 激活函数
self.activationFunc = self.chooseActivationFunc(activationFunc)
# 极限学习机类别 :CLASSIFIER->分类, REGRESSION->回归
self.type_ = type_
def fit(self, X, T):
if self.type_ == "REGRESSION":
try:
if T.shape[1] > 1:
raise ValueError("回归问题的输出维度必须为1")
except IndexError:
# 如果数据是一个array,则转换为列向量
T = np.array(T).reshape(-1, 1)
if self.type_ == "CLASSIFIER":
# 独热编码器
encoder = OneHotEncoder()
# 将输入的T转换为独热编码的形式
T = encoder.fit_transform(T.reshape(-1, 1)).toarray()
# 输入维度d,输出维度m,样本个数N,隐含层节点个数hiddenNodeNum
n, d = X.shape
# 权重系数矩阵 d*hiddenNodeNum
self.W = np.random.uniform(-1.0, 1.0, size=(d, self.hiddenNodeNum))
# 偏置系数矩阵 n*hiddenNodeNum
self.b = np.random.uniform(-0.4, 0.4, size=(n, self.hiddenNodeNum))
# 隐含层输出矩阵 n*hiddenNodeNum
H = self.activationFunc(np.dot(X, self.W) + self.b)
# 输出权重系数 hiddenNodeNum*m,β的计算公式为:((H.T*H)^-1)*H.T*T
self.beta = np.dot(np.dot(pinv(np.dot(H.T, H)), H.T), T)
def chooseActivationFunc(self, activationFunc):
"""选择激活函数,这里返回的值是函数名"""
if activationFunc == "sigmoid":
return self._sigmoid
elif activationFunc == "sin":
return self._sine
elif activationFunc == "cos":
return self._cos
def predict(self, x):
# 样本个数
sampleCNT = len(x)
# 由于训练样本个数为b矩阵的行,用len函数获取,进行预测的时候必须满足该条件,否则下面公式索引会超出范围
if sampleCNT > len(self.b):
raise ValueError("训练集样本数必须大于测试机样本数")
h = self.activationFunc(np.dot(x, self.W) + self.b[:sampleCNT, :])
res = np.dot(h, self.beta)
if self.type_ == "REGRESSION": # 回归预测
return res
elif self.type_ == "CLASSIFIER": # 分类预测
# 返回最大值所在位置的索引,因为最大值位置的类别恰好等于索引
return np.argmax(res, axis=1)
@staticmethod
def score(y_true, y_pred):
# 根据输出标签相等的个数计算得分
if len(y_pred) != len(y_true):
raise ValueError("维度不相等")
totalNum = len(y_pred)
rightNum = np.sum([1 if p == t else 0 for p, t in zip(y_pred, y_true)])
return rightNum / totalNum
@staticmethod
def RMSE(y_pred, y_true):
# Root Mean Square Error 均方根误差
# 这里计算平均均方根误差
# 计算公式参考:https://blog.csdn.net/yql_617540298/article/details/104212354
try:
if y_pred.shape[1] == 1:
y_pred = y_pred.reshape(-1)
except IndexError:
pass
return np.sqrt(np.sum(np.square(y_pred - y_true)) / len(y_pred))
@staticmethod
def _sigmoid(x):
return 1.0 / (1 + np.exp(-x))
@staticmethod
def _sine(x):
return np.sin(x)
@staticmethod
def _cos(x):
return np.cos(x)
测试案例
基于自己编写的ELM进行测试,分别用于回归和分类测试。
回归
# 使用波士顿房价数据集进行回归测试
import numpy as np
from sklearn.model_selection import train_test_split
from change_ELM import ELM
import pandas as pd
from sklearn.preprocessing import StandardScaler
data = pd.read_csv("./housing.csv", delim_whitespace=True, header=None)
# 标准化处理
scaler = StandardScaler()
X = data.iloc[:, :-1]
# 将数据标准化处理
X = scaler.fit_transform(X)
# 输出值不作处理
y = data.iloc[:, -1]
# 随机划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
elm = ELM(hiddenNodeNum=20, activationFunc="sigmoid", type_="REGRESSION")
elm.fit(X_train, y_train)
y_pred = elm.predict(X_test)
rmse = elm.RMSE(y_pred, y_test)
print("平均RMSE为:", rmse)
平均RMSE为: 5.704739831187914
分类
import numpy as np
from sklearn.model_selection import train_test_split
from myELM import ELM
from sklearn import datasets
# -------------------------------------------------------------
# # # 采用鸢尾花数据集进行分类测试
# 导入文件
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
elm = ELM(hiddenNodeNum=20, activationFunc="sigmoid", type_="CLASSIFIER")
elm.fit(X_train, y_train)
y_pred = elm.predict(X_test)
print("训练得分:", elm.score(y_test, y_pred))
输出
训练得分: 0.9210526315789473
由于系数矩阵每次都是随机生成的,所以每次的准确率都会有所变化。
其中,波士顿房价数据集是从kaggle官网下载的。
附录
黄教授代码:
REGRESSION=0;
CLASSIFIER=1;
%%%%%%%%%%% Load training dataset
train_data=load(TrainingData_File);
T=train_data(:,1)';
P=train_data(:,2:size(train_data,2))';
clear train_data; % Release raw training data array
%%%%%%%%%%% Load testing dataset
test_data=load(TestingData_File);
TV.T=test_data(:,1)';
TV.P=test_data(:,2:size(test_data,2))';
clear test_data; % Release raw testing data array
NumberofTrainingData=size(P,2);
NumberofTestingData=size(TV.P,2);
NumberofInputNeurons=size(P,1);
if Elm_Type~=REGRESSION
%%%%%%%%%%%% Preprocessing the data of classification
sorted_target=sort(cat(2,T,TV.T),2);
label=zeros(1,1); % Find and save in 'label' class label from training and testing data sets
label(1,1)=sorted_target(1,1);
j=1;
for i = 2:(NumberofTrainingData+NumberofTestingData)
if sorted_target(1,i) ~= label(1,j)
j=j+1;
label(1,j) = sorted_target(1,i);
end
end
number_class=j;
NumberofOutputNeurons=number_class;
%%%%%%%%%% Processing the targets of training
temp_T=zeros(NumberofOutputNeurons, NumberofTrainingData);
for i = 1:NumberofTrainingData
for j = 1:number_class
if label(1,j) == T(1,i)
break;
end
end
temp_T(j,i)=1;
end
T=temp_T*2-1;
%%%%%%%%%% Processing the targets of testing
temp_TV_T=zeros(NumberofOutputNeurons, NumberofTestingData);
for i = 1:NumberofTestingData
for j = 1:number_class
if label(1,j) == TV.T(1,i)
break;
end
end
temp_TV_T(j,i)=1;
end
TV.T=temp_TV_T*2-1;
end
start_time_train=cputime;
%%%%%%%%%%% Random generate input weights InputWeight (w_i) and biases BiasofHiddenNeurons (b_i) of hidden neurons
InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons)*2-1;
BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1);
tempH=InputWeight*P;
clear P; % Release input of training data
ind=ones(1,NumberofTrainingData);
BiasMatrix=BiasofHiddenNeurons(:,ind); % Extend the bias matrix BiasofHiddenNeurons to match the demention of H
tempH=tempH+BiasMatrix;
%%%%%%%%%%% Calculate hidden neuron output matrix H
switch lower(ActivationFunction)
case {'sig','sigmoid'}
%%%%%%%% Sigmoid
H = 1 ./ (1 + exp(-tempH));
case {'sin','sine'}
%%%%%%%% Sine
H = sin(tempH);
case {'hardlim'}
%%%%%%%% Hard Limit
H = double(hardlim(tempH));
case {'tribas'}
%%%%%%%% Triangular basis function
H = tribas(tempH);
case {'radbas'}
%%%%%%%% Radial basis function
H = radbas(tempH);
%%%%%%%% More activation functions can be added here
end
clear tempH; % Release the temparary array for calculation of hidden neuron output matrix H
%%%%%%%%%%% Calculate output weights OutputWeight (beta_i)
OutputWeight=pinv(H') * T'; % implementation without regularization factor //refer to 2006 Neurocomputing paper
end_time_train=cputime;
TrainingTime=end_time_train-start_time_train; % Calculate CPU time (seconds) spent for training ELM
%%%%%%%%%%% Calculate the training accuracy
Y=(H' * OutputWeight)'; % Y: the actual output of the training data
if Elm_Type == REGRESSION
TrainingAccuracy=sqrt(mse(T - Y)) % Calculate training accuracy (RMSE) for regression case
end
clear H;
%%%%%%%%%%% Calculate the output of testing input
start_time_test=cputime;
tempH_test=InputWeight*TV.P;
clear TV.P; % Release input of testing data
ind=ones(1,NumberofTestingData);
BiasMatrix=BiasofHiddenNeurons(:,ind);
tempH_test=tempH_test + BiasMatrix;
switch lower(ActivationFunction)
case {'sig','sigmoid'}
%%%%%%%% Sigmoid
H_test = 1 ./ (1 + exp(-tempH_test));
case {'sin','sine'}
%%%%%%%% Sine
H_test = sin(tempH_test);
case {'hardlim'}
%%%%%%%% Hard Limit
H_test = hardlim(tempH_test);
case {'tribas'}
%%%%%%%% Triangular basis function
H_test = tribas(tempH_test);
case {'radbas'}
%%%%%%%% Radial basis function
H_test = radbas(tempH_test);
%%%%%%%% More activation functions can be added here
end
TY=(H_test' * OutputWeight)'; % TY: the actual output of the testing data
end_time_test=cputime;
TestingTime=end_time_test-start_time_test;
if Elm_Type == REGRESSION
TestingAccuracy=sqrt(mse(TV.T - TY)) % Calculate testing accuracy (RMSE) for regression case
end
if Elm_Type == CLASSIFIER
%%%%%%%%%% Calculate training & testing classification accuracy
MissClassificationRate_Training=0;
MissClassificationRate_Testing=0;
for i = 1 : size(T, 2)
[x, label_index_expected]=max(T(:,i));
[x, label_index_actual]=max(Y(:,i));
if label_index_actual~=label_index_expected
MissClassificationRate_Training=MissClassificationRate_Training+1;
end
end
TrainingAccuracy=1-MissClassificationRate_Training/size(T,2);
for i = 1 : size(TV.T, 2)
[x, label_index_expected]=max(TV.T(:,i));
[x, label_index_actual]=max(TY(:,i));
if label_index_actual~=label_index_expected
MissClassificationRate_Testing=MissClassificationRate_Testing+1;
end
end
TestingAccuracy=1-MissClassificationRate_Testing/size(TV.T,2);
end