JVM的垃圾回收机制(GC)
系列文章目录
JVM的内存区域划分_crazy_xieyi的博客-CSDN博客
JVM类加载(类加载过程、双亲委派模型)_crazy_xieyi的博客-CSDN博客
文章目录
- 一、什么是垃圾回收?
- 二、java的垃圾回收,要回收的内存是哪些?
- 三、回收堆上的内存,具体是回收什么?
- 四、垃圾回收到底是怎么回收的?
- 五、如何判定垃圾?
- 1.引用计数
- 2.可达性分析(java)
- 六、已经知道哪些对象是垃圾了,具体怎么去回收呢?
- 1.标记-清除
- 2.复制算法
- 3.标记整理
- 4.分代回收
一、什么是垃圾回收?
垃圾回收,回收的是内存。JVM其实是一个进程,一个进程会持有很多硬件资源,比如:CPU,内存,硬盘,带宽资源等。系统的内存总量是一定的,程序在使用内存的时候,必须先得申请,才能使用,使用完毕后还要释放。
从代码编写的角度看,内存的申请时机是非常明确的,但是内存的释放时机在很多时候是不太明确的。这个时候就给内存的释放带来了一些困难,典型的问题就是,这个内存是否还要继续使用?
像C/C++这样的编程语言,内存释放,是纯手工的,全靠程序员手动释放。比如,在C语言中,如果malloc出来的对象,不手动调用free,那么这个内存就会一直持有。此时,内存的释放就全靠程序员自己来控制,如果忘了释放(在该释放的时候没有释放),那么很有可能会带来“内存泄漏”这样的问题。一直申请不释放,导致系统可用的内存越来越少,直到耗尽,如果再想要申请内存,就申请不到了。所以,内存泄漏,一向成为了程序员幸福感的头号杀手!
既然内存泄漏有这么大的弊端,肯定有相应的办法来反制。比如,在C++中,就采取了智能指针的方式,在java中采取的方案就是“垃圾回收”机制。对于java来说,代码中的任何地方都可以申请内存,然后由JVM统一进行释放,具体来说,就是由JVM内部的一组专门负责垃圾回收的线程来进行这样的工作的。
JVM垃圾回收的优点:
能够非常好的保证不出现内存泄漏的情况,但是也不是100%保证,就是再厉害的机制也顶不过程序猿自己瞎搞。
JVM垃圾回收缺点:
1.需要消耗额外的系统资源
2.内存的释放可能存在延时
3.可能会导致出现STW问题(stop the world)(在java的世界中,其实前辈们已经做出了很多的努力来改进这个问题,目前能够把STW控制在1ms内)
二、java的垃圾回收,要回收的内存是哪些?
JVM中的内存分为了好几个区域,有堆、方法区、栈和程序计数器。在这几个区域中,堆占据的内存空间是最大的,所以在java的垃圾回收机制中,咱们日常讨论的垃圾回收,主要是指堆上内存的回收。
三、回收堆上的内存,具体是回收什么?
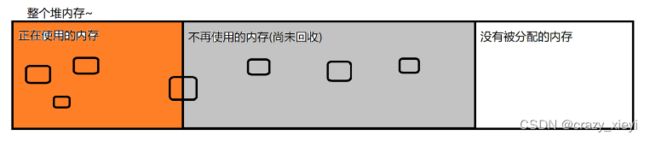
在堆上,是new出了很多的对象,此时针对堆上的对象,也分成三种:完全使用、完全不使用、一半要使用一半不使用。对于完全不使用,这就是我们要回收的东西。java中的垃圾回收,是以“对象”为基本单位的,一个对象要么被回收,要么不被回收,不会出现一个对象被回收一半的情况。
四、垃圾回收到底是怎么回收的?
垃圾回收的基本思想是先找出垃圾,再回收垃圾。一般情况下时把再也不会被使用到的对象进行垃圾回收,如果要是把正在使用的对象进行垃圾回收,这是一个非常可怕的结果。对于回收少了这样的问题来说,回收多了或回收错了显然是更严重的问题。对于GC来说,判定垃圾的原则,宁可放过,也不能错杀.........
五、如何判定垃圾?
单说GC的话,判定垃圾有两种典型的方案:引用计数、可达性分析
1.引用计数
在对象里面包含一个单独的计数器,随着引用增加,计数器就自增,随着引用减少,计数器就自减。
Test a = new Test();此时认为new Test()这个对象就有一个引用指向它。
Test b = a;此时就有a和b两个引用都指向这个对象。引用计数,就是通过一个变量来保存当前这个对象被几个引用来指向。
Test a = new Test();
Test b = a;
a = null;
b = null当这两个引用都指向 null 的时候,然后这个对象就没有被指向了,此时这个对象就认为是垃圾了(引用计数为0)。
引用计数的优点:
规则简单,实现方便,比较高效(程序运行效率比较高)。
引用计数的缺点:
1.空间利用率比较低,针对大量的小对象,比较浪费空间。(比如,一个对象4个字节,也需要4个字节的计数器)
2.存在循环引用的问题(致命问题)
有些特殊的代码下,循环引用会导致代码的引用计数判断出现问题,从而无法回收。
class Test{
Test t = null;
}
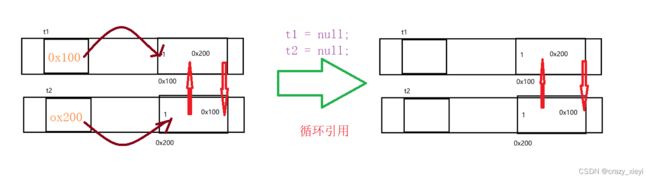
Test t1 = new Test();
Test t2 = new Test();
t1.t = t2;
t2.t = t1;
当执行下面这个操作:t1 = null; t2 = null;这一操作其实是销毁了两个引用,但是引用计数只减了1,没有了t1,就无法使用t1.t。
 很多编程语言,虽然使用了引用计数这种机制,但是实际上都是改进过的引用计数,比如(Python,PHP)。在java中,并没有使用引用计数的这种方式,而是使用第二种机制:可达性分析。
很多编程语言,虽然使用了引用计数这种机制,但是实际上都是改进过的引用计数,比如(Python,PHP)。在java中,并没有使用引用计数的这种方式,而是使用第二种机制:可达性分析。
2.可达性分析(java)
从一组初始的位置出发(比如二叉树),向下进行深度遍历,把所有能够访问到的对象都标记成“可达”(可以被访问到),对应的,不可达的对象就是垃圾。
JVM中采取的方案是:在JVM中存在一组线程,来周期性的进行上述的遍历过程。不断的找出这些不可达的对象,由JVM进行回收。
把可达性分析的初始位置称为“GCRoot”,主要对栈上的局部变量表中的引用、常量池里面的引用指向的对象,方法区中引用类型的静态成员变量进行标记。和引用计数相比,可达性分析确实要稍微麻烦一点,而且同时可达性分析的遍历过程的开销是比较大的。虽然是开销比较大,但是后面会有一些优化的手段。但是可达性分析带来了好处就是解决了引用计数的两个缺点,内存上不需要消耗额外的空间,也没有循环引用的问题。
六、已经知道哪些对象是垃圾了,具体怎么去回收呢?
在java的垃圾回收机制中,有一些经典的策略/算法:标记-清除、复制算法、标记整理以及分代回收。
1.标记-清除

白色是正在使用的对象,灰色是已经被释放的空间。虽然这个过程可以释放掉不用的空间,但是引入了额外的问题:内存碎片。
如果内存中的内存碎片很多很多,那么此时你去申请一块小的内存还好,但是想要很大的一块连续内存空间,可能会申请失败。内存碎片问题,如果一直累积下去,就会导致出现系统上看起来空闲内存挺多的,但是实际上申请连续的内存空间是申请不到的。内存碎片问题,在“频繁申请释放”的场景中,尤为严重。
2.复制算法
为了解决内存碎片问题,就引入了复制算法。

复制算法把整个内存分为了两个部分,一次只用一个部分,1和3要被回收了, 于是就把剩下的2和4拷贝到另外一侧,然后再整体回收这一整块空间。
使用复制算法,可以非常有效的避免出现内存碎片问题。但是复制算法也有一些缺点:
可用的内存空间只有一半;如果要回收的对象比较少,剩下的对象比较多,那么复制的开销就比较大了。复制算法只适用于对象会被快速回收,并且整体内存不大的场景下。
3.标记整理
为了能够解决复制算法的内存空间利用率低的问题,就引入了标记整理的策略。标记整理,就有点类似于“顺序表删除元素的搬运过程”。

这样的操作,既可以有效的避免内存碎片,也可以提高空间的利用率。但是在这个搬运的过程中,也是一个很大的开销,这个开销比复制算法里面的复制对象的开销还要大。
4.分代回收
在实际中的垃圾回收算法,是结合了以上的三种方式,取长补短,引入了分代回收的策略。
在分代回收中,把内存中的对象分成了几种情况,每一种情况采用不同的回收算法。
那么是如何进行分代的呢?
是根据对象的“年龄”的年龄来进行划分的。在JVM中,在进行垃圾回收扫描(可达性分析)也是周期性的,这个对象每次经历了一个扫描周期,就认为是长了一岁。就根据这个对象的年龄,就把整个内存进行划分。年龄短的放在一起,年龄长的放在一起。根据不同的年龄对象,就可以采用不同的回收算法了。
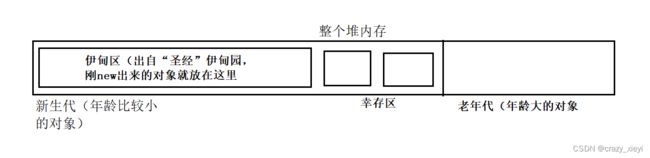
分代回收的过程:
1.一个新的对象,诞生于伊甸区。
2.如果活到一岁的对象(该对象经历了一轮GC还没回收)就拷贝到幸存区。根据经验规律,绝大部分对象都是熬不过一轮GC的,所以进入幸存区的对象不是很大,这里的拷贝开销就不是很大。
3.在幸存区中,对象也要经历若干轮GC。每一轮GC逃过的对象,都通过复制算法拷贝到另外的幸存区里。在这两个幸存区的对象经过来回拷贝,每一轮都会淘汰一批对象。
4.在幸存区中,熬过一定轮次的GC,JVM就认为这个对象未来还会更持久的存在下去,于是就把这样的对象拷贝到老年代中。
5.进入老年代的对象,JVM认为都是属于能够持久存在的对象。但是这些对象也需要使用GC来扫描,但是扫描的频次就大大降低了,老年代这里通常使用的是标记整理算法。
其实在某些特殊情况下,如果一个对象特别大,为了避免大的开销,那么也会直接进入老年代的。