GraphGPT: Graph Instruction Tuning for Large Language Models
GraphGPT:Graph Instruction Tuning for Large Language Models
基本信息
博客贡献人
猪八戒
作者
Jiabin Tang , Yuhao Yang , Wei Wei
[单位]
香港大学数据智能实验室
摘要
图神经网络(GNN)通过图节点之间的递归信息交换和聚合来实现高级图结构理解。为了提高模型的稳健性,自监督学习(SSL)已成为一种有前途的数据增强方法。然而,现有的得到预训练图嵌入的方法通常要依赖特定下游任务的标签进行微调,这限制了它们在标记数据稀缺或不可用的场景中的可用性。为了解决这个问题,我们的研究重点是提高图模型在具有挑战性的零样本学习场景中的泛化能力。受大语言模型(LLM)的启发,我们的目标是开发一种面向图的 LLM,即使没有下游图数据中的任何可用信息,也可以在不同的下游数据集和任务中实现高度泛化。在这项工作中,我们提出了 GraphGPT 框架,该框架使用设计的图指令微调范式,将LLMs与图结构知识进行对齐。我们的框架包含一个Text-Graph组件,以在文本信息和图结构之间建立联系。此外,我们提出了一种双阶段指令微调范式,并配有轻量级Text-Graph对齐映射器。该范例探索了自监督图结构信号和特定任务的图指令,以指导LLMs理解复杂的图结构并提高其在不同下游任务中的适应性。我们的框架在有监督和零样本图学习任务上进行了评估,展示了卓越的泛化能力并超越了最先进的baseline。
现有挑战&动机
总的来说,将大语言模型与图学习结合是一项具有挑战性的任务:
-
结构信息与语言空间的对齐: 图数据具有自身的结构和特性,而大语言模型主要在语言空间中进行训练和表示学习。如何有效地将图结构信息与语言空间进行对齐,使得模型能够同时理解图的结构和语义信息,是一个重要的问题。
-
引导大语言模型理解图的结构信息: 为了使大型语言模型能够有效地理解图的结构信息,需要设计适当的指令目标来要求模型理解图数据中的结构信息。
-
赋予大语言模型图学习下游任务的逐步推理能力: 在图学习的下游任务中,逐步推理是一个重要的能力。这意味着模型需要根据图的结构信息和语义信息,逐步推断出更复杂的关系和属性。
LLM建模图结构的困难
为了更深入地理解使用纯基于文本的提示语直接提示LLM来进行图结构建模的限制,图1提供了说明性示例。这些例子有助于对GraphGPT框架和ChatGPT方法之间的比较分析。我们关注于一个具有代表性的节点分类任务,其目标是预测给定论文的类别。在图1 (a)和图1 (b)中,我们展示了使用ChatGPT的两个场景的预测结果: (1)只使用输入节点的文本数据,以及(2)使用基于文本的图结构感知提示,这些提示的灵感来自于最近研究中的提示设计。这些图突出了仅依赖基于文本的提示进行图结构建模时出现的潜在限制,这可以从给出的不正确的论文节点分类结果中得到证明。相比之下,我们的GraphGPT框架通过保存和利用图结构信息,有效地解决了这些限制,如图1 ©.所示它能够准确地识别论文的类别,以理解底层的图结构。

图1 LLM在理解图结构上下文时的局限性
此外,使用基于文本的结构性提示会导致token大小的增加,这在实际场景中带来了挑战。较长的token序列会导致更高的计算和内存成本,这使得它在现实应用中不太可行。此外,现有的LLM有token限制,这进一步限制了更长的基于文本的提示在大规模图结构建模中的适用性。这些限制强调了更有效和可扩展的方法的必要性。
方法
方法架构图
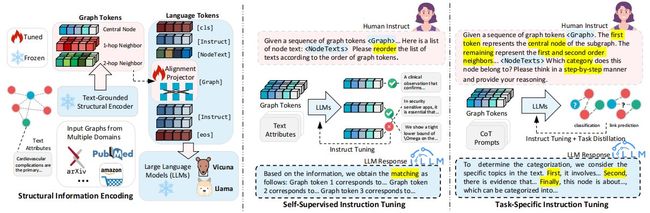
图2 GraphGPT总体架构
方法描述
用Text-Graph对齐编码结构信息
为了更有效地将大语言模型与图结构对齐,本节探索了与大语言模型良好协作的图结构编码方式。受之前的研究启发,本文在预训练中使用对比学习将文本信息融入图结构的编码过程中。然后将预训练后的图编码器集成到 GraphGPT 模型框架中,从而无缝地整合图编码器的功能。在 GraphGPT 中,图结构编码器的选择是非常灵活的,它可以利用各种基础 GNN 架构从多种图预训练范式中获得。
具体来说,让一个图 G ( ν , ε , A , X ) \mathbf{G}(\nu,\varepsilon,\mathbf{A}, \mathbf{X} ) G(ν,ε,A,X) 与这个图的原始结点文本内容 C = { c i ⊆ R l i × d , 1 ≤ i ≤ N } \mathbf{C}= \left \{ c_{i}\subseteq \mathbb{R}^{l_{i}\times d}, 1\leq i\leq N \right \} C={ci⊆Rli×d,1≤i≤N}对应,其中 ν \nu ν代表节点集, ε \varepsilon ε 表示边集, A \mathbf{A} A 表示邻接矩阵, X \mathbf{X} X 表示特征矩阵, N N N 代表节点数, l i l_{i} li 表示第 i i i 个结点的文本长度。可以通过任意图编码器 f G f_{\mathbf{G}} fG(例如 graph transformer)和任意文本编码器 f T f_{\mathbf{T}} fT(例如原始 transformer)得到编码后的图表示 H = f G ( X ) , T = f T ( C ) \mathbf{H}=f_{\mathbf{G}}(\mathbf{X}), \mathbf{T}=f_{\mathbf{T}}(\mathbf{C}) H=fG(X),T=fT(C),其中 H ∈ R N × d \mathbf{H}\in \mathbb{R}^{N\times d} H∈RN×d , T ∈ R N × d \mathbf{T}\in \mathbb{R}^{N\times d} T∈RN×d ,最后进行归一化得到最终的表示 H ^ \hat{\mathbf{H}} H^ 和 T ^ \hat{\mathbf{T}} T^。
然后,通过对比学习进行不同维度的 Text-Graph 对齐:

其中 Γ i \mathbf{Γ}_{i} Γi 为相似度矩阵,包含了一个图中所有结点间的相似度; L L L 为损失函数。 g i ( 1 ) , g_{i}^{\left (1 \right )}, gi(1), g i ( 2 ) g_{i}^{\left (2 \right )} gi(2) 为不同对比策略的转换函数,将不同维度的两种模态的表示映射到同一个子空间中;CE()为交叉熵损失函数(Cross Entropy Loss); y = ( 0 , 1 , ⋯ , n − 1 ) T \mathbf{y}=\left ( 0,1,\cdots ,n-1 \right )^{\textup{T}} y=(0,1,⋯,n−1)T 为对比标签。
双阶段图指令微调
本研究中提出的双阶段图指令微调范式是建立在指令微调的概念之上。
1.自监督指令微调
指令微调(instruct-tuning)和提示微调(prompt-tuning)的区别:
提示微调:“我在重庆上学” 的英文翻译是,输出:____
指令微调:翻译这句话:输入:我在重庆上学,输出:____
提示微调是针对某特定任务而言,不同的任务需要给出不同的表达形式;指令微调则是激发语言模型的理解能力,是针对多种任务而形成的指令,在未可见任务上泛化能力更强。
在双阶段图指令微调范式的第一阶段,引入了自监督指令微调机制,具体来说,本文设计了一个结构感知的图匹配任务。
指令设计如下:
将图中的每个节点视为中心节点,并执行h跳的随机邻居采样,从而得到每个结点的子图结构,从而建立了一个自监督图匹配任务。图匹配任务的目标是将某个子图所有结点的token与其相应的节点文本信息匹配。这需要根据图结点token的顺序重新排序节点文本信息列表,从而将每个图结点token与其相关的文本描述关联起来,这由大语言模型来完成,而子图所有结点的token产生于下面介绍的映射器。
大语言模型的自然语言输入是人类的问题。
在图匹配任务的上下文中,指令包括指令符token
文章通过引入一个映射器,将人类问题中的token
微调策略如下:
为了高效地优化微调过程,本文提出了一种轻量级对齐映射策略,在训练过程中,固定大语言模型和图编码器的参数,仅优化映射器的参数。训练完成后,映射器学会了将编码后的图表示映射为图结点token,而大语言模型则擅长将这些图结点token与这些节点文本信息对齐。
考虑到图匹配过程是无监督的,这将有机会利用来自不同领域的大量未标记的图数据,以增强学习到的映射器的泛化能力。
2.特定任务指令微调
在第二阶段,本文提出了特定任务指令微调,旨在定制模型的推理行为,以满足不同图学习任务的特定约束和要求,如节点分类或链路预测。通过使用任务特定的图指令模板对大语言模型进行微调,引导模型生成更适合当前图学习任务的响应,进一步提高了模型在处理各种图学习任务时的适应性和性能,如图3所示。

图3 图匹配任务(上)、节点分类(中)和链路预测(下)的指令设计
指令设计如下:
为了为每个节点生成图信息,采用第一阶段相同的邻居采样方法。对于节点分类任务,人类问题指令包含指令符token
这个指令提示语言模型基于图结构数据和伴随的文本信息来预测中心节点的类别。在图3中可以看到不同任务的指令数据的模版。
微调策略如下:
训练的第二阶段使用第一阶段训练得到的结构感知映射器的参数作为初始状态,在训练过程中,保持大语言模型和图编码器的参数不变,仅专注于优化映射器的参数,确保大语言模型进一步与下游任务对齐,增强其理解和解释图结构的能力。
完成上述的两个训练阶段后,GraphGPT已经获得了理解给定图结构并在提供的图上执行各种下游任务的能力。
实验
数据集
使用三个数据集来评估GraphGPT的性能: OGB-arxiv、PubMed和Cora,它们都是论文引文数据集,这里用于结点分类任务。
OGB-arxiv数据集代表了一个有向图,它捕获了由MAG索引的计算机科学arXiv论文之间的引文网络。数据集中的每一篇论文都与一个研究类别相关联,由作者和arXiv主持人手动标记这些研究类别是从40个学科领域中选择出来的。
PubMed数据集包括从PubMed数据库中获得的19,717篇关于糖尿病的科学出版物。这些出版物被分为实验性诱发糖尿病、1型糖尿病和2型糖尿病。此外,该数据集还包括一个包含44,338个链接的引文网络。
Cora数据集包含25120篇通过被引用连接的研究论文。我们使用了Cora数据集的扩展版本,与以前的版本[17]相比,它更大,有更多的类(总共70个)。
Baseline
- MLP,它使用多层感知器进行节点表示
- 具有代表性的图神经网络编码器,包括GraphSAGE、GCN、GAT和RevGNN
- 用于图学习的自监督方法DGI
- 探索知识蒸馏-增强的GNN,主要是GKD和GLNN
- 最近提出的强Graph Transformer网络,NodeFormer和DIFFormer
- 开源的LLM,如Baichuan-7b、vicuna-7B-v1.1和vicuna-7B-v1.5
实验结果
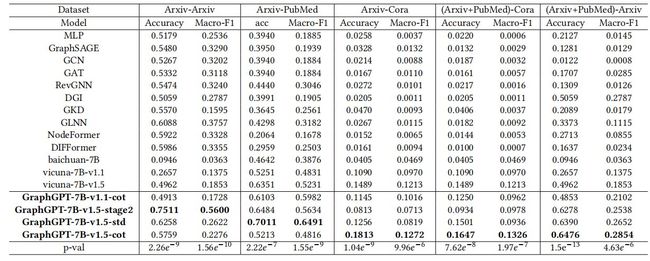
表1 在有监督和zero-shot情况下,各种节点分类方法的性能比较。其中 “Arxiv-Arxiv” 表示在Arxiv上训练,在Arxiv上测试;“Arxiv-PubMed”表示在Arxiv上训练,在PubMed上测试;“(Arxiv + PubMed) - Cora” 表示在 Arxiv 和 PubMed 上训练,在Cora上测试。“-7B”表示参数量表,“-v1.1”和“-v1.5”表示模型的不同版本,“-stage2”表示只采用了第二阶段的调优,“-std”和“-cot”表示标准的和加入思维链提示的方法的使用。

表2 有监督和zero-shot情况下的消融实验结果。其中w/o GS为只使用LLM而不加入结构信息,w/o LR为只使用图编码器而不使用LLM。
实验分析
根据表1和表2的结果,较有意义的结论有以下三点:
- 图结构信息的有效性:GraphGPT明显优于缺乏图结构信息的基本LLM模型。这表明,我们的图形指令调优范式使LLM能够更有效地理解图的结构信息。重要的是,这种性能上的改进是在没有改变LLM的原始参数的情况下实现的,仅仅是通过轻量级对齐映射器来完成的,它通过1层线性映射操作来对齐图token和自然语言token。
- 更多的数据但不遗忘:如表 1 的 “(Arxiv + PubMed) - Arxiv” 列所示,大部分传统的基于 GNN 的方法在 Arxiv 和 PubMed 上经过迭代训练后性能大幅下降。但 GraphGPT 的表现却更为出色。这种情况被认为是由于基于 GNN 的模型在较小的 PubMed 数据集上训练后出现的灾难性遗忘,导致模型的结构建模能力受损。但通过两步的图结构指令微调,此问题得到了有效缓解。这使 GraphGPT 在保持或增强其性能时,能够继续保留通用的图结构模式。
- 使用LLM增强语义推理的有效性:我们进行了进一步的调查,以评估LLM在GraphGPT中的推理能力的影响,通过仅使用默认的图编码器执行监督和零镜头预测。结果表明,GraphGPT集成了LLM后,显著提高了图编码器的性能,特别是在zero-shot设置下。这表明,LLM注入的丰富的语义信息在性能上提供了实质性的提高
此外,使用图token来表示图结构作为LLM的输入的方法比自然语言的解决方案更有效。在包含103个节点的子图的情况下,GraphGPT只需要750个token来输入LLM,而基于文本的方法需要4649个token,token消耗的显著减少意味着训练和推理资源需求的大幅减少。
总结
本文提出了一种有效的、可扩展的图大语言模型,旨在提高图模型的泛化能力。所提出的框架GraphGPT通过双阶段图指令调优范式将特定图的领域结构知识注入LLM。通过利用一个简单而有效的Text-Graph对齐映射器,使得LLM能够理解和解释图结构信息。
亮点
- 使用了一个映射器将图结构信息与文本信息在LLM中对齐;
- 提出了双阶段图指令微调范式,可以进行零样本学习,大大提升泛化能力,同时可以输入特定图的领域的(结构)知识;
- 无需过长的token就可以使LLM能够读取图结构;
- 仅需调整映射器的参数,这比调整LLM参数减少50倍。
不足
- 预印版文章部分内容不清晰或有错误。
启发
- 将具体图结构领域知识加入其中;
- 在图结点数较少的数据集里面可以尝试不使用子图采样而直接使用整个图,从而表示更完整的图信息。
BibTex
@misc{tang2023graphgpt,
title={GraphGPT: Graph Instruction Tuning for Large Language Models},
author={Jiabin Tang and Yuhao Yang and Wei Wei and Lei Shi and Lixin Su and Suqi Cheng and Dawei Yin and Chao Huang},
year={2023},
eprint={2310.13023},
archivePrefix={arXiv},
primaryClass={cs.CL}
}