09 Softmax回归+损失函数+图片分类数据集
Softmax回归
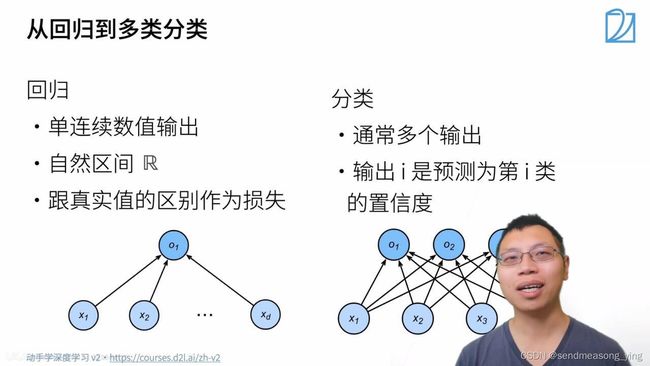
1.回归估计一个连续值,分类预测一个离散类别
2.MNIST:手写数字识别 ; ImageNet:自然物体分类
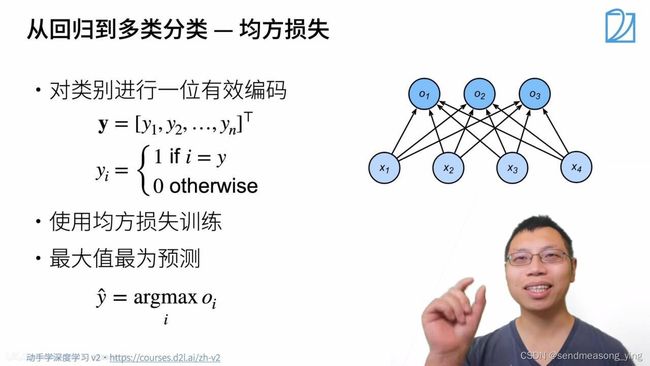
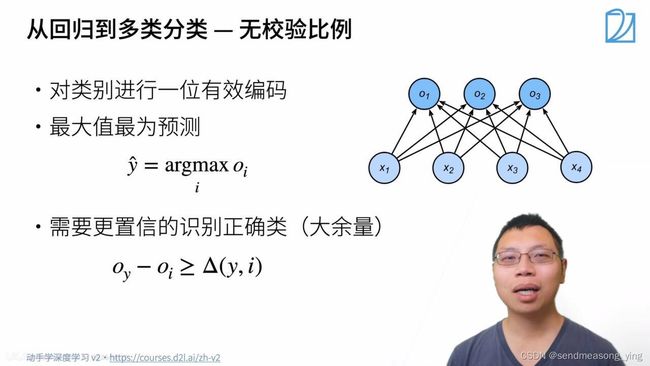
置信度可以定义为,在特定条件下,根据一定数据做出正确抉择的概率。
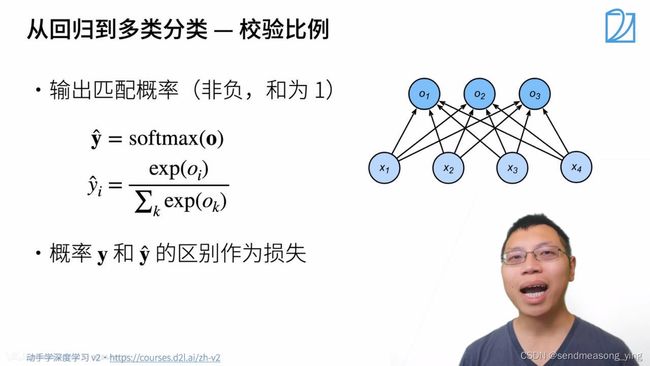

不关心对于非正确类的预测值,只关心对于正确类的预测值置信度有多大。
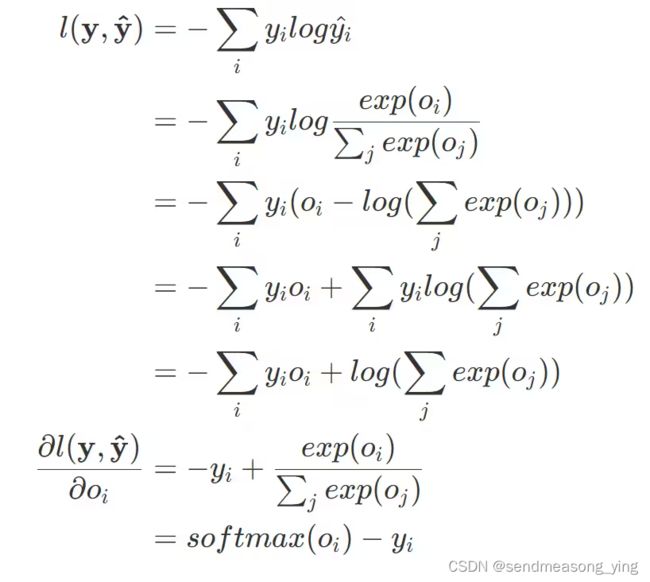
损失函数
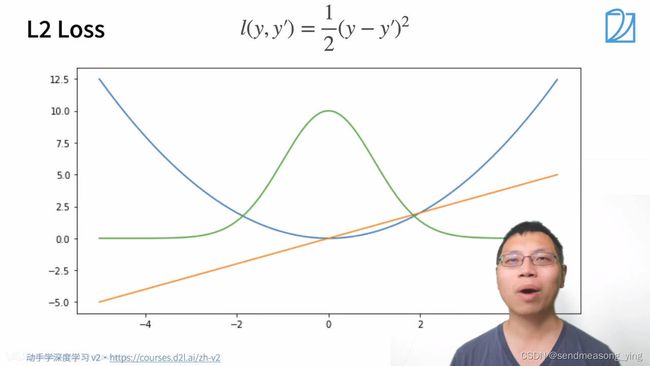
蓝色曲线表示y=0时,变换预测值的曲线变化。绿色是似然函数,近似高斯分布,橙色是损失函数的梯度。

L2损失函数的意义:当靠近原点的时候,梯度就变得越来越小,参数的更新的幅度也变得越来越小。
似然函数的定义:
似然、似然函数与似然估计_似然是什么意思-CSDN博客


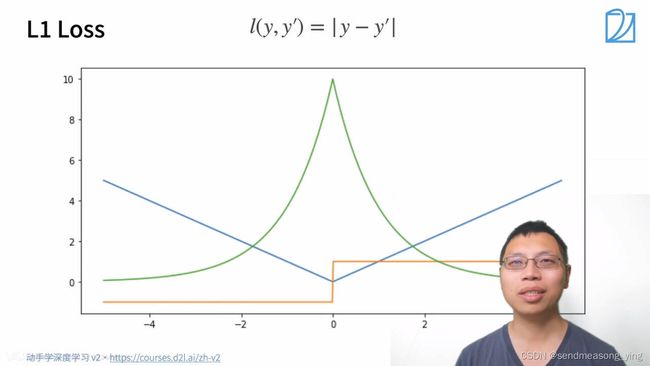
蓝色是损失函数的曲线,此时y=0,绿色的是似然函数,黄色的是梯度,当y'大于0,导数为1,小于0,导数为-1(绝对值函数在0点处不可导)。L1函数的核心是:当预测值和真实值隔的比较远的时候,无论隔的有多远,梯度始终是常数,就算隔的很远,权重更新也不会特别大。带来了稳定性上的好处。缺点就是零点处不可导以及+1和-1之间的不平滑性,当优化到末期之后就可能变得不稳定了。
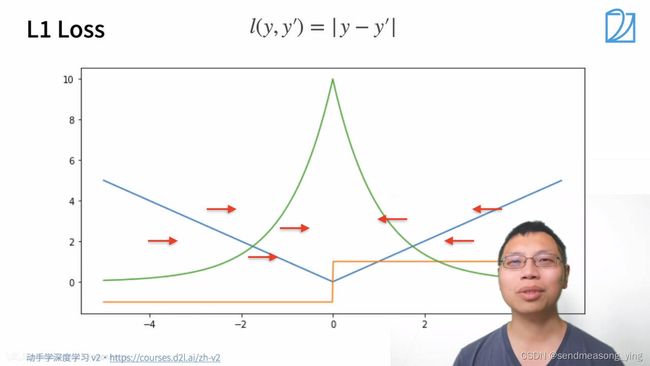
(从图可以看到,在y=0的时候,当某个参数使得y'能取值为0,那么这个参数是最有可能接近样本参数的。绿色的线似然函数代表了y'在哪儿取值时,这个y'对应的参数概率是最大的)

当预测值和真实值相差比较大的时候,损失是绝对值损失,当预测值和真实值靠得比较近的时候就是平方误差,当y'在大于1,小于-1时,梯度是一个常数,在这之间梯度缓慢变化。优化就会比较平滑。
图片分类数据集
测试数据集是用来预测模型好坏的数据集,不参与训练。
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms #transforms对数据进行操作的模组
from d2l import torch as d2l
d2l.use_svg_display() #用svg来显示图片清晰度高一点
"""读取数据集"""
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor() #把图片转成pytorch的tensor
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
#下载到上位机的目录下面,train=true表示下载的是训练数据集,
# transform=trans表示拿到的是tensor而不是一堆图片,
#download=True表示默认从网上下载
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
#train=False下载的是测试集
len(mnist_train), len(mnist_test)
"""结果:输出(60000,10000)"""
mnist_train[0][0].shape
#前一个【0】表示example,第二个【0】表示图片
"""结果:输出torch.Size([1, 28, 28])"""
#因为是黑白图片,RGB的通道数为1,长和宽都是28
def get_fashion_mnist_labels(labels): #@save
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
#以上函数用于在数字标签索引及其文本名称之间进行转换。
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
#scale:一个可选参数,指定绘制的图像的缩放比例。
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
#计算绘制所有图像所需要的画布大小figsize
#使用 matplotlib 的 subplots 函数创建一个 num_rows × num_cols 的子图
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
#plt.subplots()是一个返回包含图形和轴对象的元组的函数。因此,
#在使用时fig, ax = plt.subplots(),将此元组解压缩到变量fig和ax。
#使用 axes.flatten() 将 axes 对象转换为一维数组,方便遍历所有子图
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
#将 axes 和 imgs 两个列表中相同索引位置的元素打包成一个元组 (ax, img)
#enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)
#组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中,
#生成可以遍历的每个元素有对应序号(0, 1, 2, 3…)的enumerate对象。
#zip()函数用于将多个可迭代对象作为参数,依次将对象中对应的元素打包
#成一个个元组,然后返回由这些元组组成的对象,里面的每个元素大概为i,(ax,img)的形式。
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False) #x轴隐藏
ax.axes.get_yaxis().set_visible(False) #y轴隐藏
if titles:
ax.set_title(titles[i])
return axes
#DataLoader 加载了 MNIST 训练集中的 18 张图像和标签
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
#next() 返回迭代器的下一个项目。
#我们可以通过iter()函数获取这些可迭代对象的迭代器。然后,我们可以对获取到的
#迭代器不断使⽤next()函数来获取下一条数据
#使用 show_images 函数在一个2×9的子图中显示了这些图像
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
"""结果是一系列图片,其中X为包含18个样本的28×28的灰度图像(通道值为1)"""
"""读取小批量"""
batch_size = 256
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
#对于进程数,可以利用多进程来加速数据读取,并减少 CPU 空闲时间。在实际应用中,
#推荐将 num_workers 参数设置为 CPU 核心数的 1~4 倍之间。
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:
continue
f'{timer.stop():.2f} sec'
#在一个 for 循环中遍历 train_iter 迭代器,将其中的图像 X 和标签 y 读取出来
#并不做任何处理,然后直接跳出循环。最后,我们使用 timer.stop() 函数计算了
#循环的运行时间,并将结果格式化为一个字符串返回,保留两位小数
"""结果显示:'2.18 sec'"""
"""整合所有组件"""
def load_data_fashion_mnist(batch_size, resize=None): #@save
#加入resize参数是因为此时输入为28*28,若以后需要更大的输入,就可以更改resize
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
#将transforms.Resize(resize) 变换插入到trans列表的最前面,用于将图像大小调整为resize
trans.insert(0, transforms.Resize(resize))
#组合变换序列
trans = transforms.Compose(trans)
#加载数据集并进行trans预处理
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
#将训练集和测试集转换为数据集迭代器
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
"""结果输出:torch.Size([32, 1, 64, 64]) torch.float32 torch.Size([32]) torch.int64"""
部分函数
ToTensor()
- ToTensor() 是pytorch中的数据预处理函数,包含在 torchvision.transforms 模块下。一般用于处理图像数据,所以其处理对象是 PIL Image 和 numpy.ndarray 。
- np.array 整型的默认数据类型为 np.int32,经过 ToTensor() 后数值不变,不进行归一化。
- np.array 浮点型的默认数据类型为 np.float64,经过 ToTensor() 后数值不变,不进行归一化。
- opencv 读取的图像格式为 np.array,其数据类型为 np.uint8,经过 ToTensor() 后数值由 [0,255] 变为 [0,1],通过将每个数据除以255进行归一化。
- 经过 ToTensor() 后,HWC 的图像格式变为 CHW 的 tensor 格式。
- np.uint8 和 np.int8 不一样,uint8是无符号整型,数值都是正数。
- ToTensor() 可以处理任意 shape 的 np.array,并不只是三通道的图像数据。
from torchvision.transforms import Compose, CenterCrop, ToTensor, Resize
- 参考:torchvision.transforms 数据预处理:ToTensor()-CSDN博客
torchvision
tochvision主要处理图像数据,包含一些常用的数据集、模型、转换函数等。torchvision独立于PyTorch,需要专门安装。
torchvision主要包含以下四部分:
- torchvision.models: 提供深度学习中各种经典的网络结构、预训练好的模型,如:Alex-Net、VGG、ResNet、Inception等。
- torchvision.datasets:提供常用的数据集,设计上继承 torch.utils.data.Dataset,主要包括:MNIST、CIFAR10/100、ImageNet、COCO等。
- torchvision.transforms:提供常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
- torchvision.utils:工具类,如保存张量作为图像到磁盘,给一个小批量创建一个图像网格。
【实例化】datasets.CIFAR10(root: str,train: bool = True,transform: Optional[Callable] = None,target_transform: Optional[Callable] = None,download: bool = False,)
作用:创建一个CIFAR-10数据集的实例
- root:数据集的根目录,如果download设置为True,则将保存到该目录。
- train:如果为True,则从训练集创建数据集,否则(即为Flase)从测试集创建。
- transform:接受PIL图像并返回变换后图像的function/transform。E.g, transforms.RandomCrop。
- download:如果为true,则从internet下载数据集并将其放在根目录中。如果数据集已下载,则不会再次下载。
参考:
【学习笔记】【Pytorch】四、torchvision.datasets模块的使用_torchvision模块-CSDN博客
plt.subplots()
subplot().subplots()均用于Matplotlib绘制多图。
返回值:
fig:即figure画窗
ax:即axes,画窗中创建得笛卡尔坐标区(说明白点就是画布中得一块区域)
- 函数原型 subplot(nrows, ncols, index, **kwargs),一般我们只用到前三个参数,将整个绘图区域分成 nrows 行和 ncols 列,而index用于对子图进行编号
- matplotlib.pyplot.subplots(nrows=1, ncols=1, *, sharex=False,sharey=False, squeeze=True,subplot_kw=None, gridspec_kw=None, **fig_kw)
- nrows:默认为 1,设置图表的行数。
- ncols:默认为 1,设置图表的列数。
- sharex、sharey:设置 x、y 轴是否共享属性,默认为 false,可设置为 'none'、'all'、'row' 或 'col'。 False 或 none 每个子图的 x 轴或 y 轴都是独立的,True 或 'all':所有子图共享 x 轴或 y 轴,'row' 设置每个子图行共享一个 x 轴或 y 轴,'col':设置每个子图列共享一个 x 轴或 y 轴。
- squeeze:布尔值,默认为 True,表示额外的维度从返回的 Axes(轴)对象中挤出,对于 N*1 或 1*N 个子图,返回一个 1 维数组,对于 N*M,N>1 和 M>1 返回一个 2 维数组。如果设置为 False,则不进行挤压操作,返回一个元素为 Axes 实例的2维数组,即使它最终是1x1。
- subplot_kw:可选,字典类型。把字典的关键字传递给 add_subplot() 来创建每个子图。
- gridspec_kw:可选,字典类型。把字典的关键字传递给 GridSpec 构造函数创建子图放在网格里(grid)。
- **fig_kw:把详细的关键字参数传给 figure() 函数
subplot()、subplots()在实际过程中,先创建了一个figure画窗,然后通过调用add_subplot()来向画窗中各个分块添加坐标区,其差别在于是分次添加(subplot())还是一次性添加(subplots())。
参考:
plt: subplot()、subplots()详解及返回对象figure、axes的理解_plt.subplots-CSDN博客
flatten()
- flatten()是对多维数据的降维函数。
- flatten(),默认缺省参数为0,也就是说flatten()和flatte(0)效果一样。
- python里的flatten(dim)表示,从第dim个维度开始展开,将后面的维度转化为一维.也就是说,只保留dim之前的维度,其他维度的数据全都挤在dim这一维。
- 比如一个数据的维度是( S 0 , S 1 , S 2......... , S n ) (S0,S1,S2.........,Sn)(S0,S1,S2.........,Sn), flatten(m)后的数据为( S 0 , S 1 , S 2 , . . . , S m − 2 , S m − 1 , S m ∗ S m + 1 ∗ S m + 2 ∗ . . . ∗ S n ) (S0,S1,S2,...,Sm-2,Sm-1,Sm*Sm+1*Sm+2*...*Sn)(S0,S1,S2,...,Sm−2,Sm−1,Sm∗Sm+1∗Sm+2∗...∗Sn)
注意:
flatten()和flatten(0)含义一样,都表示从第0维压缩。
参考:python:flatten()参数详解-CSDN博客
enumerate()
- enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
- enumerate(iteration, start)函数默认包含两个参数,其中iteration参数为需要遍历的参数,比如字典、列表、元组等,start参数为开始的参数,默认为0(不写start那就是从0开始)。enumerate函数有两个返回值,第一个返回值为从start参数开始的数,第二个参数为iteration参数中的值。
参考:enumerate函数详解-CSDN博客
zip()
- zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
- 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
- 语法:zip([iterable, ...])。iterable -- 一个或多个迭代器
is_tensor()
- 语法:torch.is_tensor(obj)
- 此方法很直观,如果obj是tensor的话返回true,否则返回false。
- 另一个类似函数:isinstance(obj, Tensor)
注意,torch.is_tensor(obj)是torch的一个方法,而isinstance(obj, Tensor)是python自带的一个方法,这两个是等价的。当然isinstance(obj, type)这个方法可以检查任何类型,如果检查出obj是type类型返回true,否则返回false。
根据官网的说法,isinstance(obj, Tensor)这种方法更适合于静态检查(例如更适合mypy等静态检查工具进行检查)并且也更加直观(这个倒是我觉得两个方法都挺直观的),所以更推荐使用isinstance(obj, Tensor)这种方法。参考:pytorch每日一学1(torch.is_tensor(obj))-CSDN博客
matplotlib.axes.Axes.get_xaxis()
- 参数:此方法不接受任何参数。
- 返回:此方法返回XAxis实例。
- plt、fig、axes、axis的含义_fig, axes-CSDN博客
set_visible()
matplotlib库的axis模块中的Axis.set_visible()函数用于设置艺术家的可见性。
用法: Axis.set_visible(self, b) 参数:此方法接受以下参数。 b:此参数是布尔值 返回值:此方法不返回任何值。
Matplotlib.axes.axes.set_title()
matplotlib库的Axes模块中的Axes.set_title()函数用于设置坐标轴的标题。
参数:该方法接受以下参数。
- label:这个参数是用于标题的文本。
- fontdict:这个参数是控制标题文本外观的字典。
- loc:该参数用于设置标题的位置{‘ center ‘, ‘ left ‘, ‘ right ‘}。
- pad:这个参数是标题从坐标轴顶部的偏移量,单位为点。
Returns:该方法返回表示标题的matplotlib文本实例。
ax.imshow(img.asnumpy())
ax.imshow(img.numpy0)是一个Python代码行,它使用matplotlib库中的imshow函数将一个Numpy数组表示的图像显示在当前的Axes对象中。其中,img是一个PyTorch张量,通过调用其numpy()方法将其转换为Numpy数组。
d2l.timer()
Timer定时器是一种基于线程的定时器,它通过在指定的时间间隔内启动一个线程来执行特定的任务。当时间间隔到达时,线程将自动执行任务,并在任务完成后自动退出。
函数:
Timer(interval, function, args=[ ], kwargs={ })
interval: 指定的时间function: 要执行的方法args/kwargs: 方法的参数
transforms.Resize()
transforms.Resize()是 PyTorch 中的图像处理函数之一,用于调整图像的大小。该函数可以用于将输入图像调整为指定的大小或按照指定的缩放因子进行调整。
- transforms.Resize(size)
这里的 size 可以是一个整数,表示将图像的较短边缩放到指定长度,同时保持长宽比。例如,transforms.Resize(256) 将图像的较短边调整为256像素,而较长边将按比例缩放。
size 也可以是 [width, height],表示将图像的宽度和高度调整为指定的尺寸。例如,transforms.Resize([256, 256]) 将图像的宽度和高度分别调整为256像素。
参考:
Pytorch中transforms.Resize()的简单使用方法-CSDN博客
transforms.Compose()
torchvision.transforms.Compose()类。这个类的主要作用是串联多个图片变换的操作。例如:
transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])参考:【pytorch】transforms.Compose()使用 - 知乎 (zhihu.com)
参考:
深度学习入门——小白向——李沐《动手学深度学习》3.5节FashionMNIST代码加注释笔记-CSDN博客动手学深度学习——图像分类数据集(代码详解)_图像数据集-CSDN博客