软件工程概论---内聚性和耦合性
目录
一.耦合性
1.内容耦合
2.公共耦合
4.控制耦合
5.标记耦合(特征耦合)
6.数据耦合
7.非直接耦合
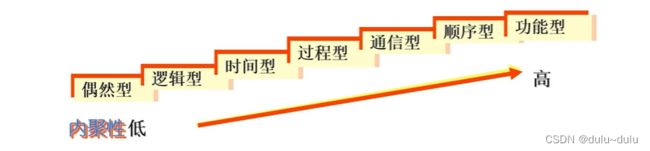
二.内聚性
1.偶然内聚
2.逻辑内聚
3.时间内聚
4.过程内聚
5.通信内聚
6.顺序内聚
7.功能内聚
一.耦合性
耦合性是指软件结构中模块相互连接的紧密程度,是模块间相互连接性的度量耦合强度的大小是由模块间接口的复杂程度决定的。
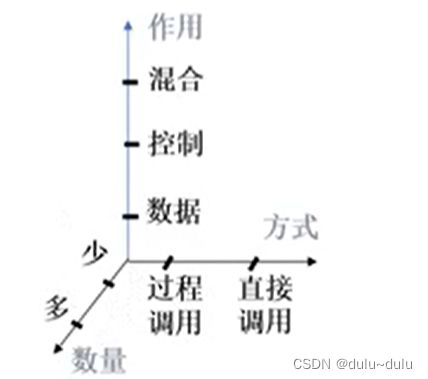
具体从三个方面衡量:
① 方式——块间联系方式由“直接引用”或“过程语句调用”。
② 作用——块间传送的共用信息(参数)类型,可为“数据型”、“控制型”或“混合型” (数据/控制型)
③ 数量——块间传送的共用信息的数量。
模块分解的一个目标是使模块之间的联系尽可能少,实现目标可通过以下措施:
① 每个模块用过程语句(或函数方式等)调用其他模块。
② 模块间传送的参数为数据型。
③ 模块间公用的信息(如参数等) 尽量少
耦合的类型:

1.内容耦合
(1)一个模块直接访问另一模块的内部数据。
(2)一个模块不通过正常入口转到另一模块的内部。
(3)一个模块有多个入口。
(4)两个模块有部分代码重迭。
注:在高级语言中是不允许出现的,但在汇编语言中可能出现(所以在编写汇编语言中,要仔细检查,以免出现内容耦合)。
2.公共耦合
若干模块访问一个公共的数据环境(全局数据结构、共享的通信区、内存的公共覆盖区等)。耦合的复杂程度随耦合模块的数量的增加而显著增加。
公共耦合的两种情况:
•松散公共耦合: 模块同时只对公共数据环境进行读或写一种操作;
注:松散公共耦合是目前使用较多的低耦合方式。
•紧密公共耦合:若干模块对公共数据环境同时读和写操作;
这种耦合使公共数据区的变化影响所有公共耦合模块,严重影响模块的可靠性和可适应,降低软件的可读性。这是一种强耦合方式。
例如:
•无法控制各个模块对公共数据的存取,严重影响了软件模块的可靠性和适应性;
•使软件的可维护性变差。若一个模块修改了公共区的数据,则会影响与此数据相关的所有模块;
•降低了软件的可理解性。因为各个模块使用公共区数据的方式是隐含的,哪些数据被哪些模块共享,不容易搞明白,诊断错误困难。

一般来说,仅当模块间共享的数据很多,且通过参数的传递很不方便时才使用公共耦合。
3.外部耦合
一组模块都访问同一全局简单变量(而不是同一全局数据结构 ),而且不是通过参数表传递该全局变量的信息。
例如:static 静态变量就属于全局变量,会造成模块间耦合度较高,尽量少用全局变量
4.控制耦合
一个模块传递给另一模块的信息是用于控制该模块内部逻辑的控制信号。显然,对被控制模块的任何修改,都会影响控制模块。
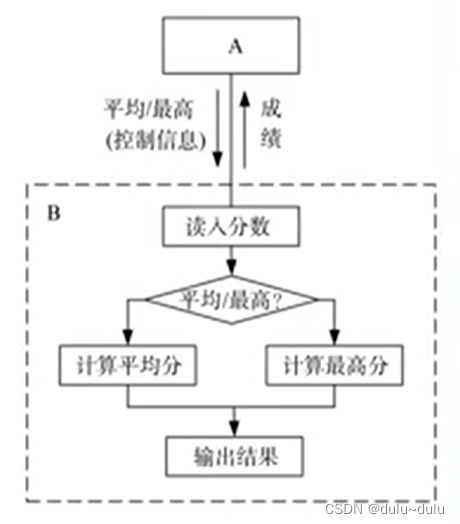
改进:控制耦合中被调函数的判定,上移到主调函数当中,即可从控制耦合转化为数据耦合

5.标记耦合(特征耦合)
一个模块传送给另一个模块的参数是一个复合的数据结构。模块间共享了数据结构,如高级语言中的数组名、记录名等,其实传递的是这些数据结构的地址。标记耦合会使某些本来无关的模块产生相互依赖性,同时由于某些模块包含了不需要的数据,也给纠错带来了麻烦。
当我通过住户情况查用水量时,我只需要查用水量,但是同时也将用电量等其他数据也一起查询了
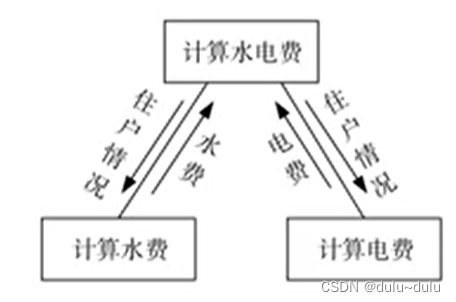
改进:将特征耦合转化为数据耦合
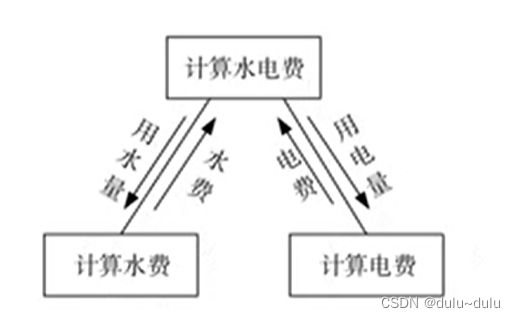
6.数据耦合
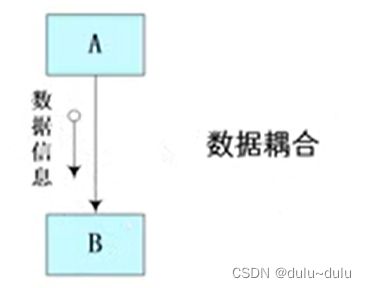
一个模块传送给另一个模块的参数是一个单个的数据项或者单个数据项组成的数组。模块间传递的是简单的数据值,相当于高级语言中的值传递。
7.非直接耦合
两个模块间没有直接的关系,它们分别从属于不同模块的控制与调用,它们之间不传递任何信息。这种耦合程度最弱,模块的独立性最高。
二.内聚性
内聚性表示一个模块内部各个元素(数据、处理)之间联系的紧密程度。显然,块内联系愈紧,即内聚性愈高,模块独立性愈好。
1.偶然内聚
又称为巧合型,为了节约空间,将毫无关系( 或者联系不多)的各元素放在一个模块中。模块元素关系松散,显然不易理解、不易修改。
P,Q,R中都有以下三行代码,但是三条语句毫无关系,并且A,B,C,D都不在CARD FILE当中,只是想要少写一些代码,就建立了模块T,模块T本身没有意义,这就是偶然内聚。
虽然空间上节省了部分空间,但是P,Q,R都需要调用模块T,效率上也是有损失的,不推荐。

2.逻辑内聚
将几个逻辑上相似的功能放在一个模块中,使用时由调用模块传递的参数确定执行的功能。
由于要传递控制参数,所以影响了模块的内聚性。
在图中,被调用模块首先要判定传递参数的含义,才能确定是进行读还是写操作。所以如果二者之间是控制耦合,那么被调用模块就是逻辑内聚型的模块。

3.时间内聚
又称为经典内聚。是把需要同时执行的成分放在一个模块中。比如初始化、中止操作这一类内部结构比较简单的模块。由于判定较少,因此比逻辑内聚高,但是由于内含多个功能,修改和维护困难。

4.过程内聚
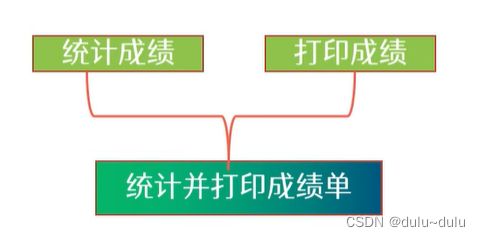
一个模块内的处理元素是相关的,而且必须以特定的次序执行。一个模块内有多个功能成分。如:
5.通信内聚
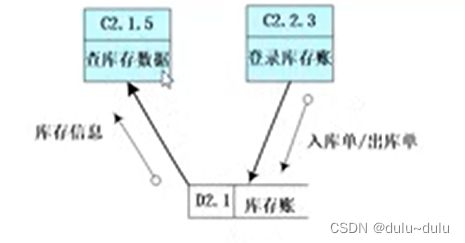
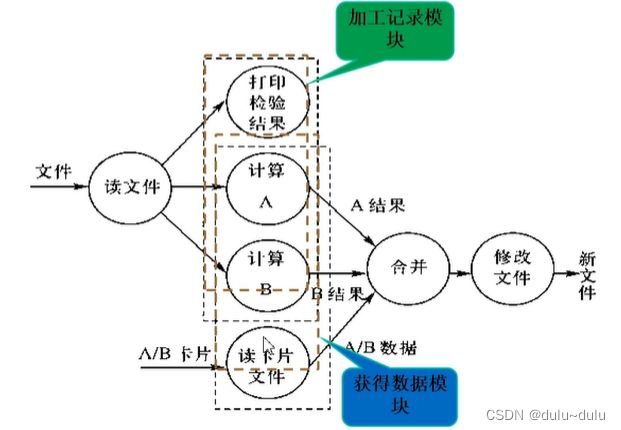
模块中的成分引用共同的输入数据,或者产生相同的输出数据,则称为是通信内聚。下图中,加工记录模块和获得数据模块就是这样(加工数据模块与获得数据模块不会同时出现)。
通信内聚比时间内聚的内聚性高。这种模块一般可以通过数据流图来定义。
6.顺序内聚
一个模块内的处理元素都密切相关于同一功能,模块中某个成分的输出是另一成分的输入。
由于这类模块是按数据执行顺序,模块的一部分依赖于另外一部分,因此具有较好的内聚性。
例如,某模块完成二分检索功能,前一部分功能元素按某关键字递增排列,随后的功能按某关键字进行二分检索。
在下图中,编辑功能的输入是读入功能的输出,打印功能的输入是累加功能的输出。

注:顺序内聚模块可能含有多个功能,也可能只含有不完整的部分功能。当模块含有多个功能时,如果修改某一功能,就要找出模块中这个功能的全部部分,修改时还要注意对其他功能的影响:如果模块只含有不完整的部分功能,修改时需要找出与完整功能有关的若干个相邻模块还需要了解这些模块都做些什么事情。
7.功能内聚
一个模块包括而且仅包括完成某一具体功能所必须的所有成分。或者说,模块的所有成分都是为完成该功能而协同工作、紧密联系、不可分割的。
编写或更改某个功能模块时,不需要考虑其他因素,该模块相对于其他模块也是独立的
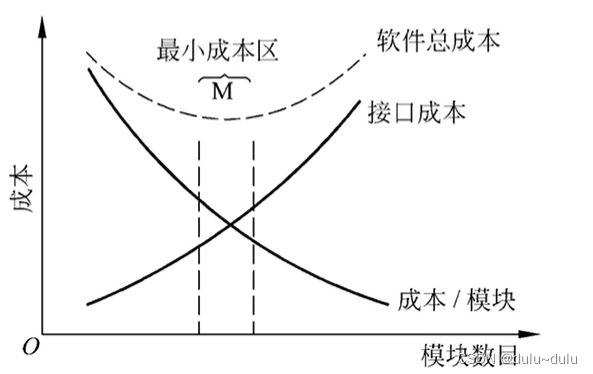
注:我们可以看到,模块越细分,模块的内聚性是越高的,那么是不是模块越细分越好呢,其实不然,模块细分,那么模块数目也会增加,如图,当模块数目增加时每个模块的规模将减小,开发单个模块需要的成本(工作量)确实减少了;但是,随着模块数目增加,设计模块间接口所需要的工作量也将增加。