数模学习day09-cftool使用
老版本的MATLAB可以在命令行使用cftool打开,2017a的版本可以直接找到。
x和y在你的工作区中需要已经存在,然后打开该工具箱就可以看见。
选择X和Y

xy选择好之后就自动画好了拟合曲线。
Results分析

画好之后结果就呈现在这里了
这里的p1就是拟合系数,也就是前一篇文章的k
p2就是前面文章的b
p1和p2后面就是置信区间
SSE就是误差平方和
R-square就是拟合优度,就是R方,调整R方用于归回,RMSE是均方标度差先不用管。
选择拟合方式
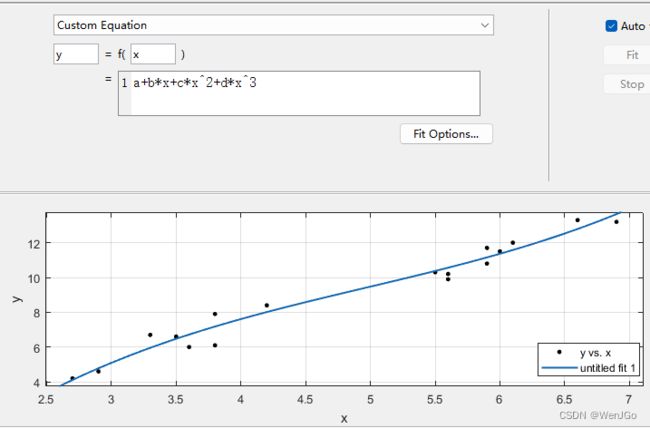
Custom Equation
使用这个就是自己使用写函数,比较灵活
Polynomial
这个是多项式拟合,可以指定阶数

里面有一个Center and scale 就是标准化,去除量纲的影响
s是标准差
公式就是:![]()
Exponential
这个就是指数
总览
进入曲线拟合工具箱界面“Curve Fitting tool”
(1)点击“Data”按钮,弹出“Data”窗口;
(2)利用X data和Y data的下拉菜单读入数据x,y,可修改数据集名“Data set name”,然后点击“Create data set”按钮,退出“Data”窗口,返回工具箱界面,这时会自动画出数据集的曲线图;
(3)点击“Fitting”按钮,弹出“Fitting”窗口;
(4)点击“New fit”按钮,可修改拟合项目名称“Fit name”,通过“Data set”下拉菜单选择数据集,然后通过下拉菜单“Type of fit”选择拟合曲线的类型,工具箱提供的拟合类型有:
Custom Equations:用户自定义的函数类型
Exponential:指数逼近,有2种类型, a*exp(b*x) 、 a*exp(b*x) + c*exp(d*x)
Fourier:傅立叶逼近,有7种类型,基础型是 a0 + a1*cos(x*w) + b1*sin(x*w)
Gaussian:高斯逼近,有8种类型,基础型是 a1*exp(-((x-b1)/c1)^2)
Interpolant:插值逼近,有4种类型,linear、nearest neighbor、cubic spline、shape-preserving
Polynomial:多形式逼近,有9种类型,linear ~、quadratic ~、cubic ~、4-9th degree ~
Power:幂逼近,有2种类型,a*x^b 、a*x^b + c
Rational:有理数逼近,分子、分母共有的类型是linear ~、quadratic ~、cubic ~、4-5th degree ~;此外,分子还包括constant型
Smoothing Spline:平滑逼近(翻译的不大恰当,不好意思)
Sum of Sin Functions:正弦曲线逼近,有8种类型,基础型是 a1*sin(b1*x + c1)
Weibull:只有一种,a*b*x^(b-1)*exp(-a*x^b)
选择好所需的拟合曲线类型及其子类型,并进行相关设置:
——如果是非自定义的类型,根据实际需要点击“Fit options”按钮,设置拟合算法、修改待估计参数的上下限等参数;
——如果选Custom Equations,点击“New”按钮,弹出自定义函数等式窗口,有“Linear Equations线性等式”和“General Equations构造等式”两种标签。
在本例中选Custom Equations,点击“New”按钮,选择“General Equations”标签,输入函数类型y=a*x*x + b*x,设置参数a、b的上下限,然后点击OK。
(5)类型设置完成后,点击“Apply”按钮,就可以在Results框中得到拟合结果,如下例:
general model:
f(x) = a*x*x+b*x
Coefficients (with 95% confidence bounds):
a = 0.009194 (0.009019, 0.00937)
b = 1.78e-011 (fixed at bound)
Goodness of fit:
SSE: 6.146
R-square: 0.997
Adjusted R-square: 0.997
RMSE: 0.8263
同时,也会在工具箱窗口中显示拟合曲线。
这样,就完成一次曲线拟合啦,十分方便快捷。当然,如果你觉得拟合效果不好,还可以在“Fitting”窗口点击“New fit”按钮,按照步骤(4)~(5)进行一次新的拟合。
不过,需要注意的是,cftool 工具箱只能进行单个变量的曲线拟合,即待拟合的公式中,变量只能有一个。对于混合型的曲线,例如 y = a*x + b/x ,工具箱的拟合效果并不好。
使用过Matlab的拟合、优化和统计等工具箱的网友,会经常遇到下面几个名词:
SSE(和方差、误差平方和):The sum of squares due to error
MSE(均方差、方差):Mean squared error
RMSE(均方根、标准差):Root mean squared error
R-square(确定系数):Coefficient of determination
Adjusted R-square:Degree-of-freedom adjusted coefficient of determination
下面我对以上几个名词进行详细的解释下,相信能给大家带来一定的帮助!!
一、SSE(和方差)
该统计参数计算的是拟合数据和原始数据对应点的误差的平方和,计算公式如下
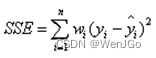
(这个权重没有特殊说明全部取1)
SSE越接近于0,说明模型选择和拟合更好,数据预测也越成功。接下来的MSE和RMSE因为和SSE是同出一宗,所以效果一样
二、MSE(均方差)
该统计参数是预测数据和原始数据对应点误差的平方和的均值,也就是SSE/n,和SSE没有太大的区别,计算公式如下
![]()
三、RMSE(均方根)
该统计参数,也叫回归系统的拟合标准差,是MSE的平方根,就算公式如下

在这之前,我们所有的误差参数都是基于预测值(y_hat)和原始值(y)之间的误差(即点对点)。从下面开始是所有的误差都是相对原始数据平均值(y_ba)而展开的(即点对全)!!!
四、R-square(确定系数)
在讲确定系数之前,我们需要介绍另外两个参数SSR和SST,因为确定系数就是由它们两个决定的
(1)SSR:Sum of squares of the regression,即预测数据与原始数据均值之差的平方和,公式如下
![]()
(2)SST:Total sum of squares,即原始数据和均值之差的平方和,公式如下
![]()
细心的网友会发现,SST=SSE+SSR,呵呵只是一个有趣的问题。而我们的“确定系数”是定义为SSR和SST的比值,故
![]()
其实“确定系数”是通过数据的变化来表征一个拟合的好坏。由上面的表达式可以知道“确定系数”的正常取值范围为[0 1],越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
保存生成好的图像
(1)点击左上角的文件
(2)点击Print to Figure
(3)这时多了一个窗口,再点击左上角的文件
(4)点击导出设置
(5)又出来了一个新的窗口,点击右边的导出即可
通过工具箱得到对应的代码
(1)点击文件
(2)点击Generate Code
(3)就默认会弹出来一个代码了
function [fitresult, gof] = createFit(x, y)
%CREATEFIT(X,Y)
% Create a fit.
%
% Data for 'untitled fit 1' fit:
% X Input : x
% Y Output: y
% Output:
% fitresult : a fit object representing the fit.
% gof : structure with goodness-of fit info.
%
% 另请参阅 FIT, CFIT, SFIT.
% 由 MATLAB 于 09-Jan-2024 15:43:40 自动生成
%% Fit: 'untitled fit 1'.
[xData, yData] = prepareCurveData( x, y );
% Set up fittype and options.
ft = fittype( 'poly1' );
% Fit model to data.
[fitresult, gof] = fit( xData, yData, ft );
% Plot fit with data.
figure( 'Name', 'untitled fit 1' );
h = plot( fitresult, xData, yData );
legend( h, 'y vs. x', 'untitled fit 1', 'Location', 'NorthEast' );
% Label axes
xlabel x
ylabel y
grid on
end
你要在其他地方调用的话,只需要将

这里拷贝到其他地方就可以使用了。
但是名字,图像标签什么的可以修改修改,不要直接使用
实战:利用拟合工具箱预测美国人口

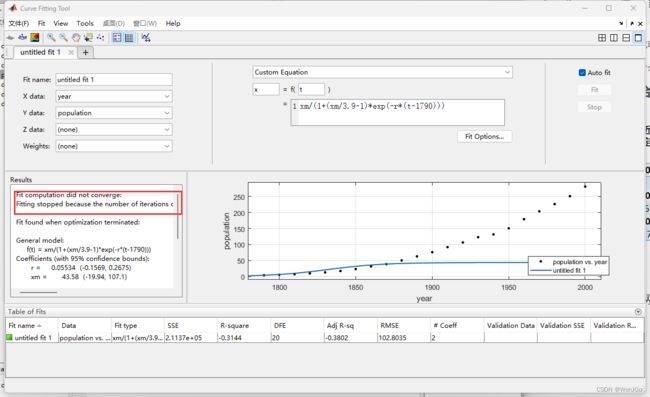
由图像可看到后面完全不在点上,没有收敛,那就是拟合设置有问题。
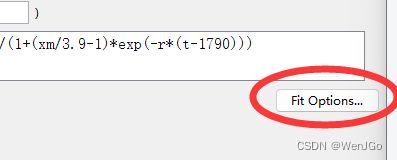
更改初始值(起始点)
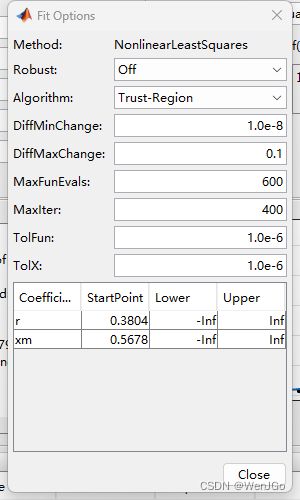
例如修改Xm到100
clear;clc
year = 1790:10:2000;
population = [3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];
plot(year,population,'-o')
cftool % 拟合工具箱
% (1) X data 选择 year
% (2) Y data 选择 population
% (3) 拟合方式选择:Custom Equation (自定义方程)
% (4) 修改下方的方框为:x = f(t) = xm/(1+(xm/3.9-1)*exp(-r*(t-1790)))
% (5) 左边的result一栏最上面显示:Fit computation did not converge:即没有找到收敛解,右边的拟合图形也表明拟合结果不理想
% (6) 点击Fit Options,修改非线性最小二乘估计法拟合的初始值(StartPoint), r修改为0.02,xm修改为500
% 有很多同学有疑惑,初始值为什么要这样设置?我们在未来学习微分方程模型和智能算法的课程时再来给大家介绍这里面蕴含的技巧。
% (7) 此时左边的result一览得到了拟合结果:r = 0.02735, xm = 342.4
% (8) 依次点击拟合工具箱的菜单栏最左边的文件—Generate Code(导出代码到时候可以放在你的论文附录),可以得到一个未命名的脚本文件
% (9) 在这个打开的脚本中按快捷键Ctrl+S,将这个文件保存到当前文件夹。
% (10) 在现在这个文件中调用这个函数得到参数的拟合值和预测的效果
[fitresult, gof] = createFit(year, population)
t = 2001:2030;
xm = 342.4;
r = 0.02735;
predictions = xm./(1+(xm./3.9-1).*exp(-r.*(t-1790))); % 计算预测值(注意这里要写成点乘和点除,这样可以保证按照对应元素进行计算)
figure(2)
plot(year,population,'o',t,predictions,'.') % 绘制预测结果图
这里R方没有意义,因为x和R不是线性的
代码
clear;clc
year = 1790:10:2000;
population = [3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];
plot(year,population,'-o')
cftool % 拟合工具箱
% (1) X data 选择 year
% (2) Y data 选择 population
% (3) 拟合方式选择:Custom Equation (自定义方程)
% (4) 修改下方的方框为:x = f(t) = xm/(1+(xm/3.9-1)*exp(-r*(t-1790)))
% (5) 左边的result一栏最上面显示:Fit computation did not converge:即没有找到收敛解,右边的拟合图形也表明拟合结果不理想
% (6) 点击Fit Options,修改非线性最小二乘估计法拟合的初始值(StartPoint), r修改为0.02,xm修改为500
% 有很多同学有疑惑,初始值为什么要这样设置?我们在未来学习微分方程模型和智能算法的课程时再来给大家介绍这里面蕴含的技巧。
% (7) 此时左边的result一览得到了拟合结果:r = 0.02735, xm = 342.4
% (8) 依次点击拟合工具箱的菜单栏最左边的文件—Generate Code(导出代码到时候可以放在你的论文附录),可以得到一个未命名的脚本文件
% (9) 在这个打开的脚本中按快捷键Ctrl+S,将这个文件保存到当前文件夹。
% (10) 在现在这个文件中调用这个函数得到参数的拟合值和预测的效果
[fitresult, gof] = createFit(year, population)
t = 2001:2030;
xm = 342.4;
r = 0.02735;
predictions = xm./(1+(xm./3.9-1).*exp(-r.*(t-1790))); % 计算预测值(注意这里要写成点乘和点除,这样可以保证按照对应元素进行计算)
figure(2)
plot(year,population,'o',t,predictions,'.') % 绘制预测结果图
课后作业
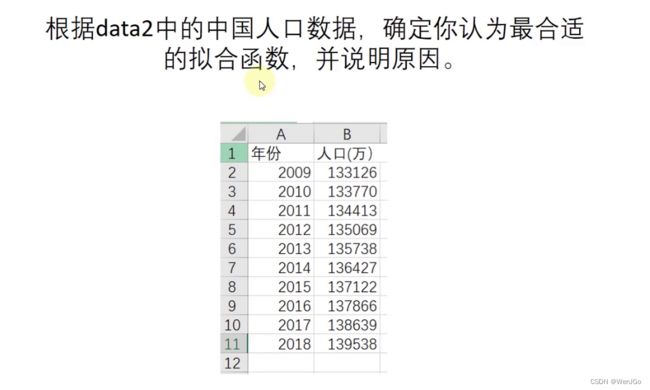
┏(^0^)┛