基于传统机器学习模型算法的项目开发详细步骤
1 场景分析
1.1 项目背景
描述开发项目模型的一系列情境和因素,包括问题、需求、机会、市场环境、竞争情况等
1.2. 解决问题
传统机器学习在解决实际问题中主要分为两类:
- 有监督学习:已知输入、输出之间的关系而进行的学习,从而产生一个能够对已知输入给出合适输出的模型。这些算法在图像分类、语音识别、自然语言处理、推荐系统等领域有着广泛的应用
- 无监督学习:已知输入,无输出结果而进行的学习,发现数据中的潜在特征和规律而训练的模型。这些算法在数据挖掘、图像处理、自然语言处理等领域有着广泛的应用
传统机器学习达到的目的主要分为两类
- 分析影响结果的主要因素
- 充分必要条件下预测结果
传统机器学习算法在实际开发中主要分两类
- 基于树的算法
- 非基于树的算法
2 数据整体情况
2.1 数据加载
数据分析3剑客:numpy pandas matplotlib
# 导入相关包
import os
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_rows', None)
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
import seaborn as sns
import plotly.express as px
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
import holoviews as hv
from holoviews import opts
hv.extension('bokeh')
1、 pandas读取数据: pd.read_csv(),训练数据一般从csv文件加载。读取数据返回DataFrame,df.head() 查看前5条件数据分布
# 读取数据
df = pd.read_csv('./xxx.csv')
df.head()

2、查看数据总体信息
df.info()

3、 查看数据描述
# 数据总数、平均值、标准差、最大最小值,25% 50% 75% 分位值
df.describe().T

4、统计数据空值
df.isnull().sum()

5、 查看数据形状
df.shape
![]()
6、查看数据类型
df.dtypes

2.2 样本是否均衡
如果正、负样本不均衡怎么做?
- 大样本变少——下采样
- 小样本变多——上采样
- 实际应用中,上采样较多,将真实的数据做重复冗余
2.3 数据分析
以下为案例:
- 绘制直方图
fig = px.histogram(df, x='列名', hover_data=df.columns, title='XXX分布', barmode='group')
fig.show()

fig = px.histogram(df, x='TPC_LIP', color='TPC_LIP', hover_data=df.columns, title='罐盖分布', barmode='group')
fig.show()

temp_agg = df.groupby('OUTER_TEMPERATURE').agg({'TEMPERATURE': ['min', 'max']})
temp_maxmin = pd.merge(temp_agg['TEMPERATURE']['max'],temp_agg['TEMPERATURE']['min'],right_index=True,left_index=True)
temp_maxmin = pd.melt(temp_maxmin.reset_index(), ['OUTER_TEMPERATURE']).rename(columns={'OUTER_TEMPERATURE':'OUTER_TEMPERATURE', 'variable':'Max/Min'})
hv.Bars(temp_maxmin, ['OUTER_TEMPERATURE', 'Max/Min'], 'value').opts(title="Temperature by OUTER_TEMPERATURE Max/Min", ylabel="TEMPERATURE")\
.opts(opts.Bars(width=1000, height=700,tools=['hover'],show_grid=True))

- 绘制分布图
hv.Distribution(np.round(df['列名'])).opts(title='标题', color='green', xlabel='x轴标签名', ylabel='y轴标签名')\
.opts(opts.Distribution(width=1000, height=600, tools=['hover'], show_grid=True))

hv.Distribution(df['BF_IRON_DUR']).opts(title='XXX时长', color='red', xlabel='时长(秒)', ylabel='Destiny')\
.opts(opts.Distribution(width=1000, height=600, tools=['hover'], show_grid=True))

- 寻找特征偏态(skewness)和核密度估计(Kernel density estimate KDE)
plt.figure(figsize=(15,10))
for i,col in enumerate(df.columns, 1):
plt.subplot(5,3,i)
plt.title(f"Distribution of {col} Data")
sns.histplot(df[col],kde=True)
plt.tight_layout()
plt.plot()

- 绘制曲线图
iron_temp = df['IRON_TEMPERATURE'].iloc[:300]
temp = df['TEMPERATURE'].iloc[:300]
(hv.Curve(iron_temp, label='XXX') * hv.Curve(temp, label='XXX')).opts(title="XXXX温度对比", ylabel="IRON_TEMPERATURE", xlabel='TEMPERATURE')\
.opts(opts.Curve(width=1500, height=500,tools=['hover'], show_grid=True))

3 数据处理
3.1 数据清洗
3.1.1离群值
利用箱形图找出离群值并可过滤剔除
Minimum 最小值
First quartile 1/4分位值
Median 中间值
Third quartile 3/4分位值
Maximum 最大值
- XXX离群值1

- XXX离群值2
fig = px.box(df, y='XXX', title='XXXXX')
fig.show()

3.1.2空数据处理
如果数据量比较大,查出空数据的行或列删除即可,反之要珍惜现有的数据样本
可采用以下两种方法进行补全
- 随机森林补全
# 引入随机森林模型
from sklearn.ensemble import RandomForestRegressor
# 随机森林模型
rfr = RandomForestRegressor(random_state=None, n_estimators=500, n_jobs=-1)
# 利用已知输入和输出数据进行模型训练
rfr.fit(known_X, known_y)
# 输出模型得分
score = rfr.score(known_X, known_y)
print('模型得分', score)
# 获得缺失的特征数据X预测并补全
unknown_predict = rfr.predict(unKnown_X)
- 简单归类补全
# 引入简单归类包
from sklearn.impute import SimpleImputer
# 对缺失的列进行平均值补全
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# 进行模型训练
imputer = imputer.fit_transform(df[['TEMPERATURE']])
# 输出训练结果
imputer

3.2 特征工程
特征衍生、选择、缩放、分布、重要性
-
特征衍生: 特征转换和特征组合
特征转换——单特征自己进行变换,例如取绝对值、进行幂函数变换等
特征组合——多特征之间组合变换,如四则运算、交叉组合、分组统计等
3.2.1 特征选择
corr相关性系数,删除相关性强、冗余的特征,对分析权重很重要
# 浅颜色代表正相关 深颜色代表负相关
plt.figure(figsize=(16, 16))
sns.heatmap(df.corr(), cmap='BrBG', annot=True, linewidths=.5)
_ = plt.xticks(rotation=45)

3.2.2 特征缩放
- 受特征缩放的影响:距离算法 KNN K-means SVM 等

- 不受特征缩放的影响:基于树的算法

缩放方法
-
归一化
最大、最小值 0~1 之间,适合非高斯分布 K-Nearest Neighbors and Neural Networks

-
标准化
适合高斯分布,但也可不是高斯分布。平均值为0,标准差为1,即使有异常值不受影响

-
Robust Scaler(鲁棒缩放)
计算上下四分位数(Q1和Q3)之间的差值,每个数据点减去下四分位数(Q1),再除以四分位数范围(Q3-Q1)
# data
x = pd.DataFrame({
# Distribution with lower outliers
'x1': np.concatenate([np.random.normal(20, 2, 1000), np.random.normal(1, 2, 25)]),
# Distribution with higher outliers
'x2': np.concatenate([np.random.normal(30, 2, 1000), np.random.normal(50, 2, 25)]),
})
np.random.normal
scaler = preprocessing.RobustScaler()
robust_df = scaler.fit_transform(x)
robust_df = pd.DataFrame(robust_df, columns =['x1', 'x2'])
scaler = preprocessing.StandardScaler()
standard_df = scaler.fit_transform(x)
standard_df = pd.DataFrame(standard_df, columns =['x1', 'x2'])
scaler = preprocessing.MinMaxScaler()
minmax_df = scaler.fit_transform(x)
minmax_df = pd.DataFrame(minmax_df, columns =['x1', 'x2'])
fig, (ax1, ax2, ax3, ax4) = plt.subplots(ncols = 4, figsize =(20, 5))
ax1.set_title('Before Scaling')
sns.kdeplot(x['x1'], ax = ax1, color ='r')
sns.kdeplot(x['x2'], ax = ax1, color ='b')
ax2.set_title('After Robust Scaling')
sns.kdeplot(robust_df['x1'], ax = ax2, color ='red')
sns.kdeplot(robust_df['x2'], ax = ax2, color ='blue')
ax3.set_title('After Standard Scaling')
sns.kdeplot(standard_df['x1'], ax = ax3, color ='black')
sns.kdeplot(standard_df['x2'], ax = ax3, color ='g')
ax4.set_title('After Min-Max Scaling')
sns.kdeplot(minmax_df['x1'], ax = ax4, color ='black')
sns.kdeplot(minmax_df['x2'], ax = ax4, color ='g')
plt.show()

3.2.3 类别特征处理
- 非基于树的算法最好的方式——独热编码
# 独热编码
feature_col_nontree = ['TPC_AGE','TPC_LID','BF_START_WAITING', 'BF_IRON_DUR', 'BF_END_WAITING', 'BF_RAIL_DUR', 'RAIL_STEEL_DUR',
'EMPTY_START_WAITING', 'EMPTY_DUR', 'EMPTY_END_WAITING', 'STEEL_RAIL_DUR', 'RAIL_BF_DUR','TOTAL_TIME','OUTER_TEMPERATURE']
fullSel=pd.get_dummies(feature_col_nontree)

- 基于树的算法最好的方式——标签编码
df_tree = df.apply(LabelEncoder().fit_transform)
df_tree.head()
3.2.4 特征重要性
注意:只有在特征没有冗余或被拆分的情况下,分析特征的重要性才有意义
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X, y)
clf.feature_importances_
plt.rcParams['figure.figsize'] = (12, 6)
plt.style.use('fivethirtyeight')
feature = list(X.columns)
importances = clf.feature_importances_
feat_name = np.array(feature)
index = np.argsort(importances)[::-1]
plt.bar(range(len(index)), importances[index], color='lightblue')
plt.step(range(15), np.cumsum(importances[index]))
_ = plt.xticks(range(15), labels=feat_name[index], rotation='vertical', fontsize=14)

4 构建模型
4.1 数据拆分
训练数据80% 测试数据20%
训练数据80% 在分80%为训练数据,20%为验证数据
from sklearn.model_selection import train_test_split
X = df.drop('TEMPERATURE', axis=1)
y = df['TEMPERATURE']
X_train_all, X_test, y_train_all, y_test = train_test_split(X, y, test_size=0.2)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_all, y_train_all, test_size=0.2)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
print(X_valid.shape, y_valid.shape)

4.2 选用算法
非基于树的算法
- LinearRegression
- LogisticRegression
- Naive Bayes
- SVM
- KNN
- K-Means
基于树的算法
- Decission Trees
- Extra Trees
- Random Forest
- XGBoost
- GBM
- LightGBM
4.2 数据交叉验证
- k-fold cross-validation:
k个不相交的子集,其中一个子集作为测试集,其余的子集作为训练集。重复k次 - stratified k-fold cross-validation (样本分布不均匀情况下使用)

4.3 算法比较优选
# 导入机器学习 线性回归为例
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, ExtraTreesRegressor
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold
# 设置kfold 交叉采样法拆分数据集
kfold = StratifiedKFold(n_splits=10)
# 汇总不同模型算法
regressors = []
regressors.append(SVR())
regressors.append(DecisionTreeRegressor())
regressors.append(RandomForestRegressor())
regressors.append(ExtraTreesRegressor())
regressors.append(GradientBoostingRegressor())
regressors.append(KNeighborsRegressor())
regressors.append(LinearRegression())
regressors.append(LinearDiscriminantAnalysis())
regressors.append(XGBRegressor())
# 不同机器学习交叉验证结果汇总
cv_results = []
for regressor in regressors:
cv_results.append(cross_val_score(estimator=regressor, X=X_train, y=y_train,
scoring='neg_mean_squared_error',
cv=kfold, n_jobs=-1))
# 求出模型得分的均值和标准差
cv_means = []
cv_std = []
for cv_result in cv_results:
cv_means.append(cv_result.mean())
cv_std.append(cv_result.std())
# 汇总数据
cvResDf = pd.DataFrame({'cv_mean': cv_means,
'cv_std': cv_std,
'algorithm':['SVC','DecisionTreeReg','RandomForestReg','ExtraTreesReg',
'GradientBoostingReg','KNN','LR','LDA', 'XGB']})
cvResDf
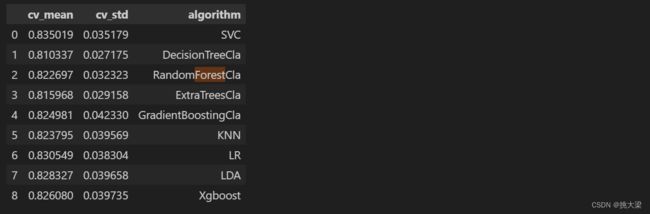
bar = sns.barplot(data=cvResDf.sort_values(by='cv_mean', ascending=False),
x='cv_mean', y='algorithm', **{'xerr': cv_std})
bar.set(xlim=(0.7, 0.9))

4.3 深度学习效果
tesorflow
import keras
d_model = keras.models.Sequential()
d_model.add(keras.layers.Dense(units=256, activation='relu', input_shape=(X_train_scaler.shape[1:])))
d_model.add(keras.layers.Dense(units=128, activation='relu'))
d_model.add(keras.layers.Dense(units=1))
out_put_dir = './'
if not os.path.exists(out_put_dir):
os.mkdir(out_put_dir)
out_put_file = os.path.join(out_put_dir, 'model.keras')
callbacks = [
keras.callbacks.TensorBoard(out_put_dir),
keras.callbacks.ModelCheckpoint(out_put_file, save_best_only=True, save_weights_only=True),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)
]
d_model.compile(optimizer='Adam', loss='mean_squared_error', metrics=['mse'])
history = d_model.fit(X_train_scaler, y_train, epochs=100, validation_data=(X_valid_scaler, y_valid), callbacks=callbacks)

pytorch
import pandas as pd
import torch
from torch import nn
data = pd.read_csv('XXX.csv', header=None)
print(data.head())
X = data.iloc[:, :-1]
print(X.shape)
Y = data.iloc[:, -1]
Y.replace(-1, 0, inplace=True)
print(Y.value_counts())
X = torch.from_numpy(X.values).type(torch.FloatTensor)
Y = torch.from_numpy(Y.values.reshape(-1, 1)).type(torch.FloatTensor)
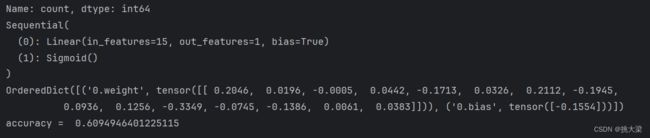
model = nn.Sequential(
nn.Linear(15, 1),
nn.Sigmoid()
)
print(model)
loss_fn = nn.BCELoss()
opt = torch.optim.SGD(model.parameters(), lr=0.0001)
batch_size = 32
steps = X.shape[0] // batch_size
for epoch in range(1000):
for batch in range(steps):
start = batch * batch_size
end = start + batch_size
x = X[start:end]
y = Y[start:end]
y_pred = model(x)
loss = loss_fn(y_pred, y)
opt.zero_grad()
loss.backward()
opt.step()
print(model.state_dict())
accuracy = ((model(X).data.numpy() > 0.5) == Y.numpy()).mean()
print('accuracy = ', accuracy)
5 模型优化
5.1 网络搜索
选择表现优秀的模型
- DecisionTreeRegressor模型
#DecisionTreeRegressor模型
GTR = DecisionTreeRegressor()
gb_param_grid = {
'criterion': ['squared_error', 'friedman_mse', 'absolute_error', 'poisson'],
'splitter': ['best', 'random'],
'max_depth': [4, 8],
'min_samples_leaf': [100,150],
'max_features': [0.3, 0.1]
}
modelgsGTR = GridSearchCV(GTR,param_grid = gb_param_grid, cv=kfold,
scoring="neg_mean_squared_error", n_jobs= -1, verbose = 1)
modelgsGTR.fit(X_train,y_train)
modelgsGTR.best_score_
- xgboost
import xgboost as xgb
params = {'objective':'reg:linear',
'booster':'gbtree',
'eta':0.03,
'max_depth':10,
'subsample':0.9,
'colsample_bytree':0.7,
'silent':1,
'seed':10}
num_boost_round = 6000
dtrain = xgb.DMatrix(X_train, y_train)
dtest = xgb.DMatrix(X_test, y_test)
evals = [(dtrain, 'train'), (dtest, 'validation')]
gbm = xgb.train(params, # 模型参数
dtrain, # 训练数据
num_boost_round, # 轮次,决策树的个数
evals=evals, # 验证,评估的数据
early_stopping_rounds=100, # 在验证集上,当连续n次迭代,分数没有提高后,提前终止训练
verbose_eval=True) # 打印输出log日志,每次训练详情
6 模型评估
-
Accuracy 准确率
-
Precision 精确率
-
Recall 召回率
-
F1 score (F1)
-
ROC/AUC

-
Log loss 损失函数
- 线性回归
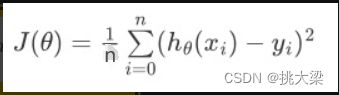
- 逻辑回归

请尊重别人的劳动成果 转载请务必注明出处