经典目标检测YOLO系列(二)YOLOv2算法详解
经典目标检测YOLO系列(二)YOLOv2算法详解
YOLO-V1以完全端到端的模式实现达到实时水平的目标检测。但是,YOLO-V1为追求速度而牺牲了部分检测精度,在检测速度广受赞誉的同时,其检测精度也饱受诟病。正是由于这个原因,YOLO团队在2016年提出了YOLO的第一个改进版本—YOLO-V2。
该论文题目,直接指出了该模型的存在三大特点——更好(better)、更快(faster)、更强(stronger)。
-
更好(better),就是YOLO-V1通过使用批归一化(Batch Normalization, BN)、基于卷积的锚点机制等一系列技术手段,使得目标检测精度较YOLO-V1有了大幅度提高; -
更快(faster),就是YOLO-V2通过改进网络结构,在小幅降低精度的情况下,大幅减少浮点运算次数以提高模型速度(针对224×224尺寸图像输入的单趟前向传播,由VGG16网络的300亿次浮点运算降低至80亿次); -
更强(stronger),就是基于YOLO-V2构建YOLO-9000模型,通过采用联合训练(jointly training)机制,综合发挥目标检测任务数据集和图像分类任务数据集的综合优势(目标检测数据集图像数量少、目标类别少但提供精确的目标位置信息,而分类数据集无目标位置信息,但类别数多且图像数量庞大),使得支持的检测目标类别数从原来的20类大幅扩展至9000类,大大提高了模型的适用性。
“更好”和“更快”主要是说YOLO-V2,“更强”是说YOLO-9000。我们主要讲解YOLO-V2。
1 YOLOv2的改进之处
1.1 添加BN层
-
在最初的YOLOv1网络中,每一层卷积的结构都是线性卷积和激活函数,并没有使用当前十分流行的诸如:批归一化(batch normalization,BN)、层归一化(layer normalization,LN)、实例归一化(instance normalization,IN)等归一化层。
-
到了YOLOv2的研究时代,BN层已经广泛应用于cv领域,成为了标准配置,因此,YOLO作者团队便在原先使用的卷积层中添加了BN层。
-
在加入了BN层后,网络在训练阶段可以回传更稳定的梯度流,因而理所当然地提升了YOLOv1的性能。在VOC2007测试集上,YOLOv1的mAP指标从原本的63.4% 提升至65.8%,超过2%的提升。
关于常见的归一化操作,可以参考:
Pytorch常用的函数(六)常见的归一化总结(BatchNorm/LayerNorm/InsNorm/GroupNorm)
1.2 高分辨率主干网络
- YOLOv1中,将YOLOv1的Backbone网络放到ImageNet数据集中,使用224×224的图像去做预训练,然后再将训练好的权重作为目标检测任务的Backbone部分的初始化权重(移除最后的全局平均池化层和分类层)。这就是常见的
ImageNet pretraining。 - 使用224×224的图像做预训练,却用448×448的图像做检测,作者认为图像尺寸的前后差异会造成一些负面影响。
- Backbone从较小的224×224的图像所学到的信息远不如448x448的图像丰富,这可能使得Backbone无法学习到更充分的信息。
- 因此,在完成了224x224的图像的预训练后,作者接着又将Backbone网络在448x448的图像上做进一步的“微调”,总共训练10个epoch。
- 完成了这两步的预训练后,再将预训练权重用作Backbone网络的初始化权重。
- 经过这种改进的预训练策略所训练出来的Backbone权重,使得YOLOv1网络获得了第二次的性能提升:在VOC2007测试集上的mAP从65.8% 提升到69.5%,提升很大。
不过,这一技巧并未成为主流训练技巧。- 一个可能的原因就是这个问题可能确实不是很严重,稍微延长训练时间便可以了。
- 如今,视觉的预训练已经从早先的
ImageNet pretraining迈入到了MAE pretraining新纪元。- 图像分类任务通常不会需要太多的细节信息,对于一个类别“猫”,我们不需要知道这只猫都有哪些细节信息,只需要学到猫这一类动物的通用特征即可,这可能会使得Backbone忽略掉很多对下游任务反而很重要的信息。
- 基于
Masked Image Modeling(MIM)思想的MAE pretraining策略则大大强化了Backbone对于图像细节信息以及通过mask所学到的图像的high-level结构信息,从而为下游任务提供了更好的初始化权重。
- 尽管目前的新版本的YOLO已经全面采用了
train from scratch(从零开始训练)策略,但Backbone部分的pretrain研究仍旧是当前视觉领域的最为重要的基础任务之一,因为一个好的预训练权重可以同步提升多个下游任务的性能上限。
1.3 引入Anchor Box机制
锚框(anchor box)的意思便是将一堆边界框预先放置在特征图网格的每一处位置,通常每个位置都放置相同数量的相同尺寸的锚框。如下图所示,每两个网格绘制一次,仅是出于观赏性的考虑,实际上每一个网格都有相同数量的锚框。
Faster R-CNN提出了anchor box,在RPN中,每个网格处设定了k个具有不同尺寸、不同宽高比的anchor box,在训练阶段,RPN网络会为每一个anchor box学习若干偏移量:中心点的偏移量和宽高的偏移量。这些偏移量可以将预先设定好的anchor box尺寸调整至所检测的目标的真实框的尺寸。
由此可见,Faster RCNN提出的anchor box的本质是提供边界框的尺寸先验。因此,anchor box有时也被称为“先验框”。使用先验框的目标检测网络,被称为Anchor-base模型。
很显然,设计先验框的一个难点在于设计多少个先验框,且每个先验框的尺寸(宽高比和面积)又是多少。
- 一类解决方案是以RetinaNet为代表的手动设置,比如使用1 : 1、1 : 3、3 : 1三种宽高比设置和32、64、128、256以及512五种面积设置,从而一共可以确定出15个先验框尺寸;
- 另一类则是以YOLO为代表的基于k-means聚类方法自适应调整先验框的尺寸。
YOLOv2中,在COCO数据集上使用聚类,可以得出5组先验框,参数如下:
[
[17, 25],
[55, 75],
[92, 206],
[202, 21],
[289, 311]
]
我们可以用下面代码,可视化下这5组先验框:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import cv2
def show_anchor_box(picture_path):
# 输入图片尺寸
INPUT_SIZE = 416
mask = [0, 1, 2, 3, 4]
# 在coco数据集上,利用kmeans聚类出来的5组不同宽高的anchor box
anchors = [17, 25,
55, 75,
90, 206,
202, 21,
289, 311]
FEATURE_MAP_SIZE = 13
GRID_SHOW_FLAG = True
img = cv2.imread(picture_path)
print("原始图片的shape: ", img.shape)
img = cv2.resize(img, (INPUT_SIZE, INPUT_SIZE))
# 显示网格,颜色为黑色
if GRID_SHOW_FLAG:
height, width, channels = img.shape
GRID_SIZEX = int(INPUT_SIZE / FEATURE_MAP_SIZE)
for x in range(0, width - 1, GRID_SIZEX):
cv2.line(img, pt1 = (x, 0), pt2 = (x, height), color = (0, 0, 0), thickness = 1, lineType = 1) # x grid
GRID_SIZEY = int(INPUT_SIZE / FEATURE_MAP_SIZE)
for y in range(0, height - 1, GRID_SIZEY):
cv2.line(img, pt1 = (0, y), pt2 = (width, y), color = (0, 0, 0), thickness = 1, lineType = 1) # y grid
for ele in mask:
# 画出图像中心点聚类出来不同宽高的5组anchor box,颜色为红色
# 需要告诉函数的左上角顶点pt1和右下角顶点的坐标pt2
cv2.rectangle(img,
pt1 = ((int(INPUT_SIZE * 0.5 - 0.5 * anchors[ele * 2]), int(INPUT_SIZE * 0.5 - 0.5 * anchors[ele * 2 + 1]))),
pt2 = ((int(INPUT_SIZE * 0.5 + 0.5 * anchors[ele * 2]), int(INPUT_SIZE * 0.5 + 0.5 * anchors[ele * 2 + 1]))),
color = (0, 0, 255),
thickness = 2
)
cv2.imshow('img', img)
while cv2.waitKey(1000) != 27: # loop if not get ESC.
if cv2.getWindowProperty('img', cv2.WND_PROP_VISIBLE) <= 0:
break
cv2.destroyAllWindows()
if __name__ == '__main__':
directory = './imgs'
for filename in os.listdir(directory):
picture_path = os.path.join(directory, filename)
show_anchor_box(picture_path)

1.4 使用全卷积网络结构
-
在YOLOv1中,一个显著的弊病就是网络在最后阶段使用了全连接层。具体来说,YOLOv1先将
[B, C, H, W]格式的特征图拉平成[B, N]格式的向量,然后交给全连接层去处理。这一操作通常会破坏特征图的空间结构。为了解决这一问题,作者便将其改成了全卷积结构,并且添加了Faster R-CNN工作所提出的anchor box机制。- 首先去掉了YOLOv1网络中的
最后一个池化层和所有的全连接层,使得降采样倍数从64变成32,最终得到的也从原先的7x7(对应448x448的图像)变为了13×13(对应416x416的图像)。 - 另外,还在每个网格处都预设了k个具有不同尺寸的anchor box。
- 对于目标的中心点,其学习目标还是中心点偏移量(默认每个网格的anchor box的中心点坐标就是所在的网格左上角坐标);
- 对于目标的宽高,网络只需要学习偏移量去调整anchor box的尺寸即可,无需再将整个边界框的尺寸作为学习标签。
- 首先去掉了YOLOv1网络中的
-
YOLOv1漏检现象的降低
- YOLOv1会在每个网格处预测2个边界框,每个边界框都有自己的置信度,但他们却都共享一组类别的置信度,因此,每个网格处最终只会输出一个物体,倘若一个网格包含了两个以上的物体,那就会漏检
- YOLOv2改为每一个先验框都预测一个边界框置信度和一组类别置信度,即每个边界框都是独立的。因此,改进后的YOLOv1的输出张量大小就从原先的
SxSx(5B+C)变成了现在的S×S×k×(1+4+C)。 - 引入anchor box后,每个网格就最多可以检测K个物体了,相对YOLOv1漏检现象会少。
-
尽管网络结构变成了全卷积网络,并使用了anchor box机制,但YOLOv1的性能却没有表现出预料中的提升,反而从69.5% mAP降至69.2% mAP,有了轻微的下降,但召回率却从81%提升到88%。召回率的提升意味着YOLO可以找出更多的目标了,尽管精度下降了一点点。由此可见,每个网格输出多个检测结果确实有助于网络检测更多的物体。
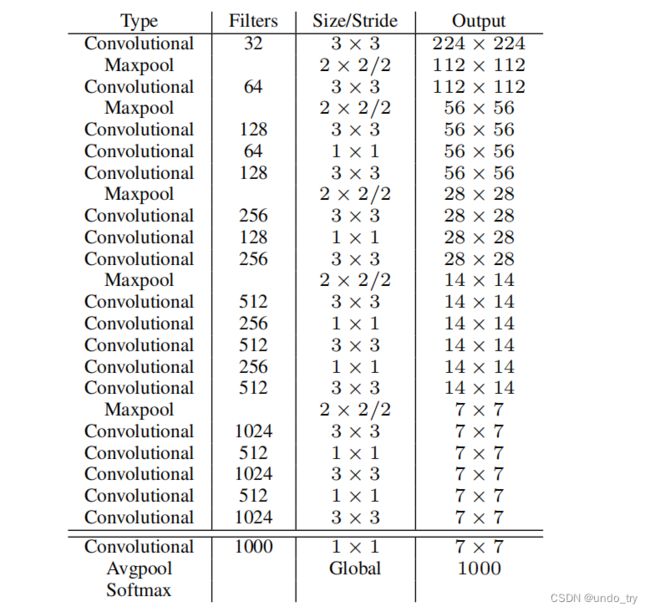
1.5 新的主干网络DarkNet19
-
DarkNet19名字中的19是因为该网络共包含19个卷积层。
-
作者首先将DarkNet19在ImageNet上进行预训练,在验证集上获得了72.9%的top1准确率和91.2%的top5准确率。就预训练的精度而言,DarkNet19网络以更少的参数量达到了当时的VGG网络的水平。
-
预训练完毕后,去掉网络中用于分类任务的全局平均池化层和分类层后,用作Backbone网络的初始化权重,随后将YOLO网络放到检测任务中去做训练和测试。再使用了新的Backbone网络后,YOLOv1的性能从上一次的69.2% mAP提升到69.6% mAP。
-
Convolutional为前面所提到的
卷积三件套:线性卷积+BN层+LeakyReLU激活函数。
1.6 基于k-means聚类方法自适应调整先验框
-
以RetinaNet为代表的先验框的尺寸参数依赖于人工设计。
-
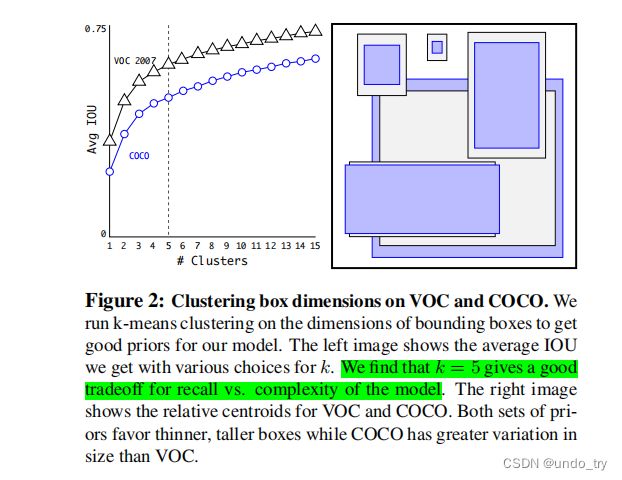
YOLO作者认为人工设定的尺寸不一定够好,并且人工设定的做法又有着一定的局限性。为了去人工化,作者采用kmeans聚类方法去自动地在指定的数据集(如VOC或者COCO)上获取适用于该数据集的k个先验框。
-
聚类的过程中,作者将先验框与目标框的IoU作为优化指标。如下图,聚类出5个先验框。
距离公式如下 : d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) 距离公式如下:\\ d(box,centroid)=1-IOU(box,centroid) 距离公式如下:d(box,centroid)=1−IOU(box,centroid) -
不过,以现在的观点看,基于kmeans聚类思想计算先验框的方法和人工设计并没有差别,仅仅是将确定先验框的尺寸的计算过程自动化了。模型依旧还是要依赖于这些超参数,从而在一定程度上削弱了自身的泛化性。因此,才有后来的anchor-free架构。
-
-
改进边界框预测方法。
-
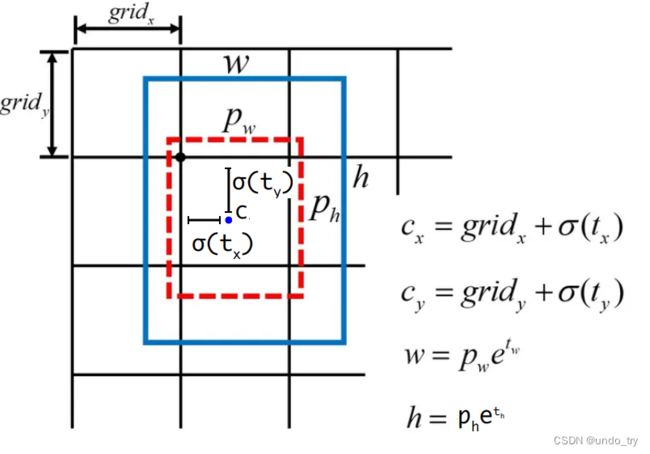
下图,展示了改进后边界框中心点及宽、高预测的公式。
-
对于边界框中心点预测,YOLO仍旧去学习中心点偏移量tx和 ty 。并使用sigmoid函数限定其数值范围处在0~1之间,这一点是修正了存在于YOLOv1中的预测值无上下界的问题。
-
对于边界框宽高预测,由于有了边界框的尺寸先验信息,YOLOv1只需要学习一些偏移量去调整先验框的尺寸即可。
-
先验框的宽和高也都是相对于
网格的尺度,因此计算出来的 cx,cy,w,h 也都是相对于网格尺度的值,最后我们还需要将其乘以32,才能将其映射到输入图像的尺度上。不过,我们后面自己实现的YOLOv2的先验框的宽高是基于原始图像大小,不需要乘以32。 -
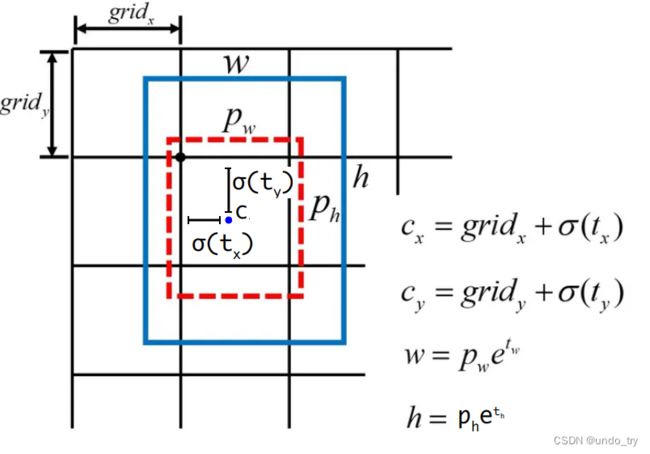
-
-
使用kmeans聚类方法获得先验框,再配合改进后的边界框预测方法,YOLOv1的性能得到了显著的提升:从69.6% mAP提升到74.4% mAP。
- 不难想到,性能提升的主要来源在于kmeans聚类,更好的先验信息自然会有效提升网络的检测性能。
- 只不过,这种先验信息是依赖于数据集的,这是一个潜在问题。
1.7 passthrough层的引入
-
YOLOv1仅在网络输出的最后一个feature map上去检查输入图像中的所有目标
- 最后一张feature map的低分辨率就意味着网格划分的很粗糙,不够精细,这不仅对于密集物体检测的效果会较差,小物体的检测效果也不够理想。
- 特征图的分辨率越高,所划分的网格也就越精细,能够更好地捕捉目标的细节信息。相较于YOLOv1只在一张7×7的过于粗糙的网格上做检测,2016年的SSD使用多种不同分辨率的特征图自然会更好。
-
YOLO作者借鉴了SSD的这一思想。
- 将Backbone的第17层卷积输出的26×26×512特征图拿出来,做一次
特殊的降采样操作,得到一个13×13×2048特征图 - 然后将二者在通道的维度上进行拼接,得到更厚的13×13×3072的特征图
- 最后在这张融合了更多信息的特征图上去做检测。
- 这里需要注意的是,实际上在作者代码中,在
特殊的降采样之前先做了降维由26×26×512降维至26×26×64,然后做特殊的降采样变为13×13×256,然后拼接得到13×13×1280的特征图。
- 将Backbone的第17层卷积输出的26×26×512特征图拿出来,做一次
-
了解passthrough层后,原版YOLOv2的整体架构也就知道了。
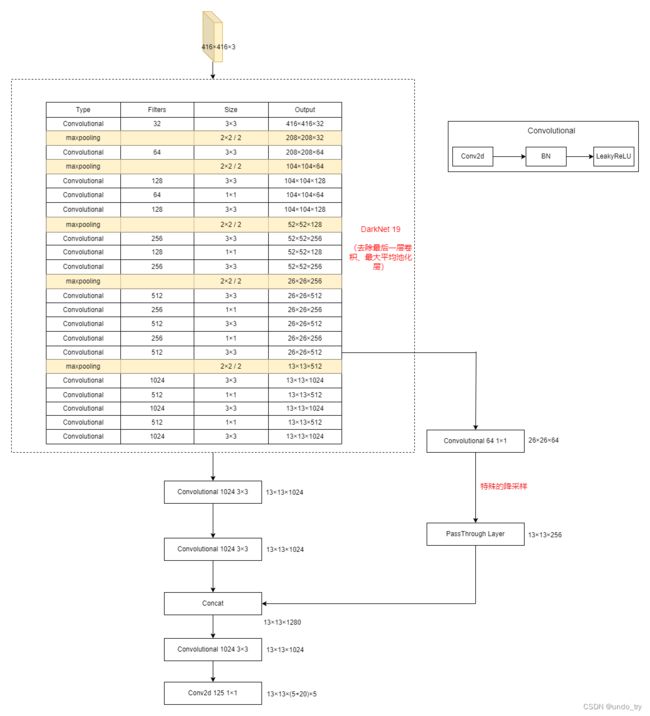
-
特殊的降采样操作(reorg)如下图所示:- 特征图在经过reorg操作的处理后,特征图的宽高会减半,而通道则扩充至4倍
- 这种特殊降采样操作的好处就在于降低分辨率的同时,没丢掉任何细节信息,信息总量保持不变。
- 加上该操作后,在VOC 2007测试集上的mAP从74.4%再次涨到了75.4%。
- 以今天的眼光看,最终的检测还是在13×13的网格中进行检测,并不是真正的类似SSD的
多级检测。 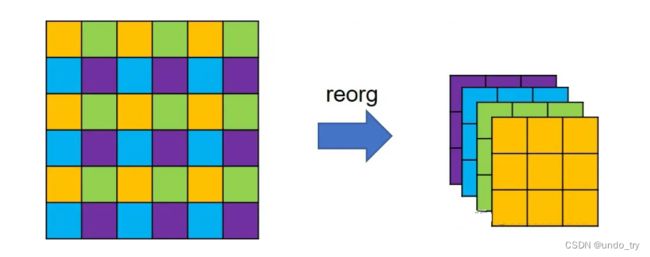
1.8 多尺度训练技巧
-
多尺度训练的好处就在于可以改变数据集中各类物体的大小占比,
- 比如说,一个物体在608的图像中占据较多的像素,面积较大,而在320图像中就会变少了,就所占的像素数量而言,相当于从一个较大的物体变成了较小物体。不断地对数据集里的图片做多尺度操作,可以有效地增加不同尺度的目标数量,进而丰富数据,因此,多尺度训练也算是一种“数据增强”操作。
- 多尺度训练就是在训练网络时,每训练迭代10次,就从{320,352,384,416,448,480,512,576,608}选择一个新的图像尺寸用作后续10次训练的图像尺寸。注意,这些尺寸都是32的整数倍,因为网络的最大降采样倍数就是32。
-
配合多尺寸训练,YOLOv1的性能再一次获得了提升:从上一次的75.4% mAP提升到了76.8% mAP。
2 复现YOLOV2
- 事实上,YOLOv2最大的变化就在于有效地引入了anchor box机制。
- 因此,后续复现YOLOv2的主要就是引入anchor box机制(不引入reorg操作)。
- 引入anchor box机制后,一个网格中有多个anchor box,那么正样本的选择就发生了很大的变化,其他诸如数据读取、数据预处理、数据增强等与之前实现的YOLOv1几乎一致。