基础数论之素数筛【C++算法竞赛】
由于下周要去做天梯赛的培训……浅浅回忆一下数论是个什么东西,当备课了
直接从备战快进到备课TAT
打开了已经打入冷宫多月的洛谷……让我想想讲课思路
本文主讲整除理论中的素数筛
整除理论
素数筛
素数的定义:质数又称素数。 一个大于1的自然数,除了1和它自身外,不能被其他自然数 整除 的数叫做质数;否则称为合数(规定1既不是质数也不是合数)。
所以,素数一定是整数,且是大于1的自然数
判断素数--试除法
针对输入的数字 n,我们可以遍历从2到 n-1这个区间中的数,如果 n 能被这个区间中任意一个数整除,那么它就不是质数。
int n;
cin>>n;
for(int i = 2; i < n; ++i)
{
int k;
for(k = 2; k < n; ++k)
if(i%k == 0)break;//如果找到一个因子k能将i除尽则跳出
if(k == i)//表明没有找到任何一个符合要求的因子k,所以为素数
cout<题目一:
判断一个数n是否为质数(除了一和它本身没有别的因数)是,输出'YES',不是,输出'NO'
范围:17<=n<=10000
在本系列的题目中,我不会拿范围过大 开longlong等情况作为迷惑/考点
这不是重点,重点是掌握判断素数的方法,以及如何过时间限制。
(所有题目及答案、代码,都会在下一篇博客《素数筛课后练习题及答案》中给出)//gcd单开一文博客
然后我先证明一下,这篇博客是真实存在的(已经发布的,在我的主页可找,不是画饼)

https://blog.csdn.net/qq_58249029/article/details/135428017?spm=1001.2014.3001.5502
核心代码:
for (int i = 2; i <= sqrt(n); ++i)
if (n % i == 0)优化①
事实上只需要遍历从 2 到  即可。
即可。
sqrt(n);//需要头文件#include
因为 因数都是成对出现的。比如,100的因数有:1和100,2和50,4和25,5和20,10和10。成对的因数,其中一个必然小于等于100的开平方,另一个大于等于100的开平方。
优化②
偶数中除了 2 都不是质数,且奇数的因数也没有偶数,因此可以进一步优化。
for循环里面i=i+2;
优化③
c++任何一个自然数,总可以表示成以下六种形式之一:6n,6n+1,6n+2,6n+3,6n+4,6n+5(n=0,1,2...)我们可以发现,除了2和3,只有形如6n+1和6n+5的数有可能是质数。且形如6n+1和6n+5的数如果不是质数,它们的因数也会含有形如6n+1或者6n+5的数。
多加了一层判断
埃氏筛
其实在优化②中,筛法九就已经有了浅浅的体现。在那次优化中,已经是把2到n中所有的数列出来,从2开始,现划掉n以内2所有的倍数【i=i+2】,那我们进行一下类推,从下一个素数开始依次划掉该数的倍数。最后剩下的都是素数。
接下来,系统的介绍一个埃氏筛的概念。
首先将2到n范围内的整数写下来,其中2是最小的素数,那么在下表中,将2的倍数划去;在此之后表中所剩下的最小的数字就是3,他不能够被更小的数整除,所以3是素数;重复上述步骤。将3的倍数划去,以此类推,就能枚举出n以内的素数。
其时间复杂度是O(n*log(logn))
如下图所示,从2开始 2是素数 那么4不是 6不是 8也不是 10、12、14、16、18、20 ……
然后3开始 6 9 12 15 18 ……都不是……
之后4,已经在上上行被划去了,所以跳过。
之后从5开始……
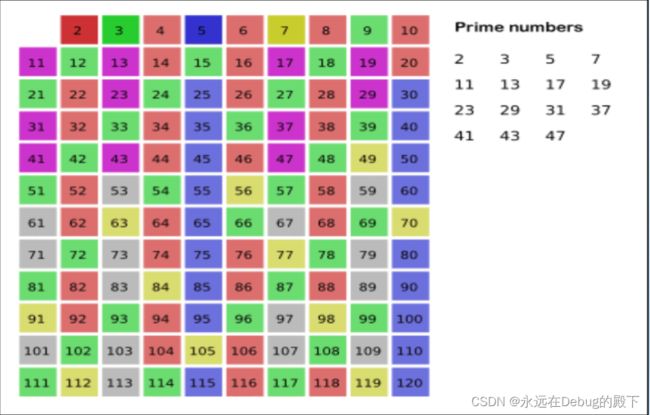
先放个截图吧……还没学会怎么上传视频,倍数被用相同的颜色标注出来了。接下来讲解一下代码
题目二:
求1~10000之间的素数,并输出总个数与所有素数。
(所有题目及答案、代码,都会在下一篇博客《素数筛课后练习题及答案》中给出)
题目三:
求 X,Y间的素数个数(包括 X 和 Y)。
输入:X Y
输出:[X,Y]之间的素数个数
这道题和上面的题目二是相同的,就是换一种方法写,用埃氏筛。
(所有题目及答案、代码,都会在下一篇博客《素数筛课后练习题及答案》中给出)
埃氏筛模板
筛法就是有一个很明显的特点,以空间换时间,而且很短,所有数字只计算一次换句话说就是,几行就行 一次就好,在面对循环输入的时候,对于节省时间/不被卡时间,是有很大优势的。
注意!该模板范围不要超过int,主要是看数组能开多大,超过int用long long,函数的返回值也记得换成long long
#include
#include
#include
using namespace std;
int isprime[10001];
void sieve()
{
for (int i = 0; i <= 10000; i++)
isprime[i] = 1;
isprime[0] = isprime[1] = 0;
for (int i = 2; i <= 10000; i++) //从2开始往后筛
if (isprime[i])
for (int j = 2 * i; j <= 10000; j += i)
isprime[j] = 0;
}
int main()
{
sieve();//先 进行埃氏筛
//此时已经判断出来哪些是素数了
int n;//在输入需要判断的数,再进行判断
while (cin>>n)//循环输入
{
if (isprime[n])
cout << "YSE" << endl;
else
cout << "NO" << endl;
}
return 0;
}
当然,这也存在重复筛出的现限,比如6,同时被因数为2的时候筛了一遍,又在因数为3的时候筛了一遍,换句话说,假设现在 i=b,如果从2倍开始倍增,将会标记b*2这个数,而这个数实际上在2倍增b倍的时候,就已经标记了。所以每次倍增应该从 i 开始,从 i^2开始标记。
就类似九九乘法表是阶梯性的而不是矩形的。
为了避免这种现象,由此出现了欧拉筛。
欧拉筛
在埃式筛法中,有些数存在被重复筛去的情况,而欧拉筛法只筛除一次,时间复杂度近似为O(n).
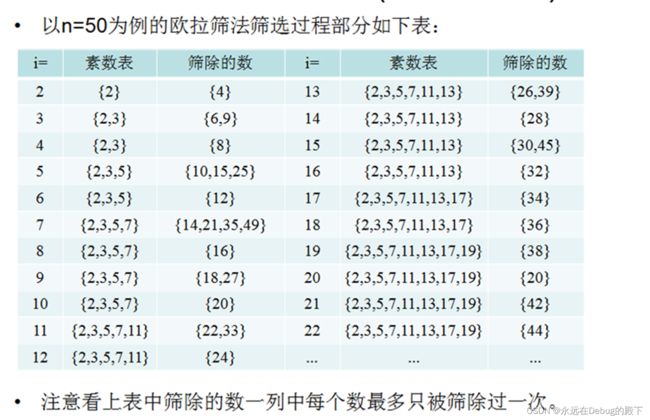
我们先来讲解一下欧拉筛的原理,就是为了不重复筛出,能极大地减少时间复杂度,所有合数都是被他的最小素因子筛去的。
#include
using namespace std;
int prime[10001];
bool visit[10001] = { false };
int cnt = 0;
void euler()
{
memset(visit, true, sizeof(visit)); // 先全部标记为素数
visit[1] = false; // 1不是素数
for (int i = 2; i <= 10000; ++i) // i从2循环到n(上限10000)
{
if (visit[i]) prime[++cnt] = i;
// 如果i没有被前面的数筛掉,则i是素数
for (int j = 1; j <= cnt && i * prime[j] <= 10000; ++j)//防止越界问题
{ // 筛掉i的素数倍,即i的prime[j]倍
visit[i * prime[j]] = false;
// 倍数标记为合数,也就是i用prime[j]把i * prime[j]筛掉了
if (i % prime[j] == 0) break;
// 最神奇的一句话,如果i整除prime[j],退出循环
// 这样可以保证线性的时间复杂度
}
}
}
int main()
{
euler();
int n;
while (cin >> n)
{
if (visit[n])
cout << "是素数" << endl;
else
cout << "不是素数" << endl;
}
return 0;
} 我们不需要用一个for循环去筛除一个质数的所有倍数,我们将所有质数存储到primes[]中,然后枚举到第i个数时,就筛去所有的primes[j] * i。这样就在每一次遍历中,正好筛除了所有已知素数的i倍。
在代码思路上和埃氏筛具有一定的相似性,首先我们需要定义两个数组/列表/或者是其他的什么类似的。
其中 prime[]用来存放素数,一开始是空的。visit用来标注整数的状态,一开始仅仅对0和1标注为0【意味不是素数】
这里面又有两个【类似指针】一直在循环的数,i和prime[j],每次将i*prime[j]=0;意为相乘得到的数都是合数。
同时,当i遇到一个合数,遭遇到他的最小素因子,并标注另外一个合数后,例如i=4时,prime[i]=2;使得i*prime[j]指向8,就结束本次遍历【break】,
这就是非常重要的一点,下面这两行判断代码可以说是欧拉筛的核心
if(i%prime[j]==0)
break;这条语句的加入,保证了每个合数只会被筛除一次,不会被重复筛除。
之后再进入进入下一次【不然会出现重复标注的情况】
防止越界问题:
当i*prime[j]的值越界,那就进入下一个i
for (int j = 1; j <= prime[0] && i * prime[j] <= 10000; j++)因为:欧拉筛的核心思想就是确保每个合数只被最小质因数筛掉。或者说是被合数的最大因子筛掉。
推荐一个视频,讲解的十分清楚,最重要的是他的图是动态演示的。
欧拉筛,几行就行,一次就好
课后练习题:
(主要是给我们学校的小朋友讲,后续还需要给他们写题解1.10讲,估计1.10之前题解也会写完发出来)
素数密度 - 洛谷
【模板】线性筛素数 - 洛谷
数字游戏 - 洛谷