大话 JavaScript(Speaking JavaScript):第十六章到第二十章
第十六章:变量:作用域、环境和闭包
原文:16. Variables: Scopes, Environments, and Closures
译者:飞龙
协议:CC BY-NC-SA 4.0
本章首先解释了如何使用变量,然后详细介绍了它们的工作方式(环境、闭包等)。
声明变量
在 JavaScript 中,您在使用变量之前通过var语句声明变量:
var foo;
foo = 3; // OK, has been declared
bar = 5; // not OK, an undeclared variable
您还可以将声明与赋值结合在一起,立即初始化变量:
var foo = 3;
未初始化变量的值为undefined:
> var x;
> x
undefined
背景:静态与动态
您可以从两个角度来检查程序的工作方式:
静态(或词法)
您在不运行程序的情况下检查程序的存在。给定以下代码,我们可以得出静态断言,即函数“g”嵌套在函数“f”内部:
function f() {
function g() {
}
}
形容词词法与静态是同义词,因为两者都与程序的词汇(单词,源代码)有关。
动态
您在执行程序时检查发生的情况(“在运行时”)。给定以下代码:
function g() {
}
function f() {
g();
}
当我们调用f()时,它调用g()。在运行时,g被f调用表示动态关系。
背景:变量的范围
在本章的其余部分,您应该了解以下概念:
变量的范围
变量的范围是它可访问的位置。例如:
function foo() {
var x;
}
在这里,“x”的直接作用域是函数“foo()”。
词法作用域
JavaScript 中的变量是词法作用域的,因此程序的静态结构决定了变量的作用域(不受例如函数从何处调用的影响)。
嵌套范围
如果作用域嵌套在变量的直接作用域内,则该变量在所有这些作用域中都是可访问的:
function foo(arg) {
function bar() {
console.log('arg: '+arg);
}
bar();
}
console.log(foo('hello')); // arg: hello
“arg”的直接范围是“foo()”,但它也可以在嵌套范围“bar()”中访问。就嵌套而言,“foo()”是外部范围,“bar()”是内部范围。
遮蔽
如果作用域声明了与外部作用域中的变量同名的变量,则内部作用域中将阻止对外部变量的访问,并且所有嵌套在其中的作用域。对内部变量的更改不会影响外部变量,在离开内部作用域后,外部变量再次可访问:
var x = "global";
function f() {
var x = "local";
console.log(x); // local
}
f();
console.log(x); // global
在函数“f()”内部,全局“x”被本地“x”遮蔽。
变量是函数作用域的
大多数主流语言都是块作用域的:变量“存在于”最内部的周围代码块中。以下是 Java 的一个例子:
public static void main(String[] args) {
{ // block starts
int foo = 4;
} // block ends
System.out.println(foo); // Error: cannot find symbol
}
在前面的代码中,变量foo只能在直接包围它的块内部访问。如果我们在块结束后尝试访问它,将会得到编译错误。
相比之下,JavaScript 的变量是函数作用域的:只有函数引入新的作用域;在作用域方面忽略了块。例如:
function main() {
{ // block starts
var foo = 4;
} // block ends
console.log(foo); // 4
}
换句话说,“foo”在“main()”中是可访问的,而不仅仅是在块内部。
变量声明被提升
JavaScript 提升所有变量声明,将它们移动到其直接作用域的开头。这样可以清楚地说明如果在声明之前访问变量会发生什么:
function f() {
console.log(bar); // undefined
var bar = 'abc';
console.log(bar); // abc
}
我们可以看到变量“bar”已经存在于“f()”的第一行,但它还没有值;也就是说,声明已经被提升,但赋值没有。JavaScript 执行f()时,就好像它的代码是:
function f() {
var bar;
console.log(bar); // undefined
bar = 'abc';
console.log(bar); // abc
}
如果声明已经声明了一个变量,那么什么也不会发生(变量的值不变):
> var x = 123;
> var x;
> x
123
每个函数声明也会被提升,但方式略有不同。完整的函数会被提升,而不仅仅是存储它的变量的创建(参见提升)。
最佳实践:了解提升,但不要害怕它
一些 JavaScript 风格指南建议您只在函数开头放置变量声明,以避免被提升所欺骗。如果您的函数相对较小(无论如何都应该是这样),那么您可以放松这个规则,将变量声明在使用它们的地方附近(例如,在for循环内部)。这样更好地封装了代码片段。显然,您应该意识到这种封装只是概念上的,因为函数范围的提升仍然会发生。
陷阱:给未声明的变量赋值会使其成为全局变量
在松散模式下,对未经var声明的变量进行赋值会创建一个全局变量:
> function sloppyFunc() { x = 123 }
> sloppyFunc()
> x
123
值得庆幸的是,严格模式在发生这种情况时会抛出异常:
> function strictFunc() { 'use strict'; x = 123 }
> strictFunc()
ReferenceError: x is not defined
通过 IIFE 引入新的作用域
通常,您会引入新的作用域来限制变量的生命周期。一个例子是您可能希望在if语句的“then”部分中这样做:只有在条件成立时才执行;如果它专门使用辅助变量,我们不希望它们“泄漏”到周围的作用域中:
function f() {
if (condition) {
var tmp = ...;
...
}
// tmp still exists here
// => not what we want
}
如果要为then块引入新的作用域,可以定义一个函数并立即调用它。这是一种解决方法,模拟块作用域:
function f() {
if (condition) {
(function () { // open block
var tmp = ...;
...
}()); // close block
}
}
这是 JavaScript 中的一种常见模式。Ben Alman 建议将其称为立即调用函数表达式(IIFE,发音为“iffy”)。一般来说,IIFE 看起来像这样:
(function () { // open IIFE
// inside IIFE
}()); // close IIFE
以下是关于 IIFE 的一些注意事项:
它立即被调用
在函数的闭括号后面的括号立即调用它。这意味着它的主体立即执行。
它必须是一个表达式
如果语句以关键字function开头,解析器会期望它是一个函数声明(参见Expressions Versus Statements)。但是函数声明不能立即调用。因此,我们通过以开括号开始语句来告诉解析器关键字function是函数表达式的开始。在括号内,只能有表达式。
需要分号
如果您在两个 IIFE 之间忘记了它,那么您的代码将不再起作用:
(function () {
...
}()) // no semicolon
(function () {
...
}());
前面的代码被解释为函数调用——第一个 IIFE(包括括号)是要调用的函数,第二个 IIFE 是参数。
注意
IIFE 会产生成本(在认知和性能方面),因此在if语句内部使用它很少有意义。上面的例子是为了教学目的而选择的。
IIFE 变体:前缀运算符
您还可以通过前缀运算符强制执行表达式上下文。例如,您可以通过逻辑非运算符这样做:
!function () { // open IIFE
// inside IIFE
}(); // close IIFE
或通过void运算符(参见The void Operator):
void function () { // open IIFE
// inside IIFE
}(); // close IIFE
使用前缀运算符的优点是忘记结束分号不会引起麻烦。
IIFE 变体:已经在表达式上下文中
请注意,如果您已经处于表达式上下文中,则不需要强制执行 IIFE 的表达式上下文。然后您不需要括号或前缀运算符。例如:
var File = function () { // open IIFE
var UNTITLED = 'Untitled';
function File(name) {
this.name = name || UNTITLED;
}
return File;
}(); // close IIFE
在上面的例子中,有两个不同的变量名为File。一方面,有一个函数,只能直接在 IIFE 内部访问。另一方面,在第一行声明的变量。它被赋予在 IIFE 中返回的值。
IIFE 变体:带参数的 IIFE
您可以使用参数来定义 IIFE 内部的变量:
var x = 23;
(function (twice) {
console.log(twice);
}(x * 2));
这类似于:
var x = 23;
(function () {
var twice = x * 2;
console.log(twice);
}());
IIFE 应用
IIFE 使您能够将私有数据附加到函数上。然后,您就不必声明全局变量,并且可以将函数与其状态紧密打包。您避免了污染全局命名空间:
var setValue = function () {
var prevValue;
return function (value) { // define setValue
if (value !== prevValue) {
console.log('Changed: ' + value);
prevValue = value;
}
};
}();
IIFE 的其他应用在本书的其他地方提到:
-
避免全局变量;隐藏全局范围内的变量(参见Best Practice: Avoid Creating Global Variables)
-
创建新的环境;避免共享(参见Pitfall: Inadvertently Sharing an Environment)
-
将全局数据私有化到所有构造函数中(参见Keeping global data private to all of a constructor)
-
将全局数据附加到单例对象上(参见[将私有全局数据附加到单例对象](ch17_split_001.html#private_data_singleton “将私有全局数据附加到单例对象”)
-
将全局数据附加到方法(参见[将全局数据附加到方法](ch17_split_001.html#private_data_method “将全局数据附加到方法”)
全局变量
包含程序的所有范围称为全局范围或程序范围。这是当进入脚本时所在的范围(无论是网页中的">
</iframe>
</body>
显然,这也是非内置构造函数的问题。
除了使用Array.isArray(),还有几件事情可以解决这个问题:
-
避免对象跨越领域。浏览器有
postMessage()方法,可以将一个对象复制到另一个领域,而不是传递一个引用。 -
检查实例的构造函数的名称(仅适用于支持函数
name属性的引擎):someValue.constructor.name === 'NameOfExpectedConstructor' -
使用原型属性标记实例属于类型
T。有几种方法可以这样做。检查value是否是T的实例如下: -
value.isT():T实例的原型必须从这个方法返回true;一个常见的超级构造函数应该返回默认值false。 -
'T' in value: 你必须用一个属性标记T实例的原型,其键是'T'(或者更独特的东西)。 -
value.TYPE_NAME === 'T': 每个相关的原型必须有一个TYPE_NAME属性,具有适当的值。
实现构造函数的提示
本节提供了一些实现构造函数的提示。
防止忘记新的:严格模式
如果你在使用构造函数时忘记了new,你是将它作为函数而不是构造函数来调用。在松散模式下,你不会得到一个实例,全局变量会被创建。不幸的是,所有这些都是没有警告发生的:
function SloppyColor(name) {
this.name = name;
}
var c = SloppyColor('green'); // no warning!
// No instance is created:
console.log(c); // undefined
// A global variable is created:
console.log(name); // green
在严格模式下,你会得到一个异常:
function StrictColor(name) {
'use strict';
this.name = name;
}
var c = StrictColor('green');
// TypeError: Cannot set property 'name' of undefined
从构造函数返回任意对象
在许多面向对象的语言中,构造函数只能生成直接实例。例如,考虑 Java:假设您想要实现一个类Expression,它有子类Addition和Multiplication。解析会生成后两个类的直接实例。您不能将其实现为Expression的构造函数,因为该构造函数只能生成Expression的直接实例。作为解决方法,在 Java 中使用静态工厂方法:
class Expression {
// Static factory method:
public static Expression parse(String str) {
if (...) {
return new Addition(...);
} else if (...) {
return new Multiplication(...);
} else {
throw new ExpressionException(...);
}
}
}
...
Expression expr = Expression.parse(someStr);
在 JavaScript 中,您可以从构造函数中简单地返回您需要的任何对象。因此,前面代码的 JavaScript 版本看起来像:
function Expression(str) {
if (...) {
return new Addition(..);
} else if (...) {
return new Multiplication(...);
} else {
throw new ExpressionException(...);
}
}
...
var expr = new Expression(someStr);
这是个好消息:JavaScript 构造函数不会将你锁定,因此您可以随时改变构造函数是否应返回直接实例或其他内容的想法。
原型属性中的数据
本节解释了在大多数情况下,您不应该将数据放在原型属性中。然而,这个规则也有一些例外。
避免具有实例属性初始值的原型属性
原型包含多个对象共享的属性。因此,它们非常适用于方法。此外,通过下面描述的一种技术,您还可以使用它们来为实例属性提供初始值。稍后我会解释为什么不建议这样做。
构造函数通常将实例属性设置为初始值。如果其中一个值是默认值,那么您不需要创建实例属性。您只需要一个具有相同键的原型属性,其值是默认值。例如:
/**
* Anti-pattern: don’t do this
*
* @param data an array with names
*/
function Names(data) {
if (data) {
// There is a parameter
// => create instance property
this.data = data;
}
}
Names.prototype.data = [];
参数data是可选的。如果缺少它,实例将不会获得属性data,而是继承Names.prototype.data。
这种方法基本上有效:您可以创建Names的实例n。获取n.data会读取Names.prototype.data。设置n.data会在n中创建一个新的自有属性,并保留原型中的共享默认值。我们只有一个问题,如果我们更改默认值(而不是用新值替换它):
> var n1 = new Names();
> var n2 = new Names();
> n1.data.push('jane'); // changes default value
> n1.data
[ 'jane' ]
> n2.data
[ 'jane' ]
在前面的示例中,push()改变了Names.prototype.data中的数组。由于该数组被所有没有自有属性data的实例共享,因此n2.data的初始值也发生了变化。
最佳实践:不要共享默认值
鉴于我们刚刚讨论的内容,最好不要共享默认值,并且始终创建新的默认值:
function Names(data) {
this.data = data || [];
}
显然,如果该值是不可变的(就像所有原始值一样;请参阅Primitive Values),那么修改共享默认值的问题就不会出现。但为了保持一致性,最好坚持一种设置属性的方式。我也更喜欢保持通常的关注点分离(参见Layer 3: Constructors—Factories for Instances):构造函数设置实例属性,原型包含方法。
ECMAScript 6 将使这更加成为最佳实践,因为构造函数参数可以具有默认值,并且您可以通过类定义原型方法,但不能定义具有数据的原型属性。
按需创建实例属性
偶尔,创建属性值是一个昂贵的操作(在计算或存储方面)。在这种情况下,您可以按需创建实例属性:
function Names(data) {
if (data) this.data = data;
}
Names.prototype = {
constructor: Names, // (1)
get data() {
// Define, don’t assign
// => avoid calling the (nonexistent) setter
Object.defineProperty(this, 'data', {
value: [],
enumerable: true,
configurable: false,
writable: false
});
return this.data;
}
};
我们无法通过赋值向实例添加属性data,因为 JavaScript 会抱怨缺少 setter(当它只找到 getter 时会这样做)。因此,我们通过Object.defineProperty()来添加它。请参阅Properties: Definition Versus Assignment来查看定义和赋值之间的区别。在第(1)行,我们确保属性constructor被正确设置(参见The constructor Property of Instances)。
显然,这是相当多的工作,所以你必须确保它是值得的。
避免非多态原型属性
如果相同的属性(相同的键,相同的语义,通常不同的值)存在于几个原型中,则称为多态。然后,通过实例读取属性的结果是通过该实例的原型动态确定的。未多态使用的原型属性可以被变量替换(这更好地反映了它们的非多态性质)。
例如,你可以将常量存储在原型属性中,并通过this访问它:
function Foo() {}
Foo.prototype.FACTOR = 42;
Foo.prototype.compute = function (x) {
return x * this.FACTOR;
};
这个常量不是多态的。因此,你可以通过变量访问它:
// This code should be inside an IIFE or a module
function Foo() {}
var FACTOR = 42;
Foo.prototype.compute = function (x) {
return x * FACTOR;
};
多态原型属性
这是一个具有不可变数据的多态原型属性的示例。通过原型属性标记构造函数的实例,可以将它们与不同构造函数的实例区分开来:
function ConstrA() { }
ConstrA.prototype.TYPE_NAME = 'ConstrA';
function ConstrB() { }
ConstrB.prototype.TYPE_NAME = 'ConstrB';
由于多态的“标签”TYPE_NAME,即使它们跨越领域(然后instanceof不起作用;参见陷阱:跨领域(帧或窗口)),你也可以区分ConstrA和ConstrB的实例。
保持数据私有
JavaScript 没有专门的手段来管理对象的私有数据。本节将描述三种解决这个限制的技术:
-
构造函数环境中的私有数据
-
使用标记键在属性中存储私有数据
-
使用具体键在属性中存储私有数据
此外,我将解释如何通过 IIFE 保持全局数据私有。
构造函数环境中的私有数据(Crockford 隐私模式)
当调用构造函数时,会创建两个东西:构造函数的实例和一个环境(参见环境:管理变量)。实例由构造函数初始化。环境保存构造函数的参数和局部变量。在构造函数内部创建的每个函数(包括方法)都将保留对环境的引用——它被创建的环境。由于这个引用,即使构造函数完成后,它仍然可以访问环境。这种函数和环境的组合被称为闭包(闭包:函数保持与它们的诞生作用域连接)。构造函数的环境因此是独立于实例的数据存储,与实例只有因为它们同时创建而相关。为了正确连接它们,我们必须有生活在两个世界中的函数。使用Douglas Crockford 的术语,一个实例可以有三种与之关联的值(参见图 17-4):
公共属性
存储在属性中的值(无论是在实例中还是在其原型中)都是公开可访问的。
私有值
存储在环境中的数据和函数是私有的——只能由构造函数和它创建的函数访问。
特权方法
私有函数可以访问公共属性,但原型中的公共方法无法访问私有数据。因此,我们需要特权方法——实例中的公共方法。特权方法是公共的,可以被所有人调用,但它们也可以访问私有值,因为它们是在构造函数中创建的。
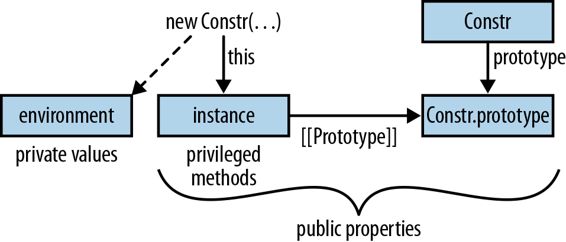 图 17-4:当构造函数 Constr 被调用时,会创建两个数据结构:参数和局部变量的环境以及要初始化的实例。
图 17-4:当构造函数 Constr 被调用时,会创建两个数据结构:参数和局部变量的环境以及要初始化的实例。
以下各节详细解释了每种值。
公共属性
请记住,对于构造函数Constr,有两种公共属性可供所有人访问。首先,原型属性存储在Constr.prototype中,并由所有实例共享。原型属性通常是方法:
Constr.prototype.publicMethod = ...;
其次,实例属性对每个实例都是唯一的。它们在构造函数中添加,通常保存数据(而不是方法):
function Constr(...) {
this.publicData = ...;
...
}
私有值
构造函数的环境包括参数和局部变量。它们只能从构造函数内部访问,因此对实例是私有的:
function Constr(...) {
...
var that = this; // make accessible to private functions
var privateData = ...;
function privateFunction(...) {
// Access everything
privateData = ...;
that.publicData = ...;
that.publicMethod(...);
}
...
}
特权方法
私有数据是如此安全,以至于原型方法无法访问它。但是离开构造函数后你还能怎么使用它呢?答案是特权方法:在构造函数中创建的函数被添加为实例方法。这意味着,一方面,它们可以访问私有数据;另一方面,它们是公共的,因此被原型方法看到。换句话说,它们在私有数据和公共数据(包括原型方法)之间充当中介:
function Constr(...) {
...
this.privilegedMethod = function (...) {
// Access everything
privateData = ...;
privateFunction(...);
this.publicData = ...;
this.publicMethod(...);
};
}
一个例子
以下是使用 Crockford 隐私模式实现的StringBuilder:
function StringBuilder() {
var buffer = [];
this.add = function (str) {
buffer.push(str);
};
this.toString = function () {
return buffer.join('');
};
}
// Can’t put methods in the prototype!
以下是交互:
> var sb = new StringBuilder();
> sb.add('Hello');
> sb.add(' world!');
> sb.toString()
’Hello world!’
Crockford 隐私模式的利弊
在使用 Crockford 隐私模式时需要考虑的一些要点:
它不是很优雅
通过特权方法介入私有数据的访问引入了不必要的间接性。特权方法和私有函数都破坏了构造函数(设置实例数据)和实例原型(方法)之间的关注点分离。
它是完全安全的
无法从外部访问环境的数据,这使得这种解决方案在需要时非常安全(例如,对于安全关键代码)。另一方面,私有数据不可被外部访问也可能会带来不便。有时你想对私有功能进行单元测试。而一些临时的快速修复依赖于访问私有数据的能力。这种快速修复是无法预测的,所以无论你的设计有多好,都可能会出现这种需求。
它可能会更慢
在当前 JavaScript 引擎中,访问原型链中的属性是高度优化的。访问闭包中的值可能会更慢。但这些事情不断变化,所以你必须测量一下,看看这对你的代码是否真的很重要。
它会消耗更多的内存
保留环境并将特权方法放在实例中会消耗内存。再次,确保这对你的代码真的很重要,并进行测量。
带有标记键的属性中的私有数据
对于大多数非安全关键的应用程序来说,隐私更像是 API 的一个提示:“你不需要看到这个。”这就是封装的关键好处——隐藏复杂性。尽管底层可能有更多的东西,但你只需要理解 API 的公共部分。命名约定的想法是通过标记属性的键来让客户端了解隐私。通常会使用前缀下划线来实现这一目的。
让我们重写先前的StringBuilder示例,以便缓冲区保存在名为_buffer的私有属性中,但按照惯例而言:
function StringBuilder() {
this._buffer = [];
}
StringBuilder.prototype = {
constructor: StringBuilder,
add: function (str) {
this._buffer.push(str);
},
toString: function () {
return this._buffer.join('');
}
};
以下是通过标记属性键实现隐私的一些利弊:
它提供了更自然的编码风格
能够以相同的方式访问私有和公共数据比使用环境实现隐私更加优雅。
它污染了属性的命名空间
具有标记键的属性可以在任何地方看到。人们使用 IDE 的越多,它们就会越烦人,因为它们会显示在公共属性旁边,而应该隐藏在那里。理论上,IDE 可以通过识别命名约定并在可能的情况下隐藏私有属性来进行适应。
可以从“外部”访问私有属性
这对单元测试和快速修复很有用。此外,子构造函数和辅助函数(所谓的“友元函数”)可以更轻松地访问私有数据。环境方法不提供这种灵活性;私有数据只能从构造函数内部访问。
它可能导致关键冲突
私有属性的键可能会发生冲突。这已经是子构造函数的一个问题,但如果您使用多重继承(某些库允许的),这将更加棘手。通过环境方法,就不会发生任何冲突。
使用具体化键在属性中保持私有数据
私有属性的一个问题是,键可能会发生冲突(例如,来自构造函数的键与来自子构造函数的键,或来自混入的键与来自构造函数的键)。通过使用更长的键,例如包含构造函数名称的键,可以减少这种冲突的可能性。然后,在前面的情况下,私有属性_buffer将被称为_StringBuilder_buffer。如果这样的键对您来说太长,您可以选择具体化它,将其存储在变量中:
var KEY_BUFFER = '_StringBuilder_buffer';
现在我们通过this[KEY_BUFFER]访问私有数据。
var StringBuilder = function () {
var KEY_BUFFER = '_StringBuilder_buffer';
function StringBuilder() {
this[KEY_BUFFER] = [];
}
StringBuilder.prototype = {
constructor: StringBuilder,
add: function (str) {
this[KEY_BUFFER].push(str);
},
toString: function () {
return this[KEY_BUFFER].join('');
}
};
return StringBuilder;
}();
我们已经将 IIFE 包装在StringBuilder周围,以便常量KEY_BUFFER保持本地化,不会污染全局命名空间。
具体化的属性键使您能够在键中使用 UUID(通用唯一标识符)。例如,通过 Robert Kieffer 的node-uuid:
var KEY_BUFFER = '_StringBuilder_buffer_' + uuid.v4();
每次代码运行时,KEY_BUFFER的值都不同。例如,可能如下所示:
_StringBuilder_buffer_110ec58a-a0f2-4ac4-8393-c866d813b8d1
具有 UUID 的长键使关键冲突几乎不可能发生。
通过 IIFE 将全局数据保持私有
本小节解释了如何通过 IIFE(请参阅通过 IIFE 引入新作用域)将全局数据保持私有,以供单例对象、构造函数和方法使用。这些 IIFE 创建新环境(请参阅环境:管理变量),您可以在其中放置私有数据。
将私有全局数据附加到单例对象
您不需要构造函数来将对象与环境中的私有数据关联起来。以下示例显示了如何使用 IIFE 来实现相同的目的,方法是将其包装在单例对象周围:
var obj = function () { // open IIFE
// public
var self = {
publicMethod: function (...) {
privateData = ...;
privateFunction(...);
},
publicData: ...
};
// private
var privateData = ...;
function privateFunction(...) {
privateData = ...;
self.publicData = ...;
self.publicMethod(...);
}
return self;
}(); // close IIFE
将全局数据保持私有以供所有构造函数使用
某些全局数据仅适用于构造函数和原型方法。通过同时将 IIFE 包装在两者周围,可以将其隐藏起来,不让公众看到。使用具体化键在属性中保持私有数据举例说明:构造函数StringBuilder及其原型方法使用常量KEY_BUFFER,其中包含属性键。该常量存储在 IIFE 的环境中:
var StringBuilder = function () { // open IIFE
var KEY_BUFFER = '_StringBuilder_buffer_' + uuid.v4();
function StringBuilder() {
this[KEY_BUFFER] = [];
}
StringBuilder.prototype = {
// Omitted: methods accessing this[KEY_BUFFER]
};
return StringBuilder;
}(); // close IIFE
请注意,如果您使用模块系统(请参阅第三十一章),您可以通过将构造函数加上方法放入模块中,以更干净的代码实现相同的效果。
将全局数据附加到方法
有时您只需要单个方法的全局数据。通过将其放在您包装在方法周围的 IIFE 的环境中,可以使其保持私有。例如:
var obj = {
method: function () { // open IIFE
// method-private data
var invocCount = 0;
return function () {
invocCount++;
console.log('Invocation #'+invocCount);
return 'result';
};
}() // close IIFE
};
以下是交互:
> obj.method()
Invocation #1
'result'
> obj.method()
Invocation #2
'result'
第 4 层:构造函数之间的继承
在本节中,我们将研究如何从构造函数中继承:给定一个构造函数Super,我们如何编写一个新的构造函数Sub,它具有Super的所有特性以及一些自己的特性?不幸的是,JavaScript 没有内置的机制来执行这个任务。因此,我们需要做一些手动工作。
图 17-5 说明了这个想法:子构造函数Sub应该具有Super的所有属性(原型属性和实例属性),另外还有自己的。因此,我们对Sub应该是什么样子有了一个大致的想法,但不知道如何实现。我们需要弄清楚几件事情,接下来我会解释:
-
继承实例属性。
-
继承原型属性。
-
确保
instanceof的工作:如果sub是Sub的一个实例,我们也希望sub instanceof Super为真。 -
覆盖方法以适应
Sub中的Super方法之一。 -
进行超级调用:如果我们覆盖了
Super的一个方法,我们可能需要从Sub中调用原始方法。
 图 17-5:Sub 应该从 Super 继承:它应该具有 Super 的所有原型属性和所有 Super 的实例属性,另外还有自己的。请注意,methodB 覆盖了 Super 的 methodB。
图 17-5:Sub 应该从 Super 继承:它应该具有 Super 的所有原型属性和所有 Super 的实例属性,另外还有自己的。请注意,methodB 覆盖了 Super 的 methodB。
继承实例属性
实例属性是在构造函数本身中设置的,因此继承超级构造函数的实例属性涉及调用该构造函数:
function Sub(prop1, prop2, prop3, prop4) {
Super.call(this, prop1, prop2); // (1)
this.prop3 = prop3; // (2)
this.prop4 = prop4; // (3)
}
当通过new调用Sub时,它的隐式参数this指向一个新实例。它首先将该实例传递给Super(1),后者添加其实例属性。之后,Sub设置自己的实例属性(2,3)。关键是不要通过new调用Super,因为那样会创建一个新的超级实例。相反,我们将Super作为一个函数调用,并将当前(子)实例作为this的值传递进去。
继承原型属性
诸如方法之类的共享属性保存在实例原型中。因此,我们需要找到一种方法,让Sub.prototype继承Super.prototype的所有属性。解决方案是将Sub.prototype设置为Super.prototype的原型。
对两种原型感到困惑吗?
是的,JavaScript 术语在这里很令人困惑。如果你感到迷茫,请参阅术语:两个原型,其中解释了它们的区别。
这是实现这一点的代码:
Sub.prototype = Object.create(Super.prototype);
Sub.prototype.constructor = Sub;
Sub.prototype.methodB = ...;
Sub.prototype.methodC = ...;
Object.create()生成一个原型为Super.prototype的新对象。之后,我们添加Sub的方法。正如在实例的构造函数属性中解释的那样,我们还需要设置constructor属性,因为我们已经替换了原始实例原型,其中它具有正确的值。
图 17-6 显示了现在Sub和Super的关系。Sub的结构确实类似于我在图 17-5 中所勾画的。该图未显示实例属性,这些属性是由图中提到的函数调用设置的。
 图 17-6:构造函数 Sub 通过调用构造函数 Super 并使 Sub.prototype 成为 Super.prototype 的原型而继承了构造函数 Super。
图 17-6:构造函数 Sub 通过调用构造函数 Super 并使 Sub.prototype 成为 Super.prototype 的原型而继承了构造函数 Super。
确保instanceof的工作
“确保instanceof的工作”意味着Sub的每个实例也必须是Super的实例。图 17-7 显示了Sub的实例subInstance的原型链的样子:它的第一个原型是Sub.prototype,第二个原型是Super.prototype。
 图 17-7:subInstance 是由构造函数 Sub 创建的。它具有两个原型 Sub.prototype 和 Super.prototype。
图 17-7:subInstance 是由构造函数 Sub 创建的。它具有两个原型 Sub.prototype 和 Super.prototype。
让我们从一个更简单的问题开始:subInstance是Sub的一个实例吗?是的,因为以下两个断言是等价的(后者可以被视为前者的定义):
subInstance instanceof Sub
Sub.prototype.isPrototypeOf(subInstance)
如前所述,Sub.prototype是subInstance的原型之一,因此两个断言都为真。同样,subInstance也是Super的一个实例,因为以下两个断言成立:
subInstance instanceof Super
Super.prototype.isPrototypeOf(subInstance)
重写一个方法
我们通过在Sub.prototype中添加与相同名称的方法来重写Super.prototype中的方法。methodB就是一个例子,在图 17-7 中,我们可以看到它为什么有效:对methodB的搜索始于subInstance,在找到Super.prototype.methodB之前找到了Sub.prototype.methodB。
进行超级调用
要理解超级调用,您需要了解术语主对象。方法的主对象是拥有其值为方法的属性的对象。例如,Sub.prototype.methodB的主对象是Sub.prototype。超级调用方法foo涉及三个步骤:
-
从当前方法的主对象的原型“之后”(在原型中)开始搜索。
-
查找一个名为
foo的方法。 -
使用当前的
this调用该方法。其理由是超级方法必须与当前方法使用相同的实例;它必须能够访问相同的实例属性。
因此,子方法的代码如下所示。它超级调用自己,调用它已经重写的方法:
Sub.prototype.methodB = function (x, y) {
var superResult = Super.prototype.methodB.call(this, x, y); // (1)
return this.prop3 + ' ' + superResult;
}
阅读(1)处的超级调用的一种方式是:直接引用超级方法并使用当前的this调用它。但是,如果我们将其分为三个部分,我们会发现上述步骤:
-
Super.prototype:从Super.prototype开始搜索,即Sub.prototype的原型(当前方法Sub.prototype.methodB的主对象)。 -
methodB:查找一个名为methodB的方法。 -
call(this, ...):调用在上一步中找到的方法,并保持当前的this。
避免硬编码超级构造函数的名称
到目前为止,我们总是通过提及超级构造函数名称来引用超级方法和超级构造函数。这种硬编码使您的代码不够灵活。您可以通过将超级原型分配给Sub的属性来避免这种情况:
Sub._super = Super.prototype;
然后调用超级构造函数和超级方法如下所示:
function Sub(prop1, prop2, prop3, prop4) {
Sub._super.constructor.call(this, prop1, prop2);
this.prop3 = prop3;
this.prop4 = prop4;
}
Sub.prototype.methodB = function (x, y) {
var superResult = Sub._super.methodB.call(this, x, y);
return this.prop3 + ' ' + superResult;
}
设置Sub._super通常由一个实用函数处理,该函数还将子原型连接到超级原型。例如:
function subclasses(SubC, SuperC) {
var subProto = Object.create(SuperC.prototype);
// Save `constructor` and, possibly, other methods
copyOwnPropertiesFrom(subProto, SubC.prototype);
SubC.prototype = subProto;
SubC._super = SuperC.prototype;
};
此代码使用了辅助函数copyOwnPropertiesFrom(),该函数在复制对象中显示并解释。
提示
将“子类”解释为一个动词:SubC 子类 SuperC。这样一个实用函数可以减轻创建子构造函数的痛苦:手动操作的事情更少,而且不会多次提及超级构造函数的名称。以下示例演示了它如何简化代码。
示例:使用中的构造函数继承
具体示例,假设构造函数Person已经存在:
function Person(name) {
this.name = name;
}
Person.prototype.describe = function () {
return 'Person called '+this.name;
};
我们现在想要创建构造函数Employee作为Person的子构造函数。我们手动这样做,看起来像这样:
function Employee(name, title) {
Person.call(this, name);
this.title = title;
}
Employee.prototype = Object.create(Person.prototype);
Employee.prototype.constructor = Employee;
Employee.prototype.describe = function () {
return Person.prototype.describe.call(this)+' ('+this.title+')';
};
以下是交互:
> var jane = new Employee('Jane', 'CTO');
> jane.describe()
Person called Jane (CTO)
> jane instanceof Employee
true
> jane instanceof Person
true
前一节的实用函数subclasses()使Employee的代码稍微简化,并避免了硬编码超级构造函数Person:
function Employee(name, title) {
Employee._super.constructor.call(this, name);
this.title = title;
}
Employee.prototype.describe = function () {
return Employee._super.describe.call(this)+' ('+this.title+')';
};
subclasses(Employee, Person);
示例:内置构造函数的继承层次结构
内置构造函数使用本节描述的相同子类化方法。例如,Array是Object的子构造函数。因此,Array的实例的原型链如下所示:
> var p = Object.getPrototypeOf
> p([]) === Array.prototype
true
> p(p([])) === Object.prototype
true
> p(p(p([]))) === null
true
反模式:原型是超级构造函数的实例
在 ECMAScript 5 和Object.create()之前,经常使用的解决方案是通过调用超级构造函数来创建子原型:
Sub.prototype = new Super(); // Don’t do this
在 ECMAScript 5 下不推荐这样做。原型将具有所有Super的实例属性,而它没有用处。因此,最好使用上述模式(涉及Object.create())。
所有对象的方法
几乎所有对象的原型链中都有Object.prototype:
> Object.prototype.isPrototypeOf({})
true
> Object.prototype.isPrototypeOf([])
true
> Object.prototype.isPrototypeOf(/xyz/)
true
以下各小节描述了Object.prototype为其原型提供的方法。
转换为原始值
以下两种方法用于将对象转换为原始值:
Object.prototype.toString()
返回对象的字符串表示:
> ({ first: 'John', last: 'Doe' }.toString())
'[object Object]'
> [ 'a', 'b', 'c' ].toString()
'a,b,c'
Object.prototype.valueOf()
这是将对象转换为数字的首选方法。默认实现返回this:
> var obj = {};
> obj.valueOf() === obj
true
valueOf被包装构造函数覆盖以返回包装的原始值:
> new Number(7).valueOf()
7
数字和字符串的转换(无论是隐式还是显式)都建立在原始值的转换基础上(有关详细信息,请参见算法:ToPrimitive()—将值转换为原始值)。这就是为什么您可以使用上述两种方法来配置这些转换。valueOf() 是数字转换的首选方法:
> 3 * { valueOf: function () { return 5 } }
15
toString() 是首选的字符串转换方法:
> String({ toString: function () { return 'ME' } })
'Result: ME'
布尔转换不可配置;对象始终被视为true(参见转换为布尔值)。
Object.prototype.toLocaleString()
此方法返回对象的区域特定的字符串表示。默认实现调用toString()。大多数引擎对于此方法的支持不会超出此范围。然而,ECMAScript 国际化 API(参见ECMAScript 国际化 API)由许多现代引擎支持,它为几个内置构造函数覆盖了此方法。
原型继承和属性
以下方法有助于原型继承和属性:
Object.prototype.isPrototypeOf(obj)
如果接收者是obj的原型链的一部分,则返回true:
> var proto = { };
> var obj = Object.create(proto);
> proto.isPrototypeOf(obj)
true
> obj.isPrototypeOf(obj)
false
Object.prototype.hasOwnProperty(key)
如果this拥有一个键为key的属性,则返回true。“拥有”意味着属性存在于对象本身,而不是其原型链中的一个。
警告
通常应该通用地调用此方法(而不是直接调用),特别是在静态不知道属性的对象上。为什么以及如何在迭代和检测属性中有解释:
> var proto = { foo: 'abc' };
> var obj = Object.create(proto);
> obj.bar = 'def';
> Object.prototype.hasOwnProperty.call(obj, 'foo')
false
> Object.prototype.hasOwnProperty.call(obj, 'bar')
true
Object.prototype.propertyIsEnumerable(propKey)
如果接收者具有具有可枚举键propKey的属性,则返回true,否则返回false:
> var obj = { foo: 'abc' };
> obj.propertyIsEnumerable('foo')
true
> obj.propertyIsEnumerable('toString')
false
> obj.propertyIsEnumerable('unknown')
false
通用方法:从原型中借用方法
有时实例原型具有对更多对象有用的方法,而不仅仅是继承自它们的对象。本节解释了如何使用原型的方法而不继承它。例如,实例原型Wine.prototype具有方法incAge():
function Wine(age) {
this.age = age;
}
Wine.prototype.incAge = function (years) {
this.age += years;
}
交互如下:
> var chablis = new Wine(3);
> chablis.incAge(1);
> chablis.age
4
incAge()方法适用于具有age属性的任何对象。我们如何在不是Wine实例的对象上调用它?让我们看看前面的方法调用:
chablis.incAge(1)
实际上有两个参数:
-
chablis是方法调用的接收器,通过this传递给incAge。 -
1是一个参数,通过years传递给incAge。
我们不能用任意对象替换前者——接收器必须是Wine的实例。否则,找不到方法incAge。但前面的方法调用等同于(参见Calling Functions While Setting this: call(), apply(), and bind()):
Wine.prototype.incAge.call(chablis, 1)
通过前面的模式,我们可以使一个对象成为接收器(call的第一个参数),而不是Wine的实例,因为接收器不用于查找方法Wine.prototype.incAge。在下面的例子中,我们将方法incAge()应用于对象john:
> var john = { age: 51 };
> Wine.prototype.incAge.call(john, 3)
> john.age
54
可以以这种方式使用的函数称为通用方法;它必须准备好this不是“它”的构造函数的实例。因此,并非所有方法都是通用的;ECMAScript 语言规范明确规定了哪些方法是通用的(参见A List of All Generic Methods)。
通过文字直接访问 Object.prototype 和 Array.prototype
通用调用方法相当冗长:
Object.prototype.hasOwnProperty.call(obj, 'propKey')
您可以通过访问空对象文字创建的 Object 实例来更简洁地访问hasOwnProperty:
{}.hasOwnProperty.call(obj, 'propKey')
同样,以下两个表达式是等价的:
Array.prototype.join.call(str, '-')
[].join.call(str, '-')
这种模式的优势在于它不太啰嗦。但它也不太容易理解。性能不应该是一个问题(至少从长远来看),因为引擎可以静态确定文字不应该创建对象。
通用调用方法的示例
以下是一些通用方法的使用示例:
-
使用
apply()(参见Function.prototype.apply(thisValue, argArray))来推送一个数组(而不是单个元素;参见Adding and Removing Elements (Destructive)):> var arr1 = [ 'a', 'b' ]; > var arr2 = [ 'c', 'd' ]; > [].push.apply(arr1, arr2) 4 > arr1 [ 'a', 'b', 'c', 'd' ]
这个例子是关于将数组转换为参数,而不是从另一个构造函数中借用方法。
-
将数组方法
join()应用于字符串(不是数组):> Array.prototype.join.call('abc', '-') 'a-b-c' -
将数组方法
map()应用于字符串:¹⁵> [].map.call('abc', function (x) { return x.toUpperCase() }) [ 'A', 'B', 'C' ]
通用地使用map()比使用split('')更有效,后者会创建一个中间数组:
> 'abc'.split('').map(function (x) { return x.toUpperCase() })
[ 'A', 'B', 'C' ]
```
+ 将字符串方法应用于非字符串。`toUpperCase()`将接收器转换为字符串并将结果大写:
```js
> String.prototype.toUpperCase.call(true)
'TRUE'
> String.prototype.toUpperCase.call(['a','b','c'])
'A,B,C'
```
在普通对象上使用通用数组方法可以让您了解它们的工作原理:
+ 在伪数组上调用数组方法:
```js
> var fakeArray = { 0: 'a', 1: 'b', length: 2 };
> Array.prototype.join.call(fakeArray, '-')
'a-b'
```
+ 看看数组方法如何转换一个被视为数组的对象:
```js
> var obj = {};
> Array.prototype.push.call(obj, 'hello');
1
> obj
{ '0': 'hello', length: 1 }
```
### 类似数组的对象和通用方法
JavaScript 中有一些感觉像数组但实际上不是的对象。这意味着它们具有索引访问和`length`属性,但它们没有任何数组方法(`forEach()`,`push`,`concat()`等)。这很不幸,但正如我们将看到的,通用数组方法可以实现一种解决方法。类似数组的对象的示例包括:
+ 特殊变量`arguments`(参见[All Parameters by Index: The Special Variable arguments](ch15.html#arguments_variable "All Parameters by Index: The Special Variable arguments")),它是一个重要的类数组对象,因为它是 JavaScript 的一个基本部分。`arguments`看起来像一个数组:
```js
> function args() { return arguments }
> var arrayLike = args('a', 'b');
> arrayLike[0]
'a'
> arrayLike.length
2
```
但是没有任何数组方法可用:
```js
> arrayLike.join('-')
TypeError: object has no method 'join'
```
这是因为`arrayLike`不是`Array`的实例(并且`Array.prototype`不在原型链中):
```js
> arrayLike instanceof Array
false
```
+ 浏览器 DOM 节点列表,由`document.getElementsBy*()`(例如`getElementsByTagName()`)、`document.forms`等返回:
```js
> var elts = document.getElementsByTagName('h3');
> elts.length
3
> elts instanceof Array
false
```
+ 字符串也是类数组的:
```js
> 'abc'[1]
'b'
> 'abc'.length
3
```
术语*类数组*也可以被视为通用数组方法和对象之间的契约。对象必须满足某些要求;否则,这些方法将无法在它们上面工作。这些要求是:
+ 类数组对象的元素必须可以通过方括号和从 0 开始的整数索引访问。所有方法都需要读取访问权限,一些方法还需要写入访问权限。请注意,所有对象都支持这种索引:方括号中的索引被转换为字符串并用作查找属性值的键:
```js
> var obj = { '0': 'abc' };
> obj[0]
'abc'
```
+ 类数组对象必须有一个`length`属性,其值是其元素的数量。一些方法要求`length`是可变的(例如`reverse()`)。长度不可变的值(例如字符串)不能与这些方法一起使用。
#### 处理类数组对象的模式
以下模式对处理类数组对象很有用:
+ 将类数组对象转换为数组:
```js
var arr = Array.prototype.slice.call(arguments);
```
方法`slice()`(参见[Concatenating, Slicing, Joining (Nondestructive)](ch18.html#Array.prototype.slice "Concatenating, Slicing, Joining (Nondestructive"))没有任何参数时会创建一个数组接收者的副本:
```js
var copy = [ 'a', 'b' ].slice();
```
+ 要遍历类数组对象的所有元素,可以使用简单的`for`循环:
```js
function logArgs() {
for (var i=0; i<arguments.length; i++) {
console.log(i+'. '+arguments[i]);
}
}
```
但你也可以借用`Array.prototype.forEach()`:
```js
function logArgs() {
Array.prototype.forEach.call(arguments, function (elem, i) {
console.log(i+'. '+elem);
});
}
```
在这两种情况下,交互如下:
```js
> logArgs('hello', 'world');
0\. hello
1\. world
```
### 通用方法列表
以下列表包括所有在 ECMAScript 语言规范中提到的通用方法:
+ `Array.prototype`(参见[Array Prototype Methods](ch18.html#array_prototype_methods "Array Prototype Methods")):
+ `concat`
+ `every`
+ `filter`
+ `forEach`
+ `indexOf`
+ `join`
+ `lastIndexOf`
+ `map`
+ `pop`
+ `push`
+ `reduce`
+ `reduceRight`
+ `reverse`
+ `shift`
+ `slice`
+ `some`
+ `sort`
+ `splice`
+ `toLocaleString`
+ `toString`
+ `unshift`
+ `Date.prototype`(参见[Date Prototype Methods](ch20.html#date_prototype_methods "Date Prototype Methods"))
+ `toJSON`
+ `Object.prototype`(参见[Methods of All Objects](ch17_split_001.html#methods_of_all_objects "Methods of All Objects"))
+ (所有`Object`方法都自动是通用的——它们必须适用于所有对象。)
+ `String.prototype`(参见[String Prototype Methods](ch12.html#string_prototype_methods "String Prototype Methods"))
+ `charAt`
+ `charCodeAt`
+ `concat`
+ `indexOf`
+ `lastIndexOf`
+ `localeCompare`
+ `match`
+ `replace`
+ `search`
+ `slice`
+ `split`
+ `substring`
+ `toLocaleLowerCase`
+ `toLocaleUpperCase`
+ `toLowerCase`
+ `toUpperCase`
+ `trim`
## 陷阱:使用对象作为映射
由于 JavaScript 没有内置的映射数据结构,对象经常被用作从字符串到值的映射。然而,这比看起来更容易出错。本节解释了在这个任务中涉及的三个陷阱。
### 陷阱 1:继承影响属性读取
读取属性的操作可以分为两种:
+ 一些操作会考虑整个原型链并查看继承的属性。
+ 其他操作只访问对象的*自有*(非继承的)属性。
当你读取对象作为映射的条目时,你需要仔细选择这些操作。为了理解原因,考虑以下示例:
```js
var proto = { protoProp: 'a' };
var obj = Object.create(proto);
obj.ownProp = 'b';
obj是一个具有一个自有属性的对象,其原型是proto,proto也有一个自有属性。proto的原型是Object.prototype,就像所有通过对象文字创建的对象一样。因此,obj从proto和Object.继承属性。
我们希望obj被解释为具有单个条目的映射:
ownProp: 'b'
也就是说,我们希望忽略继承的属性,只考虑自有属性。让我们看看哪些读取操作以这种方式解释obj,哪些不是。请注意,对于对象作为映射,我们通常希望使用存储在变量中的任意属性键。这排除了点表示法。
检查属性是否存在
in运算符检查对象是否具有给定键的属性,但它会考虑继承的属性:
> 'ownProp' in obj // ok
true
> 'unknown' in obj // ok
false
> 'toString' in obj // wrong, inherited from Object.prototype
true
> 'protoProp' in obj // wrong, inherited from proto
true
我们需要检查以忽略继承的属性。hasOwnProperty()正是我们想要的:
> obj.hasOwnProperty('ownProp') // ok
true
> obj.hasOwnProperty('unknown') // ok
false
> obj.hasOwnProperty('toString') // ok
false
> obj.hasOwnProperty('protoProp') // ok
false
收集属性键
我们可以使用什么操作来找到obj的所有键,同时又尊重我们对其作为映射的解释?for-in看起来可能有效。但是,不幸的是,它不行:
> for (propKey in obj) console.log(propKey)
ownProp
protoProp
它会考虑继承的可枚举属性。Object.prototype的属性没有显示在这里的原因是它们都是不可枚举的。
相比之下,Object.keys()只列出自有属性:
> Object.keys(obj)
[ 'ownProp' ]
这个方法只返回可枚举的自有属性;ownProp是通过赋值添加的,因此默认情况下是可枚举的。如果你想列出所有自有属性,你需要使用Object.getOwnPropertyNames()。
获取属性值
对于读取属性值,我们只能在点运算符和括号运算符之间进行选择。我们不能使用前者,因为我们有存储在变量中的任意键。这就只剩下了括号运算符,它会考虑继承的属性:
> obj['toString']
[Function: toString]
这不是我们想要的。没有内置操作可以只读取自有属性,但你可以很容易地自己实现一个:
function getOwnProperty(obj, propKey) {
// Using hasOwnProperty() in this manner is problematic
// (explained and fixed later)
return (obj.hasOwnProperty(propKey)
? obj[propKey] : undefined);
}
有了这个函数,继承的属性toString被忽略了:
> getOwnProperty(obj, 'toString')
undefined
陷阱 2:覆盖影响调用方法
函数getOwnProperty()在obj上调用了方法hasOwnProperty()。通常情况下,这是可以的:
> getOwnProperty({ foo: 123 }, 'foo')
123
然而,如果你向obj添加一个键为hasOwnProperty的属性,那么该属性将覆盖方法Object.prototype.hasOwnProperty(),getOwnProperty()将不起作用:
> getOwnProperty({ hasOwnProperty: 123 }, 'foo')
TypeError: Property 'hasOwnProperty' is not a function
你可以通过直接引用hasOwnProperty()来解决这个问题。这避免了通过obj来查找它:
function getOwnProperty(obj, propKey) {
return (Object.prototype.hasOwnProperty.call(obj, propKey)
? obj[propKey] : undefined);
}
我们已经通用地调用了hasOwnProperty()(参见通用方法:从原型中借用方法)。
陷阱 3:特殊属性 proto
在许多 JavaScript 引擎中,属性__proto__(参见特殊属性 proto)是特殊的:获取它会检索对象的原型,设置它会改变对象的原型。这就是为什么对象不能在键为'__proto__'的属性中存储映射数据。如果你想允许映射键'__proto__',你必须在使用它作为属性键之前对其进行转义:
function get(obj, key) {
return obj[escapeKey(key)];
}
function set(obj, key, value) {
obj[escapeKey(key)] = value;
}
// Similar: checking if key exists, deleting an entry
function escapeKey(key) {
if (key.indexOf('__proto__') === 0) { // (1)
return key+'%';
} else {
return key;
}
}
我们还需要转义'__proto__'(等等)的转义版本,以避免冲突;也就是说,如果我们将键'__proto__'转义为'__proto__%',那么我们还需要转义键'__proto__%',以免它替换'__proto__'条目。这就是第(1)行发生的情况。
Mark S. Miller 在一封电子邮件中提到了这个陷阱的现实影响:
认为这个练习是学术性的,不会在实际系统中出现吗?正如在一个支持主题中观察到的,直到最近,在所有非 IE 浏览器上,如果你在新的 Google Doc 开头输入“proto”,你的 Google Doc 会卡住。这是因为将对象作为字符串映射的错误使用。
dict 模式:没有原型的对象更适合作为映射
你可以这样创建一个没有原型的对象:
var dict = Object.create(null);
这样的对象比普通对象更好的映射(字典),这就是为什么有时这种模式被称为dict 模式(dict代表dictionary)。让我们首先检查普通对象,然后找出为什么无原型对象是更好的映射。
普通对象
通常,您在 JavaScript 中创建的每个对象至少都有Object.prototype在其原型链中。Object.prototype的原型是null,因此大多数原型链都在这里结束:
> Object.getPrototypeOf({}) === Object.prototype
true
> Object.getPrototypeOf(Object.prototype)
null
无原型对象
无原型对象作为映射有两个优点:
-
继承的属性(陷阱#1)不再是问题,因为根本没有。因此,您现在可以自由使用
in运算符来检测属性是否存在,并使用括号来读取属性。 -
很快,
__proto__将被禁用。在 ECMAScript 6 中,如果Object.prototype不在对象的原型链中,特殊属性__proto__将被禁用。您可以期望 JavaScript 引擎慢慢迁移到这种行为,但目前还不太常见。
唯一的缺点是您将失去Object.prototype提供的服务。例如,dict 对象不再可以自动转换为字符串:
> console.log('Result: '+obj)
TypeError: Cannot convert object to primitive value
但这并不是真正的缺点,因为直接在 dict 对象上调用方法是不安全的。
推荐
在快速的 hack 和库的基础上使用 dict 模式。在(非库)生产代码中,库更可取,因为您可以确保避免所有陷阱。下一节列出了一些这样的库。
最佳实践
使用对象作为映射有许多应用。如果所有属性键在开发时已经静态知道,那么你只需要确保忽略继承,只查看自有属性。如果可以使用任意键,你应该转向库,以避免本节中提到的陷阱。以下是两个例子:
-
Google 的 es-lab的StringMap.js
-
Olov Lassus的stringmap.js
速查表:使用对象
本节是一个快速参考,指向更详细的解释。
-
对象字面量(参见对象字面量):
var jane = { name: 'Jane', 'not an identifier': 123, describe: function () { // method return 'Person named '+this.name; }, }; // Call a method: console.log(jane.describe()); // Person named Jane -
点运算符(.)(参见点运算符(.):通过固定键访问属性):
obj.propKey obj.propKey = value delete obj.propKey -
括号运算符([])(参见括号运算符([]):通过计算键访问属性):
obj['propKey'] obj['propKey'] = value delete obj['propKey'] -
获取和设置原型(参见获取和设置原型):
Object.create(proto, propDescObj?) Object.getPrototypeOf(obj) -
属性的迭代和检测(参见属性的迭代和检测):
Object.keys(obj) Object.getOwnPropertyNames(obj) Object.prototype.hasOwnProperty.call(obj, propKey) propKey in obj -
通过描述符获取和定义属性(参见通过描述符获取和定义属性):
Object.defineProperty(obj, propKey, propDesc) Object.defineProperties(obj, propDescObj) Object.getOwnPropertyDescriptor(obj, propKey) Object.create(proto, propDescObj?) -
保护对象(参见保护对象):
Object.preventExtensions(obj) Object.isExtensible(obj) Object.seal(obj) Object.isSealed(obj) Object.freeze(obj) Object.isFrozen(obj) -
所有对象的方法(参见所有对象的方法):
Object.prototype.toString() Object.prototype.valueOf() Object.prototype.toLocaleString() Object.prototype.isPrototypeOf(obj) Object.prototype.hasOwnProperty(key) Object.prototype.propertyIsEnumerable(propKey)
¹⁵通过这种方式使用map()是 Brandon Benvie(@benvie)的一个提示。
第十八章:数组
原文:18. Arrays
译者:飞龙
协议:CC BY-NC-SA 4.0
数组是从索引(从零开始的自然数)到任意值的映射。值(映射的范围)称为数组的元素。创建数组的最方便的方法是通过数组字面量。这样的字面量列举了数组元素;元素的位置隐含地指定了它的索引。
在本章中,我将首先介绍基本的数组机制,如索引访问和length属性,然后再介绍数组方法。
概述
本节提供了数组的快速概述。详细内容将在后面解释。
作为第一个例子,我们通过数组字面量创建一个数组 arr(参见[创建数组](ch18.html#creating_arrays “Creating Arrays”))并访问元素(参见[数组索引](ch18.html#array_indices “Array Indices”):
> var arr = [ 'a', 'b', 'c' ]; // array literal
> arr[0] // get element 0
'a'
> arr[0] = 'x'; // set element 0
> arr
[ 'x', 'b', 'c' ]
我们可以使用数组属性 length(参见length)来删除和追加元素:
> var arr = [ 'a', 'b', 'c' ];
> arr.length
3
> arr.length = 2; // remove an element
> arr
[ 'a', 'b' ]
> arr[arr.length] = 'd'; // append an element
> arr
[ 'a', 'b', 'd' ]
数组方法 push() 提供了另一种追加元素的方式:
> var arr = [ 'a', 'b' ];
> arr.push('d')
3
> arr
[ 'a', 'b', 'd' ]
数组是映射,不是元组
ECMAScript 标准将数组规定为从索引到值的映射(字典)。换句话说,数组可能不是连续的,并且可能有空洞。例如:
> var arr = [];
> arr[0] = 'a';
'a'
> arr[2] = 'b';
'b'
> arr
[ 'a', , 'b' ]
前面的数组有一个空洞:索引 1 处没有元素。数组中的空洞 更详细地解释了空洞。
请注意,大多数 JavaScript 引擎会在内部优化没有空洞的数组,并将它们连续存储。
数组也可以有属性
数组仍然是对象,可以有对象属性。这些属性不被视为实际数组的一部分;也就是说,它们不被视为数组元素:
> var arr = [ 'a', 'b' ];
> arr.foo = 123;
> arr
[ 'a', 'b' ]
> arr.foo
123
创建数组
你可以通过数组字面量创建一个数组:
var myArray = [ 'a', 'b', 'c' ];
数组中的尾随逗号会被忽略:
> [ 'a', 'b' ].length
2
> [ 'a', 'b', ].length
2
> [ 'a', 'b', ,].length // hole + trailing comma
3
数组构造函数
有两种使用构造函数 Array 的方式:可以创建一个给定长度的空数组,或者数组的元素是给定的值。对于这个构造函数,new 是可选的:以普通函数的方式调用它(不带 new)与以构造函数的方式调用它是一样的。
创建一个给定长度的空数组
给定长度的空数组中只有空洞!因此,很少有意义使用这个版本的构造函数:
> var arr = new Array(2);
> arr.length
2
> arr // two holes plus trailing comma (ignored!)
[ , ,]
一些引擎在以这种方式调用 Array() 时可能会预先分配连续的内存,这可能会稍微提高性能。但是,请确保增加的冗余性值得!
初始化带有元素的数组(避免!)
这种调用 Array 的方式类似于数组字面量:
// The same as ['a', 'b', 'c']:
var arr1 = new Array('a', 'b', 'c');
问题在于你不能创建只有一个数字的数组,因为那会被解释为创建一个 length 为该数字的数组:
> new Array(2) // alas, not [ 2 ]
[ , ,]
> new Array(5.7) // alas, not [ 5.7 ]
RangeError: Invalid array length
> new Array('abc') // ok
[ 'abc' ]
多维数组
如果你需要为元素创建多个维度,你必须嵌套数组。当你创建这样的嵌套数组时,最内层的数组可以根据需要增长。但是,如果你想直接访问元素,你至少需要创建外部数组。在下面的例子中,我为井字游戏创建了一个三乘三的矩阵。该矩阵完全填满了数据(而不是让行根据需要增长):
// Create the Tic-tac-toe board
var rows = [];
for (var rowCount=0; rowCount < 3; rowCount++) {
rows[rowCount] = [];
for (var colCount=0; colCount < 3; colCount++) {
rows[rowCount][colCount] = '.';
}
}
// Set an X in the upper right corner
rows[0][2] = 'X'; // [row][column]
// Print the board
rows.forEach(function (row) {
console.log(row.join(' '));
});
以下是输出:
. . X
. . .
. . .
我希望这个例子能够演示一般情况。显然,如果矩阵很小并且具有固定的维度,你可以通过数组字面量来设置它:
var rows = [ ['.','.','.'], ['.','.','.'], ['.','.','.'] ];
数组索引
当你使用数组索引时,你必须牢记以下限制:
-
索引是范围在 0 ≤
i< 2³²−1 的数字 i。 -
最大长度为 2³²−1。
超出范围的索引被视为普通的属性键(字符串!)。它们不会显示为数组元素,也不会影响属性 length。例如:
> var arr = [];
> arr[-1] = 'a';
> arr
[]
> arr['-1']
'a'
> arr[4294967296] = 'b';
> arr
[]
> arr['4294967296']
'b'
in 操作符和索引
in 操作符用于检测对象是否具有给定键的属性。但它也可以用于确定数组中是否存在给定的元素索引。例如:
> var arr = [ 'a', , 'b' ];
> 0 in arr
true
> 1 in arr
false
> 10 in arr
false
删除数组元素
除了删除属性之外,delete 操作符还可以删除数组元素。删除元素会创建空洞(length 属性不会更新):
> var arr = [ 'a', 'b' ];
> arr.length
2
> delete arr[1] // does not update length
true
> arr
[ 'a', ]
> arr.length
2
你也可以通过减少数组的长度来删除尾随的数组元素(参见length了解详情)。要删除元素而不创建空洞(即,后续元素的索引被减少),你可以使用 Array.prototype.splice()(参见添加和删除元素(破坏性))。在这个例子中,我们删除索引为 1 的两个元素:
> var arr = ['a', 'b', 'c', 'd'];
> arr.splice(1, 2) // returns what has been removed
[ 'b', 'c' ]
> arr
[ 'a', 'd' ]
数组索引详解
提示
这是一个高级部分。通常情况下,您不需要知道这里解释的细节。
数组索引并非看起来那样。 到目前为止,我一直假装数组索引是数字。这也是 JavaScript 引擎在内部实现数组的方式。然而,ECMAScript 规范对索引的看法不同。引用第 15.4 节的话来说:
-
如果且仅当
ToString``(ToUint32(P))等于P且ToUint32(P)不等于 2³²−1 时,属性键P(一个字符串)才是数组索引。这意味着什么将在下面解释。 -
属性键为数组索引的数组属性称为元素。
换句话说,在规范中,括号中的所有值都被转换为字符串,并解释为属性键,甚至是数字。以下互动演示了这一点:
> var arr = ['a', 'b'];
> arr['0']
'a'
> arr[0]
'a'
要成为数组索引,属性键P(一个字符串!)必须等于以下计算结果:
-
将
P转换为数字。 -
将数字转换为 32 位无符号整数。
-
将整数转换为字符串。
这意味着数组索引必须是 32 位范围内的字符串化整数i,其中 0 ≤ i < 2³²−1。规范明确排除了上限(如前面引用的)。它保留给了最大长度。要了解这个定义是如何工作的,让我们使用通过位运算符实现 32 位整数中的ToUint32()函数。
首先,不包含数字的字符串总是转换为 0,这在字符串化后不等于字符串:
> ToUint32('xyz')
0
> ToUint32('?@#!')
0
其次,超出范围的字符串化整数也会转换为完全不同的整数,与字符串化后不相等:
> ToUint32('-1')
4294967295
> Math.pow(2, 32)
4294967296
> ToUint32('4294967296')
0
第三,字符串化的非整数数字会转换为整数,这些整数又是不同的:
> ToUint32('1.371')
1
请注意,规范还强制规定数组索引不得具有指数:
> ToUint32('1e3')
1000
它们不包含前导零:
> var arr = ['a', 'b'];
> arr['0'] // array index
'a'
> arr['00'] // normal property
undefined
长度
length属性的基本功能是跟踪数组中的最高索引:
> [ 'a', 'b' ].length
2
> [ 'a', , 'b' ].length
3
因此,length不计算元素的数量,因此您必须编写自己的函数来执行此操作。例如:
function countElements(arr) {
var elemCount = 0;
arr.forEach(function () {
elemCount++;
});
return elemCount;
}
为了计算元素(非空洞),我们已经利用了forEach跳过空洞的事实。以下是互动:
> countElements([ 'a', 'b' ])
2
> countElements([ 'a', , 'b' ])
2
手动增加数组的长度
手动增加数组的长度对数组几乎没有影响;它只会创建空洞:
> var arr = [ 'a', 'b' ];
> arr.length = 3;
> arr // one hole at the end
[ 'a', 'b', ,]
最后的结果末尾有两个逗号,因为尾随逗号是可选的,因此总是被忽略。
我们刚刚做的并没有添加任何元素:
> countElements(arr)
2
然而,length属性确实作为指针,指示在哪里插入新元素。例如:
> arr.push('c')
4
> arr
[ 'a', 'b', , 'c' ]
因此,通过Array构造函数设置数组的初始长度会创建一个完全空的数组:
> var arr = new Array(2);
> arr.length
2
> countElements(arr)
0
减少数组的长度
如果您减少数组的长度,则新长度及以上的所有元素都将被删除:
> var arr = [ 'a', 'b', 'c' ];
> 1 in arr
true
> arr[1]
'b'
> arr.length = 1;
> arr
[ 'a' ]
> 1 in arr
false
> arr[1]
undefined
清除数组
如果将数组的长度设置为 0,则它将变为空。这样可以清除数组。例如:
function clearArray(arr) {
arr.length = 0;
}
以下是互动:
> var arr = [ 'a', 'b', 'c' ];
> clearArray(arr)
> arr
[]
但是,请注意,这种方法可能会很慢,因为每个数组元素都会被显式删除。具有讽刺意味的是,创建一个新的空数组通常更快:
arr = [];
清除共享数组
您需要知道的是,将数组的长度设置为零会影响共享数组的所有人:
> var a1 = [1, 2, 3];
> var a2 = a1;
> a1.length = 0;
> a1
[]
> a2
[]
相比之下,分配一个空数组不会:
> var a1 = [1, 2, 3];
> var a2 = a1;
> a1 = [];
> a1
[]
> a2
[ 1, 2, 3 ]
最大长度
最大数组长度为 2³²−1:
> var arr1 = new Array(Math.pow(2, 32)); // not ok
RangeError: Invalid array length
> var arr2 = new Array(Math.pow(2, 32)-1); // ok
> arr2.push('x');
RangeError: Invalid array length
数组中的空洞
数组是从索引到值的映射。这意味着数组可以有空洞,即长度小于数组中缺失的索引。在这些索引中读取元素会返回undefined。
提示
建议避免数组中的空洞。JavaScript 对它们的处理不一致(即,一些方法忽略它们,其他方法不会)。幸运的是,通常你不需要知道如何处理空洞:它们很少有用,并且会对性能产生负面影响。
创建空洞
通过给数组索引赋值可以创建空洞:
> var arr = [];
> arr[0] = 'a';
> arr[2] = 'c';
> 1 in arr // hole at index 1
false
也可以通过在数组字面量中省略值来创建空洞:
> var arr = ['a',,'c'];
> 1 in arr // hole at index 1
false
警告
需要两个尾随逗号来创建尾随的空洞,因为最后一个逗号总是被忽略:
> [ 'a', ].length
1
> [ 'a', ,].length
2
稀疏数组与密集数组
本节将检查空洞和undefined作为元素之间的区别。鉴于读取空洞会返回undefined,两者非常相似。
带有空洞的数组称为稀疏数组。没有空洞的数组称为密集数组。密集数组是连续的,并且在每个索引处都有一个元素——从零开始,到length-1 结束。让我们比较以下两个数组,一个是稀疏数组,一个是密集数组。这两者非常相似:
var sparse = [ , , 'c' ];
var dense = [ undefined, undefined, 'c' ];
空洞几乎就像在相同索引处有一个undefined元素。两个数组的长度都是一样的:
> sparse.length
3
> dense.length
3
但是稀疏数组没有索引为 0 的元素:
> 0 in sparse
false
> 0 in dense
true
通过for进行迭代对两个数组来说是一样的:
> for (var i=0; i<sparse.length; i++) console.log(sparse[i]);
undefined
undefined
c
> for (var i=0; i<dense.length; i++) console.log(dense[i]);
undefined
undefined
c
通过forEach进行迭代会跳过空洞,但不会跳过未定义的元素:
> sparse.forEach(function (x) { console.log(x) });
c
> dense.forEach(function (x) { console.log(x) });
undefined
undefined
c
哪些操作会忽略空洞,哪些会考虑它们?
涉及数组的一些操作会忽略空洞,而另一些会考虑它们。本节解释了细节。
数组迭代方法
forEach()会跳过空洞:
> ['a',, 'b'].forEach(function (x,i) { console.log(i+'.'+x) })
0.a
2.b
every()也会跳过空洞(类似的:some()):
> ['a',, 'b'].every(function (x) { return typeof x === 'string' })
true
map()会跳过,但保留空洞:
> ['a',, 'b'].map(function (x,i) { return i+'.'+x })
[ '0.a', , '2.b' ]
filter()消除空洞:
> ['a',, 'b'].filter(function (x) { return true })
[ 'a', 'b' ]
其他数组方法
join()将空洞、undefined和null转换为空字符串:
> ['a',, 'b'].join('-')
'a--b'
> [ 'a', undefined, 'b' ].join('-')
'a--b'
sort()在排序时保留空洞:
> ['a',, 'b'].sort() // length of result is 3
[ 'a', 'b', , ]
for-in 循环
for-in循环正确列出属性键(它们是数组索引的超集):
> for (var key in ['a',, 'b']) { console.log(key) }
0
2
Function.prototype.apply()
apply()将每个空洞转换为一个值为undefined的参数。以下交互演示了这一点:函数f()将其参数作为数组返回。当我们传递一个带有三个空洞的数组给apply()以调用f()时,后者接收到三个undefined参数:
> function f() { return [].slice.call(arguments) }
> f.apply(null, [ , , ,])
[ undefined, undefined, undefined ]
这意味着我们可以使用apply()来创建一个带有undefined的数组:
> Array.apply(null, Array(3))
[ undefined, undefined, undefined ]
警告
apply()将空洞转换为undefined在空数组中,但不能用于在任意数组中填补空洞(可能包含或不包含空洞)。例如,任意数组[2]:
> Array.apply(null, [2])
[ , ,]
数组不包含任何空洞,所以apply()应该返回相同的数组。但实际上它返回一个长度为 2 的空数组(它只包含两个空洞)。这是因为Array()将单个数字解释为数组长度,而不是数组元素。
从数组中移除空洞
正如我们所见,filter()会移除空洞:
> ['a',, 'b'].filter(function (x) { return true })
[ 'a', 'b' ]
使用自定义函数将任意数组中的空洞转换为undefined:
function convertHolesToUndefineds(arr) {
var result = [];
for (var i=0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
使用该函数:
> convertHolesToUndefineds(['a',, 'b'])
[ 'a', undefined, 'b' ]
数组构造方法
Array.isArray(obj)
如果obj是数组则返回true。它正确处理跨realms(窗口或框架)的对象——与instanceof相反(参见Pitfall: crossing realms (frames or windows))。
数组原型方法
在接下来的章节中,数组原型方法按功能分组。对于每个子章节,我会提到这些方法是破坏性的(它们会改变被调用的数组)还是非破坏性的(它们不会修改它们的接收者;这样的方法通常会返回新的数组)。
添加和删除元素(破坏性)
本节中的所有方法都是破坏性的:
Array.prototype.shift()
删除索引为 0 的元素并返回它。随后元素的索引减 1:
> var arr = [ 'a', 'b' ];
> arr.shift()
'a'
> arr
[ 'b' ]
Array.prototype.unshift(elem1?, elem2?, ...)
将给定的元素添加到数组的开头。它返回新的长度:
> var arr = [ 'c', 'd' ];
> arr.unshift('a', 'b')
4
> arr
[ 'a', 'b', 'c', 'd' ]
Array.prototype.pop()
移除数组的最后一个元素并返回它:
> var arr = [ 'a', 'b' ];
> arr.pop()
'b'
> arr
[ 'a' ]
Array.prototype.push(elem1?, elem2?, ...)
将给定的元素添加到数组的末尾。它返回新的长度:
> var arr = [ 'a', 'b' ];
> arr.push('c', 'd')
4
> arr
[ 'a', 'b', 'c', 'd' ]
apply()(参见Function.prototype.apply(thisValue, argArray))使您能够破坏性地将数组arr2附加到另一个数组arr1:
> var arr1 = [ 'a', 'b' ];
> var arr2 = [ 'c', 'd' ];
> Array.prototype.push.apply(arr1, arr2)
4
> arr1
[ 'a', 'b', 'c', 'd' ]
Array.prototype.splice(start, deleteCount?, elem1?, elem2?, ...)
从start开始,删除deleteCount个元素并插入给定的元素。换句话说,您正在用elem1、elem2等替换位置start处的deleteCount个元素。该方法返回已被移除的元素:
> var arr = [ 'a', 'b', 'c', 'd' ];
> arr.splice(1, 2, 'X');
[ 'b', 'c' ]
> arr
[ 'a', 'X', 'd' ]
特殊的参数值:
-
start可以为负数,这种情况下它将被加到长度以确定起始索引。因此,-1指的是最后一个元素,依此类推。 -
deleteCount是可选的。如果省略(以及所有后续参数),则删除从索引start开始的所有元素及之后的所有元素。
在此示例中,我们删除最后两个索引后的所有元素:
> var arr = [ 'a', 'b', 'c', 'd' ];
> arr.splice(-2)
[ 'c', 'd' ]
> arr
[ 'a', 'b' ]
排序和颠倒元素(破坏性)
这些方法也是破坏性的:
Array.prototype.reverse()
颠倒数组中元素的顺序并返回对原始(修改后的)数组的引用:
> var arr = [ 'a', 'b', 'c' ];
> arr.reverse()
[ 'c', 'b', 'a' ]
> arr // reversing happened in place
[ 'c', 'b', 'a' ]
Array.prototype.sort(compareFunction?)
对数组进行排序并返回它:
> var arr = ['banana', 'apple', 'pear', 'orange'];
> arr.sort()
[ 'apple', 'banana', 'orange', 'pear' ]
> arr // sorting happened in place
[ 'apple', 'banana', 'orange', 'pear' ]
请记住,排序通过将值转换为字符串进行比较,这意味着数字不会按数字顺序排序:
> [-1, -20, 7, 50].sort()
[ -1, -20, 50, 7 ]
您可以通过提供可选参数compareFunction来解决这个问题,它控制排序的方式。它具有以下签名:
function compareFunction(a, b)
此函数比较a和b并返回:
-
如果
a小于b,则返回小于零的整数(例如,-1) -
如果
a等于b,则返回零 -
如果
a大于b,则返回大于零的整数(例如,1)
比较数字
对于数字,您可以简单地返回a-b,但这可能会导致数值溢出。为了防止这种情况发生,您需要更冗长的代码:
function compareCanonically(a, b) {
if (a < b) {
return -1;
} else if (a > b) {
return 1;
} else {
return 0;
}
}
我不喜欢嵌套的条件运算符。但在这种情况下,代码要简洁得多,我很想推荐它:
function compareCanonically(a, b) {
return return a < b ? -1 (a > b ? 1 : 0);
}
使用该函数:
> [-1, -20, 7, 50].sort(compareCanonically)
[ -20, -1, 7, 50 ]
比较字符串
对于字符串,您可以使用String.prototype.localeCompare(参见比较字符串):
> ['c', 'a', 'b'].sort(function (a,b) { return a.localeCompare(b) })
[ 'a', 'b', 'c' ]
比较对象
参数compareFunction对于排序对象也很有用:
var arr = [
{ name: 'Tarzan' },
{ name: 'Cheeta' },
{ name: 'Jane' } ];
function compareNames(a,b) {
return a.name.localeCompare(b.name);
}
使用compareNames作为比较函数,arr按name排序:
> arr.sort(compareNames)
[ { name: 'Cheeta' },
{ name: 'Jane' },
{ name: 'Tarzan' } ]
连接、切片、连接(非破坏性)
以下方法对数组执行各种非破坏性操作:
Array.prototype.concat(arr1?, arr2?, ...)
创建一个新数组,其中包含接收器的所有元素,后跟数组arr1的所有元素,依此类推。如果其中一个参数不是数组,则将其作为元素添加到结果中(例如,这里的第一个参数'c'):
> var arr = [ 'a', 'b' ];
> arr.concat('c', ['d', 'e'])
[ 'a', 'b', 'c', 'd', 'e' ]
调用concat()的数组不会改变:
> arr
[ 'a', 'b' ]
Array.prototype.slice(begin?, end?)
将数组元素复制到一个新数组中,从begin开始,直到end之前的元素:
> [ 'a', 'b', 'c', 'd' ].slice(1, 3)
[ 'b', 'c' ]
如果缺少end,则使用数组长度:
> [ 'a', 'b', 'c', 'd' ].slice(1)
[ 'b', 'c', 'd' ]
如果两个索引都缺失,则复制数组:
> [ 'a', 'b', 'c', 'd' ].slice()
[ 'a', 'b', 'c', 'd' ]
如果任一索引为负数,则将数组长度加上它。因此,-1指的是最后一个元素,依此类推:
> [ 'a', 'b', 'c', 'd' ].slice(1, -1)
[ 'b', 'c' ]
> [ 'a', 'b', 'c', 'd' ].slice(-2)
[ 'c', 'd' ]
Array.prototype.join(separator?)
通过对所有数组元素应用toString()并在结果之间放置separator字符串来创建一个字符串。如果省略separator,则使用,:
> [3, 4, 5].join('-')
'3-4-5'
> [3, 4, 5].join()
'3,4,5'
> [3, 4, 5].join('')
'345'
join()将undefined和null转换为空字符串:
> [undefined, null].join('#')
'#'
数组中的空位也会转换为空字符串:
> ['a',, 'b'].join('-')
'a--b'
搜索值(非破坏性)
以下方法在数组中搜索值:
Array.prototype.indexOf(searchValue, startIndex?)
从startIndex开始搜索数组中的searchValue。它返回第一次出现的索引,如果找不到则返回-1。如果startIndex为负数,则将数组长度加上它;如果缺少startIndex,则搜索整个数组:
> [ 3, 1, 17, 1, 4 ].indexOf(1)
1
> [ 3, 1, 17, 1, 4 ].indexOf(1, 2)
3
搜索时使用严格相等(参见相等运算符:===与==),这意味着indexOf()无法找到NaN:
> [NaN].indexOf(NaN)
-1
Array.prototype.lastIndexOf(searchElement, startIndex?)
在startIndex开始向后搜索searchElement,返回第一次出现的索引或-1(如果找不到)。如果startIndex为负数,则将数组长度加上它;如果缺失,则搜索整个数组。搜索时使用严格相等(参见相等运算符:===与==):
> [ 3, 1, 17, 1, 4 ].lastIndexOf(1)
3
> [ 3, 1, 17, 1, 4 ].lastIndexOf(1, -3)
1
迭代(非破坏性)
迭代方法使用一个函数来迭代数组。我区分三种迭代方法,它们都是非破坏性的:检查方法主要观察数组的内容;转换方法从接收器派生一个新数组;减少方法基于接收器的元素计算结果。
检查方法
本节中描述的每个方法都是这样的:
arr.examinationMethod(callback, thisValue?)
这样的方法需要以下参数:
-
callback是它的第一个参数,一个它调用的函数。根据检查方法的不同,回调返回布尔值或无返回值。它具有以下签名:function callback(element, index, array)
element是callback要处理的数组元素,index是元素的索引,array是调用examinationMethod的数组。
thisValue允许您配置callback内部的this的值。
现在是我刚刚描述的检查方法的签名:
Array.prototype.forEach(callback, thisValue?)
迭代数组的元素:
var arr = [ 'apple', 'pear', 'orange' ];
arr.forEach(function (elem) {
console.log(elem);
});
Array.prototype.every(callback, thisValue?)
如果回调对每个元素返回true,则返回true。一旦回调返回false,迭代就会停止。请注意,不返回值会导致隐式返回undefined,every()将其解释为false。every()的工作方式类似于全称量词(“对于所有”)。
这个例子检查数组中的每个数字是否都是偶数:
> function isEven(x) { return x % 2 === 0 }
> [ 2, 4, 6 ].every(isEven)
true
> [ 2, 3, 4 ].every(isEven)
false
如果数组为空,则结果为true(并且不调用callback):
> [].every(function () { throw new Error() })
true
Array.prototype.some(callback, thisValue?)
如果回调对至少一个元素返回true,则返回true。一旦回调返回true,迭代就会停止。请注意,不返回值会导致隐式返回undefined,some()将其解释为false。some()的工作方式类似于存在量词(“存在”)。
这个例子检查数组中是否有偶数:
> function isEven(x) { return x % 2 === 0 }
> [ 1, 3, 5 ].some(isEven)
false
> [ 1, 2, 3 ].some(isEven)
true
如果数组为空,则结果为false(并且不调用callback):
> [].some(function () { throw new Error() })
false
forEach()的一个潜在陷阱是它不支持break或类似的东西来提前中止循环。如果你需要这样做,可以使用some():
function breakAtEmptyString(strArr) {
strArr.some(function (elem) {
if (elem.length === 0) {
return true; // break
}
console.log(elem);
// implicit: return undefined (interpreted as false)
});
}
some()如果发生了中断,则返回true,否则返回false。这使您可以根据迭代是否成功完成(这在for循环中有点棘手)做出不同的反应。
转换方法
转换方法接受一个输入数组并产生一个输出数组,而回调控制输出的产生方式。回调的签名与检查方法相同:
function callback(element, index, array)
有两种转换方法:
Array.prototype.map(callback, thisValue?)
每个输出数组元素是将callback应用于输入元素的结果。例如:
> [ 1, 2, 3 ].map(function (x) { return 2 * x })
[ 2, 4, 6 ]
Array.prototype.filter(callback, thisValue?)
输出数组仅包含那些callback返回true的输入元素。例如:
> [ 1, 0, 3, 0 ].filter(function (x) { return x !== 0 })
[ 1, 3 ]
减少方法
对于减少,回调具有不同的签名:
function callback(previousValue, currentElement, currentIndex, array)
参数previousValue是回调先前返回的值。当首次调用回调时,有两种可能性(描述适用于Array.prototype.reduce();与reduceRight()的差异在括号中提到):
-
提供了明确的
initialValue。然后previousValue是initialValue,currentElement是第一个数组元素(reduceRight:最后一个数组元素)。 -
没有提供明确的
initialValue。然后previousValue是第一个数组元素,currentElement是第二个数组元素(reduceRight:最后一个数组元素和倒数第二个数组元素)。
有两种减少的方法:
Array.prototype.reduce(callback, initialValue?)
从左到右迭代,并像之前描述的那样调用回调。该方法的结果是回调返回的最后一个值。此示例计算所有数组元素的总和:
function add(prev, cur) {
return prev + cur;
}
console.log([10, 3, -1].reduce(add)); // 12
如果你在一个只有一个元素的数组上调用reduce,那么该元素会被返回:
> [7].reduce(add)
7
如果你在一个空数组上调用reduce,你必须指定initialValue,否则你会得到一个异常:
> [].reduce(add)
TypeError: Reduce of empty array with no initial value
> [].reduce(add, 123)
123
Array.prototype.reduceRight(callback, initialValue?)
与reduce()相同,但从右到左迭代。
注意
在许多函数式编程语言中,reduce被称为fold或foldl(左折叠),reduceRight被称为foldr(右折叠)。
看reduce方法的另一种方式是它实现了一个 n 元运算符OP:
OP[1≤i≤n] x[i]
通过一系列二元运算符op2的应用:
(…(x[1] op2 x[2]) op2 …) op2 x[n]
这就是前面代码示例中发生的事情:我们通过 JavaScript 的二进制加法运算符实现了一个数组的 n 元求和运算符。
例如,让我们通过以下函数来检查两个迭代方向:
function printArgs(prev, cur, i) {
console.log('prev:'+prev+', cur:'+cur+', i:'+i);
return prev + cur;
}
如预期的那样,reduce()从左到右迭代:
> ['a', 'b', 'c'].reduce(printArgs)
prev:a, cur:b, i:1
prev:ab, cur:c, i:2
'abc'
> ['a', 'b', 'c'].reduce(printArgs, 'x')
prev:x, cur:a, i:0
prev:xa, cur:b, i:1
prev:xab, cur:c, i:2
'xabc'
reduceRight()从右到左迭代:
> ['a', 'b', 'c'].reduceRight(printArgs)
prev:c, cur:b, i:1
prev:cb, cur:a, i:0
'cba'
> ['a', 'b', 'c'].reduceRight(printArgs, 'x')
prev:x, cur:c, i:2
prev:xc, cur:b, i:1
prev:xcb, cur:a, i:0
'xcba'
陷阱:类数组对象
JavaScript 中的一些对象看起来像数组,但它们并不是数组。这通常意味着它们具有索引访问和length属性,但没有数组方法。例子包括特殊变量arguments,DOM 节点列表和字符串。类数组对象和通用方法提供了处理类数组对象的提示。
最佳实践:迭代数组
要迭代一个数组arr,你有两个选择:
-
一个简单的
for循环(参见for):for (var i=0; i<arr.length; i++) { console.log(arr[i]); } -
数组迭代方法之一(参见迭代(非破坏性))。例如,
forEach():arr.forEach(function (elem) { console.log(elem); });
不要使用for-in循环(参见for-in)来迭代数组。它遍历索引,而不是值。在这样做的同时,它包括正常属性的键,包括继承的属性。
第十九章:正则表达式
原文:19. Regular Expressions
译者:飞龙
协议:CC BY-NC-SA 4.0
本章概述了正则表达式的 JavaScript API。它假定你对它们的工作原理有一定了解。如果你不了解,网上有很多好的教程。其中两个例子是:
-
Regular-Expressions.info by Jan Goyvaerts
-
Cody Lindley 的 JavaScript 正则表达式启示
正则表达式语法
这里使用的术语与 ECMAScript 规范中的语法非常接近。我有时会偏离以使事情更容易理解。
原子:一般
一般原子的语法如下:
特殊字符
以下所有字符都具有特殊含义:
\ ^ $ . * + ? ( ) [ ] { } |
你可以通过在前面加上反斜杠来转义它们。例如:
> /^(ab)$/.test('(ab)')
false
> /^\(ab\)$/.test('(ab)')
true
其他特殊字符包括:
-
在字符类
[...]中:- -
在以问号
(?...)开头的组内:: = ! < >
尖括号仅由 XRegExp 库(参见第三十章)使用,用于命名组。
模式字符
除了前面提到的特殊字符之外,所有字符都与它们自己匹配。
.(点)
匹配任何 JavaScript 字符(UTF-16 代码单元),除了行终止符(换行符、回车符等)。要真正匹配任何字符,请使用[\s\S]。例如:
> /./.test('\n')
false
> /[\s\S]/.test('\n')
true
字符转义(匹配单个字符)
-
特定的控制字符包括
\f(换页符)、\n(换行符、新行)、\r(回车符)、\t(水平制表符)和\v(垂直制表符)。 -
\0匹配 NUL 字符(\u0000)。 -
任何控制字符:
\cA–\cZ。 -
Unicode 字符转义:
\u0000–\xFFFF(Unicode 代码单元;参见第二十四章)。 -
十六进制字符转义:
\x00–\xFF。
字符类转义(匹配一组字符中的一个)
-
数字:
\d匹配任何数字(与[0-9]相同);\D匹配任何非数字(与[^0-9]相同)。 -
字母数字字符:
\w匹配任何拉丁字母数字字符加下划线(与[A-Za-z0-9_]相同);\W匹配所有未被\w匹配的字符。 -
空白:
\s匹配空白字符(空格、制表符、换行符、回车符、换页符、所有 Unicode 空格等);\S匹配所有非空白字符。
原子:字符类
字符类的语法如下:
-
[«charSpecs»]匹配至少一个charSpecs中的任何一个的单个字符。 -
[^«charSpecs»]匹配任何不匹配charSpecs中任何一个的单个字符。
以下构造都是字符规范:
-
源字符匹配它们自己。大多数字符都是源字符(甚至许多在其他地方是特殊的字符)。只有三个字符不是:
\ ] -
像往常一样,您可以通过反斜杠进行转义。如果要匹配破折号而不进行转义,它必须是方括号打开后的第一个字符,或者是范围的右侧,如下所述。
-
类转义:允许使用先前列出的任何字符转义和字符类转义。还有一个额外的转义:
-
退格(
\b):在字符类之外,\b匹配单词边界。在字符类内,它匹配控制字符退格。 -
范围包括源字符或类转义,后跟破折号(
-),后跟源字符或类转义。
为了演示使用字符类,此示例解析了按照 ISO 8601 标准格式化的日期:
function parseIsoDate(str) {
var match = /^([0-9]{4})-([0-9]{2})-([0-9]{2})$/.exec(str);
// Other ways of writing the regular expression:
// /^([0-9][0-9][0-9][0-9])-([0-9][0-9])-([0-9][0-9])$/
// /^(\d\d\d\d)-(\d\d)-(\d\d)$/
if (!match) {
throw new Error('Not an ISO date: '+str);
}
console.log('Year: ' + match[1]);
console.log('Month: ' + match[2]);
console.log('Day: ' + match[3]);
}
以下是交互:
> parseIsoDate('2001-12-24')
Year: 2001
Month: 12
Day: 24
原子:组
组的语法如下:
-
(«pattern»)是一个捕获组。由pattern匹配的任何内容都可以通过反向引用或作为匹配操作的结果来访问。 -
(?:«pattern»)是一个非捕获组。pattern仍然与输入匹配,但不保存为捕获。因此,该组没有您可以引用的编号(例如,通过反向引用)。
\1、\2等被称为反向引用;它们指回先前匹配的组。反斜杠后面的数字可以是大于或等于 1 的任何整数,但第一个数字不能是 0。
在此示例中,反向引用保证了破��号之前和之后的 a 的数量相同:
> /^(a+)-\1$/.test('a-a')
true
> /^(a+)-\1$/.test('aaa-aaa')
true
> /^(a+)-\1$/.test('aa-a')
false
此示例使用反向引用来匹配 HTML 标签(显然,通常应使用适当的解析器来处理 HTML):
> var tagName = /<([^>]+)>[^<]*<\/\1>/;
> tagName.exec('bold')[1]
'b'
> tagName.exec('text')[1]
'strong'
> tagName.exec('text')
null
量词
任何原子(包括字符类和组)都可以后跟一个量词:
-
?表示匹配零次或一次。 -
*表示匹配零次或多次。 -
+表示匹配一次或多次。 -
{n}表示精确匹配n次。 -
{n,}表示匹配n次或更多次。 -
{n,m}表示至少匹配n次,最多匹配m次。
默认情况下,量词是贪婪的;也就是说,它们尽可能多地匹配。您可以通过在任何前述量词(包括大括号中的范围)后加上问号(?)来获得勉强匹配(尽可能少)。例如:
> ' '.match(/^<(.*)>/)[1] // greedy
'a>
> ' '.match(/^<(.*?)>/)[1] // reluctant
'a'
因此,.*?是一个用于匹配直到下一个原子出现的有用模式。例如,以下是刚刚显示的 HTML 标签的正则表达式的更紧凑版本(使用[^<]*代替.*?):
/<(.+?)>.*?<\/\1>/
断言
断言,如下列表所示,是关于输入中当前位置的检查:
^ |
仅在输入的开头匹配。 |
|---|---|
$ |
仅在输入的末尾匹配。 |
\b |
仅在单词边界处匹配。不要与[\b]混淆,它匹配退格。 |
\B |
仅当不在单词边界时匹配。 |
(?=«pattern») |
正向预查:仅当“模式”匹配接下来的内容时才匹配。“模式”仅用于向前查看,否则会被忽略。 |
(?!«pattern») |
负向预查:仅当“模式”不匹配接下来的内容时才匹配。“模式”仅用于向前查看,否则会被忽略。 |
此示例通过\b匹配单词边界:
> /\bell\b/.test('hello')
false
> /\bell\b/.test('ello')
false
> /\bell\b/.test('ell')
true
此示例通过\B匹配单词内部:
> /\Bell\B/.test('ell')
false
> /\Bell\B/.test('hell')
false
> /\Bell\B/.test('hello')
true
注意
不支持后行断言。手动实现后行断言解释了如何手动实现它。
分歧
分歧运算符(|)分隔两个选择;任一选择必须匹配分歧才能匹配。这些选择是原子(可选包括量词)。
该运算符的绑定非常弱,因此您必须小心,以确保选择不会延伸太远。例如,以下正则表达式匹配所有以'aa'开头或以'bb'结尾的字符串:
> /^aa|bb$/.test('aaxx')
true
> /^aa|bb$/.test('xxbb')
true
换句话说,分歧比甚至^和$都要弱,两个选择是^aa和bb$。如果要匹配两个字符串'aa'和'bb',则需要括号:
/^(aa|bb)$/
同样,如果要匹配字符串'aab'和'abb':
/^a(a|b)b$/
Unicode 和正则表达式
JavaScript 的正则表达式对 Unicode 的支持非常有限。特别是当涉及到星际飞船中的代码点时,您必须小心。第二十四章解释了详细信息。
创建正则表达式
您可以通过文字或构造函数创建正则表达式,并通过标志配置其工作方式。
文字与构造函数
有两种方法可以创建正则表达式:您可以使用文字或构造函数RegExp:
文字:/xyz/i:在加载时编译
构造函数(第二个参数是可选的):new RegExp('xyz','i'):在运行时编译
文字和构造函数在编译时不同:
-
文字在加载时编译。在评估时,以下代码将引发异常:
function foo() { /[/; } -
构造函数在调用时编译正则表达式。以下代码不会引发异常,但调用
foo()会:function foo() { new RegExp('['); }
因此,通常应使用文字,但如果要动态组装正则表达式,则需要构造函数。
标志
标志是正则表达式文字的后缀和正则表达式构造函数的参数;它们修改正则表达式的匹配行为。存在以下标志:
| 短名称 | 长名称 | 描述 |
|---|---|---|
g |
全局 | 给定的正则表达式多次匹配。影响几种方法,特别是replace()。 |
i |
忽略大小写 | 在尝试匹配给定的正则表达式时忽略大小写。 |
m |
多行模式 | 在多行模式下,开始运算符^和结束运算符$匹配每一行,而不是完整的输入字符串。 |
短名称用于文字前缀和构造函数参数(请参见下一节中的示例)。长名称用于正则表达式的属性,指示在创建期间设置了哪些标志。
正则表达式的实例属性
正则表达式具有以下实例属性:
-
标志:表示设置了哪些标志的布尔值:
-
全局:标志
/g设置了吗? -
忽略大小写:标志
/i设置了吗? -
多行:标志
/m设置了吗? -
用于多次匹配的数据(设置了
/g标志): -
lastIndex是下次继续搜索的索引。
以下是访问标志的实例属性的示例:
> var regex = /abc/i;
> regex.ignoreCase
true
> regex.multiline
false
创建正则表达式的示例
在这个例子中,我们首先使用文字创建相同的正则表达式,然后使用构造函数,并使用test()方法来确定它是否匹配一个字符串:
> /abc/.test('ABC')
false
> new RegExp('abc').test('ABC')
false
在这个例子中,我们创建一个忽略大小写的正则表达式(标志/i):
> /abc/i.test('ABC')
true
> new RegExp('abc', 'i').test('ABC')
true
RegExp.prototype.test:是否有匹配?
test()方法检查正则表达式regex是否匹配字符串str:
regex.test(str)
test()的操作方式取决于标志/g是否设置。
如果标志/g未设置,则该方法检查str中是否有匹配。例如:
> var str = '_x_x';
> /x/.test(str)
true
> /a/.test(str)
false
如果设置了标志/g,则该方法返回true,直到str中regex的匹配次数。属性regex.lastIndex包含最后匹配后的索引:
> var regex = /x/g;
> regex.lastIndex
0
> regex.test(str)
true
> regex.lastIndex
2
> regex.test(str)
true
> regex.lastIndex
4
> regex.test(str)
false
String.prototype.search:有匹配的索引吗?
search()方法在str中查找与regex匹配的内容:
str.search(regex)
如果有匹配,返回找到匹配的索引。否则,结果为-1。regex的global和lastIndex属性在执行搜索时被忽略(lastIndex不会改变)。
例如:
> 'abba'.search(/b/)
1
> 'abba'.search(/x/)
-1
如果search()的参数不是正则表达式,则会转换为正则表达式:
> 'aaab'.search('^a+b+$')
0
RegExp.prototype.exec:捕获组
以下方法调用在匹配regex和str时捕获组:
var matchData = regex.exec(str);
如果没有匹配,matchData为null。否则,matchData是一个匹配结果,一个带有两个额外属性的数组:
数组元素
-
元素 0 是完整正则表达式的匹配(如果愿意的话,是第 0 组)。
-
元素n > 1 是第n组的捕获。
属性
-
input是完整的输入字符串。 -
index是找到匹配的索引。
第一个匹配(标志/g 未设置)
如果标志/g未设置,则只返回第一个匹配:
> var regex = /a(b+)/;
> regex.exec('_abbb_ab_')
[ 'abbb',
'bbb',
index: 1,
input: '_abbb_ab_' ]
> regex.lastIndex
0
所有匹配(标志/g 设置)
如果设置了标志/g,则如果反复调用exec(),所有匹配都会被返回。返回值null表示没有更多的匹配。属性lastIndex指示下次匹配将继续的位置:
> var regex = /a(b+)/g;
> var str = '_abbb_ab_';
> regex.exec(str)
[ 'abbb',
'bbb',
index: 1,
input: '_abbb_ab_' ]
> regex.lastIndex
6
> regex.exec(str)
[ 'ab',
'b',
index: 7,
input: '_abbb_ab_' ]
> regex.lastIndex
10
> regex.exec(str)
null
在这里我们循环匹配:
var regex = /a(b+)/g;
var str = '_abbb_ab_';
var match;
while (match = regex.exec(str)) {
console.log(match[1]);
}
我们得到以下输出:
bbb
b
String.prototype.match:捕获组或返回所有匹配的子字符串
以下方法调用匹配regex和str:
var matchData = str.match(regex);
如果regex的标志/g未设置,此方法的工作方式类似于RegExp.prototype.exec():
> 'abba'.match(/a/)
[ 'a', index: 0, input: 'abba' ]
如果设置了标志,则该方法返回一个包含str中所有匹配子字符串的数组(即每次匹配的第 0 组),如果没有匹配则返回null:
> 'abba'.match(/a/g)
[ 'a', 'a' ]
> 'abba'.match(/x/g)
null
String.prototype.replace:搜索和替换
replace()方法搜索字符串str,找到与search匹配的内容,并用replacement替换它们:
str.replace(search, replacement)
有几种方式可以指定这两个参数:
search
可以是字符串或正则表达式:
-
字符串:在输入字符串中直接查找。请注意,只有第一次出现的字符串会被替换。如果要替换多个出现,必须使用带有
/g标志的正则表达式。这是一个意外和一个主要的陷阱。 -
正则表达式:与输入字符串匹配。警告:使用
global标志,否则只会尝试一次匹配正则表达式。
replacement
可以是字符串或函数:
-
字符串:描述如何替换已找到的内容。
-
功能:通过参数提供匹配信息来计算替换。
替换是一个字符串
如果replacement是一个字符串,它的内容将被直接使用来替换匹配。唯一的例外是特殊字符美元符号($),它启动所谓的替换指令:
-
组:
$n插入匹配中的第 n 组。n必须至少为 1($0没有特殊含义)。 -
匹配的子字符串:
-
`$``(反引号)插入匹配前的文本。
-
$&插入完整的匹配。 -
$'(撇号)插入匹配后的文本。 -
$$插入一个单独的$。
这个例子涉及匹配的子字符串及其前缀和后缀:
> 'axb cxd'.replace(/x/g, "[$`,$&,$']")
'a[a,x,b cxd]b c[axb c,x,d]d'
这个例子涉及到一个组:
> '"foo" and "bar"'.replace(/"(.*?)"/g, '#$1#')
'#foo# and #bar#'
替换是一个函数
如果replacement是一个函数,它会计算要替换匹配的字符串。此函数具有以下签名:
function (completeMatch, group_1, ..., group_n, offset, inputStr)
completeMatch与以前的$&相同,offset指示找到匹配的位置,inputStr是正在匹配的内容。因此,您可以使用特殊变量arguments来访问组(通过arguments[1]访问第 1 组,依此类推)。例如:
> function replaceFunc(match) { return 2 * match }
> '3 apples and 5 oranges'.replace(/[0-9]+/g, replaceFunc)
'6 apples and 10 oranges'
标志/g的问题
设置了/g标志的正则表达式如果必须多次调用才能返回所有结果,则存在问题。这适用于两种方法:
-
RegExp.prototype.test() -
RegExp.prototype.exec()
然后 JavaScript 滥用正则表达式作为迭代器,作为结果序列的指针。这会导致问题:
问题 1:无法内联/g正则表达式
例如:
// Don’t do that:
var count = 0;
while (/a/g.test('babaa')) count++;
前面的循环是无限的,因为每次循环迭代都会创建一个新的正则表达式,从而重新开始结果的迭代。因此,必须重写代码:
var count = 0;
var regex = /a/g;
while (regex.test('babaa')) count++;
这是另一个例子:
// Don’t do that:
function extractQuoted(str) {
var match;
var result = [];
while ((match = /"(.*?)"/g.exec(str)) != null) {
result.push(match[1]);
}
return result;
}
调用前面的函数将再次导致无限循环。正确的版本是(为什么lastIndex设置为 0 很快就会解释):
var QUOTE_REGEX = /"(.*?)"/g;
function extractQuoted(str) {
QUOTE_REGEX.lastIndex = 0;
var match;
var result = [];
while ((match = QUOTE_REGEX.exec(str)) != null) {
result.push(match[1]);
}
return result;
}
使用该函数:
> extractQuoted('"hello", "world"')
[ 'hello', 'world' ]
提示
最好的做法是不要内联(然后您可以给正则表达式起一个描述性的名称)。但是您必须意识到您不能这样做,即使是在快速的 hack 中也不行。
问题 2:/g正则表达式作为参数
调用test()和exec()多次的代码在作为参数传递给它的正则表达式时必须小心。它的标志/g必须激活,并且为了安全起见,它的lastIndex应该设置为零(下一个示例中提供了解释)。
问题 3:共享的/g正则表达式(例如,常量)
每当引用尚未新创建的正则表达式时,您应该在将其用作迭代器之前将其lastIndex属性设置为零(下一个示例中提供了解释)。由于迭代取决于lastIndex,因此这样的正则表达式不能同时在多个迭代中使用。
以下示例说明了问题 2。这是一个简单的实现函数,用于计算字符串str中正则表达式regex的匹配次数:
// Naive implementation
function countOccurrences(regex, str) {
var count = 0;
while (regex.test(str)) count++;
return count;
}
以下是使用此函数的示例:
> countOccurrences(/x/g, '_x_x')
2
第一个问题是,如果正则表达式的/g标志未设置,此函数将进入无限循环。例如:
countOccurrences(/x/, '_x_x') // never terminates
第二个问题是,如果regex.lastIndex不是 0,函数将无法正确工作,因为该属性指示从哪里开始搜索。例如:
> var regex = /x/g;
> regex.lastIndex = 2;
> countOccurrences(regex, '_x_x')
1
以下实现解决了两个问题:
function countOccurrences(regex, str) {
if (! regex.global) {
throw new Error('Please set flag /g of regex');
}
var origLastIndex = regex.lastIndex; // store
regex.lastIndex = 0;
var count = 0;
while (regex.test(str)) count++;
regex.lastIndex = origLastIndex; // restore
return count;
}
一个更简单的替代方法是使用match():
function countOccurrences(regex, str) {
if (! regex.global) {
throw new Error('Please set flag /g of regex');
}
return (str.match(regex) || []).length;
}
有一个可能的陷阱:如果设置了/g标志并且没有匹配项,str.match()将返回null。在前面的代码中,我们通过使用[]来避免这种陷阱,如果match()的结果不是真值。
提示和技巧
本节提供了一些在 JavaScript 中使用正则表达式的技巧和窍门。
引用文本
有时,当手动组装正则表达式时,您希望逐字使用给定的字符串。这意味着不能解释任何特殊字符(例如,*,[)-所有这些字符都需要转义。JavaScript 没有内置的方法来进行这种引用,但是您可以编写自己的函数quoteText,它将按以下方式工作:
> console.log(quoteText('*All* (most?) aspects.'))
\*All\* \(most\?\) aspects\.
如果您需要进行多次搜索和替换,则此函数特别方便。然后要搜索的值必须是设置了global标志的正则表达式。使用quoteText(),您可以使用任意字符串。该函数如下所示:
function quoteText(text) {
return text.replace(/[\\^$.*+?()[\]{}|=!<>:-]/g, '\\$&');
}
所有特殊字符都被转义,因为您可能希望在括号或方括号内引用多个字符。
陷阱:没有断言(例如,^,$),正则表达式可以在任何地方找到
如果您不使用^和$等断言,大多数正则表达式方法会在任何地方找到模式。例如:
> /aa/.test('xaay')
true
> /^aa$/.test('xaay')
false
匹配一切或什么都不匹配
这是一个罕见的用例,但有时您需要一个正则表达式,它匹配一切或什么都不匹配。例如,一个函数可能有一个用于过滤的正则表达式参数。如果该参数缺失,您可以给它一个默认值,一个匹配一切的正则表达式。
匹配一切
空正则表达式匹配一切。我们可以基于该正则表达式创建一个RegExp的实例,就像这样:
> new RegExp('').test('dfadsfdsa')
true
> new RegExp('').test('')
true
但是,空正则表达式文字将是//,这在 JavaScript 中被解释为注释。因此,以下是通过文字获得的最接近的:/(?:)/(空的非捕获组)。该组匹配一切,同时不捕获任何内容,这个组不会影响exec()返回的结果。即使 JavaScript 本身在显示空正则表达式时也使用前面的表示:
> new RegExp('')
/(?:)/
匹配什么都不匹配
空正则表达式具有一个反义词——匹配什么都不匹配的正则表达式:
> var never = /.^/;
> never.test('abc')
false
> never.test('')
false
手动实现后行断言
后行断言是一种断言。与先行断言类似,模式用于检查输入中当前位置的某些内容,但在其他情况下被忽略。与先行断言相反,模式的匹配必须结束在当前位置(而不是从当前位置开始)。
以下函数将字符串'NAME'的每个出现替换为参数name的值,但前提是该出现不是由引号引导的。我们通过“手动”检查当前匹配之前的字符来处理引号:
function insertName(str, name) {
return str.replace(
/NAME/g,
function (completeMatch, offset) {
if (offset === 0 ||
(offset > 0 && str[offset-1] !== '"')) {
return name;
} else {
return completeMatch;
}
}
);
}
> insertName('NAME "NAME"', 'Jane')
'Jane "NAME"'
> insertName('"NAME" NAME', 'Jane')
'"NAME" Jane'
另一种方法是在正则表达式中包含可能转义的字符。然后,您必须临时向您正在搜索的字符串添加前缀;否则,您将错过该字符串开头的匹配:
function insertName(str, name) {
var tmpPrefix = ' ';
str = tmpPrefix + str;
str = str.replace(
/([^"])NAME/g,
function (completeMatch, prefix) {
return prefix + name;
}
);
return str.slice(tmpPrefix.length); // remove tmpPrefix
}
正则表达式速查表
原子(参见原子:一般):
-
.(点)匹配除行终止符(例如换行符)之外的所有内容。使用[\s\S]来真正匹配一切。 -
字符类转义:
-
\d匹配数字([0-9]);\D匹配非数字([^0-9])。 -
\w匹配拉丁字母数字字符加下划线([A-Za-z0-9_]);\W匹配所有其他字符。 -
\s匹配所有空白字符(空格、制表符、换行符等);\S匹配所有非空白字符。 -
字符类(字符集):
[...]和[^...] -
源字符:
[abc](除\ ] -之外的所有字符都与它们自身匹配) -
字符类转义(参见前文):
[\d\w] -
范围:
[A-Za-z0-9] -
组:
-
捕获组:
(...);反向引用:\1 -
非捕获组:
(?:...)
量词(参见量词):
-
贪婪:
-
? * + -
{n} {n,} {n,m} -
勉强:在任何贪婪量词后面加上
?。
断言(参见断言):
-
输入的开始,输入的结束:
^ $ -
在词边界处,不在词边界处:
\b \B -
正向先行断言:
(?=...)(模式必须紧跟其后,但在其他情况下被忽略) -
负向先行断言:
(?!...)(模式不能紧跟其后,但在其他情况下被忽略)
分支:|
创建正则表达式(参见创建正则表达式):
-
字面量:
/xyz/i(在加载时编译) -
构造函数:
new RegExp('xzy', 'i')(在运行时编译)
标志(参见标志):
-
全局:
/g(影响几种正则表达式方法) -
ignoreCase:
/i -
多行:
/m(^和$按行匹配,而不是完整的输入)
方法:
-
regex.test(str): 是否有匹配(参见RegExp.prototype.test: 是否有匹配?)? -
/g未设置:是否有匹配? -
/g被设置:返回与匹配次数相同的true。 -
str.search(regex): 有匹配项的索引是什么(参见String.prototype.search: At What Index Is There a Match?)? -
regex.exec(str): 捕获组(参见章节RegExp.prototype.exec: Capture Groups)? -
/g未设置:仅捕获第一个匹配项的组(仅调用一次) -
/g已设置:捕获所有匹配项的组(重复调用;如果没有更多匹配项,则返回null) -
str.match(regex): 捕获组或返回所有匹配的子字符串(参见String.prototype.match: Capture Groups or Return All Matching Substrings) -
/g未设置:捕获组 -
/g已设置:返回数组中所有匹配的子字符串 -
str.replace(search, replacement): 搜索和替换(参见String.prototype.replace: Search and Replace) -
search:字符串或正则表达式(使用后者,设置/g!) -
replacement:字符串(带有$1等)或函数(arguments[1]是第 1 组等),返回一个字符串
有关使用标志/g的提示,请参阅Problems with the Flag /g。
致谢
Mathias Bynens(@mathias)和 Juan Ignacio Dopazo(@juandopazo)建议使用match()和test()来计算出现次数,Šime Vidas(@simevidas)警告我在没有匹配项时要小心使用match()。全局标志导致无限循环的陷阱来自Andrea Giammarchi 的演讲(@webreflection)。Claude Pache 告诉我在quoteText()中转义更多字符。
第二十章:日期
原文:20. Dates
译者:飞龙
协议:CC BY-NC-SA 4.0
JavaScript 的Date构造函数有助于解析、管理和显示日期。本章描述了它的工作原理。
日期 API 使用术语UTC(协调世界时)。在大多数情况下,UTC 是 GMT(格林尼治标准时间)的同义词,大致意味着伦敦,英国的时区。
日期构造函数
有四种调用Date构造函数的方法:
new Date(year, month, date?, hours?, minutes?, seconds?, milliseconds?)
从给定数据构造一个新的日期。时间相对于当前时区进行解释。Date.UTC()提供了类似的功能,但是相对于 UTC。参数具有以下范围:
-
year:对于 0 ≤year≤ 99,将添加 1900。 -
month:0-11(0 是一月,1 是二月,依此类推) -
date:1-31 -
hours:0-23 -
minutes:0-59 -
seconds:0-59 -
milliseconds:0-999
以下是一些示例:
> new Date(2001, 1, 27, 14, 55)
Date {Tue Feb 27 2001 14:55:00 GMT+0100 (CET)}
> new Date(01, 1, 27, 14, 55)
Date {Wed Feb 27 1901 14:55:00 GMT+0100 (CET)}
顺便说一句,JavaScript 继承了略微奇怪的约定,将 0 解释为一月,1 解释为二月,依此类推,这一点来自 Java。
new Date(dateTimeStr)
这是一个将日期时间字符串转换为数字的过程,然后调用new Date(number)。日期时间格式解释了日期时间格式。例如:
> new Date('2004-08-29')
Date {Sun Aug 29 2004 02:00:00 GMT+0200 (CEST)}
非法的日期时间字符串导致将NaN传递给new Date(number)。
new Date(timeValue)
根据自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数创建日期。例如:
> new Date(0)
Date {Thu Jan 01 1970 01:00:00 GMT+0100 (CET)}
这个构造函数的反函数是getTime()方法,它返回毫秒数:
> new Date(123).getTime()
123
您可以使用NaN作为参数,这将产生Date的一个特殊实例,即“无效日期”:
> var d = new Date(NaN);
> d.toString()
'Invalid Date'
> d.toJSON()
null
> d.getTime()
NaN
> d.getYear()
NaN
new Date()
创建当前日期和时间的对象;它与new Date(Date.now())的作用相同。
日期构造函数方法
构造函数Date有以下方法:
Date.now()
以毫秒为单位返回当前日期和时间(自 1970 年 1 月 1 日 00:00:00 UTC 起)。它产生与new Date().getTime()相同的结果。
Date.parse(dateTimeString)
将 dateTimeString 转换为自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数。日期时间格式解释了 dateTimeString 的格式。结果可用于调用 new Date(number)。以下是一些示例:
> Date.parse('1970-01-01')
0
> Date.parse('1970-01-02')
86400000
如果无法解析字符串,此方法将返回 NaN:
> Date.parse('abc')
NaN
Date.UTC(year, month, date?, hours?, minutes?, seconds?, milliseconds?)
将给定数据转换为自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数。它与具有相同参数的 Date 构造函数有两种不同之处:
-
它返回一个数字,而不是一个新的日期对象。
-
它将参数解释为世界协调时间,而不是本地时间。
日期原型方法
本节涵盖了 Date.prototype 的方法。
时间单位的获取器和设置器
时间单位的获取器和设置器可使用以下签名:
-
本地时间:
-
Date.prototype.get«Unit»()返回根据本地时间的Unit。 -
Date.prototype.set«Unit»(number)根据本地时间设置Unit。 -
世界协调时间:
-
Date.prototype.getUTC«Unit»()返回根据世界协调时间的Unit。 -
Date.prototype.setUTC«Unit»(number)根据世界协调时间设置Unit。
Unit 是以下单词之一:
-
FullYear:通常是四位数 -
Month:月份(0-11) -
Date:月份中的某一天(1-31) -
Day(仅获取器):星期几(0-6);0 代表星期日 -
Hours:小时(0-23) -
Minutes:分钟(0-59) -
Seconds:秒(0-59) -
Milliseconds:毫秒(0-999)
例如:
> var d = new Date('1968-11-25');
Date {Mon Nov 25 1968 01:00:00 GMT+0100 (CET)}
> d.getDate()
25
> d.getDay()
1
各种获取器和设置器
以下方法使您能够获取和设置自 1970 年 1 月 1 日以来的毫秒数以及更多内容:
-
Date.prototype.getTime()返回自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数(参见时间值:日期作为自 1970-01-01 以来的毫秒数)。 -
Date.prototype.setTime(timeValue)根据自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数设置日期(参见时间值:日期作为自 1970-01-01 以来的毫秒数)。 -
Date.prototype.valueOf()与getTime()相同。当日期转换为数字时,将调用此方法。 -
Date.prototype.getTimezoneOffset()返回本地时间和世界协调时间之间的差异(以分钟为单位)。
Year 单位已被弃用,推荐使用 FullYear:
-
Date.prototype.getYear()已被弃用;请改用getFullYear()。 -
Date.prototype.setYear(number)已被弃用;请改用setFullYear()。
将日期转换为字符串
请注意,转换为字符串高度依赖于实现。以下日期用于计算以下示例中的输出(在撰写本书时,Firefox 的支持最完整):
new Date(2001,9,30, 17,43,7, 856);
时间(可读)
-
Date.prototype.toTimeString():17:43:07 GMT+0100 (CET)
以当前时区的时间显示。
-
Date.prototype.toLocaleTimeString():17:43:07
以特定于区域的格式显示的时间。此方法由 ECMAScript 国际化 API(参见ECMAScript 国际化 API)提供,并且如果没有它,就没有太多意义。
日期(可读)
-
Date.prototype.toDateString():Tue Oct 30 2001
日期。
-
Date.prototype.toLocaleDateString():10/30/2001
以特定于区域的格式显示的日期。此方法由 ECMAScript 国际化 API(参见ECMAScript 国际化 API)提供,并且如果没有它,就没有太多意义。
日期和时间(可读)
-
Date.prototype.toString():Tue Oct 30 2001 17:43:07 GMT+0100 (CET)
日期和时间,以当前时区的时间。对于没有毫秒的任何 Date 实例(即秒数已满),以下表达式为真:
Date.parse(d.toString()) === d.valueOf()
```
+ `Date.prototype.toLocaleString()`:
```js
Tue Oct 30 17:43:07 2001
```
以区域特定格式的日期和时间。此方法由 ECMAScript 国际化 API 提供(请参见[ECMAScript 国际化 API](ch30.html#i18n_api "ECMAScript 国际化 API")),如果没有它,这个方法就没有太多意义。
+ `Date.prototype.toUTCString()`:
```js
Tue, 30 Oct 2001 16:43:07 GMT
```
日期和时间,使用 UTC。
+ `Date.prototype.toGMTString()`:
已弃用;请改用`toUTCString()`。
日期和时间(机器可读)
+ `Date.prototype.toISOString()`:
```js
2001-10-30T16:43:07.856Z
```
所有内部属性都显示在返回的字符串中。格式符合[日期时间格式](ch20.html#date_time_formats "日期时间格式");时区始终为`Z`。
+ `Date.prototype.toJSON()`:
此方法内部调用`toISOString()`。它被`JSON.stringify()`(参见[JSON.stringify(value, replacer?, space?)](ch22.html#JSON.stringify "JSON.stringify(value, replacer?, space?)"))用于将日期对象转换为 JSON 字符串。
## 日期时间格式
本节描述了以字符串形式表示时间点的格式。有许多方法可以这样做:仅指示日期,包括一天中的时间,省略时区,指定时区等。在支持日期时间格式方面,ECMAScript 5 紧密遵循标准 ISO 8601 扩展格式。JavaScript 引擎相对完全地实现了 ECMAScript 规范,但仍然存在一些变化,因此您必须保持警惕。
最长的日期时间格式是:
```js
YYYY-MM-DDTHH:mm:ss.sssZ
每个部分代表日期时间数据的几个十进制数字。例如,YYYY表示格式以四位数年份开头。以下各小节解释了每个部分的含义。这些格式与以下方法相关:
-
Date.parse()可以解析这些格式。 -
new Date()可以解析这些格式。 -
Date.prototype.toISOString()创建了上述“完整”格式的字符串:> new Date().toISOString() '2014-09-12T23:05:07.414Z'
日期格式(无时间)
以下日期格式可用:
YYYY-MM-DD
YYYY-MM
YYYY
它们包括以下部分:
-
YYYY指的是年份(公历)。 -
MM指的是月份,从 01 到 12。 -
DD指的是日期,从 01 到 31。
例如:
> new Date('2001-02-22')
Date {Thu Feb 22 2001 01:00:00 GMT+0100 (CET)}
时间格式(无日期)
以下时间格式可用。如您所见,时区信息Z是可选的:
THH:mm:ss.sss
THH:mm:ss.sssZ
THH:mm:ss
THH:mm:ssZ
THH:mm
THH:mmZ
它们包括以下部分:
-
T是格式时间部分的前缀(字面上的T,而不是数字)。 -
HH指的是小时,从 00 到 23。您可以使用 24 作为HH的值(指的是第二天的 00 小时),但是接下来的所有部分都必须为 0。 -
mm表示分钟,从 00 到 59。 -
ss表示秒,从 00 到 59。 -
sss表示毫秒,从 000 到 999。 -
Z指的是时区,以下两者之一: -
“
Z”表示 UTC -
“
+”或“-”后跟时间“hh:mm”
一些 JavaScript 引擎允许您仅指定时间(其他需要日期):
> new Date('T13:17')
Date {Thu Jan 01 1970 13:17:00 GMT+0100 (CET)}
日期时间格式
日期格式和时间格式也可以结合使用。在日期时间格式中,您可以使用日期或日期和时间(或在某些引擎中仅使用时间)。例如:
> new Date('2001-02-22T13:17')
Date {Thu Feb 22 2001 13:17:00 GMT+0100 (CET)}
时间值:自 1970-01-01 以来的毫秒数
日期 API 称之为time的东西在 ECMAScript 规范中被称为时间值。它是一个原始数字,以自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数编码日期。每个日期对象都将其状态存储为时间值,在内部属性[[PrimitiveValue]]中(与包装构造函数Boolean,Number和String的实例用于存储其包装的原始值的相同属性)。
警告
时间值中忽略了闰秒。
以下方法适用于时间值:
-
new Date(timeValue)使用时间值创建日期。 -
Date.parse(dateTimeString)解析带有日期时间字符串的字符串并返回时间值。 -
Date.now()返回当前日期时间作为时间值。 -
Date.UTC(year, month, date?, hours?, minutes?, seconds?, milliseconds?)解释参数相对于 UTC 并返回时间值。 -
Date.prototype.getTime()返回接收器中存储的时间值。 -
Date.prototype.setTime(timeValue)根据指定的时间值更改日期。 -
Date.prototype.valueOf()返回接收者中存储的时间值。该方法确定了如何将日期转换为原始值,如下一小节所述。
JavaScript 整数的范围(53 位加上一个符号)足够大,可以表示从 1970 年前约 285,616 年开始到 1970 年后约 285,616 年结束的时间跨度。
以下是将日期转换为时间值的几个示例:
> new Date('1970-01-01').getTime()
0
> new Date('1970-01-02').getTime()
86400000
> new Date('1960-01-02').getTime()
-315532800000
Date构造函数使您能够将时间值转换为日期:
> new Date(0)
Date {Thu Jan 01 1970 01:00:00 GMT+0100 (CET)}
> new Date(24 * 60 * 60 * 1000) // 1 day in ms
Date {Fri Jan 02 1970 01:00:00 GMT+0100 (CET)}
> new Date(-315532800000)
Date {Sat Jan 02 1960 01:00:00 GMT+0100 (CET)}
将日期转换为数字
通过Date.prototype.valueOf()将日期转换为数字,返回一个时间值。这使您能够比较日期:
> new Date('1980-05-21') > new Date('1980-05-20')
true
您也可以进行算术运算,但要注意闰秒被忽略:
> new Date('1980-05-21') - new Date('1980-05-20')
86400000
警告
使用加号运算符(+)将日期加到另一个日期或数字会得到一个字符串,因为将日期转换为原始值的默认方式是将日期转换为字符串(请参阅加号运算符(+)了解加号运算符的工作原理):
> new Date('2024-10-03') + 86400000
'Thu Oct 03 2024 02:00:00 GMT+0200 (CEST)86400000'
> new Date(Number(new Date('2024-10-03')) + 86400000)
Fri Oct 04 2024 02:00:00 GMT+0200 (CEST)