解决top-k问题--堆排序
目录
TOP-K问题
堆排序
考虑以下情况:
1.在n个数里面找最大的一个数
2.在n个数里面找最大的两个数
3.在n个数中求前k大的数
为什么不用大根堆呢?
代码
时间复杂度
TOP-K问题
即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
假设我们要在1e6个数中找出前10大个数。
方法一:整体排序(快排或者并排),取前面10个数,时间复杂度nlogn
方法二:堆排序,用一个容量为k(10)的小根堆存放这k(10)个最大的数,时间复杂度为nlogk(这里k为要求的前k个数)
如果对二叉树和堆不了解的朋友可以去看看我的上一篇博客
二叉树详讲(一)---完全二叉树、满二叉树、堆-CSDN博客
考虑以下情况:
1.在n个数里面找最大的一个数
通常的做法是用一个变量max1依次去比较数组中的每一个数,并更新。
int a[10] = {1,2,3,4,5,6,7,8,9,10 };
int max1 = 0;
for (int i = 0; i < 10; i++) {
max1 = max(a[i], max1);
}
printf("%d \n", max1);2.在n个数里面找最大的两个数
我们可以模仿上面的做法,用两个变量去比较数组中a[]的每一个元素,需要确定两个元素谁是代表最大,谁代表次大。假设max1表示最大,max2表示次大。对于每一个元素:先跟max2比较
1.如果a[i]大于max2。max2原来的值我们就一定不需要了。因为max1>max2,a[i]>max2,所以此时的max2的值已经不是这个数组次大的了。之后我们再调整a[i]和max1,max2=min(a[i],max1),max1=max(a[i],max1)。
2.如果a[i]小于或者等于max2.说明a[i]没有资格成为数组中前二的存在,也就不用考虑。
int a[10] = {1,2,3,4,5,6,7,8,9,10 };
int max1 = a[0];
int max2 = -1;
for (int i = 1; i < 10; i++) {
if (a[i] > max2) {
max2 = min(a[i], max1);
max1 = max(a[i], max1);
}
else {
continue;
}
}
printf("%d %d\n", max1,max2); 
3.在n个数中求前k大的数
根据情况2我们可以扩展的想到,用k个变量去依次表示数组中的前k大的数。按照上面的比较方法,先跟这k个变量中最小的maxk去比较,如果大于此时的maxk,说明就目前来说,a[i]有资格进入这前k大的数,先把此时的maxk的值去掉,算上a[i]之后调整这k个数。这样一来,这k个变量一直维护着数组前k大的数。小的数不断地被淘汰,大的数不断地加入,被淘汰说明有前k个数大于自己,加入top-k说明此时的a[i]至少大于目前的maxk。
这k个变量我们可以用一个数组或者树存起来,重要的是怎么实现“调整”这个动作。
由于数组中的每个元素都可能加入前top-k,那么每次加入的调整动作的时间复杂度就影响着整个算法的时间复杂度。
这里我们就自然而然地想到了使用小根堆这种数据结构来维护这k个变量。
并且为了方便,用一个一维数组来模拟一棵二叉树,如何模拟可以去看上面我的博客链接。
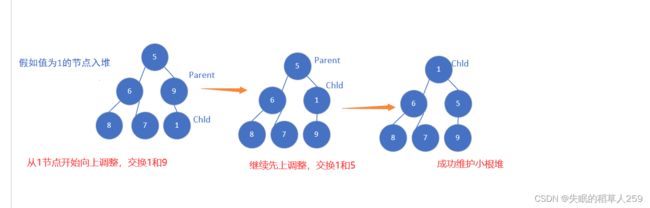
利用小根堆的特性,每次遍历到a[i]的时候,让a[i]跟堆顶元素去比较,如果大于此时的堆顶元素,那么这个堆就先弹出堆顶元素,再将a[i]入堆.
为什么不用大根堆呢?
注意我这里举的例子是求前k大的数。如果是大根堆则意味着堆顶元素是最大的数,诺此时的a[i]小于这个数,那么我们能判断a[i]是否有能进入堆的资格吗?显然是不能的。所以,用大根堆还是小根堆的关键在于,是否能利用堆顶的元素,不断地更新堆内元素,使得堆内元素不断接近top-k.
相反,如果求的是前k小的数,我们就可以用大根堆去维护了。
代码
#include
#include
#include
#include
typedef int HPDataType;
void Swap(HPDataType* a, HPDataType* b) {
HPDataType t = *a;
*a = *b;
*b = t;
}
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
//while (parent >= 0)
while (child > 0)
{
if (a[child] topk[0]) {
//topk[0]表示堆顶元素
topk[0] = a[i];//将堆顶元素换为a[i],变现的去掉了堆顶元素,
//但是此时的a[i]不一定就是堆里最小的
//再向下调整,维护小根堆
AdjustDown(topk, k, 0);
}
}
//打印结果
printf("前%d大的数为:",k);
for (int i = 0; i < k; i++) {
printf("%d ", topk[i]);
}
printf("\n");
}
int main() {
int a[10] = { 1,2,3,4,5,6,7,8,9,10 };
GetTop(a,4,10);
return 0;
} 
向下调整函数AdjustDown()
大致思路就是,自上到下,为了维护小根堆,比较当前节点和孩子节点的值,并与最小的那个孩子交换,直到遍历到parent>=size为止
void AdjustDown(HPDataType* a, int size, int pos)//size为堆的大小,pos为需要调整的位置起点
{
int parent = pos;//parent表示的是父亲节点
int child = parent * 2 + 1;//child表示的是,左右孩子中值最小的节点,默认左孩子
while (child < size)
{
if (child + 1 < size && a[child + 1]
向上调整函数 AdjustUp()
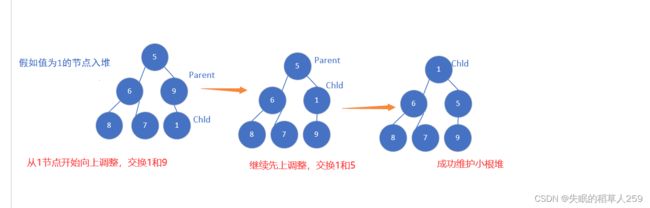
跟向下调整意思一致,方向相反。在入堆的时候,先把这个元素反在堆中最后面,由于此时这个元素可能比父亲节点的值要小,所以要在先上调整
void AdjustUp(HPDataType* a, int child)//child为向上调整的起点
{
int parent = (child - 1) / 2;//向上找child的父亲节点
//while (parent >= 0)
while (child > 0)
{
if (a[child]
堆排序
堆排序是一种基于堆数据结构的排序算法。它将待排序数组构造成一个二叉堆,然后进行堆排序。堆是一个完全二叉树,它的每个节点的值都大于等于(或小于等于)它的子节点的值。堆排序将堆的根节点与最后一个节点交换,然后将堆的大小减1,并进行堆的重构。这个过程将重复执行,直到堆的大小变为1。堆排序的时间复杂度为O(n log n),它是一种不稳定的排序算法。
前面利用堆求解决top-k问题,现在我们利用堆来对数组升序排序,与top-k问题不同的是,这里我们的堆排序在原本的数组上进行。
思考
升序排序用大根堆还是小根堆来维护呢?
如果用小根堆,取出来的堆顶元素就是最小的元素,应该放在数组的首元素位置。
可一旦首元素位置被确定为是最小的,整个堆的父节点与子节点的下标关系就被打乱了。而如果用大根堆,类似于冒泡排序。每次取出来的最大的数,我们都放在后面,然后堆的元素个数减1,前面还未被确定的数下标从0开始依旧是一个堆。
升序排序用大根堆
先将整个数组入堆并维护一个大根堆,每次取出堆顶元素从数组最后面一个位置开始放,数组最后面的位置一定是最先取出的堆顶元素,也就是数组中最大的元素,依次向前是第二次取出的最大值、第三次、第三次、直到第n次。此时整个数组递增,每个下标的元素必定小于下一个下标的元素。
void HeapSort(int* a, int n) {
//升序,用大根堆
//建堆,从最后一个非叶子节点开始向下调整,时间复杂度o(n)
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(a, n, i);
}
int end = n - 1;//end是此时需要确定的最大的数放的位置,从下标n-1开始
while (end > 0) {
Swap(&a[0], &a[end]);//将堆顶元素放在a[end]处
AdjustDown(a, end, 0);//从[0,end)处调整
end--;//更新end
}
for (int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
}
int main() {
int a[10] = { 10,9,8,7,6,5,4,3,2,1 };
HeapSort(a, 10);
return 0;
}
时间复杂度
求前top-k问题
总的时间复杂度是:建堆的时间(klog(k))+遍历整个数组并调整的时间(n*log(k))
化简用大O表示法:Nlog(K)
N为数组元素个数,k为要求的前k大的数的个数
堆排序
时间复杂度为:建堆(o(n))+交换调整(o(nlog(n)))
化简用大O表示法:Nlog(N)
N为数组元素个数