【扩散模型】10、ControlNet | 用图像控制图像的生成(ICCV2023)

论文:Adding Conditional Control to Text-to-Image Diffusion Models
代码:https://github.com/lllyasviel/ControlNet
出处:ICCV2023 Best Paper | 斯坦福
时间:2023.02
一、背景
文本到图像的生成尽管已经有很好的效果,也很方便,但难以控制生成的图像中的空间分布、姿态、形状等
本文提出了可以使用空间条件来控制模型生成结果的 ControlNet 网络,例如边缘图、深度图、关键点、分割图等等都可以用作图像生成的条件
扩散模型中会需要使用text作为条件引导模型生成, 而ControlNet在引导的时候会增加一个条件实现更加可控的text-to-image生成
一般来说,为一个大型的 text-to-image 生成扩散模型学习一个条件控制模型难度也挺大的,因为:
- 特定场景的数据量少, 在较少的数据量上很容易出现过拟合,导致模型遗忘
- 大的计算集群很奢侈, (stable diffusion base模型需要15万个A100显卡小时)
- end2end是必要的, 一些特定场景需要将原始的输入转为更高语义的表达, 手工处理的方式不太可行
本文提出的 ControlNet 是怎样的呢:
-
ControlNet 是一个 end-to-end 网络,为大型的 text-to-image 扩散模型学习一个条件控制
-
具体来说,ControlNet先复制一遍扩散模型的权重,得到一个“可训练副本”。而原扩散模型经过几十亿张图片的预训练,因此参数是被“冻结”的。而这个“可训练副本”只需要在特定任务的小数据集上训练,就能学会条件控制。
-
据作者表示,即使数据量很少,模型经过训练后条件控制生成的效果也很好。“冻结模型”和“可训练副本”通过一个1×1的卷积层连接,名叫“0卷积层”。0卷积层的权重和偏置初始化为0,这样在训练时速度会非常快,接近微调扩散模型的速度,甚至在个人设备上训练也可以。
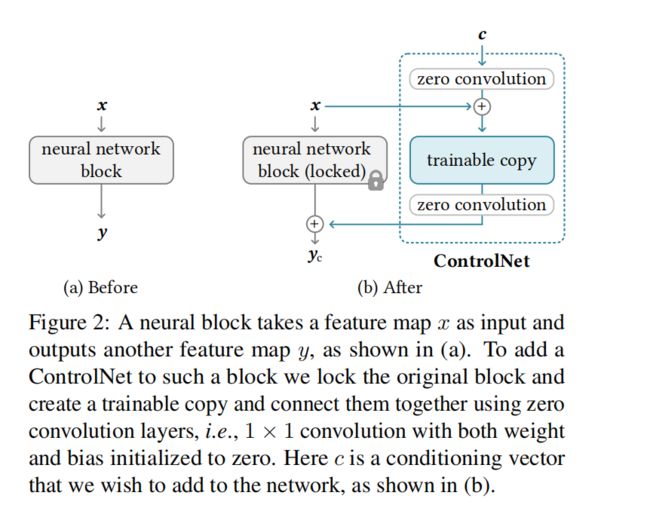
二、方法
如图 2,ControlNet 会复制一个副本,然后在副本的上下都加上 1x1 卷积,然后将副本和原来的训练好的参数相加,作为最终的输出结果
假设模型参数为 Θ \Theta Θ,输入为 x x x,输出为 y y y
则:
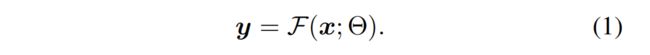
当加入 ControlNet 的时候,会固定住 Θ \Theta Θ,然后制作一个副本 Θ c \Theta_c Θc,这个副本是可训练的,起输入是 conditioning vector c c c,原始的参数 Θ \Theta Θ 是固定不变的。
相当于这个副本使用的初始化是训练的很好的模型参数了,所以其训练起来也比较快
副本 Θ c \Theta_c Θc 上下的 zero convolution 层 Z ( . ; , ) Z(.;,) Z(.;,) 是 1x1 卷积,权重和偏置都初始化为 0
完整的 ControlNet 的结构如下:
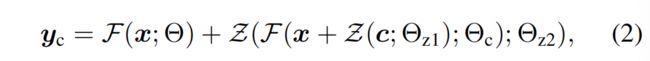
第一个训练阶段,由于权重和偏置都是 0,所以 Z ( . ; , ) Z(.;,) Z(.;,) 是 0,即:
![]()
为了在训练开始时防止有害噪声对神经网络层的隐藏状态产生影响,作者采用了零卷积法。这种方法确保了在某个特定条件下(用 Z(c; Θz1) = 0 表示)神经网络的零卷积层不会对噪声做出任何响应。因为这个可训练的副本也会接收到输入图像 x,所以它是完全功能性的,并且保留了大型、预先训练过的模型的能力,这使得它可以作为进一步学习的强大支撑。零卷积通过在初始训练步骤中消除随机噪声作为梯度,来保护这个支撑。
零卷积(Zero Convolution)能够保护网络是因为它在训练的初始阶段通过强制卷积层的输出为零来防止梯度的更新,这样做有以下几个好处:
-
防止过拟合:在训练初期,模型可能会对输入数据中的噪声过度敏感,从而学习到这些不必要的噪声特征。通过使用零卷积,可以减少这种过拟合现象,因为网络不会对这些噪声做出响应。
-
稳定训练:在训练开始时,权重的随机初始化可能会导致网络输出极大的变化,这些变化可能会引起不稳定的梯度更新。零卷积通过限制这些初始的更新,有助于稳定训练过程。
-
保留预训练特性:如果网络是在一个大型数据集上预训练的,它将会有一些通用的特征提取能力。零卷积确保这些能力在训练初期不会被破坏,从而网络可以在这个基础上进一步学习和微调。
-
控制学习过程:通过逐渐放开零卷积的限制,可以更精细地控制学习过程,让网络按照预定的节奏逐步学习,而不是一开始就全面开放所有的学习能力。
-
总的来说,零卷积是一种正则化技术,它通过在训练初期控制网络的学习,帮助网络更好地学习有用的特征,并保护网络不受初始训练阶段可能的有害噪声的影响。
ControlNet 如何为 text-to-image 扩散模型服务
作者使用 SD 为例来展示了如何将 ControlNet 添加到扩散模型中
Stable diffusion 模型结构:整个模型包括 25 个 blocks,8 个 down-sampling 或 up-sampling 卷积层,其他 17 个 block 中,每个都包含 4 个 resnet 层 + 2 个 ViTs
- U-Net
- encoder:包含 12 个 blocks
- middle block:一个 blocks
- skip-connected decoder:包含 12 个 blocks
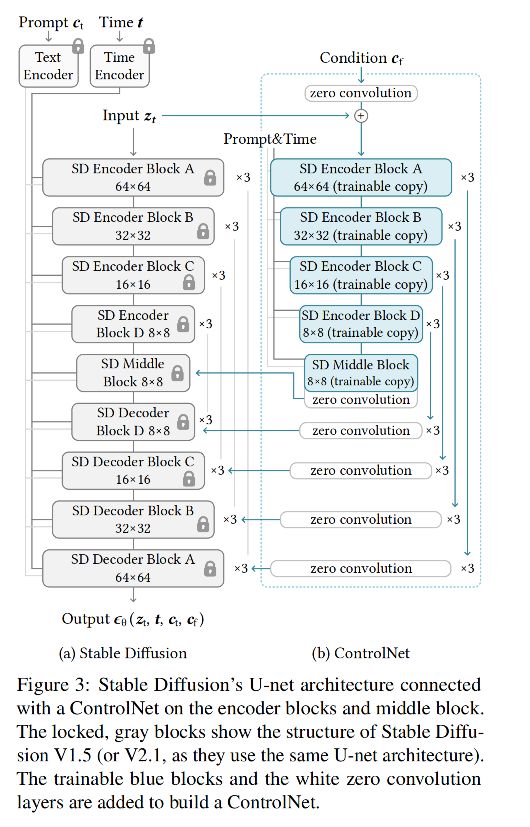
如图 3a 展示了 SD Encoder Block A,x3 表示重复 3 次,文本编码使用的是 CLIP text encoder
ControlNet 结果会用于 U-Net 中的每个 encoder 层,也就是 ControlNet 会复制 12 个 encoding blocks 和 1 个 middle block,且这 12 个 encoder 是有 4 个不同的分辨率(64/32/16/8),每个 encoder 重复 3 次。输出会加到这 12 个 skip-connections 和 1 个 middle block 上
训练 ControlNet 和 SD 的显存和时间对比,A100 上(40G显存),使用 ControlNet 来微调:
- 显存:仅需 23% 的显存占用
- 时间:仅需 34% 的训练时间
由于 SD 使用的是潜在空间,也就是使用 VQ-GAN 将 512x512 的空间编码到 64x64 的隐空间上,所以,使用 ControlNet 时,也需要先把条件图(边缘、深度、姿态)编码到 64x64 的特征空间上。具体的方法是,作者使用了一个很小的网络 ϵ ( . ) \epsilon(.) ϵ(.) 对条件图进行了编码,小网络由 4 个卷积构成(4x4卷积+2x2步长+ReLU,channel 分别为 16/32/64/128),将编码后的特征 c f c_f cf 输入 ControlNet:
![]()
训练:
-
给定输入图片 z 0 z_0 z0,扩散模型会逐步对图像加噪,得到噪声图片 z t z_t zt
-
给定一系列条件、time step t、text prompt c t c_t ct、和 task-specific condition c f c_f cf
-
扩散模型学习一个网络来预测每步添加的噪声如下, L L L 是整个扩散模型学习的目标函数,对于微调 ControlNet 来说 也是目标函数

训练阶段,作者随机使用空的字符串来代替 50% 的 text prompt c t c_t ct,文本提示通常用于提供给模型关于图像内容的描述性信息,帮助模型理解图像应该包含什么。通过这种替换方法,ControlNet 被迫依靠图像本身的视觉信息来识别语义,而不是依赖文本提示。这意味着模型需要更加精确地理解图像中的视觉元素(如边缘、姿态、深度等),从而在没有文本提示的情况下也能识别和生成图像。
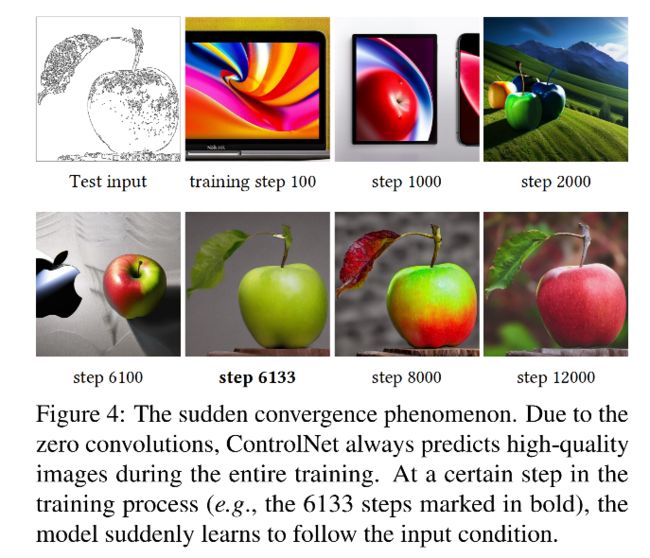
此外,作者在训练的过程中还发现了 “突然收敛” 现象:
- 在训练时,由于使用了零卷积,所以不会为模型带来额外的干扰,模型一直都能输出高质量的图片
- 作者观察到模型并不是逐渐学习如何根据输入的条件图像生成对应的控制条件,而是突然之间就能成功地做到这一点。这种现象通常在训练的前10,000步优化过程中发生,这种现象被称为“突然收敛现象”,即模型在较短的训练时间内突然达到了理解输入条件并据此生成图像的能力(如图 4)
推理:
还可以使用很多不同的方式来进一步的控制 ControlNet 对扩散过程的影响
SD 是使用 Classifier-Free Guidance (CFG) 来生成高质量的图像的,Classifier-Free Guidance 的公式如下:
![]()
- prd:是模型最终的输出
- uc:是 unconditional 输出
- c:是 conditional 输出
- cfg:是 user-specified weight
当使用一个 conditioning image 时,这个 conditional image 可以被加到 uc 和 c 上,也可以只加到 c 上
当不输入 prompt 时(只输入 conditioning image):
- 将 conditioning image 同时加到 uc 和 c 上时,就会完全移除 CFG guidance 如图 5b
- 将 conditioning image 只加到 c 上时,这个 guidance 就会非常强,如图 5c
- 本文作者为了解决这个难题,首先将 conditioning image 加到 c 上,然后给 Stable Diffusion 和 ControlNet 的每个连接处加一个权重 wi=64/hi,hi 表示第 i 个 block 的尺寸,h1=8,h2=16,h1=64,通过逐步降低 CFG guidance 的权重,得到了如图 5d 的效果

当想要输入多个 conditioning images 同时作为条件时,可以直接将对应的 controlnet 的输出加起来就行,如图 6
