OOM:GC overhead limit exceeded分析流程
前言:
OOM常见的错误类型有如下:
1.Java Heap Space(堆)
2.GC overhead limit exceeded(GC回收的开销小于回报,下面进行详细分析)
3.PermGen space(永久代)
4.Metaspace(元空间)
该异常的描述是:
GC在经过一番运算之后,发现回收的内存很小,不能满足新对象所需的内存,新对象所需的内存空间.默认情况下,如果GC花费的时间超过98%,并且GC回收的内存少于2%,就会发生该错误.
实际上,我们知道JVM内存不够了,可以通过GC回收垃圾对象来获得内存,当新的对象来临时,JVM发现内存空间不足,于是进行GC,进行过几次GC之后发现空间仍然存放不下或者不足以放下新的对象.那么JVM就会抛出该错误.当发生该错误时,一定要有大概的原因.
分析历程
业务场景:定时任务发生了OOM
1.首先我的第一排查路线是dump文件,如果配置了dump文件路径,JVM会在发生OOM错误之后,生成一个快照文件(.hprof),比较失望的是,服务器上并没有配置该项参数,经过一番询问之后,服务器上给这个任务分配的内存是128M,于是我在本地IDEA中模拟了该项参数
-Xms128m
-Xmx128m
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=D:\\dump\\costBumpLine.hprof
2.本地Debug分析
虽然服务器和本地有一定的差异,因为没有直接的dump文件.在有限的知识生命体系中,想不出更好的解决思路.但至少可以有一个大概的方向接下来就是分析hprof文件
我这边使用的是MAT分析工具,如果大家有更好的,还请大家在下方评论,
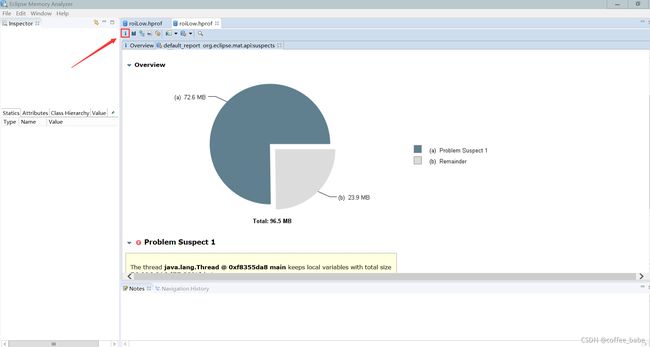
点击这个感叹号按钮,点击出现概览,MAT会给出一个出现问题的最大可能的猜测,也有可能是不准的,仅仅是给你一个参考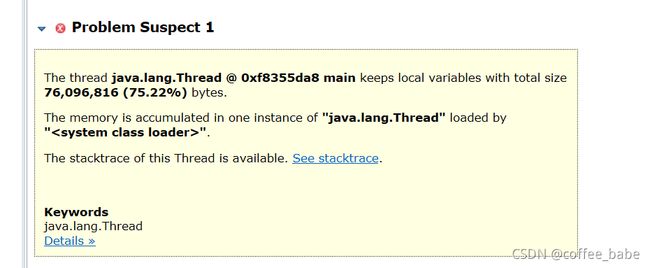
这里给出的猜测原因是一个线程持有本地变量占比达到了75%.显然还得不出原因是什么.但是我们可以初步判断可能是JVM的堆空间可能出现了不足,接下来我们进一步分析柱状图.

我们可以点击Retained Heap 深堆进行一个倒排,查看哪些对象占据的空间比较大,不看浅堆的原因是由于浅堆只包含了对象本身对象头、实例数据、对齐填充的一个占据空间大小,并不包含它持有的对象引用空间大小.一般情况是要分析深堆的.
根据上图我们发现根本定位不到我们在业务中操作的对象,都是一些底层数据结构对象.
这时我们可以输入一个正则表达式,
在这个地方输入我们在项目中的前缀com.xxx就会出现我们项目中所使用的哪些对象占据了空间产生的问题.
到现在为止也只能确定个50%的原因,因为我们定位的信息不是真正的生产服务器.这是一个本地生成的文件,于是我们进行第二步一步一步地debug本地代码,这个过程中我们需要使用一些JDK自带的小工具.来帮助我们在debug的过程中观察JVM中堆的空间变化.
jps 查看java进程
jmap -heap 查看java进程的堆内存信息
jstat -gcutil m n 打印某进程的GC状况(m:是指打印间隔,n是指打印多少次)
通过以上步骤就可以分析定位到问题的根源所在了.
在本案例中的原因是由于定时任务分配的内存是比较有限的,我把数据库查询都写成了单表查询以及在进行业务处理之前先把所有的数据都查询到,业务只是对数据进行处理.以致于在业务开始处理之前对象一直占据着空间,所以就发生了OOM.
改进方式有两种:
1.适当增加关联查询
2.在业务线程中耦合io线程,也就是在业务需要处理数据的地方进行查询,然后每一个业务处理的地方及时地将没用地对象置为null,help GC相信大家在看源码地时候经常见到这个操作.
3.增大内存.如果内存比较富裕的情况下,直接增大,不富裕就只能一步一步地精简了.