如何写一个简单的爬虫程序
1.首先给爬虫程序找到储存路径
2.按住shift和右键,选择在此处打开Powershell窗口(s)
3.在窗口内输入scrapy(杀毒软件可能会阻止程序运行,不要选择阻止!!!如果不小心选择了阻止,把杀毒软件退掉,重新从第二步开始)
4.在窗口内输入scrapy startproject movie 其中movie是文件的名字,可以自己取
如下图所示即表示成功
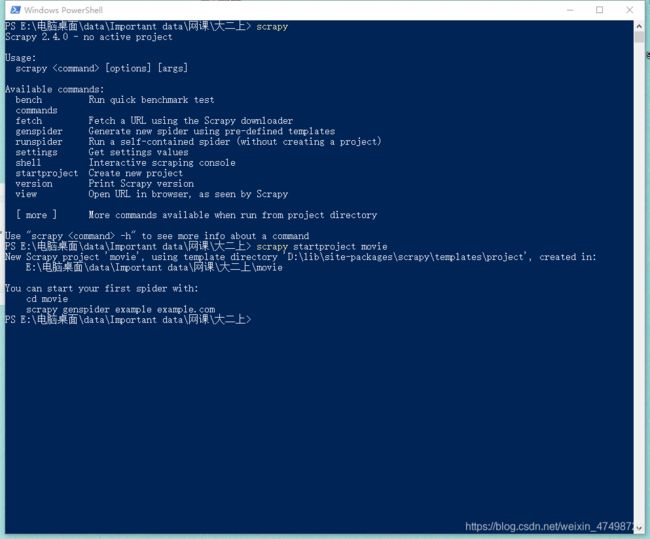
5.同时也可以看到第一步打开的储存路径下多了movie这个文件夹

6.打开pycharm,点击左上角,打开刚刚新建的项目(就是movie这个文件夹)
记得选中外面的那个movie文件夹,不要选中里面的那个!!!
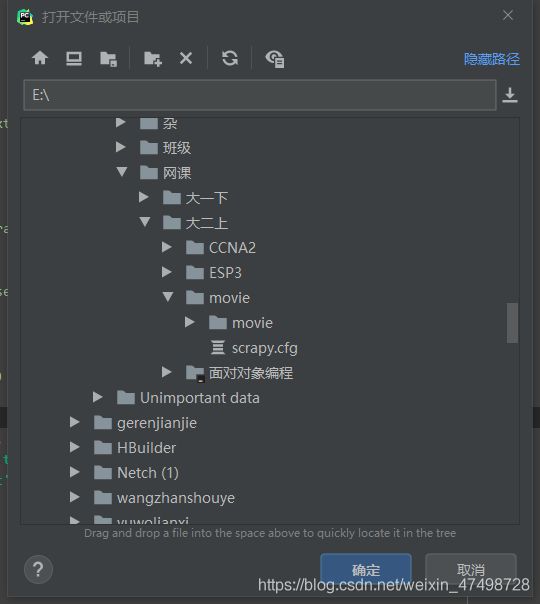
7.打开pycharm下面的terminal工具
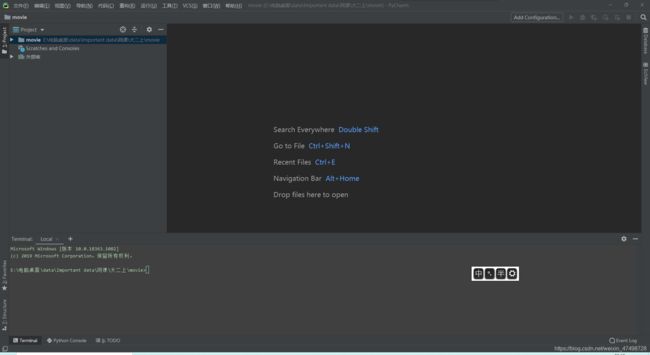
8.在terminal窗口内输入scrapy

9.确定要爬取的网站,我爬取的是https://www.1905.com/vod/
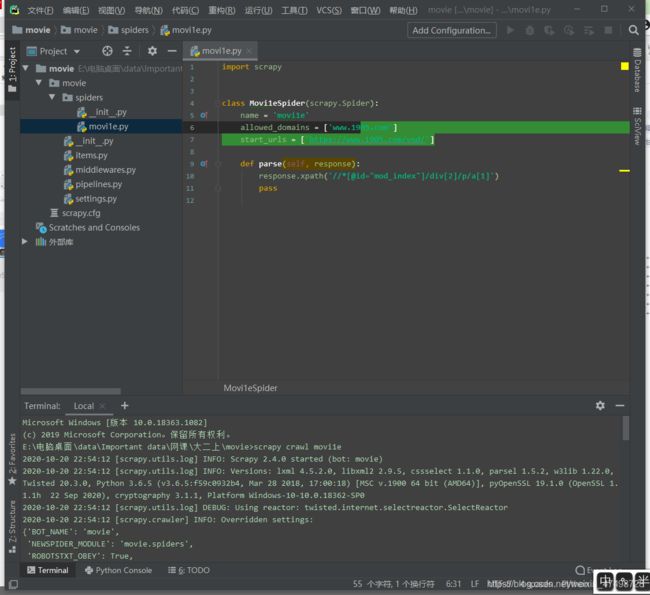
10.在terminal窗口内输入scrapy genspider movi1e www.1905.com
movi1e是文件名字可以自取,不要和项目名称一样即可,www.1905.com是要爬取网站的域名
当左边显示了movi1e.py 即表示成功

11.到这里就完成了创建项目
12.在parse下输入response.xpath()
这个里面是填写爬虫规则的

13.打开要爬取的网页,把光标放在要爬取数据内容的地方,右边查看源代码
然后右边会出现你选中的内容的源代码
14.对那部分的源代码进行copy,记得选择 copy xpath!!!
15.把复制的规则写入response.xpath(),记得加上单引号

16.然后把要爬取的网站的整个地址复制到start_urls

17.在terminal窗口内输入scrapy crawl movi1e
18.跳出来的就是爬取的内容,只不过这是没有转义过的
19.打开scrapy的官网(https://scrapy.org/),对之前的爬虫代码进行修改

20.修改如下:(因为电影网站不好爬,所以爬取网站改成了https://book.qidian.com/info/1014973218#Catalog)

21.在terminal窗口内输入scrapy crawl movi1e
如图所示,即表示成功
