数据驱动下的LLM优化:如何从数据集中发掘最大价值?
来源,公众号:芝士AI吃鱼
本文聚焦于通过使用精心策划的数据集对LLM进行微调,以提升其建模性能。具体来说,本文强调了涉及修改、使用或操纵数据集进行基于指令的微调的策略,而不是改变模型架构或训练算法。本文还将解释如何准备自己的数据集来微调开源LLM。
有监督指令微调
什么是指令微调,我们为什么要关心?
指令微调是一种用于改善像ChatGPT和Llama-2-chat这样的语言模型性能的方法,通过让模型为一系列示例输入及其期望输出生成输出。这允许模型在特定应用或任务中表现出更受控制和期望的行为。同时,它还可以提高AI系统在实际应用场景中的可靠性、特定性和安全性。
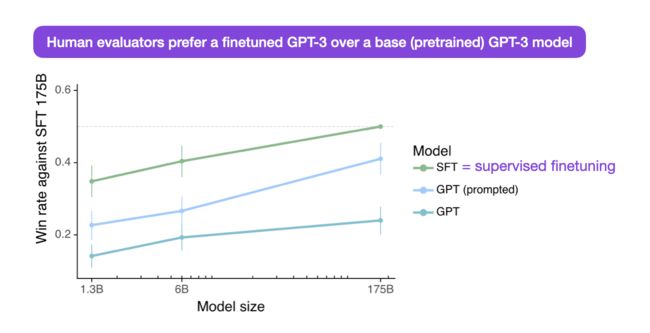
指令微调使用包含指令-响应对的数据集来提高LLM的指令遵循能力。这样的指令微调数据集通常包括三个组成部分:
- 指令文本
- 输入文本(可选)
- 输出文本
下面的例子列出了两个训练示例,一个没有输入文本,一个有可选的输入文本:

指令微调格式
然后,LLM通过下一个标记的预测(类似于预训练)在这些指令数据集上进行微调。与预训练的不同之处在于,模型在被要求进行下一个标记的预测以自回归方式生成输出文本之前,会看到整个指令和输入文本作为上下文,如下所示。

在指令数据集上微调LLM
上述过程中,以迭代的、逐标记方式微调LLM以生成期望输出,也被称为有监督微调。
在实践中,有监督微调之后通常还有一个可选的微调阶段,使用额外的偏好数据和来自人类注释者的排名标签,这些注释者比较由LLM生成的响应。这个过程也被称为带有人类反馈的强化学习(RLHF),但这超出了本文的范围,本文重点是指令数据集本身。
微调流程和数据集来源
在微调LLM时,指令微调的数据集可以通过多种方式获得:
- 人类创建:专家注释者可以提供明确的指令和反馈,创建指令微调数据集。这对于特定领域的任务或减少特定偏见或不希望的行为特别有用。
- LLM生成:我们可以使用现有的LLM(如果服务条款允许)生成大量潜在的输入-输出对。然后,这些可以由人类为质量进行精炼或评级,然后用于微调新的LLM。与上述人类创建的方法相比,这种方法通常更高效,因为一个可用的LLM(例如通过API接口的GPT-4)可以在短时间内生成大量潜在的示例。
使用人类创建或LLM生成的数据的LLM微调流程在最近的《Instruction Tuning for Large Language Models: A Survey》中进行了总结。
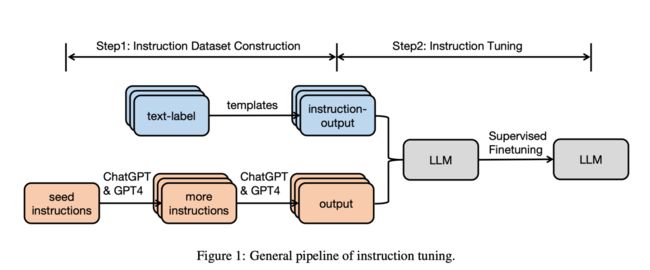
此外,我们还可以将人类创建的和LLM生成的指令数据结合起来,以获得双方的优势。
接下来的部分将更详细地讨论LLM生成的和人类创建的指令微调数据集,包括最近的研究亮点。
LLM生成的数据集
数据标注一直是机器学习的瓶颈。作为人类注释者,像将图像分类为“猫”或“狗”这样的简单标注任务,在规模化操作时已被视为繁琐。
需要长文本注释的任务可能更加耗时和具有挑战性。因此,人们投入了大量努力,使用现有的LLM自动生成用于指令微调的数据集。
Self-Instruct
LLM生成数据集中最著名和广泛使用的方法之一是“Self-Instruct”。
那么,它是如何工作的呢?简要来说,它涉及四个阶段:
- 使用一组人类编写的指令(本例中为175个)和样本指令填充种子任务池;
- 使用预训练的LLM(如GPT-3)确定任务类别;
- 根据新指令,让预训练的LLM生成响应;
- 收集、修剪和过滤响应,然后将它们添加到任务池中。

“自我指令”的一个早期流行应用是Alpaca数据集,该数据集包含52k个LLM生成的指令-响应对。今年早些时候,Alpaca被用于创建第一个微调的Llama v1模型。
回译
另一种有趣的方法涉及从响应开始,然后通过LLM生成相应的指令。
换句话说,与其从人类编写者收集指令微调数据集,不如利用LLM产生指令-响应对(也称为蒸馏)。
在一篇名为《Self-Alignment with Instruction Backtranslation》的论文中,研究人员通过“指令反向翻译”对LLM进行了微调,并发现这种方法超过了那些在像Alpaca这样的蒸馏数据集上训练的模型。
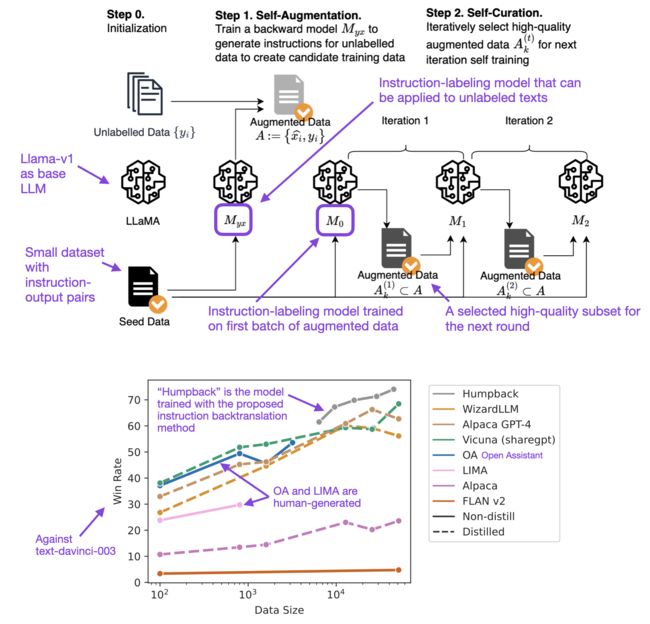
高质量数据集:在质不在量
在前一节中,我们讨论了由LLM生成的数据集。现在,让我们转换一下方向,来看看高质量的、人类生成的数据集。
LIMA
《The LIMA: Less Is More for Alignment》论文表明,在指令微调数据集方面,质量胜过数量。
在这项研究中,研究人员精心挑选了1,000个指令对来微调650亿参数的Llama-v1模型,称为LIMA,使用的是有监督微调。
值得注意的是,其他微调的Llama模型,如Alpaca,是在一个相当大的52,000个LLM生成的指令对数据集上训练的。在选定的基准测试中,LIMA超越了使用人类反馈的强化学习(RLHF)方法的模型,包括ChatGPT和GPT-3.5。

接下来的部分将展示如何开始使用开源LLM,并在LIMA上微调这些模型。
在LIMA上微调LLM
这一部分将解释如何使用Lit-GPT仓库在像LIMA这样的指令数据集上微调开源LLM。为了这个简要的演示,我们将使用7B参数的Llama 2基础模型,并在LIMA上进行微调。假设已经克隆了Lit-GPT仓库,可以通过以下三个步骤开始:
- 下载模型文件
export HF_TOKEN=your_token
python scripts/download.py \
--repo_id meta-llama/Llama-2-7b-hfpython scripts/convert_hf_checkpoint.py \
--checkpoint_dir meta-llama/Llama-2-7b-hf- 数据准备
python scripts/prepare_lima.py \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf- 利用LoRA微调大模型
python finetune/lora.py \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \
--data_dir data/lima请注意,–checkpoint_dir参数在第2步准备数据集时是必需的,因为数据集的准备是模型相关的。不同的LLM可能使用不同的分词器和特殊标记,因此按照相应的方式准备数据集非常重要。
提示
可以编辑 finetune/lora.py 文件,将 override_max_seq_length = None 更改为 override_max_seq_length = 2048,以减少GPU内存需求。
python scripts/prepare_lima.py \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \
--max_seq_length 2048此外,还建议修改 max_iter 设置,将其更改为 max_iter = 1000,以微调大约1次通过LIMA数据集,该数据集包含1k个训练示例。

选择微调迭代次数
作为参考,使用默认设置的LoRA在A100 GPU上微调7B参数模型,例如在Alpaca上的52k指令对,大约需要1小时。请注意,LIMA比Alpaca小50倍,因此微调只需几分钟。

Lit-GPT中可用的模型和数据集
截至目前,Lit-GPT目前支持多个微调数据集:
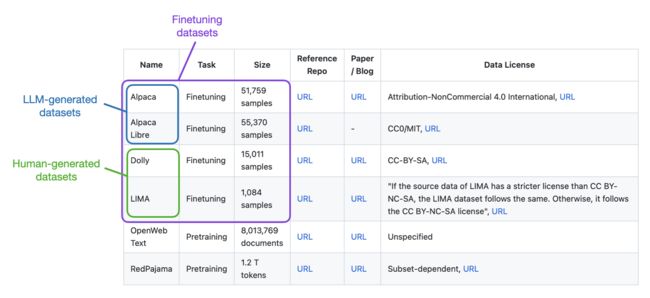
准备新的和自定义数据集
除了上述现有数据集,可能对添加新数据集或使用自己的数据集微调自定义开源LLM感兴趣。
为Lit-GPT中的LLM准备数据集有两种主要方法:
- 使用
scripts/prepare_csv.py脚本从CSV文件中读取指令数据集。 - 创建类似于LIMA的自定义
scripts/prepare_dataset.py脚本,我们之前使用过。
准备新数据集的最简单方法是使用Lit-GPT中的 scripts/prepare_csv.py 脚本从CSV文件中读取。您所需要的只是一个CSV文件,它有如下所示的三个列标题:

假设将此数据集导出为MyDataset.csv,那么可以按照以下步骤准备并微调模型:
- 准备数据
python scripts/prepare_csv.py \
--csv_dir MyDataset.csv \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf- 微调模型利用LoRA
python finetune/lora.py \
--data_dir /data/csv \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf考虑的其他数据集
前一节介绍了如何为Lit-GPT中的开源LLM准备自定义数据集。如果你没有自己想要尝试的数据集,但想要使用现有数据集进行实验,这里有一些可探索数据集的建议:
- Open Assistant(多语言)是由人类创建和注释的助理式对话集合。它包含161,443条消息,涵盖35种语言,丰富了461,292个质量评估,结果是超过10,000个全面注释的对话树。这个数据集是全球众包倡议的成果,吸引了超过13,500名志愿者参与。
- Natural Instructions是一个手工制作的英语指令数据集,包含193K条条目,涵盖61个独特的NLP任务。
- P3(公共提示池)是一个使用170个英语NLP数据集和2,052个英语提示构建的指令微调数据集。提示(有时称为任务模板)将传统NLP任务中的数据实例(例如,问题回答、文本分类)映射到自然语言的输入输出对。
- Flan 2021是一个英语指令数据集合集,通过将62个流行的NLP基准(包括SNLI、AG News等)转换为语言输入和输出对而创建。
可探索的研究方向
现在我们已经讨论了与指令微调相关的原因和方法,那么我们可以探索哪些有趣的研究方向来提升开源LLM的性能?
合并数据集
除了上面提到的P3和Flan 2021数据集,我还没有看到通过结合多个来源的数据集来创建更大数据集的尝试。例如,尝试结合LIMA和Dolly等数据集可能是有意义的。
数据集排序
在上述合并数据集的想法之后,探索不同数据点的不同顺序(例如,按指令类型排序或混洗)的作用可能很有趣。除了Pythia论文中的预训练实验外,我还没有看到关于指令微调背景下的数据集排序的研究。
多轮次训练
由于大型数据集的需求,LLM通常训练不到一个epoch,这意味着它们不会多次访问数据点。尽管计算成本是原因之一,但LLM也容易过拟合。尽管如此,有许多减少过拟合的技术可用,研究LLM的多轮次训练将会很有趣。 例如,可以在几分钟内在像LIMA这样的小数据集上训练LLM。多次迭代数据集是否有意义?
自动质量过滤
是否有必要默认采用数据集过滤? 与前面讨论的LIMA研究相关,AlpaGasus论文也强调,更大的数据集对微调LLM并不一定有利。在AlpaGasus研究中,研究人员使用ChatGPT识别原始52,000实例Alpaca数据集中质量低的指令-响应对。他们发现,将其减少到仅9,000个高质量对时,实际上在训练7亿和13亿参数的Llama-v1 LLM时提高了性能。

作为AlpaGasus的一个可行替代方案,可以使用LLM来过滤人类生成的数据集(而不是LLM生成的)。
结论
本文讨论了指令微调,并解释了LLM生成和人类生成数据集的优势。我们还简要介绍了如何使用不同的数据集微调开源LLM,以及如何使用自己的数据集创建自定义LLM的教程。与专有API和服务相比,这样的自定义LLM可以帮助利用公司的特定数据集,改善LLM在某些用例上的表现,并提供完全的隐私控制。