数据库原理—SQL学习总结
SQL学习总结
- 一、绪论
-
- 1.1数据库的四个基本概念
- 1.2关系模型
- 1.3数据库系统的三级模式结构
- 二、关系数据库
-
- 2.1关系数据结构形式化定义
- 2.2关系
- 2.3关系模式
- 2.4关系代数
- 三、关系数据库标准语言SQL
-
- 3.1开始:新建一个表
- 3.2:各种查询
- 四、数据库安全性
-
- 1.安全标准
- 2.数据库安全性控制
- 3.自主存取控制方法
- 4.视图机制
- 5.审计
- 五、数据库完整性
-
- 1.三大完整性
- 2.触发器(trigger)和存储程序
- 六、总结
一、绪论
第一章的知识都是一些定义和概念,把重点需要记忆的东西挑了挑写在了这。
1.1数据库的四个基本概念
1.数据(data):
描述事物的符号记录称为数据,数据是数据库中存储的基本对象,数据的含义称为数据的语义,数据与其语义是不可分的。
2.数据库(database):
数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。
2.数据库管理系统(DBMS):
数据库管理系统是位于用户与操作系统之间的一层数据管理软件。数据库管理系统提供的语言功能:数据定义语言DDL、数据操纵语言DML。
主要功能有:
- 数据定义功能
- 数据组织、存储和管理
- 数据操纵功能
- 数据库的事务管理和运行管理
- 数据库的建立和维护功能
3.数据库系统(DBS):
数据库系统是由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。一般简称数据库系统为数据库。
1.2关系模型
关系:一个关系对应通常说的是一张表。
元组:表中的一行即为一个元组,也就是一个实体。
属性:表中的一列即为一个属性,给每一个属性起一个名称即为属性名。
码:也称为码键。表中的某个属性组,可以唯一确定一个元组。
域:是一组具有相同数据类型的值的集合。属性的取值范围来自某个域
分量: 元组中的一个属性值
关系模式: 对关系的描述,一般表示为 关系名(属性1,属性2,···,属性n)
1.3数据库系统的三级模式结构
1.模式(逻辑模式):
数据库中全体数据的逻辑结构和特征的描述称为模式,可以看作所有用户的公共数据视图.一个数据库只有一个模式.
2.外模式(也称子模式或用户模式):
外模式通常是模式的子集,介于模式与应用之间,一个数据库可以有多个外模式。反映了不同的用户的应 用需求、看待数据的方式、对数据保密的要求。是保证数据库安全性的一个有力措施。
3.内模式(也称存储模式):
内模式是数据物理结构和存储方式的描述,一个数据库只有一个内模式,是数据在数据库内部的表示方式。包括:记录的存储方式,索引的组织方式、数据是否压缩加密以及数据存储记录的规定。
二、关系数据库
第二章开始不光包括定义和概念,开始涉及到了一些计算,这些计算和以前的集合类似。
2.1关系数据结构形式化定义
1.域(Domain):
域是一组具有相同数据类型的值的集合。
2.笛卡尔积(Cartesian Product):
给定一组域D1,D2,…,Dn,允许其中某些域是相同的。
D1,D2,…,Dn的笛卡尔积为:
D1×D2×…×Dn={(d1,d2,…,dn)|di∈Di,i=1,2,…,n}
所有域的所有取值的一个组合
不能重复
例如: 假设集合A={a, b},集合B={0, 1, 2}, 则两个集合的笛卡尔积: A×B={(a, 0), (a, 1), (a,
2), (b, 0), (b, 1), (b, 2)}。
3.元组(Tuple)
笛卡尔积中每一个元素(d1,d2,…,dn)叫作一个n元 组(n-tuple)或简称元组。
4.分量(Component)
笛卡尔积元素(d1,d2,…,dn)中的每一个值di 叫作一个分量
5.基数
若Di(i=1,2,…,n)为有限集,其基数为mi(i=1, 2,…,n),则D1×D2×…×Dn的基数M为:
2.2关系
系是一个二维表。表的每行对应一个元组,表的每列对应一个属性。
候选码:
若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码。
简单的情况:候选码只包含一个属性。
最极端的情况:所有属性组是候选码,称为全码
主码:
若一个关系有多个候选码,则选定其中一个为主码
主属性:
候选码的诸属性称为主属性。不包含在任何侯选码中的属性称为非主属性或非码属性。
关系的三种类型:基本关系(通常又称为基本表或基表)、查询表和视图表。
2.3关系模式
'关系模式是对关系的描述,可以形式化地表示为: R(U,D,DOM,F)
R 关系名
U 组成该关系的属性名集合 U中属性所来自的域
D DOM 属性向域的映象的集合
F 属性间数据的依赖关系的集合'
2.4关系代数
常用的关系操作:

1.RxS 笛卡尔积:
列:(n+m)列元组的集合
- 元组的前n列是关系R的一个元组
- 后m列是关系S的一个元组
- 行: k1×k2个元组(基数)
- R×S = {tr ts |tr ∈R ∧ts∈S }
2.选择 σ:
关系R中选取使逻辑表达式F为真的元组,是从行的角度进行的运算。
σF(R) = {t|t∈R∧F(t)= '真'}
F是一个选择条件,是一个逻辑表达式,取值为“真”或“假”
3.投影Π:
从R中选择出若干属性列组成新的关系,投影操作主要是从列的角度进行运算。投影之后不仅取消了原关系中的某些列,而且还可能取消某些元组(避免重复行)
4.连接 ⋈:
从两个关系的笛卡尔积中选取属性间满足一定条件的元组。一般的连接操作是从行的角度进行运算。自然连接还需要取消重复列,所以是同时从行和列的角度进行运算。
'两类常用连接运算'
1.等值连接(equijoin)
θ为“=”的连接运算称为等值连接
从关系R与S的广义笛卡尔积中选取A、B属性值相等的那些元组,即等值连接为:
2.自然连接(Natural join)
自然连接是一种特殊的等值连接
两个关系中进行比较的分量必须是相同的属性组
在结果中把重复的属性列去掉
3.自然连接的含义
悬浮元组(Dangling tuple)
两个关系R和S在做自然连接时,关系R中某些元组有可能在S中不
存在公共属性上值相等的元组,从而造成R中这些元组在操作时被
舍弃了,这些被舍弃的元组称为悬浮元组。
'连接类型'
外连接(Outer Join):如果把悬浮元组也保存在结果关系中,而在其他属性上,填空值(Null),就叫做外连接
左外连接(LEFT OUTER JOIN或LEFT JOIN)
只保留左边关系R中的悬浮元组
右外连接(RIGHT OUTER JOIN或RIGHT JOIN)
只保留右边关系S中的悬浮元组
5.除 ÷:
同时从行和列角度进行运算.
给定关系R (X,Y) 和S (Y,Z),其中X,Y,Z为属性组。
元组在X上分量值x的象集Yx包含S在Y上投影的集合,记作: R÷S={tr[X]|tr∈R∧πY(S)∈Yx}
Yx:x在R中的象集,x = tr[X]
三、关系数据库标准语言SQL
3.1开始:新建一个表
这里用之前的一个例子:
1.建立模式:
-- 建立模式
CREATE SCHEMA 模式名 AUTHORIZATION 用户名
-- 删除模式(前提删除该模式下的所有内容,如删除基本表drop table test.tab1)
drop schema Test
2.建立表:
CREATE TABLE SC(
--create table <表名>
Sno CHAR(9), --列名 属性
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY (Sno,Cno),
--主码由两个属性构成,必须作为表级完整性进行定义
FOREIGN KEY (Sno) REFERENCES Student(Sno),
--表级完整性约束条件,Sno是外码,被参照表是Student
FOREIGN KEY (Cno)REFERENCES Course(Cno)
--表级完整性约束条件, Cno是外码,被参照表是Course
);
3.索引建立:
ALTER TABLE Student ALTER COLUMN Sage INT;
4.增加约束条件:
ALTER TABLE Course ADD UNIQUE(Cname);
删除Student表
和例题4相同,SQL Server不支持在删除过程中使用CASCADE/RESTRICT关键字
而我们在例题7中,创建了一个引用Student的Sno为外码的SC表,所以我们无法直接删除Student
所以在删除Student前,要先删除SC中对于Sno的约束
使用如下SQL语句查询出表中外键约束名称:
select name
from sys.foreign_key_columns f join sys.objects o on f.constraint_object_id=o.object_id
where f.parent_object_id=object_id('SC')
3.2:各种查询
第三章涉及到的查询语句实在是太多了,所以就把以前写的复习了一下,然后在这里汇总,就不多写了。
※索引的建立、插入元组
https://blog.csdn.net/qq_21331159/article/details/115165279
※查询、ORDER BY子句、聚集函数、GROUP BY 子句
https://blog.csdn.net/qq_21331159/article/details/115413316添加链接描述
※连接查询
https://blog.csdn.net/qq_21331159/article/details/115439855
※嵌套查询(IN、比较运算符、ANY、ALL、EXIST)
https://blog.csdn.net/qq_21331159/article/details/115607879
※集合查询、派生词查询、数据更新、空值的处理、视图
https://blog.csdn.net/qq_21331159/article/details/115613881
四、数据库安全性
1.安全标准
1999年CC V2.1成为国际标准
CC评估等级分为EAL1、EAL2、EAL3、EAL4、EAL5、EAL6和 EAL7共七个等级。

2.数据库安全性控制
计算机系统中,安全措施是一级一级层层设置

- 用户标识鉴定用户身份,合法用户准许进入系统
- 数据库管理系统还要进行存取控制,只允许用户执行合法操作
- 操作系统有自己的保护措施
- 数据以密文形式存储到数据库中
3.自主存取控制方法
定义用户存取权限:定义用户可以在哪些数据库 对象上进行哪些操作
(1)用户权限有两个要素组成:数据库对象和操作类型。在数据库系统中,定义存取权限称为授权(authorization)。

(2)授权:授予与收回
- GRANT语句向用户授予权限
- REVOKE语句收回已经授予用户的权限
①.Grant语句
--GRANT语句格式
GRANT <权限>[,<权限>]...
ON <对象类型> <对象名>[,<对象类型> <对象名>]…
TO <用户>[,<用户>]...
[WITH GRANT OPTION];
---------------------------------------------
其中,with grant option子句为可选属性
指定->可以再授予(指被授予的用户能否授予别人权限)
没有指定->不能再授予
PS:
①对属性列的授权时必须明确指出相应属性列名
②若授予所有用户使用public
③标准SQL在指定基本表时要写table,而T-SQL不写!
②.revoke语句
revoke格式基本与GRANT操作相同,只是把grant换成revoke
--REVOKE语句格式
REVOKE <权限>[,<权限>]...
ON <对象类型> <对象名>[,<对象类型><对象名>]…
FROM <用户>[,<用户>]...[CASCADE | RESTRICT];
③.数据库角色
角色(ROLE):
被命名的一组与数据库操作相关的权限
角色是权限的集合。可以为一组具有相同权限的用户创建一个角色。
优点:简化授权的过程
1.角色的创建
create role <角色名>
2.给角色授权
GRANT <权限>[,<权限>]…
ON <对象类型>对象名
TO <角色>[,<角色>]…
3.将一个角色授予给其他角色或用户
GRANT <角色1>[,<角色2>]…
TO <角色3>[,<用户1>]…
[WITH ADMIN OPTION]
--该语句把角色授予某用户,或授予另一个角色
--授予者是角色的创建者或拥有在这个角色上的ADMIN OPTION
--指定了WITH ADMIN OPTION则获得某种权限的角色或用 户还可以把这种权限授予其他角色
④.强制存取控制(MAC)
每一个数据对象被标以一定的密级
每一个用户也被授予某一个级别的许可证
对于任意一个对象,具有合法许可证的用户才可以存取
在强制存取控制中,数据库管理系统所管理的全部实体被分为主体和客体两大类。
主体是系统中的活动实体
◼数据库管理系统所管理的实际用户
客体是系统中的被动实体
◼文件、基本表、索引、视图
❖两类常用连接运算
◼ 等值连接(equijoin)
❖敏感度标记(Label)
◼ 对于主体和客体,DBMS为它们每个实例(值)指派一个敏感度标记(Label)敏感度标记分成若干级别:
绝密(Top Secret,TS)
机密(Secret,S)
可信(Confidential,C)
公开(Public,P)
TS>=S>=C>=P
主体的敏感度标记称为许可证级别(Clearance Level)
客体的敏感度标记称为密级(Classification Level)
强制存取控制规则
仅当主体的许可证级别大于或等于客体的密级时,该主体才能读相应的客体
仅当主体的许可证级别小于或等于客体的密级时,该主体才能写相应的客体
4.视图机制
把要保护的数据对无权存取这些用户的数据隐藏起来,对数据提供一定程度的安全保护
相当于把用户与数据隔开,让用户只能看到自己权限所能看到的信息,提高了安全性
5.审计
将用户对数据库的所有操作记录进行存储,存储下来的文本就叫做审计日志.
审计员李勇审计日志,可以监控数据库中的各种行为,也可以找出非法存取数据的人、时间和内容
在标准SQL中,我们通过ADUIT语句和NOAUDIT语句可以对审计功能进行修改
audit alter,update
on SC;
noaudit alter,update
on SC;
五、数据库完整性
1.三大完整性
①.实体完整性
关系模型的实体完整性
create table 中用 primary key 定义主键
例:
--在列级定义主码
create table Student(
Sno CHAR(9) PRIMARY KEY,
Sname CHAR(20) NOT NULL,
Ssex CHAR(2), Sage SMALLINT,
Sdept CHAR(20)
);
/*在表级定义主码
create table Student{
Sno CHAR(9),
Sname CHAR(20) NOT NULL,
Ssex CHAR(2), Sage SMALLINT,
Sdept CHAR(20),
primary key(Sno)
};
*/
②.参照完整性
在create table 中用foreign key短语定义哪些列为外码,用references短语指明这些外码参照哪些表的主码
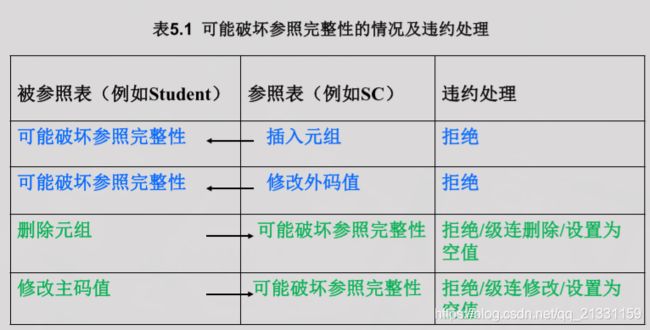
create table SC
(
Sno char(9) not null,
Cno char(4) not null,
Grade smallint,
primary key (Sno,Cno),
foreign key (Sno) references student(Sno)
on delete cascade -- 级联删除SC表中相应的元组
on update cascade, --级联更新SC表中相应的元组
foreign key (Cno) references course(Cno)
on delete no action
--当删除course 表中的元组造成了与SC表不一致时拒绝删除
on update cascade
--当更新course表中的cno时,级联更新SC表中相应的元组
);
③.用户定义的完整性
CREATE TABLE时定义属性上的约束条件
- 列值非空(NOT NULL)
- 列值唯一(UNIQUE)
- 检查列值是否满足一个条件表达式(CHECK)
在CREATE TABLE时可以用CHECK短语定义元组上的约束条件,即元组级的限制
2.触发器(trigger)和存储程序
①.创建trigger:
语法格式:
CREATE TRIGGER <触发器名>
{BEFORE | AFTER} <触发事件> ON <表名> REFERENCING NEW|OLD ROW AS<变量>
FOR EACH {ROW | STATEMENT}
[WHEN <触发条件>]<触发动作体>
--AFTER表示在触发事件的操作执行之后激活触发器
--BEFORE表示在触发事件的操作执行之前激活触发器
❖触发器类型
◼行级触发器(FOR EACH ROW)
◼语句级触发器(FOR EACH STATEMENT)
例如,在例5.11的TEACHER表上创建一个AFTER UPDATE触发器,触 发事件是UPDATE语句:
UPDATE TEACHER
SET Deptno=5; 假设表TEACHER有1000行
如果是语句级触发器,那么执行完该语句后,触发动作只发生1次
如果是行级触发器,触发动作将执行1000次
②.删除触发器:
-- 标准SQL
DROP TRIGGER<触发器名> ON <表名>
-- T-SQL
drop trigger 触发器名;
-- 或者用if exists判断删除,就没有报错了
drop trigger if exists 触发器名;
③.SQL存储过程
1.创建存储过程
CREATE OR REPLACE PROCEDURE 过程名([参数1,参数2,…])
AS <过程化SQL块>;
2.执行存储过程
T-SQL是用exec,标准SQL是call或者perform
CALL/PERFORM PROCEDURE 过程名([参数1,参数2,...]);
3.修改存储过程
ALTER PROCEDURE 过程名1 RENAME TO 过程名2;
4.删除存储过程
drop procedure 过程名;
函数和存储过程的异同
同:都是持久性存储模块
异:函数必须指定返回的类型
六、总结
回顾过来这一个月真的学了很多东西,也尝试着坚持用csdn去写出自己的实验过程,还挺有意思的,不过做的多,做的快,忘的也多,也快。数据库这门课程应该还有不少东西要学,标准SQL这部分肯定随着后面的学习而渐渐的遗忘,还是要多回头看看,别等全忘了再后悔。
对了,趁着还早,看看Android的知识,因为开学就没在看了,之后大作业还要用到,现在让我比较迷茫的是,app该如何与我的数据库连接,看网上还做的还挺麻烦的。
exists语句还是最不明白的地方,得多看看。
“长风破浪会有时,直挂云帆济沧海”。