Windows安装和使用kafka
一、安装kafka
由于kafka依赖jdk和zookeeper,安装kafka之前需要先安装jdk和zookeeper,也可以使用kafka自带的zookeeper。安装jdk可以参考:Windows和Linux安装jdk,此处使用kafka自带的zookeeper,不单独安装。
下面在Windows系统中安装kafka时使用的ip地址是192.168.10.188,这是我自己电脑的ip。
1、下载kafka

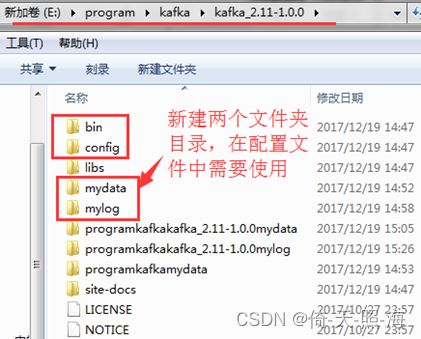
2、修改配置文件
修改zk和kafka的配置文件。
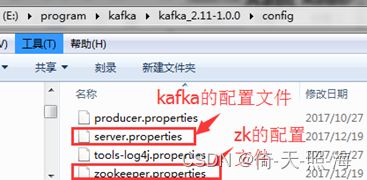
修改zk的配置文件:
配置上面创建的mydata目录,用于保存zookeeper的数据。
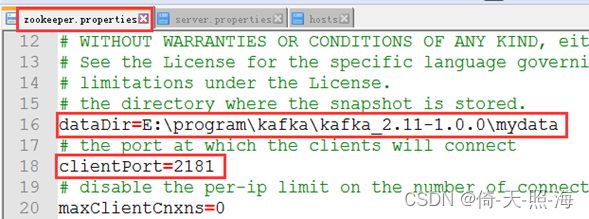
修改kafka的配置文件:
在kafka的配置文件中主要是创建或修改port、host.name、listeners、log.dirs和zookeeper.connect这五个参数。其中port就是kafka的端口号,默认是9092。host.name是当前计算机的ip地址。log.dirs就是上面创建的mylog目录,用于保存kafka的数据。zookeeper.connect参数的作用是kafka连接zookeeper,在下面创建topic时也需要用到此处配置的ip:port,默认配置是zookeeper.connect=localhost:2181。

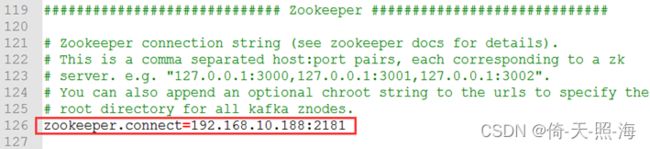
3、启动zk和kafka
启动zk:
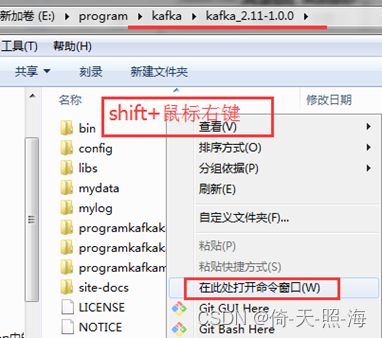
进入到kafka的安装目录kafka_2.11-1.0.0下,同时按住shift和鼠标右键,选择“打开命令窗口”选项,或者win+R输入cmd,打开命令行窗口。
输入启动zk的命令:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties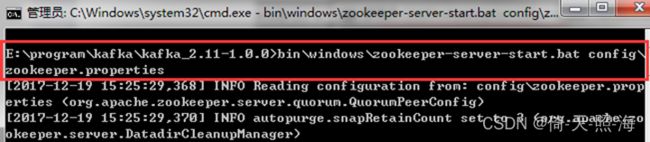
这个dos窗口不要关闭,再次进入到kafka的安装目录kafka_2.11-1.0.0下,同时按住shift和鼠标右键,选择“打开命令窗口”选项,又打开一个命令行窗口,输入启动kafka的命令。
启动kafka:
bin\windows\kafka-server-start.bat config\server.properties4、创建topic
重新打开一个dos窗口,创建topic。
bin\windows\kafka-topics.bat --zookeeper 192.168.10.188:2181 --create --replication-factor 1 --partitions 1 --topic kjTest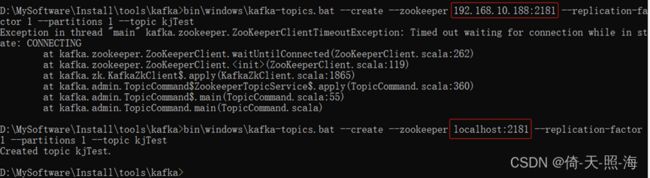
如果在kafka的配置文件中没有配置zookeeper.connect,或者配置的是zookeeper.connect=localhost:2181,创建topic时--zookeeper参数就要使用localhost:2181,2181是zookeeper的默认端口号。
查看创建的topic列表:
bin\windows\kafka-topics.bat --zookeeper 192.168.10.188:2181 --list
__consumer_offsets这个topic是kafka自动创建的,当consumer消费数据之后,consumer就会把offset提交到__consumer_offsets中。
删除topic:
bin\windows\kafka-topics.bat --zookeeper 192.168.10.188:2181 --delete --topic kjTest5、启动producer和consumer
在介绍启动producer和consumer的命令之前,先简单了解一下broker-list、bootstrap-servers和zookeeper。
1.broker:kafka服务端,可以是一个服务器也可以是一个集群。producer和consumer都相当于这个服务端的客户端。
2.broker-list:指定kafka集群中的一个或多个服务器,一般在使用kafka-console-producer.sh的时候,这个参数是必备参数,另外一个必备的参数是topic。
3.bootstrap-servers指的是kafka目标集群的服务器地址,这和broker-list功能一样,不过在启动producer时要求用broker-list,在启动consumer时用bootstrap-servers。
4. zookeeper指的是zk服务器或zk集群的地址。旧版本(0.9以前)的kafka,消费的进度(offset)是写在zk中的,所以启动consumer需要知道zk的地址。后来的版本都统一由broker管理,所以在启动consumer时就用bootstrap-server。
重新打开两个dos窗口,分别启动producer和consumer。
启动producer并输入内容:
bin\windows\kafka-console-producer.bat --broker-list 192.168.10.188:9092 --topic kjTest启动consumer查看消息:
bin\windows\kafka-console-consumer.bat --zookeeper 192.168.10.188:2181 --topic kjTest --from-beginning上面是旧版本的写法,下面是新版本的写法。
bin\windows\kafka-console-consumer.bat --bootstrap-server 192.168.10.188:9092 --topic kjTest --from-beginning
参数--zookeeper 192.168.10.188:2181中的ip和port是zookeeper节点的ip和zookeeper的port,参数--bootstrap-server 192.168.10.188:9092中的ip和port是kafka节点的ip和kafka的port。
6、查看消费者组以及消息是否积压
查看消费者组的命令:
bin\windows\kafka-consumer-groups.bat --bootstrap-server localhost:9092 --list查看消息是否有积压的命令:
bin\windows\kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --group consumer-group-01
上图中GROUP表示消费者组,TOPIC表示消息主题,PARTITION表示分区,CURRENT-OFFSET表示当前消费的消息条数,LOG-END-OFFSET表示kafka中生产的消息条数,LAG表示kafka中有多少条消息还未消费,也就是有多少条积压的消息。
在kafka中,消费者是按批次拉取数据的,每一批次拉取的数据条数是0-n条,每个消费者可以拉取多个分区的数据,但是一个分区的数据只能被同一个消费者组中的一个消费者拉取。如果一个消费者拉取多个分区的数据,那么拉取的这一批次的数据就包含多个分区的数据。消费者处理完这批数据之后,会将offset提交到__consumer_offsets这个topic中,__consumer_offsets(是一个topic)就是用于维护消费者消费到哪条数据offset的,是按照分区粒度维护的,各个分区的offset是互不影响的。例如一个consumer拉取两个分区(p0、p1)的数据,如果p0分区的数据处理完并将offset提交到__consumer_offsets中,而p1分区的数据还未处理完,p1分区的offset还未提交到__consumer_offsets中,此时consumer异常重启,consumer不会再拉取p0分区上次已消费的数据,但是会重新拉取p1分区上次消费但未提交的数据。
7、异常
启动consumer时可能会报下面的异常:
kafka的consumer:java.nio.channels.ClosedChannelException
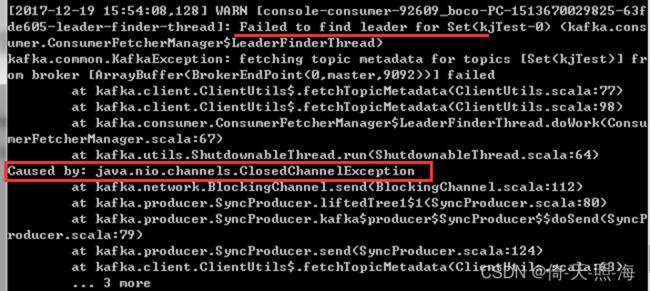
解决方法:
出现以上异常是由于服务器没有做kafka的主机名与ip的映射,
linux的目录是/etc/hosts
windows的目录是C:\Windows\System32\drivers\etc\hosts
二、创建生产者和消费者
上面在Windows中安装好kafka之后,就可以在idea中操作kafka了。
项目结构:
pom.xml文件:
4.0.0
org.example
kafka-study
1.0-SNAPSHOT
org.apache.kafka
kafka_2.12
2.7.0
junit
junit
4.13.2
1、配置kafka相关参数
package com.example.kafka.config;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
/**
* 此处为了简化,直接将kafka配置信息写到代码中,
* 实际项目中需要从application.yml配置文件中读取
*
* @Author: 倚天照海
*/
public class MyKafkaConfig {
/**
* kafka集群地址,多个地址用逗号分隔
*/
private String bootstrapServer = "localhost:9092";
private String topic = "testKafka";
/**
* 消费者组
*/
private String consumerGroupId = "consumer-group-01";
/**
* kafka中保存的是将数据序列化后的字节数组,需要指定key和value的序列化方式
*/
private String keySerializerClass = StringSerializer.class.getName();
private String valueSerializerClass = StringSerializer.class.getName();
/**
* kafka中key和value的反序列化方式
*/
private String keyDeserializerClass = StringDeserializer.class.getName();
private String valueDeserializerClass = StringDeserializer.class.getName();
public String getBootstrapServer() {
return bootstrapServer;
}
public String getTopic() {
return topic;
}
public String getConsumerGroupId() {
return consumerGroupId;
}
public String getKeySerializerClass() {
return keySerializerClass;
}
public String getValueSerializerClass() {
return valueSerializerClass;
}
public String getKeyDeserializerClass() {
return keyDeserializerClass;
}
public String getValueDeserializerClass() {
return valueDeserializerClass;
}
}
2、编写producer
根据公司业务逻辑编写producer,用于生产消息。
package com.example.kafka.producer;
import com.example.kafka.config.MyKafkaConfig;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* kafka生产者
* 创建kafka生产者并生产消息的步骤:
* 1.启动zookeeper和kafka
* 2.创建topic
* 3.启动producer
*
* @Author: 倚天照海
*/
public class MyProducer {
/**
* 1.创建topic:进入到kafka安装目录的bin目录下,执行kafka-topics.sh(Linux系统)或windows\kafka-topics.bat(windows系统)脚本
* Linux系统: bin/kafka-topics.sh --zookeeper 192.168.10.188:2181/kafka --create --replication-factor 2 --partitions 2 --topic testKafka
* windows系统: bin\windows\kafka-topics.bat --zookeeper 192.168.10.188:2181 --create --replication-factor 2 --partitions 2 --topic testKafka
* 2.启动producer
* Linux系统: bin/kafka-console-producer.sh --broker-list 192.168.10.188:9092 --topic testKafka
* windows系统: bin\windows\kafka-console-producer.bat --broker-list 192.168.10.188:9092 --topic testKafka
*/
public void produce() throws ExecutionException, InterruptedException {
MyKafkaConfig kafkaConfig = new MyKafkaConfig();
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaConfig.getBootstrapServer());
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, kafkaConfig.getKeySerializerClass());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, kafkaConfig.getValueSerializerClass());
String topic = kafkaConfig.getTopic();
KafkaProducer producer = new KafkaProducer<>(properties);
doProduce(producer, topic);
}
private void doProduce(KafkaProducer producer, String topic) throws ExecutionException, InterruptedException {
while (true) {
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
ProducerRecord record = new ProducerRecord<>(topic, "item" + j, "price" + i);
Future future = producer.send(record);
RecordMetadata recordMetadata = future.get();
int partition = recordMetadata.partition();
long offset = recordMetadata.offset();
System.out.println("key=" + record.key() + ", value=" + record.value()
+ ", partition=" + partition + ", offset=" + offset);
}
}
}
}
}
3、编写consumer
编写consumer,用于接受消息。
package com.example.kafka.consumer;
import com.example.kafka.config.MyKafkaConfig;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.*;
/**
* @Author: 倚天照海
*/
public class MyConsumer {
public void consume() {
MyKafkaConfig kafkaConfig = new MyKafkaConfig();
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaConfig.getBootstrapServer());
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, kafkaConfig.getKeyDeserializerClass());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, kafkaConfig.getValueDeserializerClass());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, kafkaConfig.getConsumerGroupId());
/**
* ConsumerConfig.AUTO_OFFSET_RESET_CONFIG表示当kafka中未初始化offset或当前offset不存在时,消费者自动重置offset的方式,默认是latest。
* What to do when there is no initial offset in Kafka
* or if the current offset does not exist any more on the server (e.g. because that data has been deleted):
*
* - earliest: automatically reset the offset to the earliest offset
* - latest: automatically reset the offset to the latest offset
* - none: throw exception to the consumer if no previous offset is found for the consumer's group
* - anything else: throw exception to the consumer.
*
*/
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
// 是否开启自动提交,默认开启。自动提交是异步提交,开启自动提交可能会造成数据丢失或重复消费数据
// properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交的间隔时间(多长时间会触发自动提交),默认是5秒
// properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "10000");
// kafka的消费者是按批次拉取数据,该参数是设置一批最多拉取多少条数据
// properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "1000");
List topics = Collections.singletonList(kafkaConfig.getTopic());
KafkaConsumer consumer = new KafkaConsumer<>(properties);
doConsume(consumer, topics);
}
private void doConsume(KafkaConsumer consumer, List topics) {
// 消费者订阅主题消息,多个consumer会动态负载均衡多个分区
// 例如有两个分区,最开始只启动一个consumer,会给这个consumer分配两个分区,它会消费两个分区的数据。
// 然后在同一个消费者组内又启动一个consumer,此时会把第一个consumer的两个分区都撤销,再随机给这两个consumer分别分配一个分区
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection partitions) {
System.out.println("-----------------onPartitionsRevoked撤销的分区是:---------------");
Iterator iterator = partitions.iterator();
while (iterator.hasNext()) {
TopicPartition next = iterator.next();
System.out.println(next.partition());
}
}
@Override
public void onPartitionsAssigned(Collection partitions) {
System.out.println("-----------------onPartitionsAssigned分配的分区是:---------------");
Iterator iterator = partitions.iterator();
while (iterator.hasNext()) {
TopicPartition next = iterator.next();
System.out.println(next.partition());
}
}
});
while (true) {
// 消费者拉取消息,设置等待时间,按批次拉取,一批拉取的数据是0-n条,每次poll是同时拉取多个分区的数据
ConsumerRecords consumerRecords = consumer.poll(Duration.ofMillis(0));
while (!consumerRecords.isEmpty()) {
// 每次拉取数据的条数
System.out.println("----------------consumerRecords.count------------------" + consumerRecords.count());
// 方式一:按分区分别处理每个分区的数据
Set partitions = consumerRecords.partitions();
// kafka中consumer是按照分区粒度提交维护offset的,将offset提交到__consumer_offsets中
// 如果关闭自动提交,使用手动提交offset,则有三种粒度同步提交offset:
// 1.按每条消息粒度同步提交offset
// 2.按每个分区粒度同步提交offset
// 3.按poll的一批数据粒度同步提交offset
// for (TopicPartition topicPartition : partitions) {
// // 分别获取每个分区的数据记录,且分区内的数据是有序的,可以用多线程并行处理每个分区的数据
// List> partitionRecords = consumerRecords.records(topicPartition);
// for (ConsumerRecord record : partitionRecords) {
// // 一个消费者可以消费多个分区,一个分区只能被同一个消费者组中的一个消费者消费
// int partition = record.partition();
// long offset = record.offset();
// // TODO 获取数据处理复杂的业务逻辑,最终将数据持久化到数据库中
// System.out.println("key=" + record.key() + ", value=" + record.value()
// + ", partition=" + partition + ", offset=" + offset);
//
// // 粒度1.按每条消息粒度同步提交offset
// /*OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(offset);
// Map map = new HashMap<>();
// map.putIfAbsent(topicPartition, offsetAndMetadata);
// consumer.commitSync(map);*/
// }
// // 粒度2.按每个分区粒度同步提交offset
// // 获取分区最后一条消息记录的offset,将offset提交到__consumer_offsets中
// long offset = partitionRecords.get(partitionRecords.size() - 1).offset();
// OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(offset);
// Map map = new HashMap<>();
// map.putIfAbsent(topicPartition, offsetAndMetadata);
// consumer.commitSync(map);
// }
// 粒度3.按poll的一批数据粒度同步提交offset
// consumer.commitSync();
// 方式二:不区分分区,将多个分区的数据放在一起逐条处理
for (ConsumerRecord record : consumerRecords) {
// 一个消费者可以消费多个分区,一个分区只能被同一个消费者组中的一个消费者消费
int partition = record.partition();
long offset = record.offset();
// TODO 获取数据处理复杂的业务逻辑,最终将数据持久化到数据库中
System.out.println("key=" + record.key() + ", value=" + record.value()
+ ", partition=" + partition + ", offset=" + offset);
}
consumer.commitSync();
}
}
}
}
从kafka中消费数据,经过一系列逻辑处理之后将数据写入到数据库中,开启自动提交可能会造成数据丢失或重复消费数据。自动提交是异步提交,异步提交是指consumer提交offset与将数据持久化到数据库是异步的。
1.数据丢失:若开启自动提交,且自动提交的间隔时间(默认是5秒)到了,消费者会将拉取的这批数据的offset保存到_consumer_offsets中。但是5s内由于业务太过复杂,数据没有完全持久化,消费者就把offset提交了,若此时消费端consumer挂了,等消费端重启之后,会根据自身维护的offset拉取新的数据,不会重新拉取之前已消费的数据,因为这些数据的offset已经被提交了。
2.重复消费:若开启自动提交,且自动提交的间隔时间(默认是5秒)还未到,经过业务逻辑处理后将数据写入到了数据库中,此时消费者还未将拉取的这批数据的offset保存到_consumer_offsets中,若此时消费端consumer挂了,等消费端重启之后,会根据自身维护的offset拉取新的数据,会重新拉取之前已消费的数据,因为这些数据的offset还未被提交。
4、编写测试类
package com.example.kafka;
import com.example.kafka.consumer.MyConsumer;
import com.example.kafka.producer.MyProducer;
import org.junit.Test;
import java.util.concurrent.ExecutionException;
/**
* @Author: 倚天照海
*/
public class Main {
MyProducer myProducer = new MyProducer();
MyConsumer myConsumer = new MyConsumer();
@Test
public void produceTest() {
produceData();
}
@Test
public void consumeTest() {
consumeData();
}
private void produceData() {
// MyProducer myProducer = new MyProducer();
try {
myProducer.produce();
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
}
private void consumeData() {
// MyConsumer myConsumer = new MyConsumer();
myConsumer.consume();
}
}
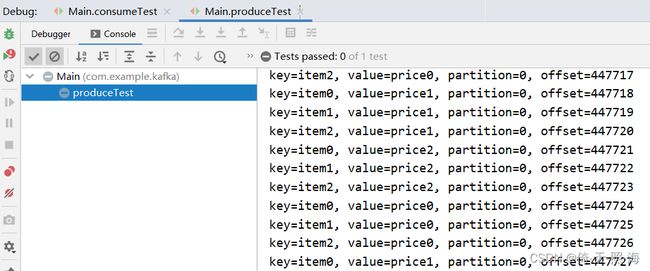
测试结果:
生产者:
消费者:
Kafka中消息积压情况:
![]()