Java面经-MySQL数据库
MySQL数据库
1.事务
开启事务用 start transaction 回滚 roll back 提交 commit
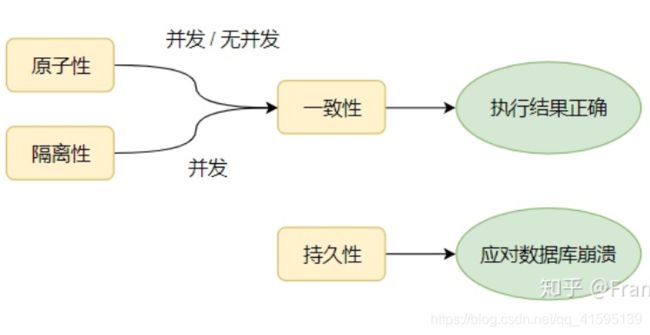
数据库事务的ACID特性
1.原子性
原子性指操作要么全部成功,要么全部失败
2.一致性
事务操作保证了两个以上操作的一致性,如打钱,一个增加200,另一个就要减少200保持一致
3.隔离性
隔离性是多个用户并发访问数据库时,数据库为每个用户开启的事务之间互不影响,相互隔离
4.持久性
一旦事务提交,就会被永久保存在数据库中,即写入硬盘持久化
2.数据库中的范式
范式之间是包含关系,即越往上要求越高
第一范式:属性不可分–确保每列保持原子性
第二范式:属性完全依赖于主键–确保表中每列都和主键相关
第三范式:属性不依赖于其他非主属性–确保每列都和主键列直接相关,而不是间接相关
3.并发一致性问题
脏读
如果数据库处于读未提交级别时,一个事务就可以读取到另一个事务中还未提交的数据,一旦另一个事务进行了回滚,那么这个事务就发生了脏读
不可重复读
如果数据库处于读已提交级别,则可能发生不可重复读,即A事务在B事务未提交之前读取了变量a,而又在B事务提交后又读取了变量A,此时发现A前后两次读取到的不一样,那么A事务就迷茫了,到底哪个是正确的呢,这就是不可重复读。
幻读
如果数据库处于可重复读级别,就可能发生幻读,幻读是指当A事务在count()聚合函数或select操作时,B事务对数据进行了insert 或delete操作,那么B事务提交后,表中数据增加或减少了,这就会让B事务迷茫了,怎么回事,明明说好是10个数据,怎么会读出来多一个,这就是幻读
数据库隔离级别
1.串行化(Serializable)
最安全的数据库读取操作, 通过锁来保证事务并发的安全性
2.可重复读
处于可重复读级别,数据可能会发生幻读问题
3.读已提交
处于读已提交级别,数据可能发生幻读和不可重复读
4.读未提交
处于此级别,数据没有安全性可言,脏读,幻读,不可重复读都有可能发生
存储引擎
常用的MySQL存储引擎有两种,一种是InnoDB,另一种是MyISAM。
对于存储引擎的选择,存储引擎是针对的表级进行的,那么每个表的存储引擎都可以不一样,根据表特性,是否需要事务,是否大量读写还是只进行读操作。
MyISAM和InnoDB引擎区别
MyISAM不支持外键,而InnoDB支持
MyISAM更加轻量级,采用表级锁,读数据库效率很高,所以如果是只读数据库表且数量很大,那么使用MyISAM更好
InnoDB支持事务,采用的是行级锁,所以要事务支持的话,就要选用InnoDB,以支持并发操作
索引
1.对于非常小的表,全表扫描比建立索引更高效
2.对于中到大型表,索引更有效
3.对于特大型表,索引的建立与维护要更大的代价,所以这种情况下,需要用到一种技术——分库分表来进行数据表的简化
实现索引的方法
B Tree原理
通过B树来进行索引的建立,存储索引数据
B+ Tree一般在数据库系统或文件系统中使用B+ Tree结构都在经典B+Tree基础上进行了优化,在叶子节点增加了顺序访问指针,做这个优化的目的是为了提高取件访问性能
用B树作为索引结构原因:
1.更少的索引次数:
平衡树检索数据的时间复杂度等于树高h,而树高大致为O(h),红黑树的树高h要比B树大很多,因此检索次数也会更多
2.利用计算机预读特性
利用局部性原理:当一个数据被用到时,其附近数据也会被使用,预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,因此速度很快
索引特性
可以加快数据库的检索速度
降低数据库插入、修改、删除等维护的速度
只能创建在表上,不能创建到视图上
既可以直接创建又可以间接创建
可以在优化隐藏中使用索引
使用查询处理器执行SQL语句,在一个表上,一次只能使用一个索引
索引失效
如果条件中有or,即使其中有条件带索引也不会使用 (这就是为什么尽量少使用or的原因)
对于多列索引,不是使用的第一部分,则不会使用索引
like查询是以%开头
如果列类型是字符串,那一定要在条件中使用引号引起来,否则不会使用索引
如果MySQL估计使用全表扫秒比使用索引快,则不适用索引。
什么情况下建立索引
为经常出现在关键字order by、group by、distinct后面的字段,建立索引。
在union等集合操作的结果集字段上,建立索引。其建立索引的目的同上。
为经常用作查询选择 where 后的字段,建立索引。
在经常用作表连接 join 的属性上,建立索引。
考虑使用索引覆盖。对数据很少被更新的表,如果用户经常只查询其中的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描改变为索引的扫描。