【论文阅读】Self-supervised Learning: Generative or Contrastive
Abstract
研究了在计算机视觉、自然语言处理和图形学习中用于表示的新的自监督学习方法。全面回顾了现有的实证方法,并根据其目的将其归纳为三大类:生成性、对比性和生成性对比(对抗性)。进一步收集了关于自我监督学习的相关理论分析,以对自我监督学习为什么有效提供更深入的思考。最后,简要讨论了自我监督学习的开放问题和未来方向。
Introduction

自监督学习可以看作无监督学习的一个分支,因为不涉及手工label,狭义地说,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习旨在恢复,这仍然处于监督环境的范式中。
有监督学习是数据驱动型的,严重依赖昂贵的手工标记、虚假相关性和对抗性攻击。我们希望神经网络能用更少的标签、更少的样本和更少的试验来学习更多。自注意力话大量的注意力在数据有效性和生成能力。在2020年AAAI的受邀演讲中,图灵奖得主Yann LeCun将自我监督学习描述为“机器为任何观察到的部分预测其输入的任何部分”。
自监督学习的特征可以概括为:
- 通过使用半自动的过程从数据本身获得label
- 从数据的其他部分预测这一部分
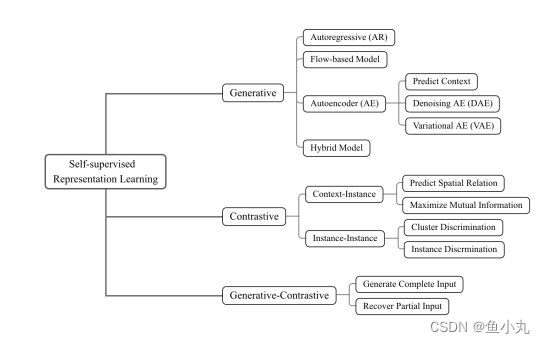
上图是这个综述文章的分类,生成性、对比性和生成性对比(对抗性);以及每一个类别下的典型的方法。
自监督学习的动机
为了解决基本的OOD(泛化能力差,简单的多层感知器泛化能力非常差(总是假设分布外(OOD)样本呈线性关系))和生成的问题。
自我监督学习的成功最关键的一点是,它找到了一种方法来利用大数据时代可用的大量未标记数据。
自监督学习可以分为三大类:
- 生成式:训练一个encoder去编码输入x到明确的向量z,和一个解码器去从z重建x。(eg:the cloze test, graph generation)
- 对比式:训练一个encoder去编码输入到一个明确的向量z,去衡量相似性。(eg:mutual information maximizetion.instance discrimination)
- 生成对比式(对抗式):训练一个encoder-decoder去省城fakesamples 和一个鉴别器去区分真实样本和生成样本。(eg:GAN)
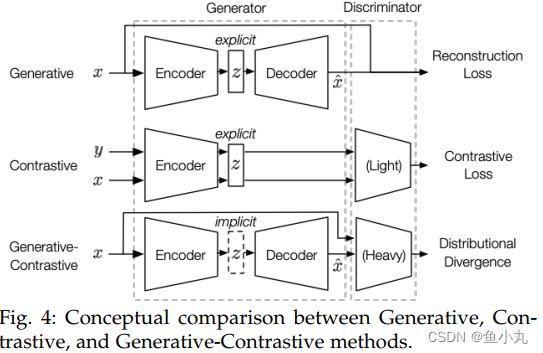
这三个类别不同在于架构和目标函数的不同。
不同点:
- 对于潜在分布z,在声称是和对比式方法中,z是明确的经常被应用于下游任务,而GAN中,z是隐式建模的。
- 对于鉴别器。这个生成的方式没有鉴别器,然而GAN和对比网络有。对比式的网络相对来说鉴别器有更少的参数。 (e.g., a multi-layer perceptron with 2-3 layers) than GAN (e.g., a standard ResNet [53])
一张自监督学习综述的图
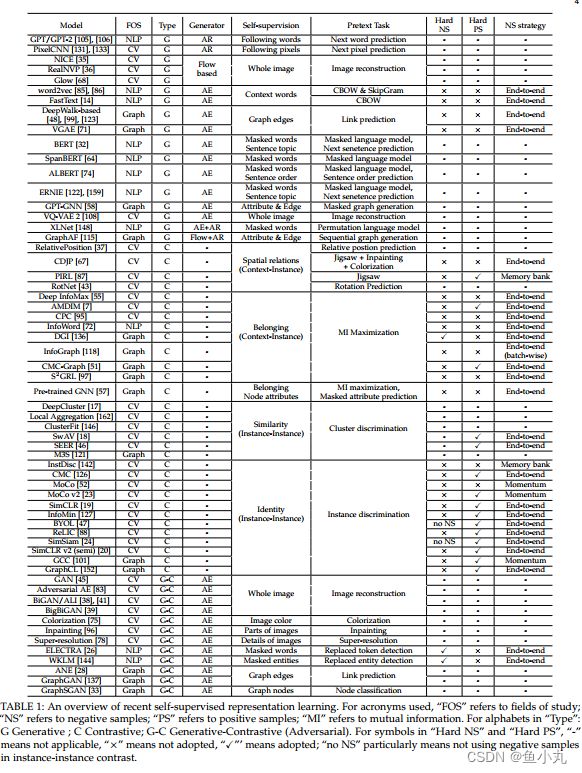
生成式的自监督学习
AR
在计算机视觉中,PixelRNN和PixelCNN,总体思路是利用自回归访华逐像素的对图像进行建模。对于2D图像,自回归模型只能更具特定方向来分解改了,所以在CNN架构中采用了掩模滤波器。基于PixelCNN, WaveNet[130]——一种原始音频生成模型被提出。为了处理长期的时间依赖性,作者开发了扩展的因果卷积来改善接受野。此外,门控残差块和跳过连接被用来增强更好的表达能力。
自回归模型的优点是可以很好地对上下文依赖性进行建模。然而,AR模型的一个缺点是,每个位置的令牌只能从一个方向访问其上下文。
Flow-based Model
基于流的模型的目标是从数据中估计复杂的高维密度函数p(x)。
AE
灵活。AE由一个编码器网络h = f e n c ( x ) f_{enc}(x) fenc(x)和一个解码器网络x’ = f d e c ( x ) f_{dec}(x) fdec(x)(h)组成。AE的目标是使x和x’尽可能相似(如通过均方误差)。可以证明线性自编码器与PCA方法相对应。
除了基础的AE,还有CPM,Denoising AE Model,Variational AE Model。
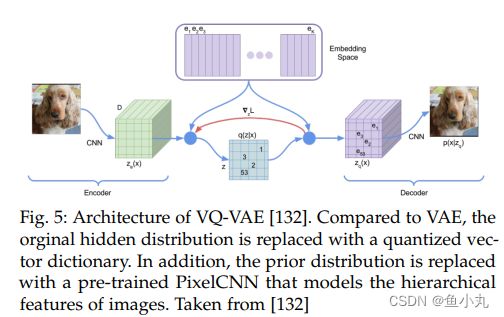
VQ-VAE的体系结构。与VAE相比,原始的隐藏分布被量化的矢量字典所取代。此外,先前的分布被预先训练的PixelCNN取代,该PixelCNN对图像的分层特征进行建模。
Hybird Fenerative Models
包括结合AR和AE的模型、结合AE和Flow-based Model。
Pros and Cons
优点:不假设下游任务的情况下,重建原始图像分布的能力。现有的生成任务严重依赖生成式自监督学习。
缺点:
- 生成子监督学习在一些分类情境下,相比于对比学习有很少的竞争力。因为对比学习的目标函数天然地符合分类学习的目标。
- 生成式模型逐点的特性使它有一些内在的缺点:敏感性和保守性分布,低级抽象的目标不适合一高级抽象目标的分类任务。
作为一种相反的方法,生成对比式自我监督学习放弃了逐点目标。它转向更健壮的分布式匹配目标,并更好地处理数据流形中的高级抽象挑战。
对比自监督学习
分为两类:上下文-实例对比、实例-实例对比。
上下文-实例对比
注重于对局部特征和全局上下文语义的对比。
例如:Predict Relative Position
注重于学习局部部分之间的相对位置。全局的上下位作为一个隐式的需求。

Maximize Mutual Information
MI专注于学习局部部分和全局乡下问之间的直接的归属关系,局部位置之间的关系被忽略了。
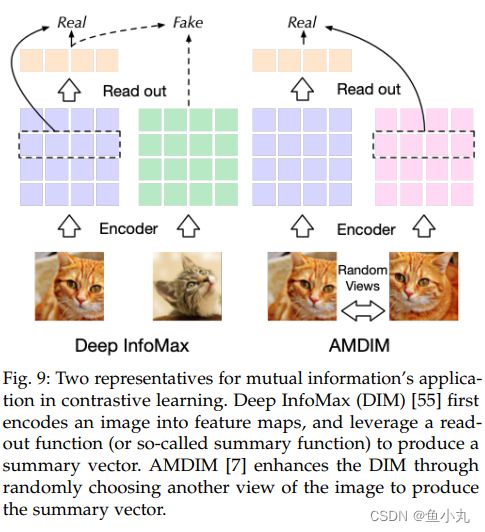
实例-实例之间的对比
度量学习的一个重要重点是在提高负采样效率的同时执行硬正采样。它们可能在基于MI的模型的成功中发挥着更关键的作用。
作为替代,实例-实例对比学习抛弃了MI,直接研究不同样本的实例级局部表示之间的关系。对于广泛的分类任务,实例级表示比上下文级表示更为重要。
例如:Cluster Discrimination
Instance Discrimination(实例判别)
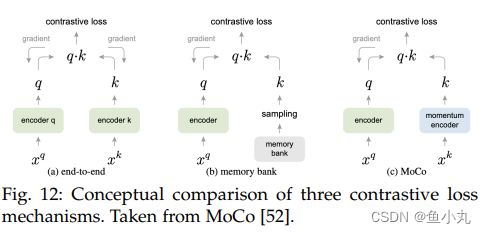
第一种是端到端的范式,有两个编码器,两个编码器都进行梯度更新,依赖于大的batchsize提供更多的负样本。第二个是有memory bank的方式,有一个编码器,只对这一个编码器进行梯度更新,负样本从memory bank中提取,每次都更新memory bank中随机位置的特征,特征一致性不好,每一个batchsize,模型都会更新,但是memory bank只更新一部分。正样本和负样本进行对比的时候,正样本是当前的encoder产生的,负样本不知道是什么时候的encoder产生的。第三个Moco使用动量编码器,在第一个基础上把右边的编码器改成动量编码器,并且采用队列形式的字典。把对比学习当作动态的字典查询问题。

SIMLR采用了多种数据增强和一个proj在最后加一个非线性层,获得了比Moco高的效果。
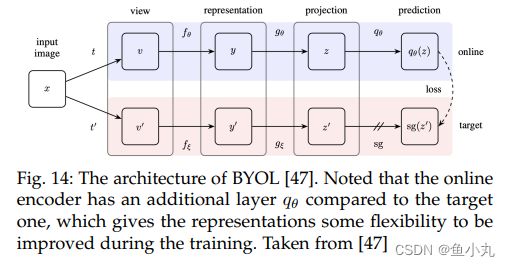
BYOL不用负样本,获得了很好的效果。
半监督自我训练的自我监督对比预训练
Chen等人[20]的SimCLR v2支持了上述结论,表明只有10%的原始ImageNet标签,通过联合预训练和自我训练,ResNet-50可以超过监督的。他们提出了一个三步框架:
- 像SimCLR v1一样进行自我监督的预训练,并进行一些小的架构修改和更深的ResNet.
- 仅使用1%或10%的原始ImageNet标签微调最后几层。
- 使用微调后的网络作为教师模型,在未标记的数据上产生标签,以训练较小的学生ResNet-50。知识蒸馏
优点和缺点
优点:对比学习没有解码器,因此对比学习是轻量级的,在下游鉴别任务中表现很好。
存在的问题:
- 对比学习在NLP领域没有取得令人信服的结果。现在大多数在BERT上进行微调。。很少有算法被提出在预训练阶段应用对比学习。由于大多数语言理解任务都是分类的,因此对比语言预训练方法应该比目前的生成语言模型更好。
- 采样有效性。负抽样对于大多数对比学习是必须的,但这个过程通常是棘手的,有偏见的,耗时的。不清楚负样本在对比学习中的作用。
- 数据增强,数据增强能提高对比学习的性能。但它为什么以及如何起作用的理论仍然相当模糊。这阻碍了它在其他领域的应用,比如NLP和图学习,这些领域的数据是离散和抽象的。
生成对比学习
总之,对抗性方法吸收了生成法和对比法的优点,同时也存在一些缺点。在我们需要适应隐式分布的情况下,这是一个更好的选择。
使用完整输入
通过部分输入恢复
图像着色、图像修复、超分辨率
预训练语言模型
图学习
领域适应和多模态表示
优点和缺点
优点:生成-对比(对抗性)自监督学习在图像生成、转换和处理方面特别成功
缺点:
- 在NLP和图领域应用受限。
- 容易坍塌
- 不是用于特征提取