2 - 集合框架(上)
1. 总览
集合就是用于存储多个数据的容器。
相对于具有相同功能的数组来说,集合的长度可变会更加灵活方便

1.1 List
List 的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作
1) ArrayList
基本操作 CRUD
// 创建一个集合
ArrayList list = new ArrayList();
//添加元素
list.add("cpp");
list.add("java");
list.add("go");
//遍历集合 for 循环
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
// 删除元素 通过下标指定的删除
list.remove(1); //后面会整体前移
// 遍历集合 for each
for (String s : list) {
System.out.println(s);
}
// 修改元素
list.set(1, "php");
特征:
- ArrayList 是由数组实现的,支持随机存取,也就是可以通过下标直接存取元素
- 从尾部插入和删除元素会比较快捷,从中间插入和删除元素会比较低效,因为涉及到数组元素的复制和移动
- 容量不足时会自动扩容,因此当元素非常庞大的时候,效率会比较低
2)LinkedList
CRUD,从使用的角度看与ArrayList 几乎没什么差别
// 创建一个集合
LinkedList list = new LinkedList();
// 添加元素
list.add("cpp");
list.add("java");
list.add("php");
// 遍历集合 for 循环
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
// 删除元素
list.remove(1);
// 遍历集合
for (String s : list) {
System.out.println(s);
}
// 修改元素
list.set(1, "go");
// 遍历集合
for (String s : list) {
System.out.println(s);
} 特征:
- LinkedList 是由双向链表实现的,不支持随机存取,只能从一端开始遍历,直到找到需要的元素后返回
- 任意位置插入和删除元素都很方便,因为只需要改变前一个节点和后一个节点的引用即可
- 因为每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比 ArrayList 多一些
3)Vector 和 Stack
ArrayList 和 Vector 非常相似,只不过 Vector 是线程安全的,导致执行执行效率会比较低,所以现在已经很少用
//Vector 的方法源码
public synchronized boolean add(E e) {
elementData[elementCount++] = e;
return true;
}
如果不需要线程安全,建议使用ArrayList代替Vector
Stack 是 Vector 的一个子类,本质上也是由动态数组实现的,只不过还实现了先进后出的功能(在 get、set、add 方法的基础上追加了 pop「返回并移除栈顶的元素」、peek「只返回栈顶元素」等方法),所以叫栈
由于 Stack 执行效率比较低(方法上同样加了 synchronized 关键字),就被双端队列 ArrayDeque 取代了
1.2 Set
特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作
1)HashSet
HashSet 本质是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作
HashSet 并不常用,需要按照顺序存储一组元素,那么ArrayList和LinkedList可能更适合;如果需要存储键值对并根据键进行查找,那么HashMap可能更适合
CRUD
// 创建一个新的HashSet
HashSet set = new HashSet<>();
// 添加元素
set.add("cpp");
set.add("java");
set.add("go");
// 输出HashSet的元素个数
System.out.println("HashSet size: " + set.size()); // output: 3
// 判断元素是否存在于HashSet中
boolean containsWanger = set.contains("cpp");
System.out.println("Does set contain 'cpp'? " + containsWanger); // output: true
// 删除元素
boolean removeWanger = set.remove("go");
System.out.println("Removed 'go'? " + removeWanger); // output: true
// 修改元素,需要先删除后添加
boolean removeChenmo = set.remove("cpp");
boolean addBuChenmo = set.add("c++");
System.out.println("Modified set? " + (removeChenmo && addBuChenmo)); // output: true
// 输出修改后的HashSet
System.out.println("HashSet after modification: " + set); // output: [c++, java] 2)LinkedHashSet
LinkedHashSet 虽然继承自 HashSet,其实是由 LinkedHashMap 实现
CRUD
LinkedHashSet set = new LinkedHashSet<>();
// 添加元素
set.add("java");
set.add("cpp");
set.add("go");
// 删除元素
set.remove("go");
// 修改元素
set.remove("cpp");
set.add("c++");
// 查找元素
boolean hasJava = set.contains("java");
System.out.println("set包含java吗?" + hasJava);
LinkedHashSet是一种基于哈希表实现的Set接口,它继承自HashSet,并且使用链表维护了元素的插入顺序。
因此,它既具有HashSet的快速查找、插入和删除操作的优点,又可以维护元素的插入顺序
3)TreeSet
TreeSet 是一种基于红黑树实现的有序集合,它实现了 SortedSet 接口,可以自动对集合中的元素进行排序。按照键的自然顺序或指定的比较器顺序进行排序
CRUD
// 创建一个 TreeSet 对象
TreeSet set = new TreeSet<>();
// 添加元素
set.add("java");
set.add("cpp");
set.add("go");
System.out.println(set); // [cpp, go, java]
// 删除元素
set.remove("go");
System.out.println(set); // [cpp, java]
// 修改元素:TreeSet 中的元素不支持直接修改,需要先删除再添加
set.remove("cpp");
set.add("c++");
System.out.println(set); // [c++, java]
// 查找元素
System.out.println(set.contains("c++")); // 输出 true
System.out.println(set.contains("go")); // 输出 false
TreeSet 不允许插入 null 元素,否则会抛出 NullPointerException 异常
1.3 Queue
队列,通常遵循先进先出(FIFO)的原则,新元素插入到队列的尾部,访问元素返回队列的头部
1)ArrayDeque
ArrayDeque 是一个基于数组实现的双端队列,为了满足可以同时在数组两端插入或删除元素的需求,数组必须是循环的,也就是说数组的任何一点都可以被看作是起点或者终点
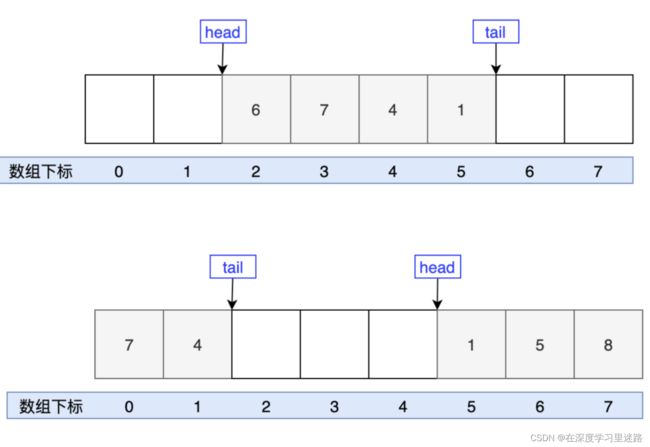
head 指向队首的第一个有效的元素,tail 指向队尾第一个可以插入元素的空位,因为是循环数组,所以 head 不一定从是从 0 开始,tail 也不一定总是比 head 大
CRUD
// 创建一个ArrayDeque
ArrayDeque deque = new ArrayDeque<>();
// 添加元素
deque.add("java");
deque.add("cpp");
deque.add("go");
// 删除元素
deque.remove("go");
// 修改元素
deque.remove("cpp");
deque.add("c++");
// 查找元素
boolean hasJava = deque.contains("Java");
System.out.println("deque包含Java吗?" + hasJava); 2)LinkedList
LinkedList 实现了 Deque 接口,可以作为队列来使用
LinkedList 同时实现了 Stack、Queue、PriorityQueue 的所有功能
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
{}
CRUD
// 创建一个 LinkedList 对象
LinkedList queue = new LinkedList<>();
// 添加元素 是添加到队尾
queue.offer("java");
queue.offer("cpp");
queue.offer("go");
System.out.println(queue); // [java, cpp, go]
// 删除元素
queue.poll();
System.out.println(queue); // [cpp, go]
// 修改元素:LinkedList 中的元素不支持直接修改,需要先删除再添加
String first = queue.poll();
queue.offer("c++");
System.out.println(queue); // [go, c++]
// 查找元素:LinkedList 中的元素可以使用 get() 方法进行查找
System.out.println(queue.get(0)); // go
System.out.println(queue.contains("go")); // true
// 查找元素:使用迭代器的方式查找陈清扬
// 使用迭代器依次遍历元素并查找
Iterator iterator = queue.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("c++")) {
System.out.println("找到了:" + element); //找到了:c++
break;
}
}
区别与选择:
- 底层实现方式不同:LinkedList 是基于链表实现的,而 ArrayDeque 是基于数组实现的。
- 随机访问的效率不同:由于底层实现方式的不同,LinkedList 对于随机访问的效率较低,时间复杂度为 O(n),而 ArrayDeque 可以通过下标随机访问元素,时间复杂度为 O(1)。
- 迭代器的效率不同:LinkedList 对于迭代器的效率比较低,因为需要通过链表进行遍历,时间复杂度为 O(n),而 ArrayDeque 的迭代器效率比较高,因为可以直接访问数组中的元素,时间复杂度为 O(1)。
- 内存占用不同:由于 LinkedList 是基于链表实现的,它在存储元素时需要额外的空间来存储链表节点,因此内存占用相对较高,而 ArrayDeque 是基于数组实现的,内存占用相对较低。
因此,在选择使用 LinkedList 还是 ArrayDeque 时,需要根据具体的业务场景和需求来选择。
如果需要在双向队列的两端进行频繁的插入和删除操作,并且需要随机访问元素,可以考虑使用 ArrayDeque;如果需要在队列中间进行频繁的插入和删除操作,可以考虑使用 LinkedList。
3)PriorityQueue
PriorityQueue 是一种优先级队列,它的出队顺序与元素的优先级有关,执行 remove 或者 poll 方法,返回的总是优先级最高的元素
实现优先级,就需要实现 Comparable 接口或者 Comparator 接口
通过实现 Comparator 接口按照年龄姓名排序的优先级队列
import java.util.Comparator;
import java.util.PriorityQueue;
class Student {
private String name;
private int chineseScore;
private int mathScore;
public Student(String name, int chineseScore, int mathScore) {
this.name = name;
this.chineseScore = chineseScore;
this.mathScore = mathScore;
}
public String getName() {
return name;
}
public int getChineseScore() {
return chineseScore;
}
public int getMathScore() {
return mathScore;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", 总成绩=" + (chineseScore + mathScore) +
'}';
}
}
class StudentComparator implements Comparator {
@Override
public int compare(Student s1, Student s2) {
// 比较总成绩
return Integer.compare(s2.getChineseScore() + s2.getMathScore(),
s1.getChineseScore() + s1.getMathScore());
}
}
public class PriorityQueueComparatorExample {
public static void main(String[] args) {
// 创建一个按照总成绩排序的优先级队列 比较器是一个参数
PriorityQueue queue = new PriorityQueue<>(new StudentComparator());
// 添加元素
queue.offer(new Student("王二", 80, 90));
System.out.println(queue);
queue.offer(new Student("陈清扬", 95, 95));
System.out.println(queue);
queue.offer(new Student("小驼铃", 90, 95));
System.out.println(queue);
queue.offer(new Student("沉默", 90, 80));
while (!queue.isEmpty()) {
System.out.print(queue.poll() + " ");
}
}
}
输出可以看到 学生的总成绩由高到低进行了排序
[Student{name='王二', 总成绩=170}]
[Student{name='陈清扬', 总成绩=190}, Student{name='王二', 总成绩=170}]
[Student{name='陈清扬', 总成绩=190}, Student{name='王二', 总成绩=170}, Student{name='小驼铃', 总成绩=185}]
Student{name='陈清扬', 总成绩=190} Student{name='小驼铃', 总成绩=185} Student{name='沉默', 总成绩=170} Student{name='王二', 总成绩=170}
1.4 Map
Map 保存的是键值对,键要求保持唯一性,值可以重复
1)HashMap
HashMap 实现了 Map 接口,可以根据键快速地查找对应的值——通过哈希函数将键映射到哈希表中的一个索引位置,从而实现快速访问,是无序的
CRUD
// 创建一个 HashMap 对象
HashMap hashMap = new HashMap<>();
// 添加键值对
hashMap.put("张三", "zhangshan");
hashMap.put("李四", "lisi");
hashMap.put("王二", "wanger");
// 获取指定键的值
String value1 = hashMap.get("张三");
System.out.println("张三对应的值为:" + value1);
// 修改键对应的值
hashMap.put("张三", "zhang_shan");
String value2 = hashMap.get("张三");
System.out.println("修改后张三对应的值为:" + value2);
// 删除指定键的键值对
hashMap.remove("王二");
// 遍历 HashMap
for (String key : hashMap.keySet()) {
String value = hashMap.get(key);
System.out.println(key + " 对应的值为:" + value);
}
2)LinkedHashMap
需要一个有序的Map,就要用到 LinkedHashMap;它使用链表来记录插入/访问元素的顺序,维持了键值对的插入顺序
LinkedHashMap 可以看作是 HashMap + LinkedList 的合体,它使用了哈希表来存储数据,又用了双向链表来维持顺序
// 创建一个 LinkedHashMap,
LinkedHashMap linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("123", "321");
linkedHashMap.put("456", "654");
linkedHashMap.put("789", "987");
// 遍历 LinkedHashMap
for (String key : linkedHashMap.keySet()) {
String value = linkedHashMap.get(key);
System.out.println(key + " 对应的值为:" + value);
}
3)TreeMap
TreeMap 实现了 SortedMap 接口,可以自动将键按照自然顺序或指定的比较器顺序排序,并保证其元素的顺序。内部使用红黑树来实现键的排序和查找
// 创建一个 TreeMap 对象
Map treeMap = new TreeMap<>();
// 向 TreeMap 中添加键值对
treeMap.put("c", "cat");
treeMap.put("a", "apple");
treeMap.put("b", "banana");
// 遍历 TreeMap
for (Map.Entry entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
/* 输出为
a: apple
b: banana
c: cat
*/
CRUD
// 创建一个 TreeMap 对象
Map treeMap = new TreeMap<>();
// 向 TreeMap 中添加键值对
treeMap.put("沉默", "cenzhong");
treeMap.put("王二", "wanger");
treeMap.put("陈清扬", "chenqingyang");
// 查找键值对
String name = "沉默";
if (treeMap.containsKey(name)) {
System.out.println("找到了 " + name + ": " + treeMap.get(name));
} else {
System.out.println("没有找到 " + name);
}
// 修改键值对
name = "王二";
if (treeMap.containsKey(name)) {
System.out.println("修改前的 " + name + ": " + treeMap.get(name));
treeMap.put(name, "newWanger");
System.out.println("修改后的 " + name + ": " + treeMap.get(name));
} else {
System.out.println("没有找到 " + name);
}
// 删除键值对
name = "陈清扬";
if (treeMap.containsKey(name)) {
System.out.println("删除前的 " + name + ": " + treeMap.get(name));
treeMap.remove(name);
System.out.println("删除后的 " + name + ": " + treeMap.get(name));
} else {
System.out.println("没有找到 " + name);
}
// 遍历 TreeMap
for (Map.Entry entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
2. ArrayList 详解
ArrayList 实现了 List 接口,并且是基于数组实现的
数组的大小是固定的,一旦创建的时候指定了大小,就不能再调整了。也就是说,如果数组满了,就不能再添加任何元素了。ArrayList 在数组的基础上实现了自动扩容,并且提供了比数组更丰富的预定义方法(各种增删改查)
2.1 创建 ArrayList
ArrayList alist = new ArrayList();
这样就可以创建,也可以简化为:
List alist = new ArrayList<>(); 此时会调用无参构造器创建一个空的数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//常量DEFAULTCAPACITY_EMPTY_ELEMENTDATA的值为 {}如果确定 ArrayList 中元素的个数,在创建的时候还可以指定初始大小
List alist = new ArrayList<>(20); 知道初始大小后进行指定大小,可以避免后续进行不必要的扩容
2.2 添加元素
alist.add("zhangsan");
查看 add() 都干了啥?
/**
* 将指定元素添加到 ArrayList 的末尾
* @param e 要添加的元素
* @return 添加成功返回 true
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确保 ArrayList 能够容纳新的元素
elementData[size++] = e; // 在 ArrayList 的末尾添加指定元素
return true;
}
e 为要添加到末尾的元素,size 是 ArrayList 的长度,初始为 0
ensureCapacityInternal() 是如何确保能添加新元素?
/**
* 确保 ArrayList 能够容纳指定容量的元素
* @param minCapacity 指定容量的最小值
*/
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 如果 elementData 还是默认的空数组
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
// 使用 DEFAULT_CAPACITY 和指定容量的最小值中的较大值
}
ensureExplicitCapacity(minCapacity); // 确保容量能够容纳指定容量的元素
}
在这里可以知道:
参数 minCapacity 为 1(size+1 传过来的)
elementData 为存放 ArrayList 元素的底层数组,此时为空
{}DEFAULTCAPACITY_EMPTY_ELEMENTDATA 前面也讲过了,为
{}
以及知道 DEFAULT_CAPACITY 为 10 ,那么 minCapacity 为 10
private static final int DEFAULT_CAPACITY = 10;
然后调用 ensureExplicitCapacity(minCapacity) 方法
/**
* 检查并确保集合容量足够,如果需要则增加集合容量。
* @param minCapacity 所需最小容量
*/
private void ensureExplicitCapacity(int minCapacity) {
// 检查是否超出了数组范围,确保不会溢出
if (minCapacity - elementData.length > 0)
// 如果需要增加容量,则调用 grow 方法
grow(minCapacity);
}
此时:
参数 minCapacity 为 10
elementData.length 为 0(数组为空)
进入 if 语句执行 grow() 方法
/**
* 扩容 ArrayList 的方法,确保能够容纳指定容量的元素
* @param minCapacity 指定容量的最小值
*/
private void grow(int minCapacity) {
// 检查是否会导致溢出,oldCapacity 为当前数组长度
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容至原来的1.5倍
if (newCapacity - minCapacity < 0) // 如果还是小于指定容量的最小值
newCapacity = minCapacity; // 直接扩容至指定容量的最小值
if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果超出了数组的最大长度
newCapacity = hugeCapacity(minCapacity); // 扩容至数组的最大长度
// 将当前数组复制到一个新数组中,长度为 newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}
进行数组的第一次扩容,长度为 10,然后回到 add() 方法
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
数组的第一个元素(下标为 0) 被赋值为“zhangsan”,接着返回 true,第一次 add 方法执行完毕
总结:
add() 调用的过程:
add(element)
└── if (size == elementData.length) // 判断是否需要扩容
├── grow(minCapacity) // 扩容
│ └── newCapacity = oldCapacity + (oldCapacity >> 1) // 计算新的数组容量
│ └── Arrays.copyOf(elementData, newCapacity) // 创建新的数组
├── elementData[size++] = element; // 添加新元素
└── return true; // 添加成功
2.3 指定位置添加元素
把元素添加到 ArrayList 的指定位置
alist.add(1, "lisi");
add(int index, E element) 方法的源码:
/**
* 在指定位置插入一个元素。
* @param index 要插入元素的位置
* @param element 要插入的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public void add(int index, E element) {
rangeCheckForAdd(index); // 检查索引是否越界
ensureCapacityInternal(size + 1); // 确保容量足够,如果需要扩容就扩容
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
// 将 index 及其后面的元素向后移动一位
elementData[index] = element; // 将元素插入到指定位置
size++; // 元素个数加一
}
调用了 System.arraycopy(),它实现对数组进行复制
/*
语法
System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
*/
System.arraycopy(elementData, index, elementData, index + 1, size - index);
2.4 更新元素
可以使用 set() 方法来更改 ArrayList 中的元素,需要提供下标和新元素
alist.set(0, "wangwu");
这样就将之前在索引为 0 的元素值更新为 "wangwu"
/**
* 用指定元素替换指定位置的元素。
* @param index 要替换的元素的索引
* @param element 要存储在指定位置的元素
* @return 先前在指定位置的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public E set(int index, E element) {
rangeCheck(index); // 检查索引是否越界
E oldValue = elementData(index); // 获取原来在指定位置上的元素
elementData[index] = element; // 将新元素替换到指定位置上
return oldValue; // 返回原来在指定位置上的元素
}
2.5 删除元素
remove(int index) 方法用于删除指定下标位置上的元素
remove(Object o) 方法用于删除指定值的元素
alist.remove(1);
alist.remove("wangwu");
两种方式都行,同样因为删除了中间的一个元素,会发生整体的移动
/**
* 删除指定位置的元素。
* @param index 要删除的元素的索引
* @return 先前在指定位置的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public E remove(int index) {
rangeCheck(index); // 检查索引是否越界
E oldValue = elementData(index); // 获取要删除的元素
int numMoved = size - index - 1; // 计算需要移动的元素个数
if (numMoved > 0) // 如果需要移动元素,就用 System.arraycopy 方法实现
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // 将数组末尾的元素置为 null,让 GC 回收该元素占用的空间
return oldValue; // 返回被删除的元素
}
/**
* 删除列表中第一次出现的指定元素(如果存在)。
* @param o 要删除的元素
* @return 如果列表包含指定元素,则返回 true;否则返回 false
*/
public boolean remove(Object o) {
if (o == null) { // 如果要删除的元素是 null
for (int index = 0; index < size; index++) // 遍历列表
if (elementData[index] == null) { // 如果找到了 null 元素
fastRemove(index); // 调用 fastRemove 方法快速删除元素
return true; // 返回 true,表示成功删除元素
}
} else { // 如果要删除的元素不是 null
for (int index = 0; index < size; index++) // 遍历列表
if (o.equals(elementData[index])) { // 如果找到了要删除的元素
fastRemove(index); // 调用 fastRemove 方法快速删除元素
return true; // 返回 true,表示成功删除元素
}
}
return false; // 如果找不到要删除的元素,则返回 false
}
通过遍历的方式找到要删除的元素,null 的时候使用 == 操作符判断,非 null 的时候使用 equals() 方法,然后调用 fastRemove() 方法
注:存在相同元素的时候,只会删除第一个就结束了
fastRemove() 方法:
/**
* 快速删除指定位置的元素。
* @param index 要删除的元素的索引
*/
private void fastRemove(int index) {
int numMoved = size - index - 1; // 计算需要移动的元素个数
if (numMoved > 0) // 如果需要移动元素,就用 System.arraycopy 方法实现
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // 将数组末尾的元素置为 null,让 GC 回收该元素占用的空间
}
2.6 查找元素
如果要正序查找一个元素,可以使用 indexOf() 方法;
如果要倒序查找一个元素,可以使用 lastIndexOf() 方法
/**
* 返回指定元素在列表中第一次出现的位置。
* 如果列表不包含该元素,则返回 -1。
* @param o 要查找的元素
* @return 指定元素在列表中第一次出现的位置;如果列表不包含该元素,则返回 -1
*/
public int indexOf(Object o) {
if (o == null) { // 如果要查找的元素是 null
for (int i = 0; i < size; i++) // 遍历列表
if (elementData[i]==null) // 如果找到了 null 元素
return i; // 返回元素的索引
} else { // 如果要查找的元素不是 null
for (int i = 0; i < size; i++) // 遍历列表
if (o.equals(elementData[i])) // 如果找到了要查找的元素
return i; // 返回元素的索引
}
return -1; // 如果找不到要查找的元素,则返回 -1
}
要注意的是,这里为啥区分了要找的元素是否是 null?
如果元素为 null 的时候使用“==”操作符,否则使用
equals()方法
/**
* 返回指定元素在列表中最后一次出现的位置。
* 如果列表不包含该元素,则返回 -1。
* @param o 要查找的元素
* @return 指定元素在列表中最后一次出现的位置;如果列表不包含该元素,则返回 -1
*/
public int lastIndexOf(Object o) {
if (o == null) { // 如果要查找的元素是 null
for (int i = size-1; i >= 0; i--) // 从后往前遍历列表
if (elementData[i]==null) // 如果找到了 null 元素
return i; // 返回元素的索引
} else { // 如果要查找的元素不是 null
for (int i = size-1; i >= 0; i--) // 从后往前遍历列表
if (o.equals(elementData[i])) // 如果找到了要查找的元素
return i; // 返回元素的索引
}
return -1; // 如果找不到要查找的元素,则返回 -1
}
同样 contains() 方法可以判定是否包含某个元素,其内部也是 indexOf() 方法实现的:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
2.7 二分查找
如果 ArrayList 中的元素是经过排序的,就可以使用二分查找法,效率更快
List copy = new ArrayList<>(alist);
copy.add("a");
copy.add("c");
copy.add("b");
copy.add("d");
Collections.sort(copy);
System.out.println(copy); //[a, b, c, d]
Collections 类的 sort() 方法可以进行排序,默认为按照字母顺序进行排序。如果是自定义类型的列表,可以自行指定 Comparator 进行排序
int index = Collections.binarySearch(copy, "b");2.8 时间复杂度
1)查询
时间复杂度为 O(1),因为 ArrayList 内部使用数组来存储元素,所以可以直接根据索引来访问元素
2)插入
时间复杂度最好情况为 O(1),最坏情况为 O(n)
如果在列表末尾添加元素,时间复杂度为 O(1)。
如果要在列表的中间或开头插入元素,则需要将插入位置之后的元素全部向后移动一位,时间复杂度为 O(n)
3)删除
最好情况 O(1),最坏情况 O(n)
如果要删除列表末尾的元素,时间复杂度为 O(1)。
如果要删除列表中间或开头的元素,则需要将删除位置之后的元素全部向前移动一位,时间复杂度为 O(n)。
4)修改
与查询操作类似,可以直接根据索引来访问元素,时间复杂度为 O(1)
3. LinkedList 详解
底层是通过链表实现
/**
* 链表中的节点类。
*/
private static class Node {
E item; // 节点中存储的元素
Node next; // 指向下一个节点的指针
Node prev; // 指向上一个节点的指针
/**
* 构造一个新的节点。
* @param prev 前一个节点
* @param element 节点中要存储的元素
* @param next 后一个节点
*/
Node(Node prev, E element, Node next) {
this.item = element; // 存储元素
this.next = next; // 设置下一个节点
this.prev = prev; // 设置上一个节点
}
}
3.1 创建 LinkedList
因为是链表结构,初始化不需要设定大小
LinkedList list = new LinkedList(); 3.2 添加元素
调用 add 方法添加元素,默认是添加在链表的尾部
list.add("123");
list.add("456");
list.add("789");
add 方法内部其实调用的是 linkLast 方法:
/**
* 将指定的元素添加到列表的尾部。
* @param e 要添加到列表的元素
* @return 始终为 true(根据 Java 集合框架规范)
*/
public boolean add(E e) {
linkLast(e); // 在列表的尾部添加元素
return true; // 添加元素成功,返回 true
}
linkLast 源码:
/**
* 在列表的尾部添加指定的元素。
* @param e 要添加到列表的元素
*/
void linkLast(E e) {
final Node l = last; // 获取链表的最后一个节点
final Node newNode = new Node<>(l, e, null);
// 创建一个新的节点,并将其设置为链表的最后一个节点
last = newNode; // 将新的节点设置为链表的最后一个节点
if (l == null) // 如果链表为空,则将新节点设置为头节点
first = newNode;
else
l.next = newNode; // 否则将新节点链接到链表的尾部
size++; // 增加链表的元素个数
}
添加第一个元素的时候,first 和 last 都为 null
然后新建一个节点 newNode,它的 prev 和 next 也为 null
然后把 last 和 first 都赋值为 newNode
可以演化成另外两个版本:addFirst() 将元素添加到第一位,addLast()将元素添加到末尾
3.3 删除元素
remove():删除第一个节点,内部就是调用removeFirst()remove(int):删除指定位置的节点remove(Object):删除指定元素的节点removeFirst():删除第一个节点removeLast():删除最后一个节点
remove(int) 内部调用的是 unlink 方法:
/**
* 删除指定位置上的元素。
* @param index 要删除的元素的索引
* @return 从列表中删除的元素
* @throws IndexOutOfBoundsException
* 如果索引越界(index < 0 || index >= size())
*/
public E remove(int index) {
checkElementIndex(index); // 检查索引是否越界
return unlink(node(index)); // 删除指定位置的节点,并返回节点的元素
}unlink 方法就是更新当前节点的 next 和 prev,然后把当前节点上的元素设为 null
/**
* 从链表中删除指定节点。
* @param x 要删除的节点
* @return 从链表中删除的节点的元素
*/
E unlink(Node x) {
final E element = x.item; // 获取要删除节点的元素
final Node next = x.next; // 获取要删除节点的下一个节点
final Node prev = x.prev; // 获取要删除节点的上一个节点
if (prev == null) { // 如果要删除节点是第一个节点
first = next; // 将链表的头节点设置为要删除节点的下一个节点
} else {
prev.next = next; // 将要删除节点的上一个节点指向要删除节点的下一个节点
x.prev = null; // 将要删除节点的上一个节点设置为空
}
if (next == null) { // 如果要删除节点是最后一个节点
last = prev; // 将链表的尾节点设置为要删除节点的上一个节点
} else {
next.prev = prev; // 将要删除节点的下一个节点指向要删除节点的上一个节点
x.next = null; // 将要删除节点的下一个节点设置为空
}
x.item = null; // 将要删除节点的元素设置为空
size--; // 减少链表的元素个数
return element; // 返回被删除节点的元素
}
remove(Object) 内部也调用了 unlink 方法,只不过在此之前要先找到元素所在的节点
注:元素为 null 的时候,必须使用 == 来判断;元素非 null 的时候,要使用 equals 来判断
3.4 更新元素
可以调用 set() 方法来更新元素
list.set(0, "321");
set() 源码:
/**
* 将链表中指定位置的元素替换为指定元素,并返回原来的元素。
* @param index 要替换元素的位置(从 0 开始)
* @param element 要插入的元素
* @return 替换前的元素
* @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
*/
public E set(int index, E element) {
checkElementIndex(index); // 检查索引是否超出范围
Node x = node(index); // 获取要替换的节点
E oldVal = x.item; // 获取要替换节点的元素
x.item = element; // 将要替换的节点的元素设置为指定元素
return oldVal; // 返回替换前的元素
}
这里要注意一下 node(index) 方法:
/**
* 获取链表中指定位置的节点。
* @param index 节点的位置(从 0 开始)
* @return 指定位置的节点
* @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
*/
Node node(int index) {
if (index < (size >> 1)) { // 如果索引在链表的前半部分
Node x = first;
for (int i = 0; i < index; i++)
// 从头节点开始向后遍历链表,直到找到指定位置的节点
x = x.next;
return x; // 返回指定位置的节点
} else { // 如果索引在链表的后半部分
Node x = last;
for (int i = size - 1; i > index; i--)
// 从尾节点开始向前遍历链表,直到找到指定位置的节点
x = x.prev;
return x; // 返回指定位置的节点
}
}
先对下标做一个初步判断,提高效率
3.5 查找元素
1)indexOf(Object):查找某个元素所在的位置
/**
* 返回链表中首次出现指定元素的位置,如果不存在该元素则返回 -1。
* @param o 要查找的元素
* @return 首次出现指定元素的位置,如果不存在该元素则返回 -1
*/
public int indexOf(Object o) {
int index = 0; // 初始化索引为 0
if (o == null) { // 如果要查找的元素为 null
for (Node x = first; x != null; x = x.next) { // 从头节点开始向后遍历链表
if (x.item == null) // 如果找到了要查找的元素
return index; // 返回该元素的索引
index++; // 索引加 1
}
} else { // 如果要查找的元素不为 null
for (Node x = first; x != null; x = x.next) { // 从头节点开始向后遍历链表
if (o.equals(x.item)) // 如果找到了要查找的元素
return index; // 返回该元素的索引
index++; // 索引加 1
}
}
return -1; // 如果没有找到要查找的元素,则返回 -1
}
2)get(int):查找某个位置上的元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}演化为其他的一些方法:
getFirst()方法用于获取第一个元素;
getLast()方法用于获取最后一个元素;
poll()和pollFirst()方法用于删除并返回第一个元素(两个方法尽管名字不同,但方法体是完全相同的);
pollLast()方法用于删除并返回最后一个元素;
peekFirst()方法用于返回但不删除第一个元素
4. List 集合遍历
4.1 for 循环
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + ",");
}4.2 迭代器 Iterator
Iterator 发现有元素被 remove/add ,就会抛出一个异常 fail-fast
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + ",");
}4.3 for-each
看起来是 for-each,只不过是一个语法糖,其实背后也是 Iterator
不过,remove/add 操作直接调用的是集合自己的方法,而不是 Iterator 的 remove/add 方法
for (String str : list) {
System.out.print(str + ",");
}4.4 迭代器 ListIterator
ListIterator,它继承了 Iterator 接口,在遍历List 时可以从任意下标开始遍历,而且支持双向遍历
public interface ListIterator extends Iterator {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
} 集合(Collection)不仅有 List,还有 Set,那 Iterator 不仅支持 List,还支持 Set,但 ListIterator 就只支持 List
/**
* ArrayList 逆向迭代器的实现,内部类。
*/
private class DescendingIterator implements Iterator {
/**
* 使用 ListItr 对象进行逆向遍历。
*/
private final ListItr itr = new ListItr(size());
/**
* 判断是否还有下一个元素。
*
* @return 如果还有下一个元素,则返回 true,否则返回 false。
*/
public boolean hasNext() {
return itr.hasPrevious();
}
/**
* 获取下一个元素。
*
* @return 列表中的下一个元素。
* @throws NoSuchElementException 如果没有下一个元素
* 则抛出 NoSuchElementException 异常。
*/
public E next() {
return itr.previous();
}
/**
* 删除最后一个返回的元素。
* 迭代器只能删除最后一次调用 next 方法返回的元素。
*
* @throws UnsupportedOperationException 如果列表不支持删除操作,
* 则抛出 UnsupportedOperationException 异常。
* @throws IllegalStateException 如果在调用 next 方法之前没有调用 remove 方法,
* 或者在同一次迭代中多次调用 remove 方法,
* 则抛出 IllegalStateException 异常。
*/
public void remove() {
itr.remove();
}
}
DescendingIterator 刚好利用了 ListIterator 向前遍历的方式。可以通过以下的方式来使用:
Iterator it = list.descendingIterator();
while (it.hasNext()) {
}Map 就没办法直接使用 for-each,因为 Map 没有实现 Iterable 接口,只有通过
map.entrySet()、map.keySet()、map.values()这种返回一个 Collection 的方式才能使用 for-each
4.5 开发规约
不要在 foreach 循环里进行元素的
remove/add操作。remove 元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁 ---《阿里巴巴 Java 开发手册》

1)for-each 删除元素报错
List list = new ArrayList<>();
list.add("123");
list.add("456");
list.add("789");
for (String str : list) {
if ("456".equals(str)) {
list.remove(str);
// 在 remove 发生报错
}
}
System.out.println(list);
本质是调用 迭代器:
public Iterator iterator() {
return new Itr();
}
private class Itr implements Iterator {
int cursor; // 下一个元素的索引
int lastRet = -1; // 上一个返回元素的索引;如果没有则为 -1
int expectedModCount = modCount; // ArrayList 的修改次数
Itr() { } // 构造函数
public boolean hasNext() { // 判断是否还有下一个元素
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() { // 返回下一个元素
checkForComodification(); // 检查 ArrayList 是否被修改过
int i = cursor; // 当前索引
Object[] elementData = ArrayList.this.elementData; // ArrayList 中的元素数组
if (i >= elementData.length) // 超出数组范围
throw new ConcurrentModificationException(); // 抛出异常
cursor = i + 1; // 更新下一个元素的索引
return (E) elementData[lastRet = i]; // 返回下一个元素
}
} modCount 是 ArrayList 中的一个计数器,用于记录 ArrayList 对象被修改的次数。ArrayList 的修改操作包括添加、删除、设置元素值等。每次对 ArrayList 进行修改操作时,modCount 的值会自增 1
在迭代 ArrayList 时,如果迭代过程中发现 modCount 的值与迭代器的 expectedModCount 不一致,则说明 ArrayList 已被修改过,此时会抛出 ConcurrentModificationException 异常。这种机制可以保证迭代器在遍历 ArrayList 时,不会遗漏或重复元素,同时也可以在多线程环境下检测到并发修改问题
2)正确删除元素
方法一:remove 后就 break
List list = new ArrayList<>();
list.add("123");
list.add("456");
list.add("789");
for (String str : list) {
if ("456".equals(str)) {
list.remove(str);
break;
}
}
方法二:for 循环
List list = new ArrayList<>();
list.add("123");
list.add("456");
list.add("789");
for (int i = 0; i < list.size(); i++) {
String str = list.get(i);
if ("456".equals(str)) {
list.remove(str);
}
}
方法三:使用 Iterator
List list = new ArrayList<>();
list.add("123");
list.add("456");
list.add("789");
Iterator itr = list.iterator();
while (itr.hasNext()) {
String str = itr.next();
if ("456".equals(str)) {
itr.remove();
}
}
为什么使用 Iterator 的 remove 方法就可以避开 fail-fast 保护机制呢?
调用的是 迭代器的 remove 方法
public void remove() {
if (lastRet < 0) // 如果没有上一个返回元素的索引,则抛出异常
throw new IllegalStateException();
checkForComodification(); // 检查 ArrayList 是否被修改过
try {
ArrayList.this.remove(lastRet); // 删除上一个返回元素
cursor = lastRet; // 更新下一个元素的索引
lastRet = -1; // 清空上一个返回元素的索引
expectedModCount = modCount; // 更新 ArrayList 的修改次数
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException(); // 抛出异常
}
}删除完会执行 expectedModCount = modCount,保证了 expectedModCount 与 modCount 的同步
3)利用 Stream 流的 filter() 方法来过滤集合中的元素
采用 Stream 的filter() 方法来过滤集合中的元素,然后再通过 collect() 方法将过滤后的元素收集到一个新的集合中
List list = new ArrayList<>(Arrays.asList("12", "34", "56"));
list = list.stream().filter(s -> !s.equals("34")).collect(Collectors.toList());