神经网络——ReLU和线性层
目录
ReLU
线性层
实践部分
ReLU
ReLU(Rectified Linear Unit)是一种激活函数,称为非线性激活,常用于卷积神经网络(CNN)中的隐藏层,能够很好地提取数据的非线性特征。官方文档说明:ReLU 的使用
CLASS torch.nn.ReLU(inplace=False)
- inplace:布尔值,当inplace-True时,替换原变量的值,False时则保留原输入值
Input: 输入的图像数据需指明batch_size,其余参数则不做限制
Output: same shape as the input.
其中inplace 为是否保留原始数据,为True时会对数据进行替换,一般我们让inplace=False以防止数据的丢失。

ReLU 是将输入数据中大于0的数据保留,小于0的部分进行截断并归为0。
非线性的激活函数实际上是给模型增加非线性的表达能力或者因素,有了非线性函数模型的表达能力就会更强。整个模型就像活了一样,而不是像机器一样只会做单一的线性操作。简单来说就是激活后直线就变弯了,很多弯曲的线可以拟合复杂的曲线,不激活的话,再多直线变来变去还是直线,仍然只有原来的能力。因此,非线性特征越多,才能训练出符合各种特征的曲线和模型,提高模型的泛化能力。
线性层
线性层(Linear Layer),也称为全连接层(Fully Connected Layer)或仿射层(Affine Layer),是神经网络中常见的一种层类型。官方文档说明:Linear Layer
CLASS torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
in_features (int) :输入样本大小
out_features (int):输出样本大小
bias (bool) :偏置,选择是否加上一个常数,默认 bias=True
线性层的作用是将输入的特征进行线性变换和映射,并输出一个新的特征表示。它通常由一个矩阵乘法操作和一个偏置向量相加组成,可以表示为,其中 x 是输入特征向量,W 是权重矩阵,b 是偏置向量,y 是输出特征向量。
线性层的功能主要有两个:
- 特征提取:线性层通过权重矩阵的乘法操作,将输入特征进行线性组合,从而提取出输入特征的不同组合和表示。
- 非线性映射:通过添加偏置向量,并将线性组合的结果进行非线性的激活函数处理(如ReLU函数),进一步增加模型的表达能力,使得线性层能够学习到更复杂的特征表示。
在线性层之后,通常会接着使用非线性激活函数(如ReLU、Sigmoid、Tanh等)来引入非线性变换,以便神经网络能够学习到更复杂的特征表示和决策边界。
这里我们举一个示例进行说明:

各层间采用的是线性连接的方式,也可以称为全连接。输入从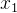 ~
~ ![]() 一共有 d 个,故 in_features=d ,从
一共有 d 个,故 in_features=d ,从 ~
~ ![]() 一共有L 个,故 out_features=L,可以理解为 d 代表特征个数,L 代表神经元个数。从 Input layer 到 Hidden layer 会经过一个 y = Kx + b 的线性变换过程,其中 K 和 b 都需要不断进行调整以适应模型。
一共有L 个,故 out_features=L,可以理解为 d 代表特征个数,L 代表神经元个数。从 Input layer 到 Hidden layer 会经过一个 y = Kx + b 的线性变换过程,其中 K 和 b 都需要不断进行调整以适应模型。
同时从图中可以看出,输入的数据是单列形式,而我们进行网络训练时传入的图像是一个二维数组,明显不符合输入,因此我们在 X 部分需要将数组进行一定处理,将其转换为一维的形式。
实践部分
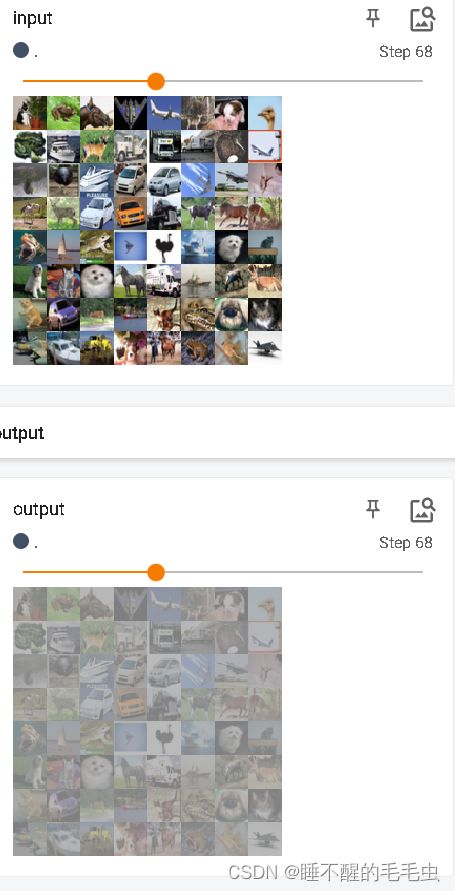
ReLU相关代码如下:由于我们使用的数据集是CIFAR10,图像的像素范围在0—255,故ReLU函数对其并没有作用,为显示图像变化效果,故这里使用了另外一个常用的激活函数 Sigmoid。
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Mydata(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU()
self.Sigmoid1 = Sigmoid()
def forward(self, input):
output = self.Sigmoid1(input)
return output
mydata = Mydata()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = mydata(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()由于之前并未对参数 step 进行讲解,在这里简单说明一下:step 和 batch_size 是有关系的,由于数据集通常很大,没有办法一次性全部取出来,因此我们将其分批取出,step 对应的就是第几个 batch_size 。
运行效果:
线性变换相关代码如下:由理论部分知道我们需要将图像数组转换为一维的形式,即(H=1,W=n),里面的 n 我们可以通过 torch.reshaspe(64,1,1,-1) 得到,-1 表示函数会自动计算该处的值。得到之后就可以设置 Linear(n,m),n 是特征个数,即宽度,m 是想要得到的神经元个数。
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)
class Mydata(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
mydata = Mydata()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = mydata(output)
print(output.shape)