爬虫补环境jsdom、proxy、Selenium案例:某条
声明:
该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关
一、简介
爬虫逆向补环境的目的是为了模拟正常用户的行为,使爬虫看起来更像是一个真实的用户在浏览网站。这样可以减少被网站封禁或限制访问的风险,提高爬取成功率。同时,合理的环境补充也有助于保护爬虫的隐私和安全,避免被恶意攻击或追踪。
由于浏览器和node的差别,很多网站会根据这些差别做一些校验,会导致浏览器的js代码在node没有办法执行,js代码会根据浏览器的这些属性来判断你是不是在真正的浏览器执行的代码,要不是正确的浏览器环境则不会返回正确的数据信息,拿到代码在node里面执行、经常看到这一类型的错误,提示xxx未定义,其实这一块就是浏览器对象的一些特征
二、找出网站加密位置,并扣出代码
- js运行 atob(‘aHR0cHM6Ly93d3cudG91dGlhby5jb20v’) 拿到网址,F12打开调试工具,点击推荐发送请求,找到 pc/list/feed 请求,鼠标右击请求找到Copy>Copy as cUrl(cmd)
- 打开网站:https://spidertools.cn/#/curl2Request,把拷贝好的curl转成python代码,新建 jrtt.py,把代码复制到该文件
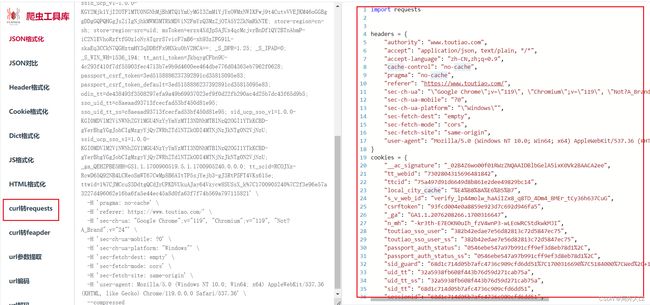
- 关键字_signature搜索,会发现有_signature赋值的地方

- 右击该文件,选择在source中打开
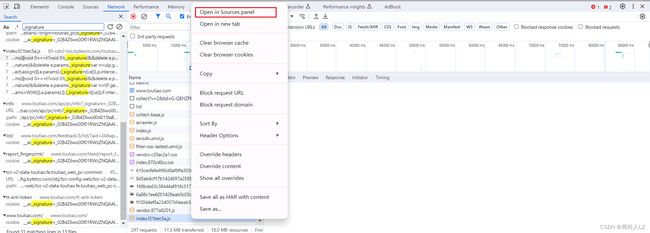
- 在该文件内 Ctrl+F 搜索_signature,会发现有两个赋值的地方全部打上断点
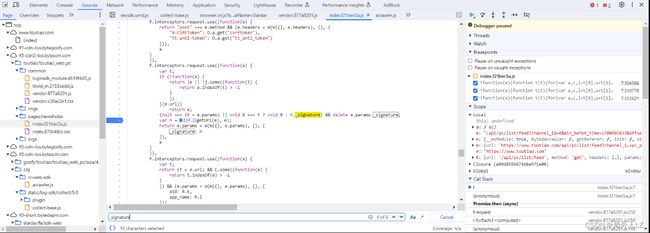

- 点击推荐重新发送请求,会发现断点进入 var n = I(F.getUri(e), e),鼠标悬浮到 I 上点击蓝色部分快速找到该方法,会发现一个 I(e, t) 方法,在该方法内部打断点
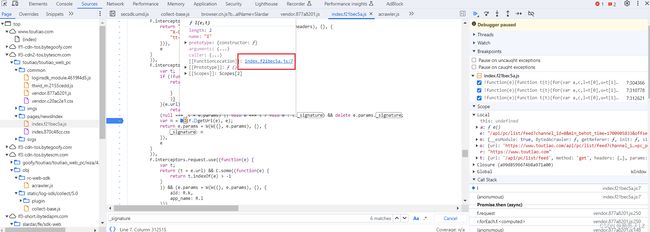

- 点击跳过断点,会进入该断点,分析代码会发现该代码return出去的是 a.call(n, o),而a=n.sign,n = window.byted_acrawler,o则是请求地址加上参数的一串字符,鼠标悬浮到 window.byted_acrawler 找到 sign方法,点击蓝色部分快速找到该方法,分析代码会发现该函数是jsvmp实现的,jsvmp是js虚拟机保护方案
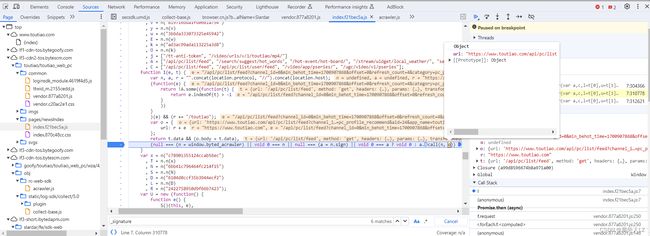
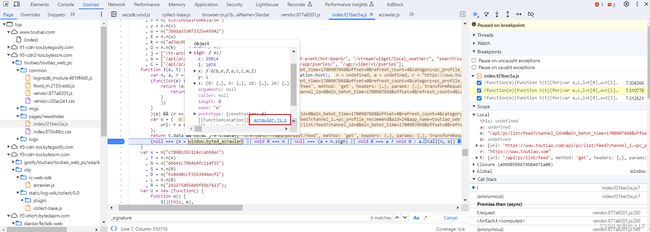

- 新建jrtt.js,把代码全部拷贝到该文件,再把 o 在控制台输出,拷贝到jrtt.js文件

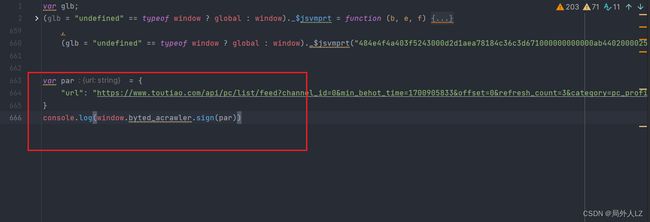
三、打断点补环境
- 运行jrtt.js,会发现报 window 错误,window是浏览器中的,node环境不存在,在代码顶部补上window:window = global
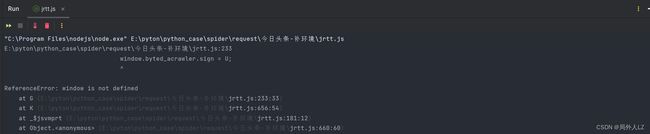
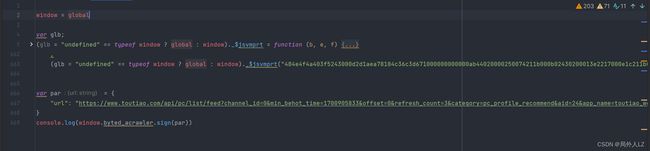
- 运行jrtt.js,会报 sign 错误,这是因为刚才的sign是声明在 window.byted_acrawler 中,而现在的window中没有byted_acrawler,补上byted_acrawler:
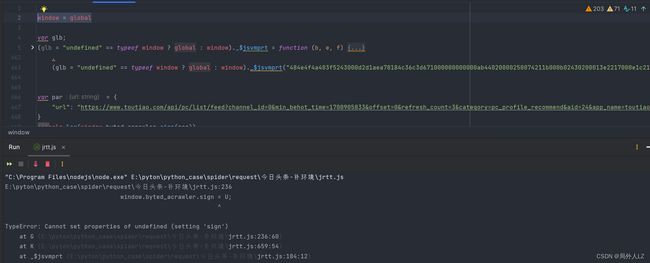
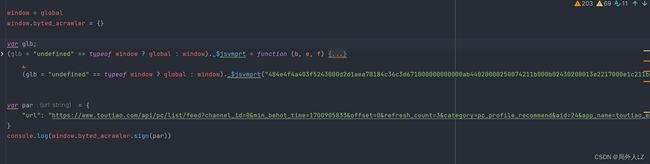
- 运行jrtt.js,会报referrer的错误,在source中的加密文件,搜索 S[R] = S[R][A],会找到该代码,在该代码处打个日志断点,在日志断点处输出 S[R]、A、S[R]A

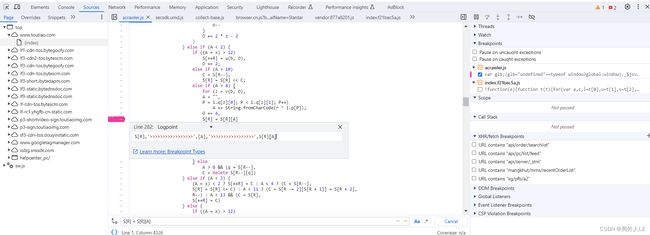
- 取消之前所有的断点,除了刚才的日志断点,刷新网页,会发现控制台中打印很多日志,这些就是刚才的日志断点生成的,控制台搜索referrer,会发现是document下的referrer,且值是一个空字符串,在代码顶部补上referrer


- 运行jrtt.js文件 sign 错误,找代码会发现 “undefined” != typeof exports ? exports : void 0,这是环境检测 exports 是node环境的,把代码修改为 “undefined” == typeof exports

- 运行jrtt.js文件会报 href 错误,同 referrer 一样,在控制台搜索 href,会发现 href 是 location 下的,在代码顶部补上该代码

- 运行jrtt.js文件会报 length 错误,因太多对象有length,所以length不能像href、referrer 一样直接再浏览器控制台搜索,找到拷贝下的加密代码,搜索 S[R] = S[R][A],找到对应位置添加 console.log(A)
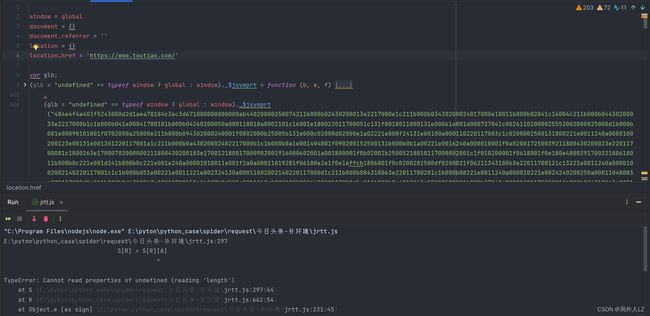
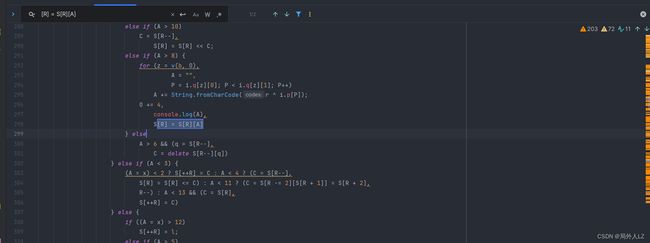
- 运行jrtt.js文件,会发现报错length的对象是protocol,同href、referrer,一样在控制台搜索protocol,会发现 protocol 是 location 下的,在代码顶部补上该代码


- 运行jrtt.js文件,会报userAgent的错误,在控制台搜索userAgent,会发现userAgent是navigator中的,在顶部补上该代码


- 再次运行jrtt.js文件,会发现已经没有报错,参数加密成功,直到现在补了 windows、href、protocol、userAgent这些
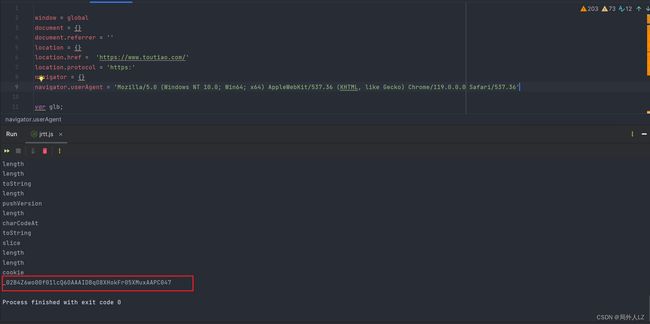
- 验证加密结果:修改jjtt.py,并运行,数据获取成功


四、吐环境脚本,检测环境
使用Proxy对目标环境进行拦截,检测缺少的环境,Proxy对象由两个部分组成:target、handler
handler:是一个对象,声明了代理target的指定行为,支持的拦截操作,一共13种:
- get(target,propKey,receiver):拦截对象属性的读取。
- target: 目标对象
- propKey: 被获取的属性名。
- receiver: Proxy 或者继承 Proxy 的对象
- set(target,propKey,value,receiver):拦截对象属性的设置,返回一个布尔值(修改成功)。
- target: 目标对象
- propKey: 被获取的属性名。
- value: 新属性值。
- receiver: Proxy 或者继承 Proxy 的对象
- 新建jsProxy.js,放入以下代码,代码可通用,需要扩展的可在该代码基础上扩展
// 代理器封装
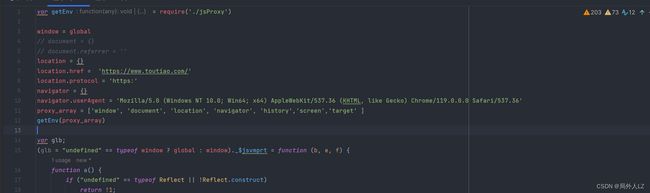
function getEnv(proxy_array) {
for(var i=0; i- 修改jrtt.js,运行jrtt.js,会发现有很多undefined的,这些就是需要补的值,由刚才的断点不环境得知sessionStorage、localStorage、cookie等是不需要补的,所以如果不知道需要补哪些环境,就先补报错的,报错的补完,先验证下,如果验证不通过在补其他的
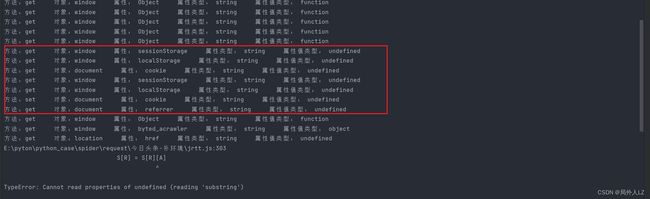
- 由刚才的报错得知location下的herf获取时值时undefined,所以先补href,直接在控制台输出location.href值补上

- 重复步骤5,直到没有报错再去验证结果,运行jjtt.py后会发现,虽然没补referrer,但是数据依然获取成功,那是因为referrer是空值,已经在代理中把它之前的值返回了

五、Selenium补环境
selenium就是一个真实的浏览器环境,可以把扣下来的代码直接用Selenium来进行访问
-
新建jrtt.html,把之前扣下的代码拷贝到script下,因为是在浏览器下运行的,所以把之前检验环境的 “undefined” != typeof exports ? exports 还原
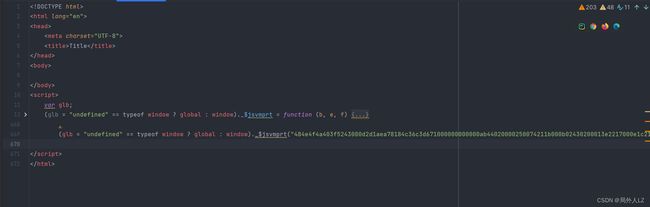

-
浏览器打开该html,验证window.byted_acrawler.sign会发现加密成功
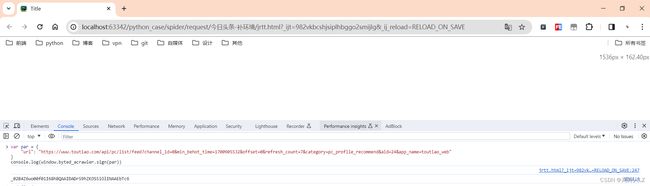
-
新建seleniumJrtt.py,如果运行出错,先检查下自己浏览器和谷歌驱动版本
import os
from selenium import webdriver
PRO_DIR = os.path.dirname(os.path.abspath(__file__))
def driver_sig(html_file):
option = webdriver.ChromeOptions()
option.add_argument('--disable-blink-features=AutomationControlled')
option.add_argument('headless')
driver = webdriver.Chrome(options=option)
driver.get(PRO_DIR +'\\'+ html_file)
return driver
html_file = 'jrtt.html'
driv = driver_sig(html_file)
js_code = '''
return window.byted_acrawler.sign(arguments[0]);
'''
par = {
"url": "https://www.toutiao.com/api/pc/list/feed?channel_id=0&min_behot_time=1700905532&offset=0&refresh_count=7&category=pc_profile_recommend&aid=24&app_name=toutiao_web"
}
result = driv.execute_script(js_code,par)
print(result)
六、jsdome补环境
