机器学习中的线性回归
线性回归
概念
利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。
分类
一元线性回归:y = wx +b 目标值只与一个因变量有关系
多元线性回归: y= w_1x_1+ w_2x_2 + w_3x_3 + … + b 目标值只与多个因变量有关系
线性回归的API
# 创建线性回归对象
estimator = LinearRegression()
# 使用数据训练线性回归模型
estimator.fit(x,y)
# 利用训练好的模型 做预测
estimator.predict([[176]]) # 利用训练好的线性方程, 把特征值带进去, 计算目标值训练好的线性回归模型对象有两个重要的属性
estimator.intercept_ # 截距 x = 0 y 的取值
estimator.coef_ # 回归系数 (线性方程的斜率)线性回归求解的基本思路
线性回归 最终的目的是为了得到一个线性方程, 要来表示特征和目标之间的关系, 这一类模型目的是为了得到一个数学公式, 这种问题的解决有固定的套路
确定假设函数 如果线性回归 y = KX +b 认为特征和目标之间满足线性关系
确定损失函数 如果是回归问题一般使用均方误差

对损失函数求解, 找到损失函数的极小值, 所对应的系数, 数学关系就确定下来, 模型也就搞定了
对于线性回归来说, 就是要找到是损失最小的那一组 K 和 b
求解损失函数的极小值 就是优化方法

损失函数最小化方式
正规方程
线性回归最小而成损失函数
J(w) = ‖Xw−y‖_2^2 取值最小
其解为: w = (X^TX)^−1 X^Ty
梯度下降
顾名思义:沿着梯度下降的方向求解极小值
举个例子:坡度最陡下山法,梯度下降过程就和下山场景类似 可微分的损失函数,代表着一座山 寻找的函数的最小值,也就是山底
公式: 循环迭代求当前点的梯度,更新当前的权重参数\
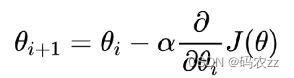
α: 学习率(步长) 不能太大, 也不能太小. 机器学习中:0.001 ~ 0.01
梯度是上升最快的方向, 我们需要是下降最快的方向, 所以需要加负号
梯度下降几种算法
全梯度下降
-
使用全部样本进行计算, 当样本量较大的时候, 计算的速度可能比较慢
-
想优化计算的速度, 可以考虑使用下面几种梯度下降算法
随机梯度下降
每一轮随机挑选一个样本
小批量梯度下降
每一轮随机挑选一小批样本
随机平均梯度下降
每一轮随机挑选一个样本 , 会把这个样本记录下来
下一轮再挑选一个样本, 计算两个样本梯度的平均值
线性回归模型评估
均方误差 Mean Squared Error MSE

平均绝对误差 Mean Absolute Error MAE

均方根误差 Root Mean Squared Error (RMSE)

指标使用
MSE 均方误差, 是模型误差的平方, 不能反应真是的误差情况
MAE / RMSE 基本可以反应真实的平均误差
MAE / RMSE
一般情况下 对同一个模型, 同一份测试数据计算上面两个指标, RMSE > MAE
RMSE 会对预测误差较大的点比较敏感
可以综合两个指标来看最终模型的结果
波斯顿房价预测案例
加载数据
import pandas as pd
boston = pd.read_csv('/root/code/波士顿房价xy.csv')
y = boston['target']
x = boston.drop('target',axis=1) # 从数据中去掉 target这一列, 剩下的都是特征值 axis = 1 删除的数据指定的是列名正规方程
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression # 正规方程
from sklearn.metrics import mean_squared_error # 均方误差
from sklearn.metrics import mean_absolute_error # 绝对平均误差
# 训练集测试集划分 test_size 默认值 0.25
X_train, X_test, y_train, y_test = train_test_split(x,y,random_state=22)
# 特征工程 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 模型训练 正规方程
estimator = LinearRegression()
estimator.fit(X_train_scaled,y_train)
y_train_pred = estimator.predict(X_train_scaled)
y_test_pred = estimator.predict(X_test_scaled)
# 模型评估
print('训练集,mse',mean_squared_error(y_train_pred, y_train))
print('测试集,mse',mean_squared_error(y_test_pred, y_test))
print('训练集,mae',mean_absolute_error(y_train_pred, y_train))
print('测试集,mae',mean_absolute_error(y_test_pred, y_test))梯度下降
from sklearn.linear_model import SGDRegressor #随机梯度下降
# 训练集测试集划分
X_train, X_test, y_train, y_test = train_test_split(x,y,random_state=22)
# 特征工程 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 模型训练 随机梯度下降
estimator = SGDRegressor()
estimator.fit(X_train_scaled,y_train)
y_train_pred = estimator.predict(X_train_scaled)
y_test_pred = estimator.predict(X_test_scaled)
# 模型评估
print('训练集,mse',mean_squared_error(y_train_pred, y_train))
print('测试集,mse',mean_squared_error(y_test_pred, y_test))
print('训练集,mae',mean_absolute_error(y_train_pred, y_train))
print('测试集,mae',mean_absolute_error(y_test_pred, y_test))