【书生·浦语】大模型实战营——第五课作业
教程文档:https://github.com/InternLM/tutorial/blob/vansin-patch-4/lmdeploy/lmdeploy.md#tritonserver-%E6%9C%8D%E5%8A%A1%E4%BD%9C%E4%B8%BA%E5%90%8E%E7%AB%AF
视频链接:
作业:

基础作业
使用如下命令创建conda环境
conda create -n lmdeploy --clone /share/conda_envs/internlm-base
然后激活环境,进入环境。

通过pip命令安装lmdeploy
pip install 'lmdeploy[all]==v0.1.0'
途中遇到报错,说没有packaing这个包。

那么通过pip install packaging命令进行安装,此时再执行安装lmdeploy的命令,发现安装一直卡在flash-attn的wheel上。
看到了QA文档中的解决方案,先通过以下命令手动安装flash-attn的wheel,再执行lmdeploy的安装命令,就可以顺利安装。
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl

Client左侧为Server端,是经典的C/S架构。
Model Inference是相对独立的一部分,要与业务解耦。API Server是对外暴露服务的部分。
本地对话
Lmdeploy支持直接读取huggingface上的模型权重。这里以internlm-chat7b为例,执行以下命令启动internlm-chat7b模型。即可开启本地对话

有一说一,lmdeploy部署的模型回复速度好快。
离线转换需要在启动服务之前,,使用lmdeploy convert命令即可。
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
lmconvert的作用是将文件转换成lmdeploy要求的格式。
那lmdeploy要求的格式是什么呢?长下面这样子。

其中weights目录的文件长以下这样

这里将每一层网络的参数都拿了出来,bias和weeight分开。前面的那个数字0指代的则是显卡的编号。
分开显卡的编号主要是方便Tensor并行,拆开计算。
TurboMind推理+命令行本地对话
执行以下命令
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/

TurboMind推理+API服务
可以通过下面的命令来启动API服务,相当于启动了一个服务器server端
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
此时,vscode里新开一个窗口,首先激活环境,然后再敲入以下命令充当客户端:
lmdeploy serve api_client http://localhost:23333
然后在客户端(右侧)进行聊天,服务端(左侧)会收到相关请求,并回复消息给客户端。整个速度非常快。

此时,敲下方命令进行端口转发
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p
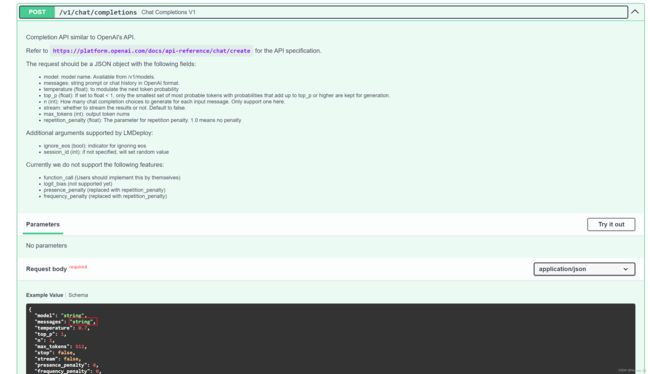
此时在浏览器网址栏输入http://localhost:23333/,就可以看到API信息了。

点击GET请求,然后点击try it out,点击execute,就可以看到模型列表。

我们换个接口再试试,点击completion这个接口,点击try it out,将message里的字符串换一个。也能得到正常的回复。
网页DEMO演示+基础作业300字生成演示
此处仅展示turbomind作为后端。敲入以下命令,启动gradio后端。
lmdeploy serve gradio ./workspace
等到出现Running on local URL: …就说明部署好了

现在敲入以下命令转发6006端口
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 35122
就可以在浏览器中看到相关界面了

我跟他说不高兴,想听一个童话故事。
