GAT网络为什么占用那么多的显存
GAT网络显存占用原因分析(非专业,纯个人理解)
- 1:GAT的注意力机制
- 2:为什么transformer就可以有很长的输入
本blog主要聚焦以下几点:
- GAT为什么占用那么多的显存,尤其是在节点多的时候
- Transformer为什么就可以处理很长的输入,GAT就不行?
⚠⚠:并非图相关的方向,仅是打工时用到了,简单了解了一下。
1:GAT的注意力机制
GAT占用显存多的原因一句话概括就是:注意力机制
首先来看GAT的注意力机制是什么样的:
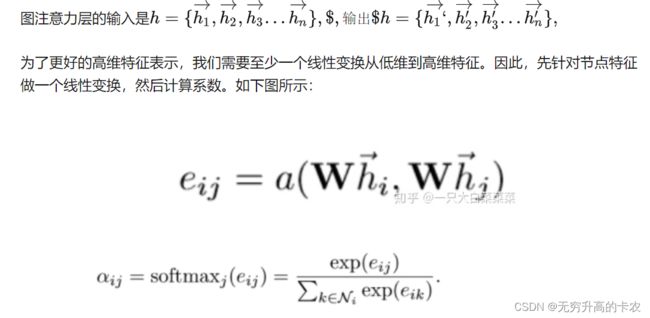
图片先随便放一张,之后再改:来源(https://zhuanlan.zhihu.com/p/137592078)
也就是,每一个节点可以用一个向量 h i h_i hi表示,那么在计算attention score的时候,就是 W h i Wh_i Whi向量与 W h j Wh_j Whj向量拼接之后( W W W是去可学习的权重),再乘一个可学习权重 a a a。,之后再求softmax,并且使用了mask,让每个节点只使用和他直接相连的节点进行计算。
其实很容易理解,就是先把每一个节点的向量过一个mlp,之后使用每个节点得到的新向量,计算每两个节点之间的加权求和。这就是主要的费显存的地方。为什么呢?请看这部分的代码是如何实现的:
GAT的代码我直接在网上找的一个,改成了batch版本,代码来源:https://zhuanlan.zhihu.com/p/128072201
def forward(self, inp, adj):
"""
inp: input_fea [B, N, in_features] in_features表示节点的输入特征向量元素个数
adj: 图的邻接矩阵 维度[B, N, N] 非零即一,数据结构基本知识
"""
h = torch.matmul(inp, self.W) # [B, N, out_features]
# print(h.size())
print('1: ', torch.cuda.memory_allocated())
N = h.size()[1] # N 图的节点数
# 最占显存的就是这下面一行
# 单独一个a_input就会占用276.39兆的显存,而实际上这一个计算之后立马就会新增0.81G的显存占用
a_input = torch.cat([h.repeat(1, 1, N).view(-1, N * N, self.out_features),
h.repeat(1, N, 1)], dim=1).view(-1, N, N, 2 * self.out_features)
print('2: ', torch.cuda.memory_allocated())
其中,在计算 a i n p u t a_input ainput的时候计算的就是 ( W h i , W h j ) (Wh_i, Wh_j) (Whi,Whj),为了便于快速计算出 N N N个节点中两两之间的attention score,要么就两层循环嵌套,一共循环 N 2 N^2 N2次,要么直接将矩阵 W h i Wh_i Whi和 W h j Wh_j Whj在不同的维度上重复 N N N次,然后拼接。repeat的效果大概是下面这样:

同一个颜色代表同一个向量,左边是把每一个重复 N N N次,右边是把整体重复 N N N次。拼接起来之后,刚刚好每一行就是一个向量 h i h_i hi和另一个向量 h j h_j hj,之后在乘一个矩阵 a a a,直接就计算出了两个向量之间的加权求和值。
而恰恰就是这个向量导致整体的显存占用暴涨。我的场景是有一个500+节点的图,每一个图的特征是6,我设置的 o u t _ f e a t u r e s out\_features out_features数目是128。所以我上面repeat之前的矩阵大小是 [ B , 500 , 128 ] [B, 500, 128] [B,500,128],重复之后变成了 [ B , 500 , 500 , 256 ] [B, 500, 500, 256] [B,500,500,256],此时我把B设为4。那么一共有 4 ∗ 500 ∗ 500 ∗ 256 = 256000000 4 * 500 * 500 * 256 = 256000000 4∗500∗500∗256=256000000个数字,而一个单精度的foat32的数占用四个字节,因此该tensor占用 256000000 / 256 / 1024 / 1024 = 0.95 G B 256000000 / 256 / 1024 / 1024 = 0.95GB 256000000/256/1024/1024=0.95GB,而我们还会设置多头注意力,不过没经过一个头,算完之后,这个显存会被回收,所以八个头其实占用和一个头差不太多。
到这里虽然占用比较多,但是还在可接受的范围之内,因为我们的显卡经常都是32G的显或者40G的显存。
但是,当把八个头的输出叠加到一起之后,是一个 [ B , N , o u t _ f e a t u r e s ∗ 8 ] [B, N, out\_features*8] [B,N,out_features∗8]大小的矩阵,此时再加一个输出的GAT头,因为我还有1600个类别,所以输出头的 o u t _ f e a t u r e s out\_features out_features就是1600。此时再继续按照上面的方法来算的话,就会发现,完蛋了。
我们的显存占用将会是 [ B , N , N , 3200 ] [B, N, N, 3200] [B,N,N,3200],占用显存直接变为 4 ∗ 500 ∗ 500 ∗ 3200 / 256 / 1024 / 1024 = 11.9 G B 4 * 500 * 500 * 3200 / 256 / 1024 / 1024 = 11.9GB 4∗500∗500∗3200/256/1024/1024=11.9GB,直接就变得非常大了,而这只是理想情况下,实际上,pytorch会分配更多的显存。 因此,bs必须非常小才能勉强维持不爆显存。
2:为什么transformer就可以有很长的输入
这个也很简单,因为transformer使用的注意力机制是Scaled Dot-Product Attention。
它不需要对tensor进行重复操作,只需要直接dot-product就行了。