TF-IDF和BM25算法原理及python实现
目录
- 前言
- 一、TF-IDF
-
- TF定义:
- 逆文本频率指数(Inverse Document Frequency,IDF)
- TF-IDF(Term Frequency-inverse Document Frequency)
- 二、BM25
-
- 1.BM25中的TF
- BM25如何对待文档长度
- BM25 相对TF-IDF有哪些优势?
- BM25代码实现 python
前言
搜索引擎是如何计算关键字和内容的相关性呢?这里介绍2种重要的权重度量方法:TF-IDF和BM25。
在进入理论探讨之前,我们先举个例子。假如,我们想找和“Lucence”相关的文章。可以想一下,那些内容里只出现过一次“Lucence”的文章,有可能是在讲某种技术,顺便提到了Lucence这个工具。而那些出现了两三次“Lucence”的文章,很可能是专门讨论Lucence的。通过直觉,我们可以得出判断:关键字出现的次数越多,文档与关键字的匹配度越高
一、TF-IDF
TF定义:
词频(Term Frequenc,TF): 表示某关键词词在文章中出现的总次数,TF越大,通常相关性越高。该指标通常会被归一化为:

其中,除以文档总词量进行归一化的目的是:防止结果偏向过长的文档(同一个词语在长文档里通常会具有比短文档更高的词频)
举例:某文档D,长度为200,其中“Lucence”出现了2次,“的”出现了20次,“原理”出现了3次,那么:

“Lucence的原理”这个短语与文档D的相关性就是三个词的相关性之和。
![]()
我们发现一个问题,就是“的”这个词占了很大权重,而它对文档主题的几乎没什么贡献。这种词叫停用词,在度量相关性时不考虑它们的词频。去掉这个词后,上面的相关性变为0.025。其中“Lucence”贡献了0.01, “原理”贡献了0.015。
逆文本频率指数(Inverse Document Frequency,IDF)
细心的人还会发现,“原理”是个很通用的词,而“Lucence”是个专业词。直觉告诉我们,“Lucence”这个词对我们的搜索比“原理”更重要。抽象一下,可以理解为 一个词预测主题的能力越强,就越重要,权重也应该越大。反之,权重越小。
假设我们把世界上所有的文档的总和看成一个文档库。如果一个词,很少在文档库里出现过,那通过它就容易找到目标,它的权重也应该大。反之,如果一个词在文档库中大量出现,看到它仍然不清楚在讲什么内容,它的权重就应该小。
其中,“的、地、得”这些虚词出现的频率太高,以至于权重设为零也不影响搜素,这也是它们成为停用词的原因之一。
假设关键词w在n个文档中出现过,那么n越大,则w的权重越小。
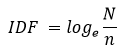
注意: 这里的log是指以2为底的对数,不是以10为底的对数。
N表示全部文档数,n代表某关键词w在全部文档N中出现的文档数目。
假如世界上文档总数位100亿,"Lucence"在1万个文档中出现过,“原理”在2亿个文档中出现过,那么它们的IDF值分别为:
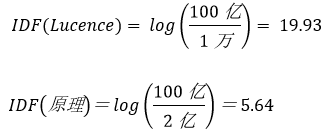
“Lucence”重要性相当于“原理”的3.5倍。停用词“的”在所有的文档里出现过,故n=N,它的IDF=log(1)=0,这就是停用词,影响力为0。
当某关键词w在全部文档N中出现的文档数目为0时,会出现分母为0的现象,故为了解决这个问题,进行平滑操作,对其分母+1:
![]()
TF-IDF(Term Frequency-inverse Document Frequency)
TF-IDF是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比(TF),跟它在语料库出现的次数成反比。这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。
![]()
TFIDF值越大表示该特征词对这个文本的重要性越大。
Lucence中的TF-IDF:
早期的Lucence是直接把TF-IDF作为默认相似度来用的,只不过做了适当调整,它的相似度公式为:

N:文档数量总数量;
n:包含关键字的文档数量;
tf:某个关键词在文档中出现的次数
length:文档的长度
上面的公式在Lucence系统里做计算时会被拆分成三个部分:

fieldNorms 是对文本长度的归一化(Normalization)。
所以,上面公式也可以表示成:
![]()
短语与文档的最终相关性就是TF和IDF的加权求和:
![]()
现在可以计算出上文中提到的“Lucence的原理”与文档D的相关性:
![]()
其中,“Lucence”占了70%的权重,“原理”仅占30%的权重,符合上节“Lucence”这个词对我们的搜索比“原理”更重要的猜测。
二、BM25
BM25, 下一代的TF-IDF。新版的lucence不再把TF-IDF作为默认的相关性算法,而是采用了BM25(BM是Best Matching的意思)。BM25是基于TF-IDF并做了改进的算法。(Elasticsearch是一个基于Lucene库的搜索引擎).
1.BM25中的TF
传统的TF值理论上是可以无限大的。而BM25与之不同,它在TF计算方法中增加了一个常量k,用来限制TF值的增长极限。下面是两者的公式:
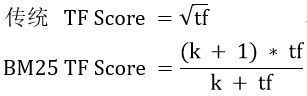
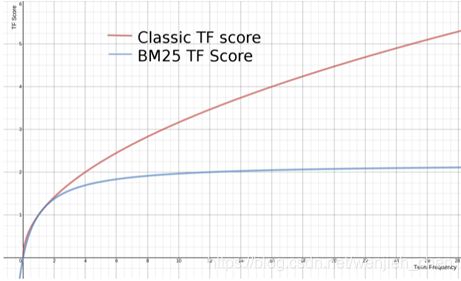
下面是两种计算方法中,词频对TF Score影响的走势图。从图中可以看到,当tf增加时,TF Score跟着增加,但是BM25的TF Score会被限制在0~k+1之间。它可以无限逼近k+1,但永远无法触达它。
这在业务上可以理解为某一个因素的影响强度不能是无限的,而是有个最大值,这也符合我们对文本相关性逻辑的理解。
在Lucence的默认设置里,k=1.2,使用者可以修改它。
BM25如何对待文档长度
BM25还引入了平均文档长度的概念,单个文档长度对相关性的影响力与它和平均长度的比值有关系。BM25的TF公式里,除了k外,引入另外两个参数:L和b。
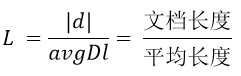
L是文档长度与平均长度的比值;如果文档长度是平均长度的2倍,则L=2;b是一个常数,它的作用是规定L对评分的影响有多大。故:

下面是不同L的条件下,词频对TF Score影响的走势图:
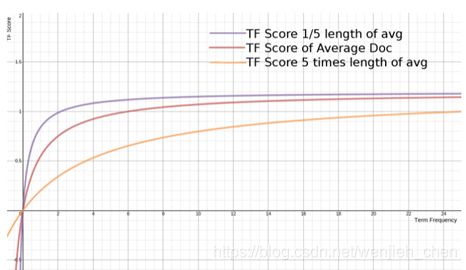
从图上可以看到,文档越短,它逼近上限的速度越快,反之则越慢。这是可以理解的,对于只有几个词的内容,比如文章“标题”,只需要匹配很少的几个词,就可以确定相关性。而对于大篇幅的内容,比如一本书的内容,需要匹配很多词才能知道它的重点是讲什么。
上文说到,参数b的作用是设定L对评分的影响有多大。如果把b设置为0,则L完全失去对评分的影响力。b的值越大,L对总评分的影响力越大。此时,相似度最终的完整公式为:
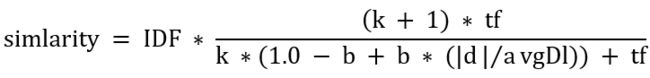
BM25 相对TF-IDF有哪些优势?
ES 5.0(基于Lucene 6)及后续版本使用 BM25代替TF-IDF作为默认的相似度算法。那么BM25 相对 TF-IDF 有哪些优势呢?
- BM25在传统TF-IDF的基础上增加了几个可调节的参数,使得它在应用上更佳灵活和强大,具有较高的实用性。
- 根据ES权威指南的说法,BM25 在词频饱和度方面有更好的表现。但是考虑到 TF 会被归一化到
[0,1],实际的词频饱和度表现如下(BM25取k=1.2, 文档长度等于平均长度)。
思考:
为什么BM25的TF Score计算要用 d/avgDl, 而不是用平方根、log或者其它计算方法?它背后是否有理论支持?
BM25代码实现 python
PARAM_K1 = 1.5
PARAM_B = 0.75
EPSILON = 0.25
# BM25 相似度算法
# simlarity = IDF * ((k + 1) * tf) / (k * (1.0 - b + b * (|d|/avgDl)) + tf)
#用BM25做召回,esim做排序(文本相似度匹)
class BM25(object):
"""Implementation of Best Matching 25 ranking function.
Attributes
----------
corpus_size : int
Size of corpus (number of documents).
avgdl : float
Average length of document in `corpus`.
corpus : list of list of str
Corpus of documents.
f : list of dicts of int
Dictionary with terms frequencies for each document in `corpus`. Words used as keys and frequencies as values.
df : dict
Dictionary with terms frequencies for whole `corpus`. Words used as keys and frequencies as values.
idf : dict
Dictionary with inversed terms frequencies for whole `corpus`. Words used as keys and frequencies as values.
doc_len : list of int
List of document lengths.
"""
def __init__(self, corpus):
"""
Parameters
----------
corpus : list of list of str
Given corpus.
"""
self.corpus_size = len(corpus)
self.avgdl = sum(float(len(x)) for x in corpus) / self.corpus_size
self.corpus = corpus
self.f = []
self.df = {}
self.idf = {}
self.doc_len = []
self.initialize()
def initialize(self):
"""Calculates frequencies of terms in documents and in corpus. Also computes inverse document frequencies."""
for document in self.corpus:
frequencies = {}
self.doc_len.append(len(document))
for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.f.append(frequencies)
for word, freq in iteritems(frequencies):
if word not in self.df:
self.df[word] = 0
self.df[word] += 1
for word, freq in iteritems(self.df):
self.idf[word] = math.log(self.corpus_size - freq + 0.5) - math.log(freq + 0.5)
# def get_score(self,document, index, average_idf):
def get_score(self, document, index):
"""Computes BM25 score of given `document` in relation to item of corpus selected by `index`.
Parameters
----------
document : list of str
Document to be scored.
index : int
Index of document in corpus selected to score with `document`.
average_idf : float
Average idf in corpus.
Returns
-------
float
BM25 score.
"""
score = 0
for word in document:
if word not in self.f[index]:
continue
idf = self.idf[word]
# if self.idf[word] >= 0 else EPSILON * average_idf
# score += (idf * self.f[index][word] * (PARAM_K1 + 1)
# / (self.f[index][word] + PARAM_K1 * (1 - PARAM_B + PARAM_B * self.doc_len[index] / self.avgdl)))
score += (idf * self.f[index][word] * (PARAM_K1 + 1)
/ (self.f[index][word] + PARAM_K1 * (1 - PARAM_B + PARAM_B * self.doc_len[index] / self.avgdl)))
return score
# def get_scores(self,document, average_idf):
def get_scores(self, document):
"""Computes and returns BM25 scores of given `document` in relation to
every item in corpus.
Parameters
----------
document : list of str
Document to be scored.
average_idf : float
Average idf in corpus.
Returns
-------
list of fl
Returns
-------
list of float
BM25 scores.
"""
scores = []
for index in xrange(self.corpus_size):
# score = self.get_score(document, index, average_idf)
score = self.get_score(document, index)
scores.append(score)
return scores
参考链接:https://my.oschina.net/stanleysun/blog/1617727
https://www.cnblogs.com/johnnyzen/p/116298273.html
https://www.infoq.cn/article/k2pil5frm450o5ocClz0