C++ Webserver从零开始:基础知识(三)——Linux服务器程序框架
目录
前言
一.服务器编程基础框架
C/S模型
主要框架
二.I/O模型
阻塞I/O
非阻塞I/O
异步I/O
三.两种高效的事件处理模式
Reactor
Proactor
四.模拟Proactor模式
五.半同步/半异步的并发模式
六.有限状态机
七.其他提高服务器性能的方法
池
数据复制
上下文切换和锁
前言
这一章是整个专栏的核心,也是后续章节的总览。这一章我们会从宏观角度上概括,解释,分析Webserver的各个部分。
分析原理,搭建网络,将一个高性能Webserver的各个部分串联起来。可以说,如果没有彻底看懂这一章的内容,那么后面的学习都如同雾里看花,甚至不知道在干嘛,唯有将框架了解清楚,才知道什么地方该填入正确的血肉。
同时,这一章内容也是面试的各大高频考点。
一.服务器编程基础框架
C/S模型
TCP/IP的最初设计理念并没有客户端和服务端的概念,主机与主机之间大多进行的是信息对等交换。
类似于人类古代的以物易物的交易方式
但随着网络的发展,有一些主机其掌握了更多的资源,其他主机想要获得资源都要去找它获取,这些主机慢慢发展壮大,成了我们今天的服务端,而其他的主机便是客户端。
类似于出现了店家,人们不再以物易物,而是去店家那获取资源
而在Linux中,客户端与服务端之间“交易方式”,如下图所示
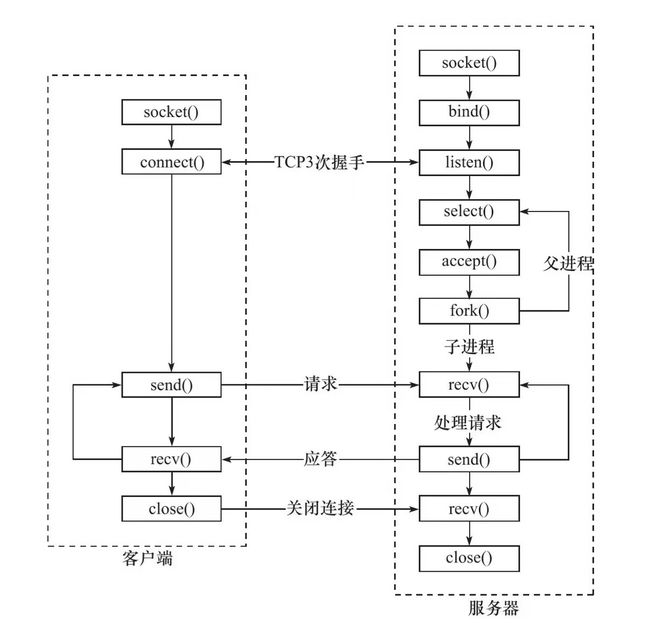
主要框架
但很显然,上面这种交易方式并不是单独发生,当有多个客户端和服务端发生“交易”时,服务端就得好好设计一番,才能不耽误与各个客户端的“交易”过程。
于是,我们在服务端内部作好一种最基本的新体系,如下图:

- I/O处理单元:
- 接受客户连接
- 接收客户数据
- 将处理好的数据还给客户端
- 请求队列:
- 并非为真正的一个队列,而是一种单元间通信的抽象。
- 当I/O处理单元收到客户请求后,将客户请求交给逻辑单元处理
- 逻辑单元:
- 通常为一个进程或线程
- 分析客户数据,作出处理
- 将处理结果交给I/O单元(或者直接给客户端)
二.I/O模型
服务端与客户端交互的第一棒是I/O,而I/O又可以分为阻塞I/O和非阻塞I/O
阻塞I/O
基础API中,acept,send,recv,connect可能会被阻塞,而其一旦阻塞,操作系统就会将其挂起,直到其等待的事件发生为止(操作系统基础知识)。
非阻塞I/O
非阻塞I/O的系统调用总是被立刻返回,无论事件是否发生,若事件没有发生,系统调用就返回-1,并返回错误码errno,我们就要根据errno进行适当处理.
如:再试一次.
所以为了不影响非阻塞I/O的效率,非阻塞I/O就要和其他I/O通知机制配合使用,比如 I/O复用 和 SIGIO信号
I/O复用:
- 原理:应用程序通过I/O复用函数向内核注册一组事件,内核通过I/O复用函数把其中就绪的事件通知给应用程序.
- I/O复用函数
- select
- poll
- epoll_wait
[I/O复用文章链接]
SIGIO信号:
原理:我们为目标文件描述符指定一个宿主进程,宿主进程会捕获到SIGIO信号,当目标文件描述符上有事件发生时,SIGIO信号的信号处理函数将被触发,于是在该信号处理函数中,我们就可以进行非阻塞I/O操作.
[信号文章链接]
异步I/O
其实从理论上来说,上述的I/O模型都是同步I/O模型,因为I/O的读写操作都是在I/O事件发生后的.而真正的异步I/O模型是用户直接进行I/O读写操作,这些操作告诉内核:
1读写缓冲区的位置
2读写完成后怎么通知应用程序
所以异步I/O会"自动"进行I/O读写,不用在乎I/O事件和I/O读写的顺序.
PS:可以理解为同步I/O模型将数据的读和写操作按程序员写的代码来处理,而异步I/O模型将数据的读和写直接交给内核来处理,程序员只需要告诉内核一些注意事项即可.
三.两种高效的事件处理模式
前面我们已经了解了服务器编程的基础框架和几种不同的I/O模型,接下来我们将两者结合一下,就可以得到两种高效的事件处理模式
-
- Reactor
- Proactor
其中,同步I/O实现Reactor模式,异步I/O实现Proactor模式.
但同时,我们可以用同步I/O去模拟出Proactor处理模式.
Reactor
我们知道,服务器的内部有多个线程在工作,那么他们的结构是怎么样的呢?
一般的结构是将服务器的线程分为主线程和工作线程,其中主线程一直处于激活状态,而工作线程则可能睡眠,也可能工作.
在Reactor模式中:
- 主线程:
- 一直在监听文件描述符上是否有事件发生,有就通知工作线程
- 工作线程:
- 接受新的连接
- 读数据
- 处理客户请求
- 写数据
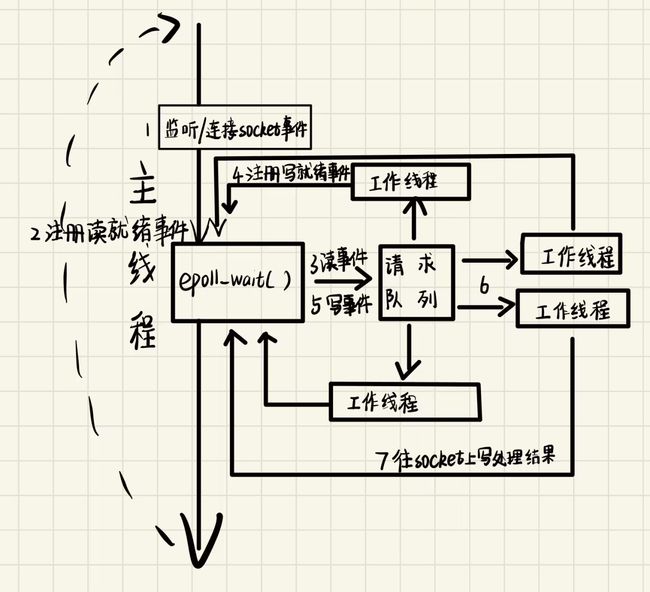
PS:图中工作线程并不是区分“读工作线程”和“写工作线程”,而是为了逻辑清晰而这样画,Reactor真正运行的过程中,工作线程将自己根据从请求队列取出的事件类型来决定如何处理
Proactor
Reactor是同步I/O模型的事件处理模式(只有在读/写就绪之后才能进行数据读/写操作)
而Proactor则需要异步I/O模型,即Proactor模式下,所有的I/O操作将由内核来处理,工作线程只负责业务逻辑。
Proactor模式中:
- 主线程:
- 一直在监听socket上的事件
- 向内核注册socket读完成事件,告诉内核用户读缓冲区位置,读操作完成时该怎么通知应用程序
- 内核
- 在读缓冲区上收到socket数据后,向程序发送一个信号通知,程序会根据信号处理函数选择工作线程进行处理
- 接受工作线程的写完成事件和写缓冲区位置
- 工作线程将写缓冲区的数据写入socket后,向程序发送一个信号通知,程序根据信号处理函数选择一个工作线程进行善后处理
- 工作线程:
- 处理业务逻辑

PS:主线程中的epoll仅仅用来检测 监听socket 上的连接请求事件,不能用来检测 连接socket 上的读写事件
四.模拟Proactor模式
通过观察我们发现,在Proactor模型中I/O交由内核处理,工作线程不需要进行数据的读写。因此,我们可以用主线程来完成一部分内核的功能来做到模拟Proactor模式。
即:主线程执行数据的读写操作,读写完成后,主线程向工作线程通知读写完成。这样从工作线程来看,就只需进行数据的逻辑操作了。

五.半同步/半异步的并发模式
CPU的并发可以显著提升程序的性能(操作系统基础知识),在服务器编程中,一种比较高效常见的并发编程模式是:半同步/半异步模式。
注意,这里的同步和异步与前文I/O模型的同步和异步是完全不同的概念。
在I/O模型中:
- 同步:内核向应用程序通知I/O就绪事件,由应用程序(工作线程)完成读写
- 异步:内核向应用程序通知I/O完成事件,内核自己完成读写
在并发模式中:
- 同步:代码按顺序执行
- 异步:代码可能受中断,信号等影响,交错地执行
在服务器的设计中,我们往往采用同步线程处理客户逻辑,异步线程处理I/O事件
这种并发模式结合事件处理模式和I/O模型,即可得到一种称为
半同步/半反应堆(half-sync/half-reactive)模式
从其名字可知,其采用的是Reactor的事件处理模式

该模式中,只有主线程是是异步线程,工作线程都是同步线程。
其工作流程细节:
主线程监听所有socket上的事件,如有有可读事件发生(新的连接到来),就获取其连接socket,并往epoll内核事件表中注册这个socket上的读写事件,然后将其插入请求队列。工作线程将其从中取出,进行读操作,逻辑处理,写操作等。
如何将其改成模拟Proactor事件模式:
主线程将socket的中的信息读出封装成一个任务对象,然后将这个任务对象(或指向这个任务对象的指针)插入请求队列,工作线程就只用处理,不必进行I/O操作了。
六.有限状态机
我们前面几节讨论了服务器 I/O处理单元,请求队列,逻辑单元之间协调完成任务的各种模式,现在我们来了解一下在逻辑单元内部的一种处理问题的编程方法:有限状态机。
在连接socket的数据被工作线程得到后,可以根据其应用层协议的头部类型字段的类型来进行不同的处理。其中每种不同的字段可以映射成有限状态机内的各种状态,每种状态下编写不同的处理代码。
同时,状态机还需要在不同的状态之间进行转移。
{
State cur_State = typeA;//1.初始状态
while(cur_State != typeC) {//2.当状态变成退出状态typeC时,退出循环
Package _pack = getNewPackage();
switch(cur_State) {
case type_A:
process_package_state_A(_pack);
cur_State = typeB;//3.切换状态
break;
case type_B:
process_package_state_B(_pack);
cur_State = typeC;//4.切换到退出状态
break;
}
}七.其他提高服务器性能的方法
前面的内容组成了一个高性能Web服务器的基础框架,下面我们再简要介绍其他几个方面:池,数据复制,上下文切换和锁
池
现代计算机的硬件资源大都十分充裕,所以我们可以用算法里的一个基本的思想来提高效率:用空间换时间。在Web服务器里,其具象化为池。
所谓池是一组资源的集合,这组资源在服务器启动的时候就已经初始化好了,当服务器进入正式运行阶段,需要某些资源,就不需要花费大量时间去动态申请,使用,释放,而直接从池里取出用即可,这就极大提高了服务器的运行效率。
池思想面临的困难:
我们不知道预先应该分配多少资源,应该怎么办?
解决方法:
- 分配非常多的资源,在大多数情况下不可能用完(不现实)
- 根据使用场景预估分配足够多的资源,如果不够用了,可以自动再扩充池
常用池:线程池,进程池,内存池,连接池。
数据复制
高性能服务器应该避免不必要的数据复制操作,且要善用零拷贝,共享内存等方式。
例如:FTP服务器,当客户请求一个文件时,服务器只需要检测目标文件是否存在,用户是否有读取它的权限即可,不必关心文件内的内容。所以FTP服务器无需将目标文件的内容完整地读到应用程序缓冲区中并调用send来进行发送,而是可以直接使用“零拷贝”函数send将其直接发给客户端。
上下文切换和锁
在web服务器地模型中,有人也许回想:我为每一个客户连接都创建一个工作线程可行吗?
答案是:不行。
因为这样会创建非常多的工作线程,而CPU的数量是有限的。而CPU在并发的工作模式下,会在同的线程之间进行切换,这种切换会消耗CPU资源,而处理业务逻辑的时间就会减少,如果线程太多,CPU就会频繁切换上下文而真正有意义的工作将大大减少。
我们提高服务器运行效率的其中一个重要方法是共享内存,但共享内存同时也会带来许多安全隐患问题,为了防止这些隐患,我们需要使用锁。而锁也会占用一定的系统资源,这种时候我们需要考虑使用粒度更小的锁,如读写锁等来提高性能。
八.一些废话
这篇文章我写了两天,算是自己对Web服务器框架的梳理。很显然,它并不完美也不全面,但是对于初学者来说应该已经够用了,在服务器基础框架这里有许多光看十分难理解的内容。比如:Reactor和Proactro处理模式到底是怎么搞得。这部分基本上要结合后面的实践才能有更深的理解。但是它也足够重要。写这篇文章的时候我腱鞘炎又犯了,写的非常痛苦。但好在写完了,在自己梳理一遍以后对服务器框架会更加清晰,这是光靠看所不能达到的。我推荐每一个做Web服务器的同学,都能自己去梳理一遍框架,这会对你对这个项目的理解更加深刻。
后面会尽快出I/O复用和信号的文章,讲解epoll和信号的有关内容。