CMU-MOSEI数据集解读
Multimodal Language Analysis in the Wild:CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph
作者:
- Amir Zadeh(Language Technologies Institute,CMU, USA)
- Paul Pu Liang(Machine Learning Department, CMU, USA)
- Jonathan Vanbriesen(Language Technologies Institute,CMU, USA)
- Soujanya Poria(A*STAR,Singapore)
- Edmund Tong(Language Technologies Institute,CMU, USA)
- Erik Cambria(Nanyang Technological University,Singapore)
- Minghai Chen(Language Technologies Institute,CMU, USA)
- Louis-Philippe Morency(Language Technologies Institute,CMU, USA)
发布时间:2018.7.15
paper:Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers)
论文链接:https://aclanthology.org/P18-1208.pdf
论文GitHub:https://github.com/A2Zadeh/CMU-MultimodalSDK
数据集下载链接:http://immortal.multicomp.cs.cmu.edu/raw_datasets/CMU_MOSEI.zip
论文结构:

数据集解读:
- 参考论文?官网?建库团队?
参考论文:CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph
官网:http://immortal.multicomp.cs.cmu.edu/raw_datasets/CMU_MOSEI.zip
建库团队:1- Language Technologies Institute,CMU, USA;2- Machine Learning Departmentg, CMU, USA;3- A*STAR, , Singapore;4- Nanyang Technological Universityg, Singapore
- 有几种模态?分别是哪些?
模态:3种(语言,视觉,声音)
- 哪些标签?如何标注的?
既有情感标注又有情绪标注。情感标注是对每句话的7分类的情感标注,作者还提供了了2/5/7分类的标注。情绪标注是包含高兴,悲伤,生气,恐惧,厌恶,惊讶六个方面的情绪标注。数据集是多标签特性,即每一个样本对应的情绪可能不止一种,对应情绪的强弱也不同,在[-3~3]之间。
- 如何得到这些数据集的?
收集的数据来自YouTube的独白视频,去掉了那些包含过多人物的视频,并通过注释和特征提取得到最终数据。
- 数据集大小?单个视频时长?
最终的数据集包含3228个视频,23453个句子,1000个讲述者,250个话题,总时长达到65小时(平均单个视频时长为0.02小时)
- 数据集内容topic
数据集一共包含250个主题(详细可见下文词云图)
- 建库年代?
2018年
- 被试情况?
GitHub上star数为480,fork数达147
论文翻译:
CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph
多模态语言分析:CMU-MOSEI 数据集和可解释的动态融合图
摘要
分析人类多模态语言是 NLP 的一个新兴研究领域。 本质上,人类交流是多模式(异类)、时间和异步的; 它由异步协调序列形式的语言(单词)、视觉(表达)和声学(副语言)模态组成。从资源的角度来看,真正需要能够对多模态语言进行深入研究的大规模数据集。在本文中,我们介绍了 CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI),这是迄今为止最大的情感分析和情感识别数据集。 使用来自 CMU-MOSEI 的数据和一种称为动态融合图 (DFG) 的新型多模态融合技术,我们进行了实验以研究模态如何在人类多模态语言中相互交互。与之前提出的融合技术不同,DFG 具有高度的可解释性,与当前最先进的技术相比,实现了具有竞争力的性能。
1 引言
语言起源理论将语言和非语言行为(视觉和声学模式)的组合确定为人类在整个进化过程中使用的主要交流形式(Müller,1866)。在自然语言处理中,这种形式的语言被认为是人类的多模态语言。 建模多模态语言最近已成为 NLP 和多模态机器学习的中心研究方向(Hazarika 等,2018;Zadeh 等,2018a;Poria等,2017a;Baltruˇsaitis 等,2017;Chen 等, 2017)。现有研究正尽力构建对多模态语言的双重动态模型:模态内动态(每个模态内的动态)和跨模态动态(跨不同模态的动态)。然而,从资源的角度来看,以往的多模态语言数据集在以下几个方面存在严重的不足:
训练样本的多样性:由于潜在分布的复杂性,训练样本的多样性对于综合多模态语言研究至关重要。这种复杂性源于语言、视觉和声学模态的模态内和跨模态动态的可变性(Rajagopalan 等,2016)。由于与数据获取和注释成本相关的困难,先前提出的多模态语言数据集通常规模较小。
主题的多样性:主题的多样性为跨不同领域的可概括研究打开了大门。仅在少数主题上训练的模型泛化能力很差,因为语言和非语言行为往往会根据主题对说话者内部心理状态的印象而改变。
演讲者的多样性:就像写作风格一样,演讲风格也非常独特。仅针对少数说话者的训练模型会导致退化解决方案,其中模型学习的是说话者的身份,而不是多模态语言的泛化模型(Wang 等,2016)。
注释的多样性:有多个要预测的标签使得可以研究标签之间的关系。拥有多种标签的另一个积极方面是允许多任务学习,这在过去的研究中表现出色。
我们在本文中的第一个贡献是介绍了最大的多模态情感和情感识别数据集,称为 CMU 多模态观点情感和情感强度 (CMUMOSEI)。CMU-MOSEI 包含来自 1000 个不同说话者的 23453 个带注释的视频片段和250 个主题。 每个视频片段都包含与音频到音素级别对齐的手动转录。所有视频均来自在线视频共享网站。该数据集目前是 CMU Multimodal Data SDK 的一部分,可通过Github免费提供给科学界。
我们的第二个贡献是一种称为动态融合图 (DFG) 的可解释融合模型,用于研究多模态语言中跨模态动力学的性质。DFG 包含与模态交互方式直接相关的内置功效。这些功效在我们的实验中被可视化和详细研究。除了可解释性之外,与之前在 CMU-MOSEI 上提出的多模态情感和情感识别模型相比,DFG 实现了卓越的性能。
2 背景
在本节中,我们将CMU-MOSEI 数据集与先前提出的用于建模多模态语言的数据集进行比较。然后,我们描述了用于情感分析和情感识别的baseline和最新模型。
2.1 与其他数据集的比较
我们将 CMU-MOSEI 与用于情感分析和情感识别的大量数据集进行比较。以下数据集的输入数据包括语言、视觉和声学模态的组合。
2.1.1 多模态数据集
CMU-MOSI (Zadeh等, 2016b) 是 2199 个意见视频片段的集合,每个片段都用 [-3,3] 范围内的情绪进行注释。CMU-MOSEI是CMU-MOSI的下一代。ICT-MMMO(W¨ollmer 等,2013 )由在线社交评论视频组成,这些视频在视频级别进行了情感注释。YouTube (Morency等., 2011) 包含来自社交媒体网站YouTube的视频,涵盖广泛的产品评论和意见视频。MOUD(Perez-Rosas 等,2013 )由西班牙语的产品评论视频组成。每个视频由多个标记为积极、消极或中性情绪的片段组成。IEMOCAP (Busso et al., 2008) 包含 151 个录制对话的视频,每个会话有 2 个演讲者,整个数据集共有 302 个视频。 每个部分被注释为存在 9 种情绪(愤怒、兴奋、恐惧、悲伤、惊讶、沮丧、快乐、失望和中性)以及效价、唤醒和支配。
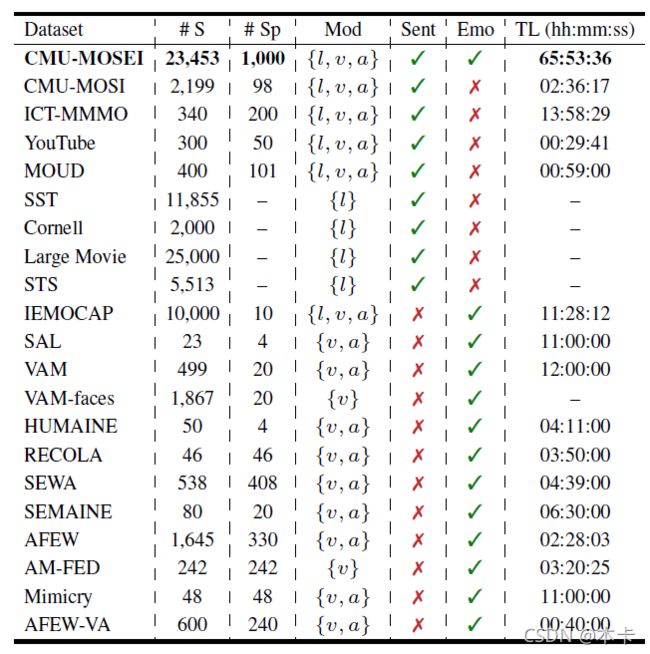
表1:CMU-MOSEI 数据集与之前的情感分析和情感识别数据集的比较。#S 表示注释数据点的数量。#Sp 是不同说话者的数量。Mod表示来自表示为{(l)anguage(语言);(v)ision;(视觉);(a)udio(声音)}的模态子集。Sent 和 Emo 列表示情绪和情感标签的存在。TL 表示视频总小时数。
2.1.2 语言数据集
Stanford Sentiment Treebank (SST) (Socher等, 2013) 在从电影评论数据中收集的句子的解析树中包含短语的细粒度情感标签。 虽然 SST 有更大的注释池,但我们只考虑根级注释进行比较。 Cornell Movie Review(Pang 等,2002 )是 2000 份电影评论文档和句子的集合,这些文档和句子根据其整体情绪极性或主观评分进行了标记。Large Movie Review数据集(Maas 等,2011 )包含来自高度极端电影评论的文本。Sanders Tweets Sentiment (STS) 由 5513 条手工分类的推文组成,每条推文都根据 Microsoft、Apple、Twitter 和 Google 的四个主题之一进行分类。
2.1.3 视觉和声学数据集
Vera am Mittag (VAM) 语料库包含 12 小时的德国电视谈话录音-视频 “Vera am Mittag”(格林等,2008 )。该视听数据被标记为三个情绪原语的连续值尺度:效价、激活和支配。VAM-Audio 和 VAMFaces 是分别包含声学和视觉输入的子集。RECOLA(Ringeval 等人,2013 年)包含 9.5 小时的在线二元交互的音频、视觉和生理(心电图和皮肤电活动)记录。Mimicry (Bilakhia等, 2015) 包含两种情况下人类互动的视听记录:讨论政治话题时和玩角色扮演游戏时。AFEW (Dhall et al., 2012, 2015) 是一个动态时间面部表情数据语料库,由从电影中提取的接近真实世界的环境组成。
CMU-MOSEI 与本节数据集的详细比较如表 1 所示。CMU-MOSEI 具有更长的总持续时间以及更多的数据点。 此外,CMU-MOSEI 的演讲者和主题的数量更多。 它提供了所有三种模式,以及情感和情感的注释。
2.2 基线模型
建模多模态语言一直是 NLP 和多模态机器学习研究的主题。 值得注意的方法列出如下,并在实验和讨论部分(第 5 节)中用符号表示以供参考。
- # MFN:(Memory Fusion Network)(Zadeh 等人,2018a)使用多视图门控存储器同步多模态序列,该存储器随时间存储视图内和跨视图交互。
- (小黑方块)MARN:(多注意循环网络)(Zadeh 等人,2018b)通过分配多个注意系数来模拟模内和多模态交互。 模内和跨模态交互存储在混合LSTM 内存组件中。
- (*)TFN(张量融合网络)(Zadeh 等人,2017年)通过创建一个多维张量来模拟模态间和模态内的相互作用,该张量可捕获单峰、双峰和三峰相互作用。
- □ \Box □MV-LSTM (Multi-View LSTM) (Rajagopalan et al., 2016) 是一个循环模型,它将 LSTM内的区域指定为不同的数据视图。
- (章节符)EF-LSTM(早期融合 LSTM)在每个时间步连接来自不同模态的输入,并将其用作单个 LSTM 的输入(Hochreiter 和Schmidhuber,1997;Graves等人,2013 年;Schuster 和 Paliwal,1997 年)。在单峰模型的情况下,EF-LSTM 指的是单个 LSTM。
我们还与以下基线模型进行了比较:† BC-LSTM (Poria et al., 2017b), ♣ \clubs ♣C-MKL (Poria et al., 2016), ♭ \flat ♭DF (Nojavanasghari et al., 2016), ♡ \heartsuit ♡SVM (Cortes 和 Vapnik,1995;Zadeh 等,2016b;Perez-Rosas 等,2013;Park 等,2014)、 ∙ \bullet ∙RF(Breiman,2001)、THMM(Morency 等,2011)、SAL-CNN (Wang 等人,2016 年)、3DCNN(Ji 等人,2013 年)。
对于仅语言基线模型:* ∪ \cup ∪CNN-LSTM** (Zhou et al., 2015)、RNTN (Socher et al., 2013)、×: DynamicCNN (Kalchbrenner et al., 2014)、 ⊳ \rhd ⊳DAN (Iyyer et al., 2015) )、 ≀ \wr ≀DHN (Srivastava et al., 2015)、 ⊲ \lhd ⊲RHN (Zilly et al., 2016)。
对于纯声学基线模型:AdieuNet (Trigeorgis et al., 2016)、SERLSTM (Lim et al., 2016)。
3 CMU-MOSEI 数据集
理解表达的情感和情绪是人类多模态语言中的两个关键因素。我们引入了一个用于多模态情绪和情感识别的新数据集,称为 CMU 多模态观点情绪和情感强度 (CMU-MOSEI)。在下面的小节中,我们首先解释了 CMU-MOSEI 数据获取的细节,然后是注释和特征提取的细节。
3.1 数据采集
社交多媒体提供了一个独特的机会,可以从不同的演讲者和话题中获取大量数据。这些社交多媒体网站的用户经常以独白视频的形式发表他们的意见;只有一个人在镜头前讨论某个感兴趣的话题的视频。每个视频固有地包含三种形式:口头文本形式的语言,通过感知手势和面部表情的视觉,以及通过语调和韵律的声音。
在我们的自动数据采集过程中,使用人脸检测分析来自 YouTube 的视频是否存在一个说话者,以确保视频是独白。我们通过拒绝带有移动摄像头的视频(例如自行车上的摄像头或边走边拍的自拍照),将视频限制在演讲者的注意力只集中在摄像头上的设置中。 我们使用在线视频中 250 个经常使用的主题作为获取的种子。我们限制从每个频道获取的视频数量最多为10个。结果从 YouTube 发现了 1000 个身份。身份的定义代表通道的数量,因为准确的识别需要二次手动注释,这对于大量说话者来说是不可行的。此外,我们限制视频具有上传者提供的手动和正确标点的转录。最终获得的视频库包括 5000 个视频,然后由 14 位专家评委在三个月内手动检查视频、音频和转录的质量。评委还对每个视频进行了性别注释,并确认每个视频都是可接受的独白。人工质检后剩余一组3228个视频。我们还使用面部特征提取置信度和强制对齐置信度对 3.3 节中讨论的视频和转录质量进行了自动检查。此外,我们使用评委提供的数据(57% 男性对 43% 女性)平衡数据集中的性别。这构成了 CMU-MOSEI 中的最后一组原始视频。最后一组视频中涵盖的主题在图 1 中显示为维恩式词云(Coppersmith 和 Kelly,2014),其大小与为该主题收集的视频数量成正比。最常见的 3 个主题是评论 (16.2%)、辩论 (2.9%) 和咨询 (1.8%)。 其余主题几乎均匀分布。
 图 1:CMUMOSEI 中视频主题的多样性,显示为词云。较大的词表示来自该主题的更多视频。 最常见的 3 个主题是评论(16.2%)、辩论(2.9%)和咨询(1.8%),其余主题几乎均匀分布。
图 1:CMUMOSEI 中视频主题的多样性,显示为词云。较大的词表示来自该主题的更多视频。 最常见的 3 个主题是评论(16.2%)、辩论(2.9%)和咨询(1.8%),其余主题几乎均匀分布。
然后将最终的视频集标记为使用由抄本手动提供的标点符号的句子。由于数据的高质量,使用标点符号显示出比使用斯坦福 CoreNLP 分词器更好的句子质量(Manning 等,2014)。两位专家在一组 20 个随机视频中验证了这一点。标记化后,选择一组 23,453 个句子作为数据集中的最终句子。这是通过限制每个身份对数据集贡献至少 10 个和最多 50 个句子来实现的。 表 2 显示了 CMU-MOSEI 数据集的高级汇总统计数据。
 表 2:CMU-MOSEI 数据集统计数据摘要。
表 2:CMU-MOSEI 数据集统计数据摘要。
3.2 注释
CMU-MOSEI 的注释与 CMU-MOSI (Zadeh等, 2016a) 和 Stanford Sentiment Treebank (Socher等, 2013) 的注释密切相关。每个句子都在 [-3,3] 里克特量表上针对情绪进行注释:[-3:高度负面,-2 负面,-1 弱负面,0 中性,+1 弱正面,+2 正面,+3 高度正面 ]。Ekman 情绪 (Ekman等, 1980)包括{快乐、悲伤、愤怒、恐惧、厌恶、惊讶}在 [0,3] 范围的里克特量表上注释,用于情绪 x 的存在:[0:没有 x 的证据,1:弱 x, 2: x, 3: 高度 x]。注释由来自 Amazon Mechanical Turk 平台的 3 位众包评委进行。为了避免对评委产生偏见并捕捉人群的原始感知,我们避免了极端的注释训练,而是为评委提供了 5 分钟的关于如何使用注释系统的培训视频。 4、所有标注均由通过率高于98%的大师级工人完成,以保证高质量的标注。
 图 2:CMU-MOSEI 数据集中的情绪和情绪分布。该分布显示出更频繁使用的情绪的自然倾斜。然而,最不常见的情绪,恐惧,仍然有 1900 个数据点,这是机器学习研究可以接受的数字。
图 2:CMU-MOSEI 数据集中的情绪和情绪分布。该分布显示出更频繁使用的情绪的自然倾斜。然而,最不常见的情绪,恐惧,仍然有 1900 个数据点,这是机器学习研究可以接受的数字。
图 2 显示了情绪和CMU-MOSEI 数据集中的情绪。分布显示出有利于积极情绪的轻微转变
这类似于 CMU-MOSI 和SST的分布。我们认为这是在线意见略微转向积极时的一种隐含的偏见,因为这也存在于 CMU-MOSI 中。 情绪直方图显示了不同的情绪的不同流行度。最常见的类别是超过 12000 个的幸福正样本。 最不普遍的情绪是包括近 1900 个恐惧正样本点,这都是机器学习研究可接受的数字。
3.3 提取特征
CMU-MOSEI 中的数据点以视频格式出现,摄像头前有一个扬声器。 每种模态的提取特征如下(对于其他基准我们提取相同的特征):
语言:所有视频都有手动转录。Glove word embeddings(Pennington 等,2014 )用于从转录本中提取词向量。使用 P2FA 强制对齐模型(Yuan 和 Liberman,2008)在音素级别对齐单词和音频。 在此之后,视觉和听觉模式通过插值与单词对齐。 由于英语单词的发音持续时间通常较短,因此这种插值不会导致大量信息丢失。
视觉:从 30Hz 的完整视频中提取帧。使用 MTCNN 人脸检测算法(Zhang等, 2016)提取人脸的边界框。我们通过面部动作编码系统 (FACS) (Ekman等., 1980) 提取面部动作单元。 提取这些动作单元可以准确跟踪和理解面部表情 (Baltruˇsaitis等,2016)。 我们还使用 Emotient FACET (iMotions, 2017) 从静态人脸中提取了一组六种基本情绪。 MultiComp OpenFace (Baltruˇsaitis等, 2016) 用于提取 68 个面部标志、20 个面部形状参数、面部 HoG 特征、头部姿势、头部方向和眼睛注视 (Baltruˇsaitis et al., 2016) 的集合。最后,我们从常用的面部识别模型中提取人脸嵌入,例如 DeepFace(Taigman 等人,2014)、FaceNet(Schroff 等人,2015)和 SphereFace(Liu 等人,2017)。
声学:我们使用 COVAREP 软件(Degottex 等人,2014 年)提取声学特征,包括 12 个 Mel 频率倒谱系数、音高、浊音/清音分段特征(Drugman 和 Alwan,2011 年)、声门源参数(Drugman 等人,2014 年)。 , 2012; Alku et al., 1997, 2002),峰值斜率参数和最大色散商数 (Kane and Gobl, 2013)。 所有提取的特征都与情绪和语气有关。
4 多模态融合研究
从语言学的角度来看,理解多模态语言中语言、视觉和音频模态之间的相互作用是一个基础研究问题。 虽然以前的工作在准确性指标方面取得了成功,但他们并没有就融合是如何进行的,以及融合过程中融合过程中融合的方式和交互方式产生了新的见解。具体来说,要了解融合过程,必须首先了解n-modal dynamics (Zadeh 等,2017)。 n-modal dynamics 表明存在不同的模态组合,并且必须捕获所有这些组合才能更好地理解多模态语言。在本文中,我们将构建 n-modal dynamics 定义为一个分层过程,并提出了一种称为动态融合图 (DFG) 的新融合模型。 DFG 很容易通过所谓的图连接中的功效来解释。为了在多模式语言框架中利用这种新的融合模型,我们通过用我们的 DFG 替换 MFN 中的原始融合组件来构建记忆融合网络 (MFN)。我们将此结果模型称为图记忆融合网络 (Graph-MFN)。 一旦模型经过端到端的训练,我们将分析 DFG 中的功效,以研究为多模态语言中的模态学习的融合机制。 除了是一种可解释的融合机制,Graph-MFN 在 CMU-MOSEI 上也优于先前提出的用于情感分析和情感识别的最先进模型。
4.1 动态融合图
在本节中,我们将讨论所提出的动态融合图 (DFG) 神经模型的内部结构(图 3。DFG 具有以下特性:
1)它显式地对 n 模态交互进行建模;
2)使用有效数量的参数进行建模 (与之前的方法如 Tensor Fusion (Zadeh等, 2017))
3) 可以动态改变其结构并根据推理过程中每个 n 模态动力学的重要性选择合适的融合图。
我们假设这组模态为 M = { ( l ) a n g u a g e ; ( v ) i s i o n ; ( a ) u d i o } M = {\{(l)anguage; (v)ision; (a)udio\}} M={(l)anguage;(v)ision;(a)udio}。单峰动力学表示为 { l } ; { v } ; { a } {\{l\}};{\{v\}}; {\{a\}} {l};{v};{a},双峰动力学为 { l , v } ; { v , a } ; { l , a } {\{l,v\}}; {\{v,a\}}; {\{l,a\}} {l,v};{v,a};{l,a}和三峰动力学为 { l , v , a } {\{l,v,a\}} {l,v,a}。这些动态以潜在表示的形式出现,每个都被视为图 G = ( V ; E ) G = (V;E) G=(V;E) 内的顶点,其中 V V V 是顶点集, E E E 是边集。仅当 v i ⊂ v j v_i\subset v_j vi⊂vj 时才在两个顶点 v i v_i vi 和 v j v_j vj 之间建立定向神经连接。例如, { l } ⊂ { l , v } {\{l\}}\subset{\{l ,v\}} {l}⊂{l,v} 导致 < l a n g u a g e >
我们为表示为 α i j \alpha_{ij} αij 的每条边 e i j e_{ij} eij定义了一个功效。 v i v_i vi 在用作 D j D_j Dj 的输入之前乘以 α i j \alpha_{ij} αij。 每个 α \alpha α都是一个 sigmoid 神经元激活概率,表示 v i v_i vi 和 v j v_j vj 之间的连接强弱。 α s \alpha s αs是 DFG 中可解释性的主要来源。使用深度神经网络 D α D_\alpha Dα 推断所有 α s \alpha s αs 的向量,该网络将 V ( l 、 v 和 a ) V(l、v 和a) V(l、v和a)中的单例顶点作为输入。我们让监督训练目标来学习 D α D_\alpha Dα 的参数并充分利用功效,从而动态控制图的结构。出于此目的选择单例顶点,因为它们没有传入边,因此没有与这些边相关联的功效(不需要功效来推断单例顶点)。相同的单例顶点 l l l、 v v v 和 a a a 是 DFG 的输入。 在下一节中,我们将讨论如何将这些输入提供给 DFG。 所有顶点都通过由它们各自的功效缩放的边连接到网络的输出顶点 Γ t \Gamma_t Γt。顶点、边和各自功效的整体结构如图3所示。总共有8个顶点(计算输出顶点)、19个边和随后的19个功效。
 图 3:三种模态的动态融合图 (DFG) 结构; 包括 { ( l ) a n g u a g e ; ( v ) i s i o n ; ( a ) u d i o } {\{(l)anguage; (v)ision; (a)udio\}} {(l)anguage;(v)ision;(a)udio}。DFG 中的虚线显示了由功效 ( α \alpha α) 控制的顶点之间的动态连接。
图 3:三种模态的动态融合图 (DFG) 结构; 包括 { ( l ) a n g u a g e ; ( v ) i s i o n ; ( a ) u d i o } {\{(l)anguage; (v)ision; (a)udio\}} {(l)anguage;(v)ision;(a)udio}。DFG 中的虚线显示了由功效 ( α \alpha α) 控制的顶点之间的动态连接。
4.2 Graph-MFN
为了测试 DFG 的性能,我们使用了类似于内存融合网络 (MFN) 的循环架构。MFN 是一个循环神经模型,具有三个主要组成部分
- LSTM 系统:一组并行 LSTM,每个 LSTM 建模一个模态。
2)Delta-memory Attention Network是执行多模态融合的组件,通过分配系数来突出跨模态动态。 - Multiview Gated Memory 是一个存储多模态融合输出的组件。
我们用 DFG 替换了 Delta-memory 注意力网络,并将修改后的模型称为 Graph Memory Fusion Network (Graph-MFN)。图 4 显示了 Graph-MFN 的整体架构。
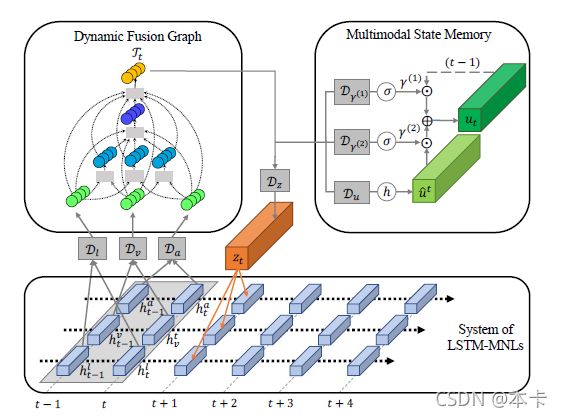
图 4:图内存融合网络 (Graph-MFN) 框架概述。 Graph-MFN 用动态融合图 (DFG) 替换了 MFN 中的融合块。有关变量和内存公式的描述,请参阅原始内存融合网络论文(Zadeh 等,2018a)。
与 MFN 类似,Graph-MFN 使用 LSTM 系统对单个模态进行建模。 c l c_l cl、 c v c_v cv 和 c a c_a ca 分别代表 LSTM 对语言、视觉和声学模态的记忆。 D m , m ∈ { l , v , a } D_m,m \in {\{l,v,a\}} Dm,m∈{l,v,a} 是一个完全连接的深度神经网络,它在两个连续的时间戳中接受 h [ t − 1 , t ] m h_{[t−1,t]}^m h[t−1,t]m LSTM 表示,这允许网络跟踪内存维度随时间的变化。 D l D_l Dl、 D v D_v Dv 和 D a D_a Da 的输出是 DFG 的单例顶点。DFG 对跨模态交互进行建模,并在其输出顶点 Γ t \Gamma_t Γt 中对跨模态表示进行编码,以便存储在多视图门控内存 u t u_t ut 中。Multi-view Gated Memory 使用网络 D u D_u Du 运行,该网络将 Γ t \Gamma_t Γt 转换为建议的内存更新 u ^ t \hat{u}_t u^t γ 1 \gamma_1 γ1和 γ 2 \gamma_2 γ2 分别是多视图门控存储器的保留和更新门,并使用网络 D γ 1 D_ {\gamma_1} Dγ1 和 D γ 2 D_{\gamma_2} Dγ2 学习。最后,网络 D z D_z Dz 将 Γ t \Gamma_t Γt转换为多模态表示 z t z_t zt 以更新 LSTM 系统。Graph-MFN 在所有实验中的输出是每个 LSTM h T m h_T^m hTm 的输出以及多视图门控存储器在时间 T T T(最后一个循环时间步长) u T u_T uT 的内容。 这个输出随后连接到分类或回归层以进行最终预测(用于情感和情感识别)。
5 实验与讨论
在我们的实验中,我们试图通过研究 DFG 随时间变化的功效来评估多模态融合过程中模态的相互作用。

表 3:对 MOSEI 数据集进行情感分析和情感识别的结果(报告结果截至 2018 年 5 月 11 日。请查看 CMU Multimodal Data SDK github,了解 CMU-MOSEI 和其他数据集的最新技术和新功能 )。 SOTA1 和 SOTA2 分别指的是之前最好的和第二好的最先进的模型(来自第 2 节)。 与基线相比,Graph-MFN 在情感分析和情感识别方面取得了优异的表现。对于所有指标,较高的值表示更好的性能,但 MAE 除外,其较低的值表示更好的性能。
表 3 显示了 CMU-MOSEI 的结果。准确性报告为 A x A_x Ax,其中 x x x 是情感类别的数量以及 F1 度量。对于回归,我们报告 MAE 和相关性 ( r r r)。 对于由于各种情绪之间的自然不平衡而导致的情绪识别,我们使用加权准确率(Tong 等,2017)和 F1 度量。Graph-MFN 在情感分析和情感识别方面表现出优异的性能。因此,DFG 是一种有效且可解释的多模态融合模型。
为了更好地理解模态之间的内部融合机制,我们将图 5 中学习的 DFG 功效的行为可视化为各种情况(深红色表示高效,深蓝色表示低效)。
多模态融合具有易变的性质:第一个观察结果是 DFG 的结构随着时间的推移逐个发生变化。 因此,该模型似乎选择性地将某些动态置于其他动态之上。例如,在所有模式都提供信息的情况 (I) 中,所有效率似乎都很高,这意味着DFG 能够在单峰、双峰和三峰相互作用中找到有用的信息。然而,在情况 (II) 和 (III) 中,视觉模态要么没有信息,要么相互矛盾, v → l v\rightarrow l v→l, v v v 和 v → l v\rightarrow l v→l, a a a, v v v 和 l l l, a → l a\rightarrow l a→l, a a a, v v v的功效。 v v v 减少,因为没有有意义的交互涉及视觉模式。
融合中的先验:某些功效在不同情况下和时间上保持不变。这些是 DFG 学习的人类多模态语言的先验。例如,模型似乎总是在 ( l → l , a ) (l\rightarrow l,a) (l→l,a) 和 ( a → l , a ) (a\rightarrow l,a) (a→l,a) 中优先考虑语言和音频之间的融合。随后,DFG 对单方面依赖于语言或音频的功效给出了较低的值: ( l → τ ) (l\rightarrow \tau) (l→τ) 和 ( a → τ ) (a\rightarrow \tau) (a→τ) 功效似乎一直很低。 另一方面,视觉模式似乎具有部分孤立的行为。 在存在信息性视觉信息的情况下,该模型提高了 ( v → τ ) (v\rightarrow \tau) (v→τ) 的功效,尽管其他视觉功效的值也增加了。
多模态融合的踪迹:我们追溯每种模态在融合过程中经历的主要路径:1) l a n g u a g e language language倾向于首先通过 ( l → l , a ) (l\rightarrow l,a) (l→l,a) 与音频融合,语言和声学模态共同参与更高级别的融合,例如 ( l , a → l , a , v ) (l,a\rightarrow l,a,v) (l,a→l,a,v)。直观地说,这与语言和音频通过单词语调之间的密切联系是一致的。2) v i s i o n vision vision模式似乎只有在包含有意义的信息时才会进行融合。在情况(I)和(IV)中,所有涉及视觉模态的路径都相对活跃,而在情况(II)和(III)中涉及视觉模式的路径的效率低下。3)声学情态大多与语言情态融合在一起。然而,与语言不同的是,如果两种模态都有意义,例如在情况 (I) 中,声学模态似乎也与视觉模态融合。
一个有趣的观察结果是,在几乎所有情况下,到终端 Γ \Gamma Γ 的单峰连接的效率都很低,这意味着 Γ \Gamma Γ 更喜欢不只依赖一种模态。 此外,DFG 总是更喜欢在语言和音频之间进行融合,因为在大多数情况下都是 l → l , a l\rightarrow l, a l→l,a 和 a → l , a a\rightarrow l,a a→l,a 功效高;直观地,在大多数自然场景中,语言和声学模态高度一致。这两种情况都显示出不变的行为,我们认为 DFG 已经习得了人类交流信号的自然先验。
通过这些观察,我们相信 DFG 已经成功地学会了如何管理其内部结构来模拟人类交流。
六,结论
在本文中,我们提出了最大的多模态情感分析和情感识别数据集,称为 CMU 多模态观点情感和情感强度 (CMU-MOSEI)。 CMUMOSEI 包含来自 1000 多名在线演讲者和 250 个不同主题的 23453 个带注释的句子。该数据集扩展了 NLP 中人类多模态语言研究的视野。本文介绍了一项这样的研究,我们分析了情感分析和情感识别中多模态融合的结构。 这是使用一种称为动态融合图 (DFG) 的新型可解释融合机制完成。 在我们的研究中,我们使用 DFG 的内置功效调查了模式在相互交互中的行为。 除了融合分析之外,DFG 在记忆融合网络管道中进行了训练,并在情感分析和情感识别方面表现出优异的性能。
致谢
本文基于美国国家科学基金会(奖号 #1833355)和 Oculus VR 部分支持的工作。 本文中表达的任何意见、发现、结论或建议均为作者的观点,不一定反映美国国家科学基金会或 Oculus VR 的观点,不应推断出官方认可。