大数据开发之Hive(详细版,最后有实战训练)
第 1 章:Hive基本概念
1.1 Hive
1.1.1 Hive产生背景
HDFS来存储海量的数据、MapReduce来对海量数据进行分布式并行计算、Yarn来实现资源管理和作业调度。但是面对海量的数据和负责的业务逻辑,开发人员要编写MR对数据进行统计分析难度极大,所以就产生了Hive这个数仓工具。Hive可以帮助开发人员将SQL语句转化为MapReduce在yarn上跑。
1.1.2 hive简介
Hive是基于hadoop的一个数据仓库工具,将结构化的数据文件映射成一张表,并提供类SQL(HQL)查询功能。
1.1.3 Hive本质:将HQL(hiveSQL)转化成MapReduce程序

1、Hive处理的数据存储在HDFS
2、Hive分析数据底层的实现是MapReduce
3、执行程序运行在Yarn上
4、结构化文件如何映射成一张表呢?借助存储在元数据数据库中的元数据来解析结构化文件。
1.2 Hive架构原理

1.2.1 Hive架构介绍
| 1)用户结构:Client | CLI(command-line interface)、JDBC/ODBC(jdbc访问hive) | |
|---|---|---|
| 2)元数据:Metastore | 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore | |
| 3) Hadoop | 使用HDFS进行存储,使用MapReduce进行计算 | |
| 4) 驱动器:Driver | 解析器(SQL Parser) | 将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误 |
| 编译器(Physical Plan) | 将AST编译生成逻辑执行计划 | |
| 优化器(Query Optimizer) | 对逻辑执行计划进行优化 | |
| 执行器(Execution) | 把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark |
1.2.2 Hive的运行机制

hive通过给用户提供的一系列交互接口,接受到的用户指令(SQL),使用自己Driver,结合元数据(metaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口中。
1.3 Hive和数据库比较
| Hive | mysql | |
|---|---|---|
| 语言 | 类sql | sql |
| 语言规模 | 大数据pd及以上 | 数据量小一般在百万左右到达单表极限 |
| 数据插入 | 能增加insert,不能update,delete | 能insert,update,delete |
| 数据存储 | Hdfs | 拥有自己的存储空间 |
| 计算引擎 | MapReduce/Spark/tez | 自己的引擎innodb |
第 2 章:Hive安装
2.1 修改hadoop相关参数
1)修改core-site.xml
1、配置该superUser允许通过代理访问的主机节点
2、配置该superUser允许通过代理用户所属组
3、配置该superUser允许通过代理的用户
2)配置yarn-site.xml
1、NodeManager使用内存数,默认是8G,修改成4G内存
2、容器最小内存,默认512M
3、容器最大内存,默认是8G,修改成4G
4、关闭虚拟内存检查(默认开启)
3)分发修改后的配置文件
2.2 Hive解压安装
1)上传压缩包到linux的/opt/softsware目录下
2)将/opt/softsware目录下的压缩包解压到/opt/module目录下
3)将解压后的文件修改成hive
4)修改/etc/profile.d/my_env.sh文件,将hive的/bin目录添加到环境变量
2.3 Hive元数据的三种部署方式
2.3.1 元数据库之Derby
这种方式适用于轻量级或者单机模式的部署,通常用于测试或开发环境。配置相对简单,但不适合高可用性和大规模部署。
1、内嵌模式示意图:

2、Derby数据库:
Derby数据库是Java编写的内存数据库,在内嵌模式中与应用程序共享一个JVM,应用程序负责启动和停止。
3、初始化Derby数据库:
1)在hive根目录下,使用/bin目录下的schematool命令初始化hive自带的Derby元数据库
2)执行上述初始化元数据库时,会发生存在jar包冲突问题
3)解决jar包冲突问题,只需要把hive的/lib目录下的log4j~.jar重命名即可
4、启动Hive
1)执行/bin目录下的hive命令,就可以启动hive,并通过cli方式连接到hive
2)使用hive
- show databases; 查看当前所有的数据库
- show tables; 查看当前所有的表
- create table test_derby(id int); 创建表
- insert into test_derby values(1001); 插入数据
- select * from test_derby; 查看数据
5、内嵌模式只有一个JVM进程
在内嵌模式下,命令行执行jps -ml命令,只能看到一个CliDriver进程。
2.3.2 元数据库之Mysql
这种方式更加适合生产环境,因为它支持多用户并发访问和更好的可伸延性。需要额外的配置和管理数据库服务。
1、直连模式示意图:

2、Mysql安装部署
1)检测当前系统是否安装过Mysql,如果安装过删除掉
2)将Mysql安装包上传至/opt/software目录下
3)解压到/opt/software下新建的mysql_jars目录
4)查看mysql_jars目录下文件
5)在/opt/software/mysql_jars目录下执行rpm安装,按顺序
6)如果在mysql的数据存储路径下有文件存在,需要将其全部删除,存储路径地址在/etc/my.cnf文件下datadir参数所对应的值
7)初始化数据库,查看临时的root用户的密码
8)启动mysql服务
9)登录mysql,修改root用户的密码
10)修改mysql库下的user表中的root用户允许任意ip连接
11)刷新,使得修改生效
3、配置Hive元数据库为MySQL
1)拷贝驱动
Hive需要将元数据信息存储到元数据库mysql中,需要使用JDBC的方式连接到Mysql,所以,将Mysql的JDBC驱动拷贝到Hive的lib目录下,供hive调用。
2)配置Metastore到Mysql
在/opt/module/hive/conf目录下新建hive-site.xml文件
(1)jdbc连接的URL
(2)jdbc连接的Driver
(3)jdbc连接的username
(4)jdbc连接的password
(5)Hive默认在HDFS的工作目录
(6)Hive元数据存储的验证设置false
(7)元数据存储授权设置false
4、Hive初始化元数据库
在mysql中创建hive存储元数据的数据库metastore,再通过hive的初始化元数据库操作创建表
1)登录mysql
2)新建Hive元数据库
3)初始化Hive元数据库
5、启动Hive
1)启动Hive
2)使用hive
- show databases; 查看当前所有的数据库
- show tables; 查看当前所有的表
- create table test_mysql(id int); 创建表
- insert into test_mysql values(1002); 插入数据
- select * from test_mysql; 查看数据
3)开启另一个窗口测试,是否支持客户端并发操作
6、在公司生产环境中,网络环境非常的复杂,mysql的所在环境可能存在网络隔离,无法直接访问;另外,mysql的root账户和密码在此模式下会存在泄露风险,存在数据安全隐患。
2.3.3 元数据之MetaStore Server
在这种模式下,Hive与Hadoop生态系统中的其他组件共享元数据,这种方式可以实现元数据的高度集成和优化。
1、元数据服务模式示意图:

2、元数据服务模式
在服务器端访问MetaStore服务,客户端利用Thrift协议通过MetaStore服务访问元数据库。相比于内嵌式,这种更适合在生产环境中部署使用。
3、将Mysql作为元数据库,配置元数据服务
1)首先,将hive的元数据库配置为Mysql,编写hive-site.xml文件。在配置完后,启动hive之前必须先启动元数据服务,否则,hive启动后无法连接到元数据服务。
2)启动元数据服务
注意:启动后窗口不能再操作,需打开一个新的shell窗口做别的操作。
(1)启动hive,查看表和表中的数据,是否是Mysql数据库中的表。
(2)再另一个窗口启动hive,测试多客户端能否同时连接操作。
2.4 hive的两种访问方式
2.4.1 命令行方式
1、cli太过笨重,需要hive的jar支持。
2.4.2 HiveServe2 模式
1、JDBC访问Hive示意图:

2、JDBC方式访问Hive
将hive包装为服务发布出去,开发者使用JDBC的方式连接到服务,从而操作hive,减少对hive环境的依赖。
3、开启Hiveserver2
1)在hive-site.xml文件中添加如下配置信息
(1)指定hiveserver2连接的host
(2)指定hiveserver2连接的端口号
2)重启MetaStore服务
3)启动hive服务(如果是使用元数据服务的模式,需要提前开启元数据服务)
4)启动beeline服务
2.5 Hive常用交互命令
2.5.1 查看bin/hive命令帮助
- bin/hive -help
2.5.2 命令中参数-e的使用
使用-e参数,可以不进入hive的交互窗口执行sql语句
2.5.3 命令中参数-f的使用
使用-f参数,可以不进入hive交互窗口,执行脚本中sql语句
1)在/opt/module/hive/下创建datas目录并在目录下创建hive-f.sql文件
2)文件中写入正确的sql语句
3)执行文件中的sql语句,还可以将结果写入指定文件中
第 3 章 Hive数据类型
3.1 基本数据类型
| Hive数据类型 | Java数据类型 | 长度 |
|---|---|---|
| TINYINT | byte | 1byte有符号整数 |
| SWALINT | short | 2byte有符号整数 |
| INT | int | 4byte有符号整数 |
| BIGINT | long | 8byte有符号整数 |
| BOOLEAN | boolean | 布尔类型,true或者false |
| FLOAT | float | 单精度浮点数 |
| DOUBLE | double | 双精度浮点数 |
| STRING | string | 字符系列。可以使用单引号或者双引号 |
| TIMESTAMP | 时间类型 | |
| BINARY | 字节数组 |
Hive的String类型不用声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
3.2 集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如:如果某个列的数据类型是STRUCT{first STRING, last String},那么第1个元素可以通过字段.first来引用。 | struct() 例如: struct |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如:如果某个列的数据类型是MAP,其中键->值对是’first’->'john’和‘last’->‘doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() 例如:map |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如:数组值为[‘john’,‘doe’] ,那么第2个元素可以通过数组名[1]进行引用 | Array() 例如:array |
3.3 案例操作
3.3.1 简单了解前后端的数据传输

3.3.2 数据结构映射
1)假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 19 ,
"xiaoxiao song": 18
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
2)基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
在目录/opt/module/hive/datas下创建本地测试文件personInfo.txt
- vim personInfo.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
3.3.3 测试案例
1)Hive上创建测试表personInfo
hive(default)>create table personInfo (
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
指定数据文件中行格式的分隔符
指定字段之间用’,’进行分割
指定集合类型的元素之间用’_’进行分割
指定map类型中key和value用’:’进行分割
指定行之间的分隔符为’\n’
2)上传数据到hdfs中上述表的对应路径
hadoop fs -put /opt/module/hive/datas/personInfo.txt /user/hive/warehouse/personInfo;
3)访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
select
friends[1],
children['xiao song'],
address.city
from personInfo
where name="songsong";
结果:
_c0 _c1 city
lili 18 beijing
3.4 类型转换
1)Hive的基本数据类型进行隐性转换类似Java
2)隐式类型转换规则如下
(1)所有整数类型都可以隐式的转换为一个范围更广的类型,如INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
3)可以使用CAST操作显示进行数据类型转换
例如:CAST(‘1’ AS INT)将把字符串‘1’转换成整数1;
第4章:DDL 数据定义
4.1 创建数据库
1)创建数据库,数据库在HDFS上的默认存储路径是/usr/hive/warehouse/*.db。
create database bigdata;
2)避免要创建的数据库已经存在,增加if not exists判断。
create database if not exists bigdata;
3)创建一个数据库,指定数据库在HDFS上存放的位置
create database bigdata2 location '/bigdata2.db';
4.2 查询数据库
4.2.1 显示数据库
1)显示数据库
show databases;
2)过滤显示查询的数据库
show databases like 'bigdata*';
4.2.2 查看数据库详情
1)显示数据库信息
desc database bigdata;
bigdata hdfs://hadoop102:9000/user/hive/warehouse/bigdata.db atguigu USER
2)显示数据库详细信息,extended
desc database extended bigdata;
bigdata hdfs://hadoop102:9000/user/hive/warehouse/bigdata.db atguigu USER
3)创建数据库bigdata3,并设置其createtime属性
create database bigdata3 with dbproperties('createtime'='20211022');
4)再次查询
desc database bigdata3
OK
bigdata3 hdfs://hadoop102:8020/user/hive/warehouse/bigdata3.db atguigu USER
desc database extended bigdata3
OK
bigdata3 hdfs://hadoop102:8020/user/hive/warehouse/bigdata3.db atguigu USER {createtime=20211022}
4.2.3 切换当前数据库
use bigdata;
4.3 修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。
alter database bigdata set dbproperties('createtime'='20211022');
4.4 删除数据库
1)删除空数据库
drop database if exists bigdata2
2)如果数据库不为空,可以采用cascade命令,强制删除
drop database bigdata cascade;
4.5 创建表
1)建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
[LIKES existing_table_or_view_name]
2)字段解释说明
| CREATE TABLE | 创建一个指定名称的表。如果相同名称的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项忽略这个异常 |
|---|---|
| EXTERNAL | 1)关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION)2)在删除表的适合,内部表的元数据和数据都被一起删除,外部表只删除元数据,不删除数据。 |
| COMMENT | 为表和列添加注释 |
| PARTITIONED BY | 创建分区表 |
| CLUSTERED BY | 创建分桶表 |
| SORTED BY | 不常用,对桶中的一个或多个列另外排序 |
| ROW FROMAT | Fields 指定字段之间的分隔符;Collection 用于指定集合中元素的分隔符等 |
| STORE AS | 指定存储文件类型:如SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件) |
| LOCATION | 指定表在HDFS上的存储位置 |
| AS | 后跟查询语句,根据查询语句结果创建表 |
| LIKE | 允许用户复制现有的表结构,但是不复制数据 |
4.5.1 管理表(内部表)
1)理论
- 默认创建的表都是所谓的管理表,有时也被称为内部表。
- 管理表,Hive会控制着元数据和真实数据的生命周期。
- Hive默认会将这些表的数据存储在hive.metastore.warehouse.dir定义目录的子目录下。
- 当我们删除一个管理表时,Hive也会删除这个表中数据。
- 管理表不适合和其他工具共享数据。
2)案例实操
创建数据文件,在/opt/module/hive/datas目录下创建文件student.txt,编辑如下内容:
vim student.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
(1)创建内部表student
create table if not exists student(
id int,
name string
)
row format delimited
fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student';
(2)查询表的类型
desc formatted student;
Table Type: MANAGED_TABLE
(3)根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student2 as select id, name from student;
(4)根据已经存在的表结构创建表
create table if not exists student3 like student;
(5)查询表的类型
desc formatted student2;
Table Type: MANAGED_TABLE
(6)删除表student2后,观察表的元数据和数据文件是否还存在
drop table student2;
4.5.2 外部表
1、理论
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
元数据信息:指存储在Hive元数据仓库中的关于表的信息,例如表名、表结构(列名和数据类型)、表的物理位置(文件路径)等。这些信息帮助Hive了解如何访问和解释存储在外部位置的数据。
2、管理表和外部表的使用场景
外部表多用来存储原始数据,采用外部表交易共享数据。在原始数据基础上做大量的统计分析,中间用到的中间表、结果表多存于内部表。
3、案例实操
1)创建teacher.txt
1001 teacher1
1002 teacher2
1003 teacher3
1004 teacher4
1005 teacher5
2)上传数据到HDFS
hadoop fs -mkdir -p /school/teacher
hadoop fs -put teacher.txt /school/teacher
3)在hive中创建外部表teacher
create external table if not exists teacher(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/school/teacher';
4)查看创建的表
show tables;
5)查看表格式化信息
desc formatted dept;
Table Type: EXTERNAL_TABLE
6)删除外部表,观察表的元数据和相应hdfs中的数据
drop table dept;
外部表删除后,hdfs中的数据还在,但是metadata中dept的元数据已被删除
4.5.3 管理表与外部表的互相转换
1)查询表的类型
desc formatted student2;
Table Type: MANAGED_TABLE
2)修改内部表student2为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');
3)查询表的类型
desc formatted student2;
Table Type: EXTERNAL_TABLE
4)修改外部表student2为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
4.6 修改表
4.6.1 重命名表
1、语法
ALTER TABLE table_name RENAME TO new_table_name
2、实操案例
alter table student3 rename to student4;
4.6.2 增加/修改/替换列信息
1、语法
1)更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
2)增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
2、实操案例
1)查询表结构
desc test2;
OK
col_name data_type comment
id int
2)更新列:将列名id修改为student_id,类型不变
alter table test2 change column id student_id int;
OK
Time taken: 0.083 seconds
desc test2;
OK
col_name data_type comment
student_id int
3)更新列:不修改列名,仅修改列的类型为string
alter table test2 change column student_id student_id string;
OK
Time taken: 0.083 seconds
desc test2;
OK
col_name data_type comment
student_id string
4)新增列:向test2表中新增一列,列名为name,类型为string
alter table test2 add columns(name string);
desc test2;
OK
col_name data_type comment
student_id string
name string
5)调整列的位置:现在想让name的列在最前面,做如下操作
alter table test2 change name name string first;
OK
Time taken: 0.139 seconds
desc test2;
OK
col_name data_type comment
name string
student_id string
Time taken: 0.036 seconds, Fetched: 2 row(s)
6)调整列的位置:将name更新到指定列的后面,操作如下
alter table test2 change name name string after student_id;
OK
Time taken: 0.069 seconds
desc test2;
OK
col_name data_type comment
student_id string
name string
Time taken: 0.033 seconds, Fetched: 2 row(s)
7)替换列(替换所有的列)
alter table test2 replace columns(id double);
OK
Time taken: 0.058 seconds
desc test2;
OK
col_name data_type comment
id double
Time taken: 0.032 seconds, Fetched: 1 row(s)
4.7 删除表
drop table test2;
4.8 清除表中数据(Truncate)
truncate table student;
注意:truncate 只能删除管理表,不能删除外部表中数据
第5章 DML 数据操作
5.1 数据导入
5.1.1 向表中状态数据(Load)
1、基本语法
load data [local] inpath '数据的path' [overwrite] into table table_name [partition (partcol1=val1,…)];
| Load data | 加载数据 |
|---|---|
| Local | 表示从本地加载数据到hive表,否则是从HDFS加载数据到Hive表 |
| Inpath | 表是加载数据的路径 |
| Overwrite | 表示覆盖表中已有数据,否则表示追加 |
| Into table | 表示加载数据到哪张表中 |
| Partition | 表示加载数据到指定分区 。通过分区,可以将表中的数据分散存储在不同的部分,通常基于某些列的值。例如,可以根据日期、地区等属性来分区。 |
2、实例操作
1)创建一张表student
create table student(
id string,
name string
)
row format delimited fields terminated by '\t';
2)加载本地文件到hive
load data local inpath '/opt/module/hive/datas/student.txt' into table default.student;
3)加载HDFS文件到hive中
(1)上传文件到HDFS
dfs -put /opt/module/hive/datas/student.txt /input;
(2)加载HDFS上数据
load data inpath '/input/student.txt' into table default.student;
4)加载数据覆盖表中已有的数据
load data inpath '/input/student.txt' overwrite into table default.student;
FAILED: SemanticException Line 1:17 Invalid path ''/input/student.txt'': No files matching path hdfs://hadoop102:8020/input/student.txt
竟然报错了,信息显示文件不存在?
显然,加载HDFS上的文件到hive表中,采用的类似剪切的方式,将文件拷贝到表的映射目录下。
上传文件到HDFS
dfs -put /opt/module/hive/datas/student.txt /input;
加载HDFS上数据
load data inpath '/input/student.txt' overwrite into table default.student;
5.1.2 向表中插入数据(Insert)
1)创建一张表
create table student2(id int, name string) row format delimited fields terminated by '\t';
2)基本插入数据
insert into table student2 values(1,'wangwu'),(2,'zhaoliu');
3)将查询结果插入表中
insert overwrite table student2 select id, name from student ;
| insert into | 以追加数据的方式插入到表或分区,原有数据不会删除 |
|---|---|
| insert overwrite | 会覆盖表中已存在的数据 |
注意:insert不支持只插入部分数据
5.1.3 查询语句中创建表并加载数据(AS Select)
根据查询结果创建表
create table if not exists student4
as select id, name from student;
5.1.4 创建表时通过Location指定加载数据路径
1、上传数据到hdfs上
dfs -mkdir /input/student;
dfs -put /opt/module/hive/datas/student.txt /input/student/student.txt;
2、创建表,并指定在hdfs上的位置
create external table if not exists student5(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/input/student';
3、查询数据
select * from student5;
OK
student5.id student5.name
1001 ss1
1002 ss2
……
注意:hive创建表时,默认将表的名称作为默认HDFS上表对应的存储路径的名称,但是,如果你通过location指定存储路径,就不会修改路径名称为表名了。如上边的表名为student5和其在HDFS上的存储路径student。
5.2 数据导入
5.2.1 Insert导入
1、将查询的结果导出到本地
insert overwrite local directory '/opt/module/hive/datas/export/student'
select * from student;
2、将查询的结果格式化导出到本地
insert overwrite local directory '/opt/module/hive/datas/export/student'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from bigdata1.student;
3、将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/output/student'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
注意:insert导入时,hive会自动创建导出目录,但是由于是overwrite,所以导出路径一定要写准确,否则存在误删数据的可能。
5.3 数据迁移
export 和 import命令主要用于两个Hadoop平台集群之间Hive表迁移。(元数据源+真实数据)
5.3.1 Export导出到HDFS上
export table default.student2 to '/地址'; 导出到哪里
5.3.2 Import数据到指定Hive表中
import table student2 from '/地址 '; 从哪里导入
注意:先用export导出后,再将数据导入。
第 6 章:查询
6.1 基本语法及执行顺序
1、查询语句语法
select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT number]
2、书写次序和执行次序
| 顺序 | 书写次序 | 书写次序说明 | 执行次序 | 执行次序说明 |
|---|---|---|---|---|
| 1 | select | 查询 | from | 先执行表与表直接的关系 |
| 2 | from | 先执行表与表直接的关系 | on | 先执行表与表直接的关系 |
| 3 | join on | 先执行表与表直接的关系 | join | 先执行表与表直接的关系 |
| 4 | where | 先执行表与表直接的关系 | where | 过滤 |
| 5 | group by | 分组 | group by | 分组 |
| 6 | having | 分组后再过滤 | having | 分组后再过滤 |
| 7 | distribute by cluster by | 4个by | select | 查询 |
| 8 | sort by | 4个by | distinct | 去重 |
| 9 | order by | 4个by | distribute by cluster by | 4个by |
| 10 | limit | 限制输出的行数 | sort by | 4个by |
| 11 | union/union all | 合并 | order by | 4个by |
| 12 | limit | 限制输出的行数 | ||
| 13 | union/union all | 合并 |
6.2 基本查询(Select…From)
6.2.1 全表和特定列查询
1、数据准备
分别创建部门和员工外部表,并向表中导入数据。
1)在/opt/module/hive/datas目录下编辑文件dept.txt,添加如下内容。
vim dept.txt
10 行政部 1700
20 财务部 1800
30 教学部 1900
40 销售部 1700
2)在/opt/module/hive/datas目录下编辑文件emp.txt,添加如下内容。
vim emp.txt
7369 张三 研发 800.00 30
7499 李四 财务 1600.00 20
7521 王五 行政 1250.00 10
7566 赵六 销售 2975.00 40
7654 侯七 研发 1250.00 30
7698 马八 研发 2850.00 30
7782 金九 \N 2450.0 30
7788 银十 行政 3000.00 10
7839 小芳 销售 5000.00 40
7844 小明 销售 1500.00 40
7876 小李 行政 1100.00 10
7900 小元 讲师 950.00 30
7902 小海 行政 3000.00 10
7934 小红明 讲师 1300.00 30
3)上传数据到HDFS
dfs -mkdir /user/hive/warehouse/dept;
dfs -mkdir /user/hive/warehouse/emp;
dfs -put /opt/module/hive/datas/dept.txt /user/hive/warehouse/dept;
dfs -put /opt/module/hive/datas/emp.txt /user/hive/warehouse/emp;
4)建表语句,创建外部表
创建部门表dept
create external table if not exists dept(
deptno int,--部门编号
dname string, --部门名称
loc int --部门位置
)
row format delimited
fields terminated by '\t';
创建员工表
create external table if not exists emp(
empno int, --员工编号
ename string, --员工姓名
job string, --员工岗位(大数据工程师、前端工程师、java工程师)
sal double,--员工薪资
deptno int --部门编号
)
row format delimited fields terminated by '\t';
2、全表查询
select * from EMP;
select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp ;
3、选定特定列查询
select empno, ename from emp;
注意:
1、SQL语言大小写不敏感
2、SQL可以写在一行或者多行
3、关键字不能被缩写也不能分行
4、各子句一般要分行写
5、使用缩进提高语句的可读性
6.2.2 列别名
紧跟列名,也可以在列名和别名之间加入关键字‘AS’
如:
select
ename AS name,
deptno dn
from emp;
6.2.3 常用函数(set hive.exec.mode.local.auto=true;本地模式)
1、求emp表的总行数(count)
select count(*) cnt from emp;
2、求emp表中工资的最大值
elect max(sal) max_sal from emp;
3、求emp表中工资的最小值
elect min(sal) min_sal from emp;
4、求emp表中工资的总和
elect sum(sal) sum_sal from emp;
5、求emp表中工资的平均值
select avg(sal) avg_sal from emp;
6.2.4 Limit语句
一般的查询会返回多行数据,在生产环境中,通常使用LIMIT子句用于限制返回的行数
select ename, sal from emp limit 5;
select ename, sal from emp limit 2,3;
6.2.5 Where语句
1、实例:查询出薪水大于1000的所有员工
select * from emp where sal > 1000;
6.2.6 比较运算符(Between/In/Is Null)
1、下面表中描述了谓词操作符,这些操作符同样可以用于JOIN…ON和HAVING语句中。
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,如果以便为NULL,返回False |
| A RLIKE B | STRING类型 | B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是 |
2、案例实操
1)查询出薪水等于5000的所有员工
select * from emp where sal =5000;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
2)查询工资在500到1000的员工信息
select * from emp where sal between 800 and 1100;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
3)查询job为空的所有员工信息
select * from emp where job is null;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
4)查询工资是1500或5000的员工信息
select * from emp where sal IN (1500, 5000);
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
6.2.7 Like 和 RLike
1、like关键字:使用LIKE运算选择类似的值
2、选择条件可以包含字符或数字:
1)% -> 代表零个或多个字符
2)_ -> 代表一个字符
3、RLIKE关键字:RLIKE子句是Hive中这个功能的一个扩展,其可以通过java的正则表达式这个更加强大的语言来指定匹配条件。
1)$x -> 代表以x结尾
2)^x -> 代表以x开头
3).* 任意数量字符
4). 一个任意字符
5)*上一个字符可以无限次出现或者不出现
4、实例操作
1)查找名字以“小”开头的员工信息
select * from emp where ename LIKE '小%';
select * from emp where ename RLIKE '^小';
2)查找名字以“明”结尾的员工信息
select * from emp where ename LIKE '%明';
select * from emp where ename RLIKE '明$';
3)查找名字中带有“明”的员工信息
select * from emp where ename LIKE '%明%';
select * from emp where ename RLIKE '[明]';
6.3 排序
6.3.1 每个Reduce内部排序(Sort By)
1、Sort by:在每个Reduce内部进行排序,对全局结果集来说不是有序。sort by为每个reducer产生一个排序文件,每个Reducer内部进行排序,对全局结果来说不是排序。
2、通过命令设置reduce个数
set mapreduce.job.reduces=3;
3、案例实操:
1)根据部门编号降序查看员工信息
select * from emp sort by deptno desc;
2)将查询结果导入到文件中
insert overwrite local directory '/opt/module/hive/datas/sortby-result'
row format delimited fields terminated by '\t '
select *
from emp
sort by deptno desc;
6.3.2 分区(Distribute By)
1、Distribute By
在有些情况下,我们需要控制某个特定行应该在哪个reducer,通常时为了进行后续的聚集操作。distribute by可以实现。distribute by类似MR中的partition(自定义分区),进行分区,结合sort by 使用。
2、案例分析
1)先按照部门编号分区,再按照员工薪水降序排序
set mapreduce.job.reduces=3;
insert overwrite local directory '/opt/module/hive/datas/distribute-result'
row format delimited fields terminated by '\t'
select
ename,
empno,
deptno,
sal
from emp
distribute by deptno
sort by sal desc;
注意:
- distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一起。
- Hive要求DISTRIBUTE BY语句要写在SORT BY语句前面。
6.3.3 Cluster By
1、cluster by:
1)当distribute by和sort by字段相同时,可以使用cluster by方式。
2)cluster by除了具有distribute by的功能外还兼具sort by的功能。
2、案例:查询emp表中的员工信息,并按照部分编号分区排序。
select ename,empno,deptno,sal from emp cluster by deptno;
select ename,empno,deptno,sal from emp distribute by deptno sort by deptno;
第 7 章 分区表和分桶表
我们创建一个hive表时,此时在hdfs上就在默认路径上创建了一个以表名字命名的文件夹。Hive表中的数据在hdfs上则是对应文件夹下的所有文件。在查询表中数据时,其实就是将文件下的所有文件进行读取,在海量数据的场景下,这无疑是非常耗时的,并且在实际生产环境中,往往会进行查询过滤。
所以,如何在海量数据的场景下进行高效的查询过滤呢?
7.1 分区表
1、分区表实际上就是对应一个HDFS文件系统上的独立的文件夹。
2、该文件夹下是该分区所有的数据文件。
3、Hive中的分区就是分目录,把一个大的数据集根据业务需求分割成小的数据集。
4、在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
7.1.1 分区表基本操作
1、需要根据日期对日志进行管理,通过部门信息模拟
2、创建分区表语法
create table dept_partition(
deptno int, --部门编号
dname string, --部门名称
loc string --部门位置
)
partitioned by (day string)
row format delimited fields terminated by '\t';
注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。
3、数据准备
为每个分区准备数据,我们根据日期对日志进行管理,通过部门信息模拟
vim dept_20200401.log
10 行政部 1700
20 财务部 1800
vim dept_20200402.log
30 教学部 1900
40 销售部 1700
vim dept_20200403.log
50 运营部 2000
60 人事部 1900
4、案例:
1)向dept_partition表的分区加载数据
load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table dept_partition partition(day='20200401');
load data local inpath '/opt/module/hive/datas/dept_20200402.log' into table dept_partition partition(day='20200402');
load data local inpath '/opt/module/hive/datas/dept_20200403.log' into table dept_partition partition(day='20200403');
注意:分区表加载数据时,必须指定分区

2)查询分区表中数据
单分区查询
select * from dept_partition where day='20200401';
多分区联合查询(union必走mr效率较低)
select * from dept_partition where day='20200401'
union
select * from dept_partition where day='20200402'
union
select * from dept_partition where day='20200403';
select * from dept_partition where day='20200401' or
day='20200402' or day='20200403' ;
5、增加分区
1)添加单个分区
alter table dept_partition add partition(day='20200404') ;
2)同时添加多个分区
alter table dept_partition add partition(day='20200405') partition(day='20200406');
6、删除分区
1)删除单个分区
alter table dept_partition drop partition (day='20200406');
2)同时删除多个分区
alter table dept_partition drop partition (day='20200404'), partition(day='20200405');
7、查看分区表结构
desc formatted dept_partition;
# Partition Information
# col_name data_type comment
day string
7.1.2 二级分区
思考:在根据日期分区后,如果一天的日志数据量也很大,如何再将数据拆分?
1、创建二级分区表
create table dept_partition2(
deptno int,
dname string,
loc string
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
2、加载数据
1)加载数据到二级分区表中
load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table dept_partition2 partition(day='20200401', hour='11');
2)查找分区数据
select * from dept_partition2 where day='20200401' and hour='11';
3、让分区表和数据产生关联的三种方式
1)、方式一:上传数据后修复
(1)上传数据
dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20200401/hour=12;
dfs -put /opt/module/hive/datas/dept_20200402.log /user/hive/warehouse/dept_partition2/day=20200401/hour=12;
(2)查询数据(查询不到刚上传的数据)
select * from dept_partition2 where day='20200401' and hour='12';
(3)执行修复命令
msck repair table dept_partition2;
(4)再次查询数据
select * from dept_partition2 where day='20200401' and hour='12';
2)方式二:上传数据后添加分区
(1)上传数据
dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20200401/hour=13;
dfs -put /opt/module/hive/datas/dept_20200403.log /user/hive/warehouse/dept_partition2/day=20200401/hour=13;
(2)执行添加分区
alter table dept_partition2 add partition(day='20200401',hour='13');
(3)查询数据
select * from dept_partition2 where day='20200401' and hour='14';
3)方式三:创建文件夹后load数据到分区
(1)创建目录
dfs -mkdir -p /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14;
(2)上传数据
load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table
dept_partition2 partition(day='20200401',hour='14');
(3)查询数据
select * from dept_partition2 where day='20200401' and hour='14';
7.1.3 动态分区
引言:关系型数据库中,对分区表Insert数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中。Hive中也提供类似的操作,即动态分区(Dynamic Partition),只不过,使用Hive的动态分区,需要进行相应的配置。
1、开启动态分区参数设置
1)开启动态分区功能
set hive.exec.dynamic.partition=true;
2)设置非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区)
set hive.exec.dynamic.partition.mode=nonstrict
3)在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
set hive.exec.max.dynamic.partitions=1000;
4)在每个执行MR的节点上,最大可以创建多少个动态分区
该参数需要根据实际的数据来设定。比如,源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认100,则会报错。
set hive.exec.max.dynamic.partitions.pernode=100;
5)整个MR Job中,最大可以创建多少个HDFS文件。默认100000
set hive.exec.max.created.files=100000;
6)当有空分区生成时,是否抛出异常。一般不需要设置。默认false
set hive.error.on.empty.partition=false;
2、案例
需求:将dept表中的数据按照地区(loc字段),插入到目标表dept_partition_loc的相应分区中
1)创建部门地区分区表
create table dept_partition_dynamic(
id int,
name string
)
partitioned by (loc int)
row format delimited fields terminated by '\t';
2)以动态分区的方式向表中插入数据
insert into table dept_partition_loc partition(loc) select deptno, dname, loc from dept;
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
set hive.exec.dynamic.partition.mode = nonstrict;
insert into table dept_partition_dynamic partition(loc) select deptno, dname, loc from dept;
3)查看目标分区表的分区情况
show partitions dept_partition;
OK
partition
loc=1700
loc=1800
loc=1900
7.2 分桶表
1、分桶表
对于一张表或分区,Hive可以进一步组织成桶,也就是更为细粒度的数据范围划分。分区针对的是数据的存储路径(细分文件夹);分桶针对的是数据文件(按规则多文件放在一起)。
2、案例:创建分桶表
1)创建分桶表
create table stu_bucket(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
2)查看表结构
desc formatted stu_bucket;
Num Buckets: 4
注意:想要将表创建为4个桶,需要将hive中mapreduce.jog.reduces参数设置为>=4或设置为-1
3)导入数据到分桶表中
load data local inpath '/opt/module/hive/datas/student.txt' into table stu_bucket;
4)查看创建的分桶表中是否分为4个桶

5)查询分桶的数据
select * from stu_bucket;
6)分桶规则
Hive的分桶采取对分桶字段的值进行哈希,然后除以桶的个数求余
7)分桶表操作需要注意的事项:
(1)mapreduce.job.reduces=-1,让Job自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的数量。
(2)从hdfs中load数据到分桶表中,避免本地文件找不到问题
8)insert方式将数据导入分桶表
truncate table stu_bucket;(删除表内数据,不删表结构,因此只能删内表)
insert into table stu_bucket select * from student ;
第 8 章:函数
8.1 系统内置函数
1)查看系统自带的函数
show functions;
2)显示自带的函数的用法
desc function abs;
3)详细显示自带函数的用法
desc function extended abs;
8.2 常用内置函数
8.2.1 空字段赋值-NVL(防止空字段参与计算)
1、函数说明
desc function extended nvl;
2、解释
| NVL | 给值为NULL的数据赋值,它的格式是NVL(value,default_value) |
|---|---|
| 功能 | 如果value为NULL,则NVL函数返回default_value的值,否则返回value的值。如果两个参数都为NULL,则返回NULL |
3、案例
1、数据准备
采用员工表
2、查询
1)如果员工的comm为NULL,则用0代替
select ename,comm,nvl(comm, 0) comm_0 from emp;
2)如果员工的job为NULL,则用领导id代替
select ename, mgr,comm, nvl(job,mgr) comm_mgr from emp;
8.2.2 CASE WHEN ELSE END
1、案例
1)数据准备,在/opt/module/hive/datas目录下创建emp_sex.txt,添加如下内容
vim emp_sex.txt
悟空,A,男
大海,A,男
宋宋,B,男
凤姐,A,女
婷姐,B,女
婷婷,B,女
2)创建emp_sex表并导入数据
create table emp_sex(
name string,
dept_id string,
sex string
)
row format delimited fields terminated by ",";
load data local inpath '/opt/module/hive/datas/emp_sex.txt' into table emp_sex;
3)需求:求出不同部门男女各多少人。结果如下
select
dept_id,
sum(case sex when '男' then 1 else 0 end) man_num,
sum(case sex when '女' then 1 else 0 end) woman_num
from
emp_sex
group by dept_id;
8.2.3 行转列

1、相关函数说明
1)CONCAT(string A/col,string B/col…)
select concat('abc','def') from src limit 1;
'abcdef'
2)CONCAT_WS(separator,str1,str2,…)
select concat_ws('.','www',array('facebook','com')) from src limit 1;
'www.facebook.com'
3)COLLECT_SET(col):去重汇总
4)COLLECT_LIST(col):汇总
2、案例
1)需求:把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋|苍老师
2)数据准备
vim person_info.txt
孙悟空,白羊座,A
大海,射手座,A
宋宋,白羊座,B
猪八戒,白羊座,A
凤姐,射手座,A
苍老师,白羊座,B
3)操作
create table person_info(
name string,
constellation string,
blood_type string
)
row format delimited fields terminated by ",";
load data local inpath "/opt/module/hive/datas/person_info.txt" into table person_info;
按需求查询结果
SELECT
t1.c_b,
CONCAT_WS("|",collect_set(t1.name))
FROM (
SELECT
NAME ,
CONCAT_WS(',',constellation,blood_type) c_b
FROM person_info
)t1
GROUP BY t1.c_b
8.2.4 列转行

1、函数说明
1)EXPLODE(col):将hive表的一列中复杂的array或者map结构拆分成多行
2)SPLIT(string str,string regex):按照reget字符串分割str,会返回分割后的字符串数组
SELECT split('oneAtwoBthreeC', '[ABC]') FROM src LIMIT 1;
["one", "two", "three"]
3)LATERAL VIEW:对拆分后的数据进行聚合
2、案例
1)需求
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
2)原始数据
| movie | category |
|---|---|
| 《疑犯追踪》 | 悬疑,动作,科幻,剧情 |
| 《Lie to me》 | 悬疑,警匪,动作,心理,剧情 |
| 《战狼2》 | 战争,动作,灾难 |
3)操作
vim movie_info.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
create table movie_info(
movie string,
category string)
row format delimited
fields terminated by "\t";
load data local inpath "/opt/module/hive/datas/movie_info.txt" into table movie_info;
4)按需求查询数据
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name ;
8.2.5 窗口函数(开窗函数)
1、介绍
输入多行数据(一个窗口),为每行数据进行一次计算,返回一个值。灵活运用窗口函数可以解决如去重,排序等。

2、语法
Function (arg1 ...) over ([patition by arg1 ...] [order by arg1 ...] [<window_expression>])
| Function | Over() | window_expression |
|---|---|---|
| 支持的函数 | 指定分析函数工作的数据窗口大小,窗口会随着行的变化而变化 | 窗口边界的设置 |
| 聚合函数:sum()、max()等 | partition by:表示将数据先按字段进行分区 | n preceding : 向前n行 n following:向后n行 current row:当前行 |
| 排序函数:rank()、row_number()等 | Order by:表示将各个分区内的数据按字段进行排序 | unbounded preceding:从前面的起点开始 unbounded following:到后面的终点结束 |
| 统计比较函数:lead()、lag()等 |
3、数据准备
1)在/opt/module/hive/datas目录下创建business.txt,添加如下内容
vim business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
2)创建hive表并导入数据
create table business(
name string,
orderdate string,
cost int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/hive/datas/business.txt" into table business;
4、实例
1)需求:查询在2017年4月份购买过的顾客,及总人数
(1)样例
name consume_num
mart 2
jack 2
select
name,
count(name) over()
from business
where subString(orderdate,1,7) = '2017-04'
group by name;
2)需求:查询顾客的购买明细及月购买总额
(1)样例
name orderdate cost month_sum
jack 2017-01-05 46 111
jack 2017-01-08 55 111
jack 2017-01-01 10 111
jack 2017-02-03 23 23
jack 2017-04-06 42 42
(2)分析
查询顾客的购买明细,即表中的所有的列,分别以name和orderdate分组,显然group by无法满足我们。这里我们用到over(partition by arg1)指定窗口函数的分区字段,在分区基础上进行窗口分析。
(3)案例
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate))
from business;
OK
name orderdate cost sum_window_0
jack 2017-01-05 46 111
jack 2017-01-08 55 111
jack 2017-01-01 10 111
jack 2017-02-03 23 23
jack 2017-04-06 42 42
mart 2017-04-13 94 299
mart 2017-04-11 75 299
mart 2017-04-09 68 299
mart 2017-04-08 62 299
neil 2017-05-10 12 12
neil 2017-06-12 80 80
tony 2017-01-04 29 94
tony 2017-01-02 15 94
tony 2017-01-07 50 94
3)需求:将每个顾客的cost按照日期进行累加
计算表business的消费总额
select
name,
orderdate,
cost,
sum(cost) over() sample1
from business;

计算每个人的销售总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name) as sample2
from business;
计算每个人截至到当天的消费总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate) as sample3 from business;

计算每个人截至到今天的消费总额(另一种写法)
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4
from business;
计算每个人连续两天的消费总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row ) as sample5
from business;

计算每个人从当前天到最后一天的消费总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample6 from business;.

rows必须跟在Order by子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数量行数量。
4)需求:查看顾客上次的购买时间
(1)样例
name orderdate cost last_time
jack 2017-01-01 10 (…………………)
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
(2)函数介绍
LAG (scalar_expression[,offset] [,default]) OVER ([query_partition_clause] order_by_clause);
解释:
Lag函数用于统计窗口内往上第n行值,参数scalar_pexpression为列名,参数offset为往上几行,参数default是设置的默认值(当往上第n行为NULL时,取默认值,否则就为NULL)
(3)案例代码
select
name,
orderdate,
cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as last_time
from business;
OK
name orderdate cost last_time
jack 2017-01-01 10 1900-01-01
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 1900-01-01
5)需求:查询前20%时间的订单信息
(1)分析
当前表中总共有14行数据,前20%,就是大约前三行,你会觉得很简单,将数据orderdate字段排序取前三即可,但是表中数据量持续变化,前20%的数据是变化的,这里需要使用ntile函数。
(2)函数介绍
Ntile函数,为已排序的行,均分为指定数量的组,组号按顺序排列,返回组号,不支持rows between
(3)案例
select
t1.name,
t1.orderdate,
t1.cost
from (
select
name,
orderdate,
cost,
ntile(5) over(order by orderdate) sorted from business
) t1
where t1.sorted = 1;
OK
t.name t.orderdate t.cost
jack 2017-01-01 10
tony 2017-01-02 15
tony 2017-01-04 29
8.2.6 Rank
1、函数说明
1)RANK():排序相同时会重复,总数不会变。重复的名次一样但是下一名名次会以前面人数+1来定
2)DENSE_RANK():排序相同时会重复,总数会减少。就是若有重复则最后一名的名词不会和总数相等 即并列
3)ROW_NUMBER():会根据顺序计算,字段相同就按排头字段继续排
2、数据准备
1)数据
vim score.txt
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
2)导入数据
create table score(
name string,
subject string,
score int)
row format delimited
fields terminated by "\t";
load data local inpath '/opt/module/hive/datas/score.txt' into table score;
3、需求:计算每门学科成绩排名
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
OK
name subject score rp drp rmp
孙悟空 数学 95 1 1 1
宋宋 数学 86 2 2 2
婷婷 数学 85 3 3 3
大海 数学 56 4 4 4
宋宋 英语 84 1 1 1
大海 英语 84 1 1 2
婷婷 英语 78 3 2 3
孙悟空 英语 68 4 3 4
大海 语文 94 1 1 1
孙悟空 语文 87 2 2 2
婷婷 语文 65 3 3 3
宋宋 语文 64 4 4 4
8.3 自定义函数
1、内置函数:比如max/min等
2、根据用户自定义函数类别分为以下三种:
1)UDF:一进一出
2)UDAF:聚合函数,多进一出,类似:count/max/min
3)UDTF:炸裂函数,一进多出,类似:explode()
3、编程步骤
1)继承Hive提供的类
2)实现类中的抽象方法
3)在hive的命令行窗口创建函数
4、hive中引入自定义函数步骤
1)添加jar
add jar linux_jar_path
2)创建function
create [temporary] function [dbname.]function_name AS class_name;
3)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
8.4 自定义UDF函数
1、需求:自定义一个UDF实现计算给定字符串的长度,例如:
select my_len("abcd");
ok
4
2、案例
1)创建Maven工程Hive
2)在工程项目的pom.xml文件中导入依赖
hive-exec
3)创建一个类
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 自定义UDF函数,需要继承GenericUDF类
* 需求: 计算指定字符串的长度
*/
public class MyStringLength extends GenericUDF {
/**
*
* @param arguments 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断输入参数的个数
if(arguments.length !=1){
throw new UDFArgumentLengthException("Input Args Length Error!!!");
}
// 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"Input Args Type Error!!!");
}
//函数本身返回值为int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数的逻辑处理
* @param arguments 输入的参数
* @return 返回值
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if(arguments[0].get() == null){
return 0 ;
}
return arguments[0].get().toString().length();
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}
4)打包jar包上传到服务器/opt/module/hive/datas/myudf.jar
5)将jar包添加到hive的classpath
add jar /opt/module/hive/datas/myudf.jar;
8.5 创建临时函数
1、创建临时函数与开发好的java class关联
create temporary function my_len as "com.atguigu.hive. MyStringLength";
2、在hql中使用自定义的函数
select ename,my_len(ename) ename_len from emp;
OK
ename _c1
fanfan 6
SMITH 5
ALLEN 5
WARD 4
JONES 5
MARTIN 6
BLAKE 5
CLARK 5
SCOTT 5
KING 4
TURNER 6
ADAMS 5
JAMES 5
FORD 4
MILLER 6
注意:临时函数只跟会话有关系,跟库没有关系,只有创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全部不能使用。
8.6 创建永久函数
注意:因为add jar 的方式本身也是临时生效,所以在创建永久函数的时候,需要执行路径
create function my_len2
as "com.atguigu.hive.udf.MyUDF"
using jar "hdfs://hadoop102:8020/udf/myudf.jar";
即可在hql中使用自定义的永久函数
select
ename,
my_len2(ename) ename_len
from emp;
删除永久函数
drop function my_len2;
注意:永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
第 9 章:压缩和存储
Hive不会强制要求将数据转换成特定的格式才能使用。利用Hadoop的InputFormat API可以从不同数据源读取数据,使用OutputFormat API可以将数据写成不同的格式输出。
对数据进行压缩虽然会增加额外的CPU开销,但是会节约客观的磁盘空间,并且通过减少内存的数据量而提高I/O吞吐量会更加提高网络传输性能。
原则上Hadoop的job时I/O密集型的话就可以采用压缩可以提高性能,如果job是CPU密集型的话,那么使用压缩可能会降低执行性能。
9.1 Hadoop压缩配置
9.1.1 MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| Deflate | Deflate | .deflate | 否 |
| Gzip | Deflate | .gz | 否 |
| Bzip2 | Bzip2 | .bz2 | 是 |
| Lzo | Lzo | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| Deflate | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| Lzo | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
为什么需要这么多的压缩方案呢?
每一个压缩方案都在压缩和解压缩速度和压缩率间进行权衡。
如下是压缩性能的比较
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
9.1.2 压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.Lz4Codec | 输出压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数为true启动压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启动压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
9.2 开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。
1、具体配置如下:
1)开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate =true;
2)开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
3)设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
4)执行查询语句
select count(ename) name from emp;
5)观察yarn执行的job的map阶段日志可看到如下内容

9.3 开启Reduce输出阶段压缩
当Hive将输出写入到表中时可以通过属性hive.exec.compress.output,对输出内容进行压缩。当hive.exec.compress.output=false,这样输出就是非压缩的纯文本文件了。将hive.exec.compress.output=true,来开启输出结果压缩功能。
1、设置步骤如下:
1)开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
2)开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
3)设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
4)设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5)测试以下输出结果是否为压缩文件
insert overwrite local directory
'/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
6)查看目录/opt/module/hive/datas/distribute-result下文件
distribute-result]$ ll
总用量 4
-rw-r--r--. 1 atguigu atguigu 493 10月 21 22:56 000000_0.snappy
9.4 文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET。
9.4.1 列式存储和行式存储

如图所示,左边为逻辑表,右边第一个是行式存储,第二个式列式存储。
9.4.2 TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip,Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
9.4.3 Orc格式
Orc是Hive 0.11版里引入的新的存储格式。
如下图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data, Row Data,Stripe Footer;
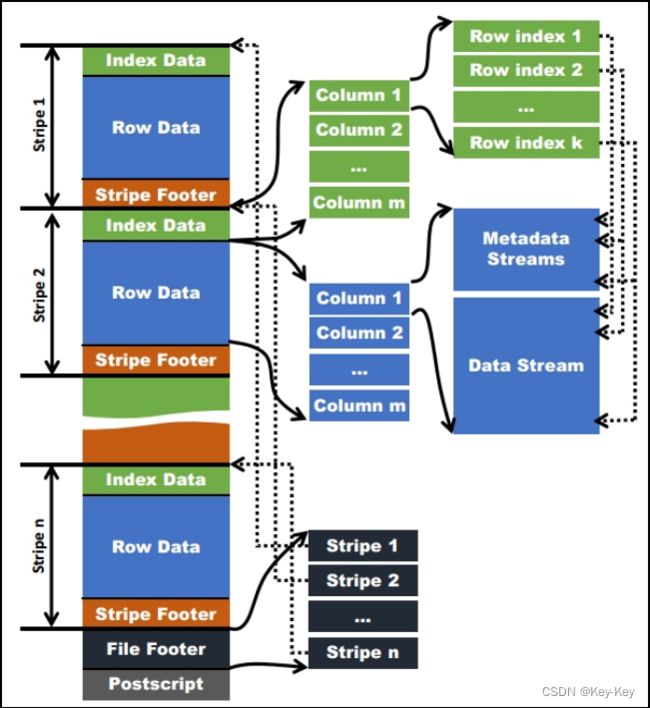
1、Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
2、Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3、Stripe Footer:存的是各个Stream的类型,长度等信息。每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
9.4.4 Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的。文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
1、行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
2、列块(Column Chunk):在一个行组中每一列保持在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同列块可能使用不同的算法进行压缩。
3、页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。

上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三中类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
9.4.5 主流存储文件格式对比
1、TextFile
1)创建log_text,设置其存储数据格式为TEXTFILE
create table log_text (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile;
2)向表中加载数据
load data local inpath '/opt/module/hive/datas/log.data' into table log_text ;
3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_text;
18.1 M 54.4 M /user/hive/warehouse/log_text/log.data
4)采用TextFile格式存储,文件大小为18.1M
2、ORC
1)创建表loc_orc,存储数据格式是ORC
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE"); // 由于ORC格式时自带压缩的,这设置orc存储不使用压缩
2)向表中插入数据
insert into table log_orc select * from log_text ;
3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_orc/ ;
7.7 M 23.1 M /user/hive/warehouse/log_orc/000000_0
4)采用ORC(非压缩)格式存储,文件大小为7.7M
3、Parquet
1)创建表log_parquet,设置其存储数据格式为parquet
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet ;
2)向表中插入数据
insert into table log_parquet select * from log_text ;
3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_parquet/ ;
13.1 M 39.3 M /user/hive/warehouse/log_parquet/000000_0
4)采用Parquet格式存储,文件大小为13.1M
4、存储文件的对比总结:
ORC>Parquet>textFile
5、存储文件的查询速度测试:
1)TextFile
insert overwrite local directory '/opt/module/hive/data/log_text' select substring(url,1,4) from log_text ;
No rows affected (10.522 seconds)
2)ORC
insert overwrite local directory '/opt/module/hive/data/log_orc' select substring(url,1,4) from log_orc ;
No rows affected (11.495 seconds)
3)Parquet
insert overwrite local directory '/opt/module/hive/data/log_parquet' select substring(url,1,4) from log_parquet ;
No rows affected (11.445 seconds)
存储文件的查询速度总结:查询速度相近
9.5 存储和压缩结合
9.5.1 测试存储和压缩
1、创建一个ZLIB压缩的ORC存储方式
1)创建表log_orc_zlib表,设置其使用ORC文件格式,并使用ZLIB压缩
create table log_orc_zlib(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
2)向表log_orc_zlib插入数据
insert into log_orc_zlib select * from log_text;
3)查看插入后数据文件大小
dfs -du -h /user/hive/warehouse/log_orc_zlib/ ;
2.8 M 8.3 M /user/hive/warehouse/log_orc_zlib/000000_0
4)采用ORC文件格式,并使用ZLIB压缩时,文件大小2.8M
2、创建一个SNAPP压缩的ORC存储方式
1)创建表log_orc_snappy表,设置其使用ORC文件格式,并使用snappy压缩
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
2)插入数据
insert into log_orc_snappy select * from log_text;
3)查看插入后数据
dfs -du -h /user/hive/warehouse/log_orc_snappy/ ;
3.7 M 11.2 M /user/hive/warehouse/log_orc_snappy/000000_1
4)采用ORC文件格式,并使用SNAPPY压缩时,文件大小3.7M
ZLIB比Snappy压缩的还小。原因是ZLIB采用的是deflate压缩算法。比snappy压缩的压缩率高。
3、创建一个SNAPPY压缩的parquet存储方式
1)创建表log_parquet_snappy,设置其使用Parquet文件格式,并使用SNAPPY压缩
create table log_parquet_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
2)向表log_parquet_snappy插入数据
insert into log_parquet_snappy select * from log_text;
3)查看插入后数据
dfs -du -h /user/hive/warehouse/log_parquet_snappy / ;
6.4 M 19.2 M /user/hive/warehouse/log_parquet_snappy/000000_0
4)采用Parquet文件格式,并使用SNAPPY压缩时,文件大小6.4MB
4、存储方式和压缩总结
在实际的项目开发当中:
1)hive表的数据存储格式一般选择:orc或parquet
2)压缩方式一般选择snappy,lzo
第 10 章:企业级调优
创建测试用例
1、建大表、小表和JOIN后表的语句
// 创建大表
create table bigtable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建小表
create table smalltable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建JOIN后表
create table jointable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
2、分别向大表和小表中导入数据
load data local inpath '/opt/module/hive/datas/bigtable' into table bigtable;
load data local inpath '/opt/module/hive/datas/smalltable' into table smalltable;
10.1 执行计划(Explain)
1、基本语法
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query
2、实例操作
1)查看下面这条语句的执行计划
(1)没有生成MR任务的
explain select * from emp;

(2)有生成MR任务的
explain select deptno, avg(sal) avg_sal from emp group by deptno;

2)查看详细执行计划
explain extended select * from emp;
explain extended select deptno, avg(sal) avg_sal from emp group by deptno;
10.2 HQL语法优化
10.2.1 列裁剪和分区裁剪
在生产环境中,会面临列很多或者数据量很大时,如果使用select * 或者不指定分区进行全列或者全表扫描时效率很低。Hive在读取数据时,可以只读取查询中所需要的列,忽略其它的列,这样做可以节省读取开销(中间表存储开销和数据整合开销)
1、列裁剪:在查询时只读取需要的列
2、分区裁剪:在查询时只读取需要的分区
10.2.2 Group By
1、介绍:默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。

并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
2、进行参数设置
1)开始Map端聚合参数设置
(1)是否在Map端进行聚合,默认为True()
set hive.map.aggr = true
(2)在Map端进行聚合操作的条目数量
set hive.groupby.mapaggr.checkinterval = 100000
(3)在数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
(4)当开启数据负载均衡时,生成的查询计划会有两个MRJob。
第一个MRJob中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
第二个MRJob再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
3、案例
1)优化前
select deptno from emp group by deptno;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 23.68 sec HDFS Read: 19987 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 23 seconds 680 msec
OK
deptno
10
20
30
2)优化以后
set hive.groupby.skewindata = true;
explain select deptno from emp group by deptno;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 28.53 sec HDFS Read: 18209 HDFS Write: 534 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 5 Cumulative CPU: 38.32 sec HDFS Read: 15014 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 6 seconds 850 msec
OK
deptno
10
20
30
10.2.3 CBO优化
join的时候表的顺序的关系:前面的表会被加载到内存中。后面的表进行磁盘扫描
select a.*, b.*, c.* from a join b on a.id = b.id join c on b.tt = c.tt;
Hive自0.14.0开始,加入了一项“Cost based Optimizer”来对HQL执行计划进行优化,这个功能通过“hive.cbo.enable”来开启。在Hive1.1.0之后,这个属性是默认开启的,它可以自动优化HQL中多个Join的顺序,并选择合适的Join算法。
CBO,成本优化器,代价最小的执行计划就是最好的执行计划。传统的数据块,成本优化器做出最优化的执行计划是依据统计信息来计算的。
Hive的成本优化器也一样,Hive在提供最终执行前,优化每个查询的执行逻辑和物理执行计划。这些优化工作是交给底层来完成的。根据查询成本执行进一步的优化,从而产生潜在的不同决策:如何排序连接,执行哪种类型的连接,并行度等等。
要使用基于成本的优化(也称为CBO),请在查询开始设置一下参数:
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;(Removed In: Hive 3.0.0 with HIVE-17932)
10.2.4 谓词下推
1、谓词下推:保证结果正确的前提下,将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。对应逻辑优化器是PredicatePushDown,配置项为hive.optimize.ppd,默认值为true。
2、什么是谓词:where后面的条件
3、优势:通过谓词下推,过滤条件将在map端提前执行,减少了map端的输出,降低了数据IO,节约资源,提升性能。
4、实例:
1)打开谓词下推优化属性
set hive.optimize.ppd = true; #谓词下推,默认是true
2)查看先关联两张表,再用where条件过滤的执行计划
explain select o.id from bigtable b join bigtable o on o.id = b.id where o.id <= 10;
3)查看子查询后,再关联表的执行计划
explain select b.id from bigtable b
join (select id from bigtable where id <= 10) o on b.id = o.id;
(1)测试先关联两张表,再用where条件过滤
select o.id from bigtable b
join bigtable o on o.id = b.id
where o.id <= 10;
Time taken: 34.406 seconds, Fetched: 100 row(s)
(2)通过子查询后,再关联表
select b.id from bigtable b
join (select id from bigtable where id <= 10 ) o on b.id = o.id;
Time taken: 30.058 seconds, Fetched: 100 row(s)
10.2.5 MapJoin
MapJoin是将Join双方比较小的表直接分发给各个Map进程的内存中,在Map进程中进行Join操作,这样就不用进行Reduce步骤,从而提高了速度。如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成Join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在Map端进行Join,避免Reducer处理。
1、开启MapJoin参数设置
1)设置自动选择MapJoin
set hive.auto.convert.join=true; #默认为true
2)大表小表的阈值设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize=25000000;
2、MapJoin工作机制
MapJoin是将Join双方比较小的表直接分发到各个Map进程的内容中,在Map进程中进行Join操作,这样就不用进行Reduce步骤,从而提高了速度。
3、实操:
1)开启MapJoin功能
hive(default)> set hive.auto.convert.join = true; //默认为true
2)执行小表JOIN大表功能
注意:此时小表(左连接)作为主表,所有数据都要写出去,因此此时会走reduce,mapjoin失效
Explain
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
left join bigtable b
on s.id = b.id;
3)执行大表JOIN小表语句
Explain
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable b
left join smalltable s
on b.id = s.id;
10.2.6 大表、大表SMB JOIN(重点)
1、SMB:sort merge bucket join
2、实例
1)对照案例,普通大表join
(1)创建第二张大表bigtable2,并加载数据
create table bigtable2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/bigtable' into table bigtable2;
(2)测试大表直接JOIN
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable s
join bigtable2 b
on b.id = s.id;
2)SMB案例,分桶大表join
(1)创建分桶表1 -> bigtable_buck1,桶的个数不要超过可用cpu的核数
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets -- 桶的个数和CPU核数和Reduce数需要一致
row format delimited fields terminated by '\t';
insert into bigtable_buck1 select * from bigtable;
(2)创建分桶表2 -> bigtable_buck2,桶的个数是bigtable_buck1的倍数关系,这里取一倍
create table bigtable_buck2 like bigtable_buck1;
insert into bigtable_buck2 select * from bigtable;
(3)设置参数,开启SMB
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
(4)测试SMB join
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
10.2.7 笛卡尔积
1、产生笛卡尔积的条件:
1)两个表join时不写on条件
2)两个表join时on条件无效
2、问题:Hive中笛卡尔积的查询只能使用一个Reducer来完成,面对海量数据很容易出现问题。
Map阶段:在这个阶段,系统对输入数据进行初步处理,通常是分解和转换操作。例如,它可能对数据集进行排序或筛选。
Reduce阶段:在Map阶段之后进行的是Reduce阶段。在这个阶段,Reduce接收来自Mapper的输出数据,并对这些数据进行汇总、整合或其它形式的处理,并生成最终的输出结果。
3、解决:不要写笛卡尔积,开启严格模式,不允许在HQL中出现笛卡尔积
10.3 数据倾斜
1、数据倾斜现象:
绝大多数任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败。
2、数据过量现象:
数据过量的表现为所有任务都执行的很慢,这个时候只有提高执行资源才可以优化HQL的执行效率。
3、数据倾斜的原因:
导致倾斜的原因在于按照key分组后,少量的任务负载着绝大部分数据的计算,也就是说,产生数据倾斜的HQL中一定存在分组的操作。所有从HQL的角度,我们可用将数据倾斜分为单表携带了Group by字段的查询和两表(多表)join的查询。
10.3.1 单表数据倾斜优化
1、使用参数优化
当任务中存在group by操作同时聚合函数为count或者sum可用设置参数来处理数据倾斜的问题,就是上文的Group by处理方式。
1)是否在Map端进行聚合,默认为True
set hive.map.aggr = true
2)在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
3)有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
2、增加Reduce数量
当数据中的多个key同时导致数据倾斜,可用通过增加reduce的数量解决数据倾斜问题
1)调整Reduce个数方法1:
(1)每个Reduce处理的数据量默认是256MB
set hive.exec.reducers.bytes.per.reducer=256000000
(2)每个任务最大的reduce数,默认为1009
set hive.exec.reducers.max=1009
(3)计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
2)调整Reduce个数方法2:
通过参数配置的方式(三种)直接指定reduce的个数,参数mapreduce.job.reduces。
set mapreduce.job.reduces = 15;
10.3.1 join数据倾斜优化
1、使用参数
在编写Join查询语句时,如果确定是由于join出现的数据倾斜,那么请坐如下设置。
# join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是join过程出现倾斜应该设置为true
set hive.optimize.skewjoin=false;
如果开启了,在Join过程中Hive会将计数超过阈值hive.skewjoin.key(默认100000)的倾斜key对应的行临时写入文件中,然后再启动另一个job左map join生成结果。通过hive.skewjoin.mapjoin.map.tasts参数还可以控制第二个job的mapper数量,默认10000。
set hive.skewjoin.mapjoin.map.tasks=10000;
2、大小表join
可用使用MapJoin,没有Reduce阶段就不会出现数据倾斜。
3、大表大表join
使用大散加扩容方式解决数据倾斜问题
选择其中较大的表做打散处理:
select *,concat(id,'-','0 or 1 or 2') from A;t1
选择其中较小的表做扩容处理
select *,concat(id,'-','0') from B
union all
select *,concat(id,'-','1') from B
union all
select *,concat(id,'-','2') from B;t2
10.4 Hive job优化
10.4.1 Hive Map阶段优化
1、负载文件增加Map数量
1)使用场景:当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可用考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
2)增加map数据的方法:
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
公式调整maxSize最大值。让maxSize最大值低于blocksize就可以增加map的个数。
3)案例:
(1)执行查询
select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
(2)设置最大切片值为100个字节
set mapreduce.input.fileinputformat.split.maxsize=100;
select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 6; number of reducers: 1
2、小文件进行合并
1)再map执行前合并小文件,减少map数:
CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。
HiveInputFormat没有对小文件合并功能。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2)再Map-Reduce的任务结束时合并小文件的设置
在map-only任务结束时合并小文件,默认true
SET hive.merge.mapfiles = true;
在map-reduce任务结束时合并小文件,默认false
SET hive.merge.mapredfiles = true;
合并文件的大小,默认256M
SET hive.merge.size.per.task = 268435456;
当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
SET hive.merge.smallfiles.avgsize = 16777216;
3、Map端聚合
set hive.map.aggr=true;//相当于map端执行combiner
10.4.2 Hive Reduce优化
1、合理设置Reduce数
1)调整reduce个数方法一
(1)每个Reduce处理的数据量默认是256MB
set hive.exec.reducers.bytes.per.reducer=256000000
(2)每个任务最大的reduce数,默认为1009
set hive.exec.reducers.max=1009
(3)计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
2)调整reduce个数方法二
通过参数配置的方式(三种)直接指定reduce的个二叔,参数mapreduce.job.reduces。
set mapreduce.job.reduces = 15;
3)reduce个数不是越多越好
(1)过多的启动和初始化reduce也会消耗时间和资源
(2)另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个文件的输入,则会出现小文件过多的问题。
(3)在设置reduce个数的时候也需要考虑这两个问题:处理大数据量利用合适的redece数;使单个reduce任务处理数据量大小要合适。
10.4.3 Hive任务整体优化
1、Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:select * from emp;在这种情况下,Hive可以简单地读取emp对应地存储目录下的文件,然后输出查询结果到控制台。在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认minimal,该属性修改为more以后,在全局查询、字段查询、limit查询等都不走mapreduce。
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
1)案例:
(1)把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
set hive.fetch.task.conversion=none;
select * from emp;
select ename from emp;
select ename from emp limit 3;
(2)把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询语句都不会执行mapreduce程序。
set hive.fetch.task.conversion=more;
select * from emp;
select ename from emp;
select ename from emp limit 3;
2、本地模式
1)本地模式介绍
(1)大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。
(2)不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。
(3)对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
(4)用户可以通过设置hive.exec.mode.local.auto=true,来让Hive在适当的时候自动启动这个优化。
set hive.exec.mode.local.auto=true; //开启本地mr
// 设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
// 设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
2)案例:
(1)开启本地模式,并执行查询语句
set hive.exec.mode.local.auto=true;
select * from emp cluster by deptno;
……
Ended Job = job_local177532144_0001
……
Time taken: 1.328 seconds, Fetched: 14 row(s)
(2)关闭本地模式,并执行查询语句
set hive.exec.mode.local.auto=false;
select * from emp cluster by deptno;
……
Starting Job = job_1634825444943_0018, Tracking URL = http://hadoop103:8088/proxy/application_1634825444943_0018/
……
Time taken: 20.09 seconds, Fetched: 14 row(s)
3、并行执行
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其它阶段。默认情况下,Hive依次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。不过,如果有更多的阶段可以并行执行,那么job可能就越快完成。通过设置参数hive.exec.parallel=true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。
当然,的在系统资源比较空闲的时候才有优势,否则,没资源,并行不起来。
4、严格模式
1)介绍:Hive可以通过设置防止一些危险操作
2)分区表不适用分区过滤
将hive.strict.checks.no.partition.filter=true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
set hive.strict.checks.no.partition.filter=true;
select * from dept_partition;
FAILED: SemanticException [Error 10056]: Queries against partitioned tables without a partition filter are disabled for safety reasons. If you know what you are doing, please set hive.strict.checks.no.partition.filter to false and make sure that hive.mapred.mode is not set to 'strict' to proceed. Note that you may get errors or incorrect results if you make a mistake while using some of the unsafe features. No partition predicate for Alias "dept_partition" Table "dept_partition"
3)使用order by 没有limit过滤
将hive.strict.checks.orderby.no.limit=true时,对于使用了order by语句的查询,要求必须使用limit语句。应为order by为了执行排序过程中会将所有的结果数据分发到同一个Reducer中进行处理,强制要求用户增加这个LIMIT语句可以防止Reducer额外执行很长一段时间。
set hive.strict.checks.orderby.no.limit=true;
select * from emp order by sal;
FAILED: SemanticException 1:27 Order by-s without limit are disabled for safety reasons. If you know what you are doing, please set hive.strict.checks.orderby.no.limit to false and make sure that hive.mapred.mode is not set to 'strict' to proceed. Note that you may get errors or incorrect results if you make a mistake while using some of the unsafe features.. Error encountered near token 'sal'
4)笛卡尔积
将hive.strict.checks.cartesian.product=true时,会限制笛卡尔积的查询。对关系型数据块非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
set hive.strict.checks.orderby.no.limit=true;
select * from emp order by sal;
FAILED: SemanticException 1:27 Order by-s without limit are disabled for safety reasons. If you know what you are doing, please set hive.strict.checks.orderby.no.limit to false and make sure that hive.mapred.mode is not set to 'strict' to proceed. Note that you may get errors or incorrect results if you make a mistake while using some of the unsafe features.. Error encountered near token 'sal'
第 11 章:Hive实战
11.1 数据结构
1、视频表
| 字段 | 备注 | 详细描述 |
|---|---|---|
| videoId | 视频唯一id(String) | 11位字符串 |
| uploader | 视频上传者(String) | 上传视频的用户名String |
| age | 视频年龄(int) | 视频在平台上的整天数 |
| category | 视频类别(Array) | 上传视频指定的视频分类 |
| length | 视频长度(Int) | 整形数字标识的视频长度 |
| views | 观看次数(Int) | 视频被浏览的次数 |
| rate | 视频评分(Double) | 满分5分 |
| Ratings | 流量(Int) | 视频的流量,整形数字 |
| comments | 评论数(Int) | 一个视频的整数评论数 |
| relatedId | 相关视频id(Array) | 相关视频的id,最多20个 |
2、用户表
| 字段 | 备注 | 字段类型 |
|---|---|---|
| uploader | 上传者用户名 | string |
| videos | 上传视频数 | int |
| friends | 朋友数量 | int |
11.2 准备工作
1、需要准备的表
1)创建原始数据表:gulivideo_ori,gulivideo_user_ori,
2)创建最终表:gulivideo_orc,gulivideo_user_orc
2、创建原始数据表
1)创建原始数据表gulivideo_ori
create external table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>
)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile
location '/gulivideo/video';
2)创建原始数据表:gulivideo_user_ori
create external table gulivideo_user_ori(
uploader string,
videos int,
friends int
)
row format delimited
fields terminated by "\t"
stored as textfile
location '/gulivideo/user';
3)创建orc存储格式带snappy压缩的表gulivideo_orc
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>
)
stored as orc
tblproperties("orc.compress"="SNAPPY");
4)创建orc存储格式带snappy压缩的表gulivideo_user_orc
create table gulivideo_user_orc(
uploader string,
videos int,
friends int
)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");
5)向ori表插入数据
load data local inpath "/opt/module/hive/datas/video" into table gulivideo_ori;
load data local inpath "/opt/module/hive/datas/user.txt" into table gulivideo_user_ori;
6)向orc表插入数据
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
11.3 业务分析
11.3.1 统计视频观看数Top10
1、思路:
使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。
2、代码
select
videoId,
`views`
from gulivideo_orc
order by `views` desc
limit 10;
OK
videoid views
dMH0bHeiRNg 42513417
0XxI-hvPRRA 20282464
1dmVU08zVpA 16087899
RB-wUgnyGv0 15712924
QjA5faZF1A8 15256922
-_CSo1gOd48 13199833
49IDp76kjPw 11970018
tYnn51C3X_w 11823701
pv5zWaTEVkI 11672017
D2kJZOfq7zk 11184051
11.3.2 统计视频类别热度Top10(类别热度:类别下的总视频数)
1、思路:
1)统计每个类别有多少个视频,显示出包含视频最多的前10个类别。
2)我们需要按照类别group by聚合,然后count组内的videoId个数即可。
3)因为当前表结构为:一个视频对应一个或多个类别。所以如果要group by类别,需要先将类别进行行列转化(展开),然后再进行count即可。
4)最后按照热度排序,显示前10条。
2、代码
select
tmp01.category_col,
count(tmp01.videoId) num
from (
select
videoId,
category_col
from gulivideo_orc
lateral view
explode(category) t as category_col
) tmp01
group by tmp01.category_col
order by num desc
limit 10;
// 结果显示
OK
tmp01.category_col num
Music 179049
Entertainment 127674
Comedy 87818
Animation 73293
Film 73293
Sports 67329
Gadgets 59817
Games 59817
Blogs 48890
People 48890
11.3.3 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
1、思路
1)先找到观看书最高的20个视频所属条目的所有信息(主要是类目),降序排列
2)先把20条信息中的category分裂出来(列转行),形成新的字段category_name
3)在第二步的结果下,按照炸开的视频类别category_name分组,然后统计组内的个数category_count
2、最终代码
select
table02.categroy_name,
count(table02.videoId) num
from (
select
videoId,
categroy_name
from (
select
videoId,
`views`,
category
from gulivideo_orc
order by `views` desc
limit 20
) table01
lateral view
explode(category) tmp as categroy_name
) table02
group by table02.categroy_nam;
// 结果显示
OK
table02.categroy_name num
Blogs 2
UNA 1
Comedy 6
Entertainment 6
Music 5
People 2
11.3.4 统计视频观看数Top50所关联视频的所属类别排序
1、思路
1)先找到观看数前50的视频信息(主要是求出关联视频)
2)炸开第一步求出的关联视频array,形成一个新字段new_relatedid
3)用new_relatedid和gulivideo_orc表进行join,求出new_relatedid的类别
4)炸开第三步结果的category,形成新字段category_name
5)按照catedory_name分组,然后求出每个分组的个数category_count
6)对category_count进行排序,利用开窗函数
2、代码
select
t5.category_name,
t5.num,
rank() over(order by t5.num desc ) rk
from (
select
t4.category_name,
count(t4.realte_id) num
from (
select
t3.realte_id,
category_name
from (
select
t2.realte_id,
g.category
from (
select
realte_id
from (
select
videoId,
relatedId,
`views`
from gulivideo_orc
order by `views` desc
limit 50
) t1
lateral view
explode(t1.relatedId) tmp as realte_id
) t2 join gulivideo_orc g on t2.realte_id = g.videoId
) t3
lateral view
explode(t3.category) tmp as category_name
) t4
group by t4.category_name
) t5 ;
// 结果显示OK
t5.category_name t5.num rk
Comedy 237 1
Entertainment 216 2
Music 195 3
People 51 4
Blogs 51 4
Animation 47 6
Film 47 6
News 24 8
Politics 24 8
Games 22 10
Gadgets 22 10
Sports 19 12
Howto 14 13
DIY 14 13
UNA 13 15
Travel 12 16
Places 12 16
Animals 11 18
Pets 11 18
Autos 4 20
Vehicles 4 20
11.3.5统计每个类别中的视频热度Top10,以Music为例
1、思路
1)要想统计Music类别中的视频热度Top10,需要先找到Music类别,那么就需要将category展开成新的字段categary_name。
2)然后通过category_name过滤“Music”分类的所有视频信息,按照视频观看数倒序排序,取前10
3)统计对应类别(Music)中的视频热度
2、代码
select
videoId,
`views` hot
from (
select
videoId,
category_name,
`views`
from gulivideo_orc
lateral view
explode(category) tmp as category_name
) t1
where category_name = "Music"
order by hot desc
limit 10;
// 结果显示
OK
videoid hot
QjA5faZF1A8 15256922
tYnn51C3X_w 11823701
pv5zWaTEVkI 11672017
8bbTtPL1jRs 9579911
UMf40daefsI 7533070
-xEzGIuY7kw 6946033
d6C0bNDqf3Y 6935578
HSoVKUVOnfQ 6193057
3URfWTEPmtE 5581171
thtmaZnxk_0 5142238
11.3.6 统计每个类别视频观看数Top10
1、思路
1)把每个原始表的类别炸开,形成新的字段category_name
2)按照炸裂开的类别字段category_name分区,按照视频观看数views倒叙排序进行开窗,求出每个类别下的所有视频的观看次数排序rk
3)按照rk字段对全表进行where过滤,求出每个类别观看书Top10
2、代码
select
t2.category_name,
t2.views,
t2.rk
from (
select
t1.category_name,
t1.views,
rank() over(partition by t1.category_name order by t1.views desc ) rk
from (
select
category_name,
`views`
from gulivideo_orc
lateral view
explode(category) tmp as category_name
) t1
) t2
where rk <= 10;
// 结果显示
OK
t2.category_name t2.views t2.rk
Comedy 42513417 1
Comedy 20282464 2
Comedy 11970018 3
Comedy 10107491 4
Comedy 9566609 5
Comedy 7066676 6
Comedy 6322117 7
Comedy 5826923 8
Comedy 5587299 9
Comedy 5508079 10
News 4706030 1
News 2899397 2
News 2817078 3
News 2803520 4
News 2348709 5
News 2335060 6
News 2326680 7
News 2318782 8
News 2310583 9
News 2291369 10
……
Time taken: 11.376 seconds, Fetched: 210 row(s)
11.3.7 统计上传视频最多的用户Top10以及它们上传的视频观看次数在前20的视频
有三种理解
理解一:取Top10中所有人上传的视频的观看次数前20
1、思路
1)去用户表gulivideo_user_orc求出上传视频最多的十个用户
2)关联gulivideo_orc表,求出这10个用户上传的所有的视频,按照观看数取前20
2、代码
SELECT
t1.uploader,
t2.videoid,
t2.views
FROM
(
select
uploader,
videos
from gulivideo_user_orc
order by videos DESC
limit 10
) t1
JOIN
gulivideo_orc t2
on t1.uploader = t2.uploader
ORDER BY t2.views DESC
LIMIT 20;
// 结果显示
OK
t1.uploader t2.videoid t2.views
expertvillage -IxHBW0YpZw 39059
expertvillage BU-fT5XI_8I 29975
expertvillage ADOcaBYbMl0 26270
expertvillage yAqsULIDJFE 25511
expertvillage vcm-t0TJXNg 25366
expertvillage 0KYGFawp14c 24659
expertvillage j4DpuPvMLF4 22593
expertvillage Msu4lZb2oeQ 18822
expertvillage ZHZVj44rpjE 16304
expertvillage foATQY3wovI 13576
expertvillage -UnQ8rcBOQs 13450
expertvillage crtNd46CDks 11639
expertvillage D1leA0JKHhE 11553
expertvillage NJu2oG1Wm98 11452
expertvillage CapbXdyv4j4 10915
expertvillage epr5erraEp4 10817
expertvillage IyQoDgaLM7U 10597
expertvillage tbZibBnusLQ 10402
expertvillage _GnCHodc7mk 9422
expertvillage hvEYlSlRitU 7123
Time taken: 57.272 seconds, Fetched: 20 row(s)
理解二:取Top10中每个人上传的视频的观看次数前20
1、思路
1)去用户表gulivideo_user_orc求出上传视频最多的10个用户
2)关联gulivideo_orc表,求出这10个用户上传的所有视频id,视频观看次数,还要按照uploader分区,views倒叙排序,求出每个uploder的上传的视频的观看排名
3)按照rk进行where过滤,求出rk<=20的数据
2、代码
select
t3.uploader,
t3.videoId,
t3.views,
t3.rk
from (
select
t2.uploader,
t2.videoId,
t2.views,
rank() over(partition by uploader order by t2.views desc ) rk
from (
select
t1.uploader,
g.videoId,
g.`views`
from (
select
uploader
from gulivideo_user_orc
order by videos desc
limit 10
) t1 join gulivideo_orc g on t1.uploader = g.uploader
) t2
) t3
where rk <=20;
// 结果显示
OK
t3.uploader t3.videoid t3.views t3.rk
expertvillage -IxHBW0YpZw 39059 1
expertvillage BU-fT5XI_8I 29975 2
expertvillage ADOcaBYbMl0 26270 3
expertvillage yAqsULIDJFE 25511 4
expertvillage vcm-t0TJXNg 25366 5
expertvillage 0KYGFawp14c 24659 6
expertvillage j4DpuPvMLF4 22593 7
expertvillage Msu4lZb2oeQ 18822 8
expertvillage ZHZVj44rpjE 16304 9
expertvillage foATQY3wovI 13576 10
expertvillage -UnQ8rcBOQs 13450 11
expertvillage crtNd46CDks 11639 12
expertvillage D1leA0JKHhE 11553 13
expertvillage NJu2oG1Wm98 11452 14
expertvillage CapbXdyv4j4 10915 15
expertvillage epr5erraEp4 10817 16
expertvillage IyQoDgaLM7U 10597 17
expertvillage tbZibBnusLQ 10402 18
expertvillage _GnCHodc7mk 9422 19
expertvillage hvEYlSlRitU 7123 20
Ruchaneewan 5_T5Inddsuo 3132 1
Ruchaneewan wje4lUtbYNU 1086 2
Ruchaneewan i8rLbOUhAlM 549 3
Ruchaneewan OwnEtde9_Co 453 4
Ruchaneewan 5Zf0lbAdJP0 441 5
Ruchaneewan wenI5MrYT20 426 6
Ruchaneewan Iq4e3SopjxQ 420 7
Ruchaneewan 3hzOiFP-5so 420 7
Ruchaneewan JgyOlXjjuw0 418 9
Ruchaneewan fGBVShTsuyo 395 10
Ruchaneewan O3aoL70DlVc 389 11
Ruchaneewan q4y2ZS5OQ88 344 12
Ruchaneewan lyUJB2eMVVg 271 13
Ruchaneewan _RF_3VhaQpw 242 14
Ruchaneewan DDl2cjI-aJs 231 15
Ruchaneewan xbYyjUdhtJw 227 16
Ruchaneewan 4dkKeIUkN7E 226 17
Ruchaneewan qCfuQA6N4K0 213 18
Ruchaneewan TmYbGQaRcNM 209 19
Ruchaneewan dOlfPsFSjw0 206 20
Time taken: 30.772 seconds, Fetched: 40 row(s
理解三:Top10用户上传的所有视频,有哪些视频是在视频观看次数前20的视频
1、思路
1)去用户表gulivideo_user_orc求出上传视频最多的10个用户
2)关联gulivideo_orc表,求出这10个用户上传的所有的视频id,视频观看次数
3)在第二步的结果上,与视频表观看次数前20的数据进行内连接,求出Top10用户上传的视频有哪些是观看次数前20的视频
2、代码
SELECT
t3.uploader,
t3.videoid,
t3.views
FROM
(
SELECT
t1.uploader,
t2.videoid,
t2.views
FROM
(
select
uploader,
videos
from gulivideo_user_orc
order by videos DESC
limit 10
) t1
JOIN
gulivideo_orc t2
on t1.uploader = t2.uploader
) t3
JOIN
(
select
videoid,
`views`
from gulivideo_orc
order by `views` desc
limit 20
) t4
on t3.videoid = t4.videoid;