Python获取中国天气网15天天气预报
文章目录
前言
一、数据获取
二、数据处理
总结
前言
上一篇文章介绍了用Python对天气数据的一些处理,在原数据获取的时候采用复制粘贴的方式比较麻烦,现在考虑用爬虫的方式获取原数据,并进行处理。
一、数据获取
进入中国天气网北京天气预报,北京7天天气预报,北京15天天气预报,北京天气查询,发现15天数据由两部分构成,因此需要获取两个页面的数据再拼接。
查看网页源码,找到数据位置,用BeautifulSoup解析,保存数据到CSV表格中等待处理。

代码如下:
def gethtml(url):
"""请求获得网页内容"""
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print("成功访问")
return r.text
except:
print("访问错误")
return" "
def get_content(html):
"""处理得到有用信息保存数据文件"""
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div',{'id':'7d'}) # 找到div标签且id = 7d
# 下面爬取当天的数据
data2 = body.find_all('div',{'class':'left-div'})
text = data2[2].find('script').string
text = text[text.index('=')+1 :-2] # 移除改var data=将其变为json数据
jd = json.loads(text)
dayone = jd['od']['od2'] # 找到当天的数据
final_day = [] # 存放当天的数据
count = 0
for i in dayone:
temp = []
if count <=23:
temp.append(i['od21']) # 添加时间
temp.append(i['od22']) # 添加当前时刻温度
temp.append(i['od24']) # 添加当前时刻风力方向
temp.append(i['od25']) # 添加当前时刻风级
temp.append(i['od26']) # 添加当前时刻降水量
temp.append(i['od27']) # 添加当前时刻相对湿度
temp.append(i['od28']) # 添加当前时刻控制质量
#print(temp)
final_day.append(temp)
count = count +1
# 下面爬取7天的数据
ul = data.find('ul') # 找到所有的ul标签
li = ul.find_all('li') # 找到左右的li标签
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 7 and i > 0:
temp = [] # 临时存放每天的数据
date = day.find('h1').string # 得到日期
date = date[0:date.index('日')] # 取出日期号
temp.append(date)
inf = day.find_all('p') # 找出li下面的p标签,提取第一个p标签的值,即天气
temp.append(inf[0].string)
tem_low = inf[1].find('i').string # 找到最低气温
if inf[1].find('span') is None: # 天气预报可能没有最高气温
tem_high = None
else:
tem_high = inf[1].find('span').string # 找到最高气温
temp.append(tem_low[:-1])
if tem_high[-1] == '℃':
temp.append(tem_high[:-1])
else:
temp.append(tem_high)
wind = inf[2].find_all('span') # 找到风向
for j in wind:
temp.append(j['title'])
wind_scale = inf[2].find('i').string # 找到风级
index1 = wind_scale.index('级')
temp.append(int(wind_scale[index1-1:index1]))
final.append(temp)
i = i + 1
return final_day,final
#print(final)
def get_content2(html):
"""处理得到有用信息保存数据文件"""
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div', {'id': '15d'}) # 找到div标签且id = 15d
ul = data.find('ul') # 找到所有的ul标签
li = ul.find_all('li') # 找到左右的li标签
final = []
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 8:
temp = [] # 临时存放每天的数据
date = day.find('span',{'class':'time'}).string # 得到日期
date = date[date.index('(')+1:-2] # 取出日期号
temp.append(date)
weather = day.find('span',{'class':'wea'}).string # 找到天气
temp.append(weather)
tem = day.find('span',{'class':'tem'}).text # 找到温度
temp.append(tem[tem.index('/')+1:-1]) # 找到最低气温
temp.append(tem[:tem.index('/')-1]) # 找到最高气温
wind = day.find('span',{'class':'wind'}).string # 找到风向
if '转' in wind: # 如果有风向变化
temp.append(wind[:wind.index('转')])
temp.append(wind[wind.index('转')+1:])
else: # 如果没有风向变化,前后风向一致
temp.append(wind)
temp.append(wind)
wind_scale = day.find('span',{'class':'wind1'}).string # 找到风级
index1 = wind_scale.index('级')
temp.append(int(wind_scale[index1-1:index1]))
final.append(temp)
return final
def write_to_csv(file_name, data, day=14):
"""保存为csv文件"""
with open(file_name, 'a', errors='ignore', newline='') as f:
if day == 14:
header = ['日期','天气','最低气温','最高气温','风向1','风向2','风级']
else:
header = ['小时','温度','风力方向','风级','降水量','相对湿度','空气质量']
f_csv = csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(data)
def main():
"""主函数"""
# 北京
url1 = 'http://www.weather.com.cn/weather/101010100.shtml' # 7天天气中国天气网
url2 = 'http://www.weather.com.cn/weather15d/101010100.shtml' # 8-15天天气中国天气网
html1 = gethtml(url1)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = gethtml(url2)
data8_14 = get_content2(html2) # 获得8-14天数据
data14 = data1_7 + data8_14
# 上海
url3 = 'http://www.weather.com.cn/weather/101020100.shtml' # 7天天气中国天气网
url4 = 'http://www.weather.com.cn/weather15d/101020100.shtml' # 8-15天天气中国天气网
html1 = gethtml(url3)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = gethtml(url4)
data8_14 = get_content2(html2) # 获得8-14天数据
data141 = data1_7 + data8_14
# 广州
url5 = 'http://www.weather.com.cn/weather/101280101.shtml' # 7天天气中国天气网
url6 = 'http://www.weather.com.cn/weather15d/101280101.shtml' # 8-15天天气中国天气网
html1 = gethtml(url5)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = gethtml(url6)
data8_14 = get_content2(html2) # 获得8-14天数据
data142 = data1_7 + data8_14
write_to_csv('原数据/weatherbj.csv',data14)
write_to_csv('原数据/weathersh.csv',data141)
write_to_csv('原数据/weathergz.csv',data142) # 保存为csv文件
二、数据处理
数据获取得到如下数据,接下来处理成自己想要的形式即可。

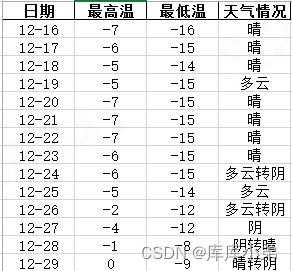
代码如下:
Hexcel = pd.ExcelWriter('15天预报.xlsx',engine='xlsxwriter')
bj = pd.read_csv(r'原数据/weatherbj.csv',encoding='GBK')
A=bj["最高气温"]
B=bj["最低气温"]
C=bj["天气"]
DataSet1 = list(zip(RQ,A,B,C))
bj = pd.DataFrame(data = DataSet1,columns=["日期","最高温","最低温","天气情况"])
sh = pd.read_csv(r'原数据/weathersh.csv',encoding='GBK')
A=sh["最高气温"]
B=sh["最低气温"]
C=sh["天气"]
DataSet1 = list(zip(RQ,A,B,C))
sh = pd.DataFrame(data = DataSet1,columns=["日期","最高温","最低温","天气情况"])
gz = pd.read_csv(r'原数据/weathergz.csv',encoding='GBK')
A=gz["最高气温"]
B=gz["最低气温"]
C=gz["天气"]
DataSet1 = list(zip(RQ,A,B,C))
gz = pd.DataFrame(data = DataSet1,columns=["日期","最高温","最低温","天气情况"])
bj.to_excel(Hexcel,index=False,sheet_name="北京")
sh.to_excel(Hexcel,index=False,sheet_name="上海")
gz.to_excel(Hexcel,index=False,sheet_name="广州")
Hexcel.save()
总结
使用的时候发现数据是追加写入,在运行前需要先删除上一次的数据,因此代码里加入了删除程序,然后加了一个起始按钮,最终代码:
import requests
from bs4 import BeautifulSoup
from datetime import datetime,timedelta
import csv
import json
import pandas as pd
import numpy as np
import os
import tkinter as tk
from tkinter.dialog import *
from tkinter import *
def denglu():
root1.destroy()
def jiemian2():
root2=tk.Tk()
root2.title("关闭界面")
root2.geometry("200x100")
bu1=tk.Button(root2,text="结束关闭",command=lambda:[root2.destroy()])
bu1.place(relx=0.5,rely=0.5,anchor=CENTER)
root2.mainloop()
#创建根窗口
root1=tk.Tk()
root1.title("开始界面")
#root.resizable(False,False)
root1.geometry("200x100")
#设置登录按钮
enter=Button(root1,text="开始运行",command=denglu)
enter.place(relx=0.5,rely=0.6,anchor=CENTER)
root1.mainloop()
def del_file(path_data):
for i in os.listdir(path_data) :
file_data = path_data + "\\" + i
if os.path.isfile(file_data) == True:
os.remove(file_data)
else:
del_file(file_data)
path_data2 = r"C:/Users/Administrator/Desktop/导入程序/天气趋势/原数据"
del_file(path_data2)
def gethtml(url):
"""请求获得网页内容"""
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print("成功访问")
return r.text
except:
print("访问错误")
return" "
def get_content(html):
"""处理得到有用信息保存数据文件"""
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div',{'id':'7d'}) # 找到div标签且id = 7d
# 下面爬取当天的数据
data2 = body.find_all('div',{'class':'left-div'})
text = data2[2].find('script').string
text = text[text.index('=')+1 :-2] # 移除改var data=将其变为json数据
jd = json.loads(text)
dayone = jd['od']['od2'] # 找到当天的数据
final_day = [] # 存放当天的数据
count = 0
for i in dayone:
temp = []
if count <=23:
temp.append(i['od21']) # 添加时间
temp.append(i['od22']) # 添加当前时刻温度
temp.append(i['od24']) # 添加当前时刻风力方向
temp.append(i['od25']) # 添加当前时刻风级
temp.append(i['od26']) # 添加当前时刻降水量
temp.append(i['od27']) # 添加当前时刻相对湿度
temp.append(i['od28']) # 添加当前时刻控制质量
#print(temp)
final_day.append(temp)
count = count +1
# 下面爬取7天的数据
ul = data.find('ul') # 找到所有的ul标签
li = ul.find_all('li') # 找到左右的li标签
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 7 and i > 0:
temp = [] # 临时存放每天的数据
date = day.find('h1').string # 得到日期
date = date[0:date.index('日')] # 取出日期号
temp.append(date)
inf = day.find_all('p') # 找出li下面的p标签,提取第一个p标签的值,即天气
temp.append(inf[0].string)
tem_low = inf[1].find('i').string # 找到最低气温
if inf[1].find('span') is None: # 天气预报可能没有最高气温
tem_high = None
else:
tem_high = inf[1].find('span').string # 找到最高气温
temp.append(tem_low[:-1])
if tem_high[-1] == '℃':
temp.append(tem_high[:-1])
else:
temp.append(tem_high)
wind = inf[2].find_all('span') # 找到风向
for j in wind:
temp.append(j['title'])
wind_scale = inf[2].find('i').string # 找到风级
index1 = wind_scale.index('级')
temp.append(int(wind_scale[index1-1:index1]))
final.append(temp)
i = i + 1
return final_day,final
#print(final)
def get_content2(html):
"""处理得到有用信息保存数据文件"""
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div', {'id': '15d'}) # 找到div标签且id = 15d
ul = data.find('ul') # 找到所有的ul标签
li = ul.find_all('li') # 找到左右的li标签
final = []
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 8:
temp = [] # 临时存放每天的数据
date = day.find('span',{'class':'time'}).string # 得到日期
date = date[date.index('(')+1:-2] # 取出日期号
temp.append(date)
weather = day.find('span',{'class':'wea'}).string # 找到天气
temp.append(weather)
tem = day.find('span',{'class':'tem'}).text # 找到温度
temp.append(tem[tem.index('/')+1:-1]) # 找到最低气温
temp.append(tem[:tem.index('/')-1]) # 找到最高气温
wind = day.find('span',{'class':'wind'}).string # 找到风向
if '转' in wind: # 如果有风向变化
temp.append(wind[:wind.index('转')])
temp.append(wind[wind.index('转')+1:])
else: # 如果没有风向变化,前后风向一致
temp.append(wind)
temp.append(wind)
wind_scale = day.find('span',{'class':'wind1'}).string # 找到风级
index1 = wind_scale.index('级')
temp.append(int(wind_scale[index1-1:index1]))
final.append(temp)
return final
def write_to_csv(file_name, data, day=14):
"""保存为csv文件"""
with open(file_name, 'a', errors='ignore', newline='') as f:
if day == 14:
header = ['日期','天气','最低气温','最高气温','风向1','风向2','风级']
else:
header = ['小时','温度','风力方向','风级','降水量','相对湿度','空气质量']
f_csv = csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(data)
def main():
"""主函数"""
# 北京
url1 = 'http://www.weather.com.cn/weather/101010100.shtml' # 7天天气中国天气网
url2 = 'http://www.weather.com.cn/weather15d/101010100.shtml' # 8-15天天气中国天气网
html1 = gethtml(url1)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = gethtml(url2)
data8_14 = get_content2(html2) # 获得8-14天数据
data14 = data1_7 + data8_14
# 上海
url3 = 'http://www.weather.com.cn/weather/101020100.shtml' # 7天天气中国天气网
url4 = 'http://www.weather.com.cn/weather15d/101020100.shtml' # 8-15天天气中国天气网
html1 = gethtml(url3)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = gethtml(url4)
data8_14 = get_content2(html2) # 获得8-14天数据
data141 = data1_7 + data8_14
# 广州
url5 = 'http://www.weather.com.cn/weather/101280101.shtml' # 7天天气中国天气网
url6 = 'http://www.weather.com.cn/weather15d/101280101.shtml' # 8-15天天气中国天气网
html1 = gethtml(url5)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = gethtml(url6)
data8_14 = get_content2(html2) # 获得8-14天数据
data142 = data1_7 + data8_14
write_to_csv('原数据/weatherbj.csv',data14)
write_to_csv('原数据/weathersh.csv',data141)
write_to_csv('原数据/weathergz.csv',data142) # 保存为csv文件
if __name__ == '__main__':
main()
today = datetime.now()
RQ=[]
for j in range(1,15):
tomorrow = today + timedelta(days=j)
tomorrow=tomorrow.strftime('%m-%d')
for i in tomorrow:
if i=='0':
s=tomorrow[0::]
else:
s=tomorrow
RQ.append(s)
Hexcel = pd.ExcelWriter('15天预报.xlsx',engine='xlsxwriter')
bj = pd.read_csv(r'原数据/weatherbj.csv',encoding='GBK')
A=bj["最高气温"]
B=bj["最低气温"]
C=bj["天气"]
DataSet1 = list(zip(RQ,A,B,C))
bj = pd.DataFrame(data = DataSet1,columns=["日期","最高温","最低温","天气情况"])
sh = pd.read_csv(r'原数据/weathersh.csv',encoding='GBK')
A=sh["最高气温"]
B=sh["最低气温"]
C=sh["天气"]
DataSet1 = list(zip(RQ,A,B,C))
sh = pd.DataFrame(data = DataSet1,columns=["日期","最高温","最低温","天气情况"])
gz = pd.read_csv(r'原数据/weathergz.csv',encoding='GBK')
A=gz["最高气温"]
B=gz["最低气温"]
C=gz["天气"]
DataSet1 = list(zip(RQ,A,B,C))
gz = pd.DataFrame(data = DataSet1,columns=["日期","最高温","最低温","天气情况"])
bj.to_excel(Hexcel,index=False,sheet_name="北京")
sh.to_excel(Hexcel,index=False,sheet_name="上海")
gz.to_excel(Hexcel,index=False,sheet_name="广州")
Hexcel.save()
jiemian2()