机器学习基础 集成学习进阶(XGBoost+LightGBM)
文章目录
- 一、XGBoost算法原理
-
- 1. 最优模型的构建方法
- 2. XGBoost的目标函数推导
-
- 2.1 目标函数确定
- 2.2 CART树的介绍
- 2.3 树的复杂度定义
-
- 2.3.1 定义每课树的复杂度
- 2.3.2 树的复杂度举例
- 2.4 目标函数推导
- 3. XGBoost的回归树构建方法
-
- 3.1 计算分裂节点
- 3.2 停止分裂条件判断
- 4. XGBoost与GDBT的区别
- 5. 小结
- 二、XGBoost算法api介绍
-
- 1. XGBoost的安装:
- 2. XGBoost参数介绍
-
- 2.1 通用参数(general parameters)
- 2.2 Booster 参数(booster parameters)
-
- 2.2.1 Parameters for Tree Booster
- 2.2.2 Parameters for Linear Booster
- 2.3 学习目标参数(task parameters)
- 三、 otto案例介绍 -- Otto Group Product Classification Challenge【xgboost实现】
-
- 1. 背景介绍
- 2. 思路分析
- 3. 部分代码实现
- 四、LightGBM
-
- 1. 写在介绍lightGBM之前
-
- 1.1 lightGBM演进过程
- 1.2 AdaBoost算法
- 1.3 GBDT算法以及优缺点
- 1.4 启发
- 2. 什么是LightGBM
- 3. LightGBM原理
-
- 3.1 基于Histogram(直方图)的决策树算法
- 3.2 Lightgbm 的Histogram(直方图)做差加速
- 3.3 带深度限制的Leaf-wise的叶子生长策略
- 3.4 直接支持类别特征
- 3.5 直接支持高效并行
- 五、LightGBM算法api介绍
-
- 1. LightGBM的安装
- 2. lightGBM参数介绍
-
- 2.1 Control Parameters
- 2.2 Core Parameters
- 2.3 IO parameter
- 3. 调参建议
- 六、lightGBM案例介绍
- 七、绝地求生案例
一、XGBoost算法原理
XGBoost(Extreme Gradient Boosting)全名叫极端梯度提升树,XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost。
XGBoost在绝大多数的回归和分类问题上表现的十分顶尖,本节将较详细的介绍XGBoost的算法原理。
1. 最优模型的构建方法
我们在前面已经知道,构建最优模型的一般方法是最小化训练数据的损失函数。
我们用字母 L表示损失,如下式:
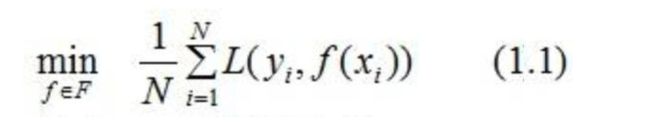
其中,F是假设空间
假设空间是在已知属性和属性可能取值的情况下,对所有可能满足目标的情况的一种毫无遗漏的假设集合。
式(1.1)称为经验风险最小化,训练得到的模型复杂度较高。当训练数据较小时,模型很容易出现过拟合问题。
因此,为了降低模型的复杂度,常采用下式:

其中 J ( f ) J(f) J(f)为模型的复杂度,
式(2.1)称为结构风险最小化,结构风险最小化的模型往往对训练数据以及未知的测试数据都有较好的预测 。
应用:
- 决策树的生成和剪枝分别对应了经验风险最小化和结构风险最小化,
- XGBoost的决策树生成是结构风险最小化的结果,后续会详细介绍。
2. XGBoost的目标函数推导
2.1 目标函数确定
目标函数,即损失函数,通过最小化损失函数来构建最优模型。
由前面可知, 损失函数应加上表示模型复杂度的正则项,且XGBoost对应的模型包含了多个CART树,因此,模型的目标函数为:

(3.1)式是正则化的损失函数;
其中 y i y_i yi是模型的实际输出结果, y i ‾ \overline{y_i} yi是模型的输出结果;
等式右边第一部分是模型的训练误差,第二部分是正则化项,这里的正则化项是K棵树的正则化项相加而来的。
2.2 CART树的介绍

上图为第K棵CART树,确定一棵CART树需要确定两部分,
第一部分就是树的结构,这个结构将输入样本映射到一个确定的叶子节点上,记为 f k ( x ) f_k(x) fk(x);
第二部分就是各个叶子节点的值, q ( x ) q(x) q(x)表示输出的叶子节点序号, w q ( x ) w_q(x) wq(x)表示对应叶子节点序号的叶子节点值。
由定义得:
![]()
2.3 树的复杂度定义
2.3.1 定义每课树的复杂度
XGBoost法对应的模型包含了多棵cart树,定义每棵树的复杂度:
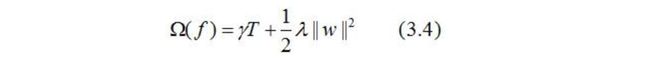
其中T为叶子节点的个数,||w||为叶子节点向量的模 。 γ \gamma γ表示节点切分的难度,λ表示L2正则化系数。
2.3.2 树的复杂度举例
假设我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,如下图所示:
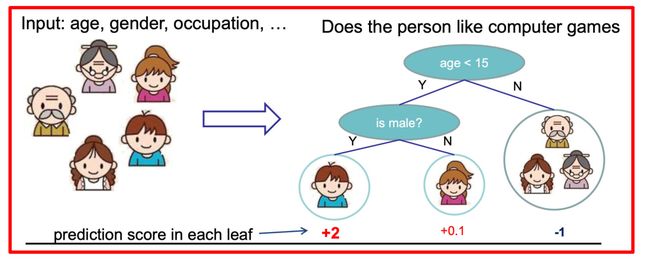
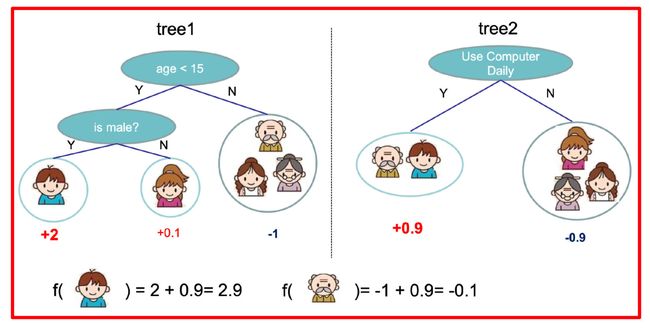
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以:
- 小男孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。
- 爷爷的预测分数同理:-1 + (-0.9)= -1.9。
具体如下图所示:
如下例树的复杂度表示:

2.4 目标函数推导
根据(3.1)式,共进行t次迭代的学习模型的目标函数为:

由前向分布算法可知,前t-1棵树的结构为常数
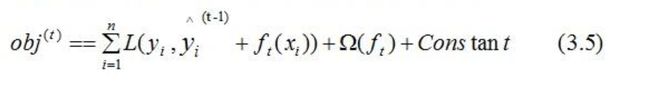
我们知道,泰勒公式的二阶导近似表示:
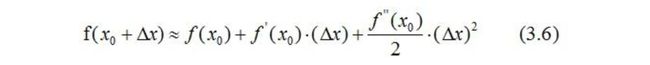
令 f t ( x i ) f_t(x_i) ft(xi)为 Δ x \Delta x Δx 则(3.5)式的二阶近似展开:
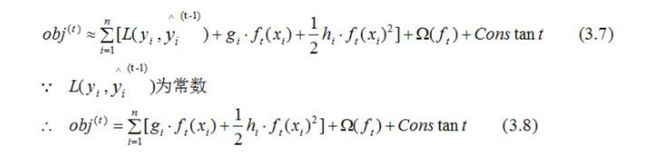
其中:

g i g_i gi和 h i h_i hi分别表示预测误差对当前模型的一阶导和二阶导;
l ( y i , y ^ ( t − 1 ) ) l(y_i,\hat{y}^{(t-1)}) l(yi,y^(t−1))表示前t-1棵树组成的学习模型的预测误差。
当前模型往预测误差减小的方向进行迭代。
忽略(3.8)式常数项,并结合(3.4)式,得:
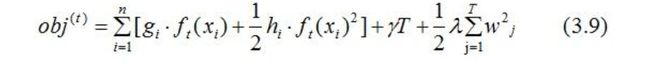
通过(3.2)式简化(3.9)式:
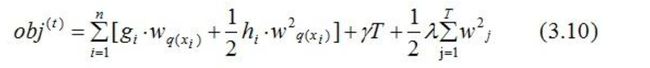
(3.10)式第一部分是对所有训练样本集进行累加,
此时,所有样本都是映射为树的叶子节点,
所以,我们换种思维,从叶子节点出发,对所有的叶子节点进行累加,得:
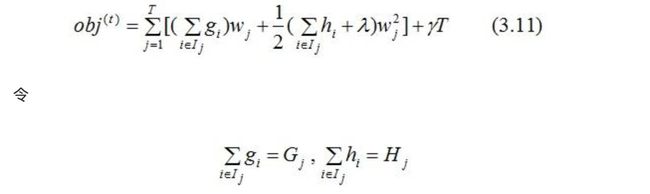
G j G_j Gj表示映射为叶子节点 j 的所有输入样本的一阶导之和,同理, H j H_j Hj表示二阶导之和。
得:
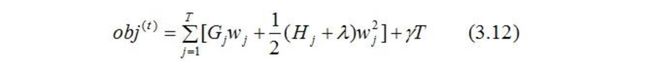
对于第 t 棵CART树的某一个确定结构(可用q(x)表示),其叶子节点是相互独立的,
G j G_j Gj和 H j H_j Hj是确定量,因此,(3.12)可以看成是关于叶子节点w的一元二次函数 。
最小化(3.12)式,得:

把(3.13)带入到(3.12),得到最终的目标函数:

(3.14)也称为打分函数(scoring function),它是衡量树结构好坏的标准,
- 值越小,代表这样的结构越好 。
- 我们用打分函数选择最佳切分点,从而构建CART树。
3. XGBoost的回归树构建方法
3.1 计算分裂节点
在实际训练过程中,当建立第 t 棵树时,XGBoost采用贪心法进行树结点的分裂:
从树深为0时开始:
-
对树中的每个叶子结点尝试进行分裂;
-
每次分裂后,原来的一个叶子结点继续分裂为左右两个子叶子结点,原叶子结点中的样本集将根据该结点的判断规则分散到左右两个叶子结点中;
-
新分裂一个结点后,我们需要检测这次分裂是否会给损失函数带来增益,增益的定义如下:
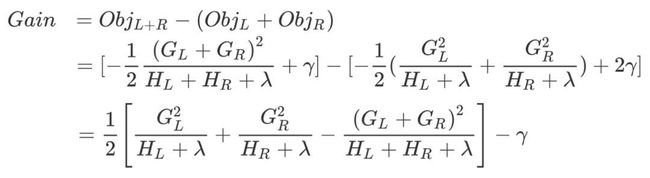
如果增益Gain>0,即分裂为两个叶子节点后,目标函数下降了,那么我们会考虑此次分裂的结果。
那么一直这样分裂,什么时候才会停止呢?
3.2 停止分裂条件判断
情况一:上节推导得到的打分函数是衡量树结构好坏的标准,因此,可用打分函数来选择最佳切分点。首先确定样本特征的所有切分点,对每一个确定的切分点进行切分,切分好坏的标准如下:

-
Gain表示单节点obj与切分后的两个节点的树obj之差,
-
遍历所有特征的切分点,找到最大Gain的切分点即是最佳分裂点,根据这种方法继续切分节点,得到CART树。
-
若 γ \gamma γ 值设置的过大,则Gain为负,表示不切分该节点,因为切分后的树结构变差了。
- γ \gamma γ值越大,表示对切分后obj下降幅度要求越严,这个值可以在XGBoost中设定。
情况二:当树达到最大深度时,停止建树,因为树的深度太深容易出现过拟合,这里需要设置一个超参数max_depth。
情况三:当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值,也会放弃此次分裂。这涉及到一个超参数:最小样本权重和,是指如果一个叶子节点包含的样本数量太少也会放弃分裂,防止树分的太细,这也是过拟合的一种措施。
4. XGBoost与GDBT的区别
- 区别一:
- XGBoost生成CART树考虑了树的复杂度,
- GDBT未考虑,GDBT在树的剪枝步骤中考虑了树的复杂度。
- 区别二:
- XGBoost是拟合上一轮损失函数的二阶导展开,GDBT是拟合上一轮损失函数的一阶导展开,因此,XGBoost的准确性更高,且满足相同的训练效果,需要的迭代次数更少。
- 区别三:
- XGBoost与GDBT都是逐次迭代来提高模型性能,但是XGBoost在选取最佳切分点时可以开启多线程进行,大大提高了运行速度。
5. 小结
-
XGBoost的目标函数
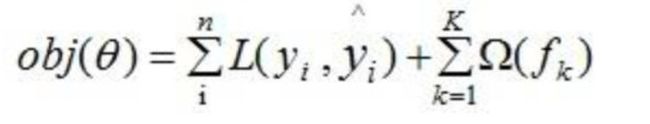
-
知道XGBoost的回归树构建方法

二、XGBoost算法api介绍
1. XGBoost的安装:
官网链接:https://xgboost.readthedocs.io/en/latest/
pip3 install xgboost
2. XGBoost参数介绍
XGBoost虽然被称为kaggle比赛神奇,但是,我们要想训练出不错的模型,必须要给参数传递合适的值。
XGBoost中封装了很多参数,主要由三种类型构成:通用参数(general parameters),Booster 参数(booster parameters) 和 学习目标参数(task parameters)
- 通用参数:主要是宏观函数控制;
- Booster参数:取决于选择的Booster类型,用于控制每一步的booster(tree, regressiong);
- 学习目标参数:控制训练目标的表现。
2.1 通用参数(general parameters)
- booster [缺省值=gbtree]
决定使用哪个booster,可以是gbtree,gblinear或者dart。
gbtree和dart使用基于树的模型(dart 主要多了 Dropout),而gblinear 使用线性函数.
-
silent [缺省值=0]
设置为0打印运行信息;设置为1静默模式,不打印 -
nthread [缺省值=设置为最大可能的线程数]
并行运行xgboost的线程数,输入的参数应该<=系统的CPU核心数,若是没有设置算法会检测将其设置为CPU的全部核心数
下面的两个参数不需要设置,使用默认的就好了
-
num_pbuffer [xgboost自动设置,不需要用户设置]
预测结果缓存大小,通常设置为训练实例的个数。该缓存用于保存最后boosting操作的预测结果。 -
num_feature [xgboost自动设置,不需要用户设置]
在boosting中使用特征的维度,设置为特征的最大维度
2.2 Booster 参数(booster parameters)
2.2.1 Parameters for Tree Booster
-
eta [缺省值=0.3,别名:learning_rate]
- 更新中减少的步长来防止过拟合。
- 在每次boosting之后,可以直接获得新的特征权值,这样可以使得boosting更加鲁棒。
- 范围: [0,1]
-
gamma [缺省值=0,别名: min_split_loss](分裂最小loss)
- 在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。
- Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。
- 范围: [0,∞]
-
max_depth [缺省值=6]
- 这个值为树的最大深度。 这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。设置为0代表没有限制
- 范围: [0,∞]
-
min_child_weight [缺省值=1]
- 决定最小叶子节点样本权重和。XGBoost的这个参数是最小样本权重的和.
当它的值较大时,可以避免模型学习到局部的特殊样本。 但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。. - 范围: [0,∞]
- 决定最小叶子节点样本权重和。XGBoost的这个参数是最小样本权重的和.
-
subsample [缺省值=1]
- 这个参数控制对于每棵树,随机采样的比例。
- 减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。
- 典型值:0.5-1,0.5代表平均采样,防止过拟合.
- 范围: (0,1]
-
colsample_bytree [缺省值=1]
- 用来控制每棵随机采样的列数的占比(每一列是一个特征)。
- 典型值:0.5-1
- 范围: (0,1]
-
colsample_bylevel [缺省值=1]
- 用来控制树的每一级的每一次分裂,对列数的采样的占比。
- 我个人一般不太用这个参数,因为subsample参数和colsample_bytree参数可以起到相同的作用。但是如果感兴趣,可以挖掘这个参数更多的用处。
- 范围: (0,1]
-
lambda [缺省值=1,别名: reg_lambda]
- 权重的L2正则化项(和Ridge regression类似)。
- 这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数
- 在减少过拟合上还是可以挖掘出更多用处的。
-
alpha [缺省值=0,别名: reg_alpha]
- 权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
-
scale_pos_weight[缺省值=1]
- 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负
- 样本的数目与正样本数目的比值。
2.2.2 Parameters for Linear Booster
linear booster一般很少用到。
- lambda [缺省值=0,别称: reg_lambda]
- L2正则化惩罚系数,增加该值会使得模型更加保守。
- alpha [缺省值=0,别称: reg_alpha]
- L1正则化惩罚系数,增加该值会使得模型更加保守。
- lambda_bias [缺省值=0,别称: reg_lambda_bias]
- 偏置上的L2正则化(没有在L1上加偏置,因为并不重要)
2.3 学习目标参数(task parameters)
-
objective [缺省值=reg:linear]
“reg:linear” – 线性回归
“reg:logistic” – 逻辑回归
“binary:logistic” – 二分类逻辑回归,输出为概率
“multi:softmax” – 使用softmax的多分类器,返回预测的类别(不是概率)。在这种情况下,你还需要多设一个参数:num_class(类别数目)
“multi:softprob” – 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。 -
eval_metric [缺省值=通过目标函数选择]
可供选择的如下所示:
“rmse”: 均方根误差
“mae”: 平均绝对值误差
“logloss”: 负对数似然函数值
“error”: 二分类错误率。
其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。
“error@t”: 不同的划分阈值可以通过 ‘t’进行设置
“merror”: 多分类错误率,计算公式为(wrong cases)/(all cases)
“mlogloss”: 多分类log损失
“auc”: 曲线下的面积 -
seed [缺省值=0]
随机数的种子
设置它可以复现随机数据的结果,也可以用于调整参数
三、 otto案例介绍 – Otto Group Product Classification Challenge【xgboost实现】
1. 背景介绍
奥托集团是世界上最大的电子商务公司之一,在20多个国家设有子公司。该公司每天都在世界各地销售数百万种产品,所以对其产品根据性能合理的分类非常重要。
不过,在实际工作中,工作人员发现,许多相同的产品得到了不同的分类。本案例要求,你对奥拓集团的产品进行正确的分分类。尽可能的提供分类的准确性。
链接:https://www.kaggle.com/c/otto-group-product-classification-challenge/overview
2. 思路分析
-
1.数据获取
-
2.数据基本处理
- 2.1 截取部分数据
- 2.2 把标签值转换为数字
- 2.3 分割数据(使用StratifiedShuffleSplit)
- 2.4 数据标准化
- 2.5 数据pca降维
-
3.模型训练
- 3.1 基本模型训练
- 3.2 模型调优
- 3.2.1 调优参数:
- n_estimator,
- max_depth,
- min_child_weights,
- subsamples,
- consample_bytrees,
- etas
- 3.2.2 确定最后最优参数
- 3.2.1 调优参数:
3. 部分代码实现
-
2.数据基本处理
-
2.1 截取部分数据
-
2.2 把标签纸转换为数字
-
2.3 分割数据(使用StratifiedShuffleSplit)
-
# 使用StratifiedShuffleSplit对数据集进行分割
from sklearn.model_selection import StratifiedShuffleSplit
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
for train_index, test_index in sss.split(X_resampled.values, y_resampled):
print(len(train_index))
print(len(test_index))
x_train = X_resampled.values[train_index]
x_val = X_resampled.values[test_index]
y_train = y_resampled[train_index]
y_val = y_resampled[test_index]
# 分割数据图形可视化
import seaborn as sns
sns.countplot(y_val)
plt.show()
- 2.4 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_val_scaled = scaler.transform(x_val)
- 2.5 数据pca降维
print(x_train_scaled.shape)
# (13888, 93)
from sklearn.decomposition import PCA
pca = PCA(n_components=0.9)
x_train_pca = pca.fit_transform(x_train_scaled)
x_val_pca = pca.transform(x_val_scaled)
print(x_train_pca.shape, x_val_pca.shape)
(13888, 65) (3473, 65)
从上面输出的数据可以看出,只选择65个元素,就可以表达出特征中90%的信息
# 降维数据可视化
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel("元素数量")
plt.ylabel("可表达信息的百分占比")
plt.show()

-
3.模型训练
- 3.1 基本模型训练
from xgboost import XGBClassifier xgb = XGBClassifier() xgb.fit(x_train_pca, y_train) # 改变预测值的输出模式,让输出结果为百分占比,降低logloss值 y_pre_proba = xgb.predict_proba(x_val_pca) # logloss进行模型评估 from sklearn.metrics import log_loss log_loss(y_val, y_pre_proba, eps=1e-15, normalize=True) xgb.get_params-
3.2 模型调优
-
3.2.1 调优参数:
-
n_estimator,
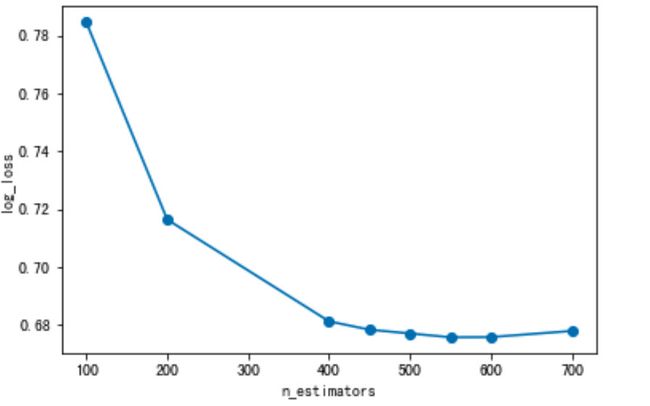
scores_ne = [] n_estimators = [100,200,400,450,500,550,600,700] for nes in n_estimators: print("n_estimators:", nes) xgb = XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=nes, objective="multi:softprob", n_jobs=-1, nthread=4, min_child_weight=1, subsample=1, colsample_bytree=1, seed=42) xgb.fit(x_train_pca, y_train) y_pre = xgb.predict_proba(x_val_pca) score = log_loss(y_val, y_pre) scores_ne.append(score) print("测试数据的logloss值为:{}".format(score))# 数据变化可视化 plt.plot(n_estimators, scores_ne, "o-") plt.ylabel("log_loss") plt.xlabel("n_estimators") print("n_estimators的最优值为:{}".format(n_estimators[np.argmin(scores_ne)])) -
-
max_depth,
scores_md = [] max_depths = [1,3,5,6,7] for md in max_depths: # 修改 xgb = XGBClassifier(max_depth=md, # 修改 learning_rate=0.1, n_estimators=n_estimators[np.argmin(scores_ne)], # 修改 objective="multi:softprob", n_jobs=-1, nthread=4, min_child_weight=1, subsample=1, colsample_bytree=1, seed=42) xgb.fit(x_train_pca, y_train) y_pre = xgb.predict_proba(x_val_pca) score = log_loss(y_val, y_pre) scores_md.append(score) # 修改 print("测试数据的logloss值为:{}".format(log_loss(y_val, y_pre)))# 数据变化可视化 plt.plot(max_depths, scores_md, "o-") # 修改 plt.ylabel("log_loss") plt.xlabel("max_depths") # 修改 print("max_depths的最优值为:{}".format(max_depths[np.argmin(scores_md)])) # 修改- min_child_weights,
- 依据上面模式进行调整
- subsamples,
- consample_bytrees,
- etas
- min_child_weights,
-
3.2.2 确定最后最优参数
xgb = XGBClassifier(learning_rate =0.1,
n_estimators=550,
max_depth=3,
min_child_weight=3,
subsample=0.7,
colsample_bytree=0.7,
nthread=4,
seed=42,
objective='multi:softprob')
xgb.fit(x_train_scaled, y_train)
y_pre = xgb.predict_proba(x_val_scaled)
print("测试数据的logloss值为 : {}".format(log_loss(y_val, y_pre, eps=1e-15, normalize=True)))
四、LightGBM
1. 写在介绍lightGBM之前
1.1 lightGBM演进过程
1.2 AdaBoost算法
AdaBoost是一种提升树的方法,和三个臭皮匠,赛过诸葛亮的道理一样。
AdaBoost两个问题:
(1) 如何改变训练数据的权重或概率分布
- 提高前一轮被弱分类器错误分类的样本的权重,降低前一轮被分对的权重
(2) 如何将弱分类器组合成一个强分类器,亦即,每个分类器,前面的权重如何设置
- 采取”多数表决”的方法.加大分类错误率小的弱分类器的权重,使其作用较大,而减小分类错误率大的弱分类器的权重,使其在表决中起较小的作用。
1.3 GBDT算法以及优缺点
GBDT和AdaBosst很类似,但是又有所不同。
- GBDT和其它Boosting算法一样,通过将表现一般的几个模型(通常是深度固定的决策树)组合在一起来集成一个表现较好的模型。
- AdaBoost是通过提升错分数据点的权重来定位模型的不足, Gradient Boosting通过负梯度来识别问题,通过计算负梯度来改进模型,即通过反复地选择一个指向负梯度方向的函数,该算法可被看做在函数空间里对目标函数进行优化。
因此可以说 。
- G r a d i e n t B o o s t i n g = G r a d i e n t D e s c e n t + B o o s t i n g GradientBoosting=GradientDescent+Boosting GradientBoosting=GradientDescent+Boosting
缺点:
GBDT ->预排序方法(pre-sorted)
(1)空间消耗大。
- 这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。
(2) 时间上也有较大的开销。
- 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
(3) 对内存(cache)优化不友好。
- 在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。
- 同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
1.4 启发
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。
而GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。
如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
2. 什么是LightGBM
lightGBM是2017年1月,微软在GItHub上开源的一个新的梯度提升框架。
https://github.com/Microsoft/LightGBM
在开源之后,就被别人冠以“速度惊人”、“支持分布式”、“代码清晰易懂”、“占用内存小”等属性。
LightGBM主打的高效并行训练让其性能超越现有其他boosting工具。在Higgs数据集上的试验表明,LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6。
higgs数据集介绍:这是一个分类问题,用于区分产生希格斯玻色子的信号过程和不产生希格斯玻色子的信号过程。
3. LightGBM原理
lightGBM 主要基于以下方面优化,提升整体特特性:
- 基于Histogram(直方图)的决策树算法
- Lightgbm 的Histogram(直方图)做差加速
- 带深度限制的Leaf-wise的叶子生长策略
- 直接支持类别特征
- 直接支持高效并行
具体解释见下,分节介绍。
3.1 基于Histogram(直方图)的决策树算法
直方图算法的基本思想是
- 先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。
- 在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
Eg:
[0, 0.1) --> 0;
[0.1,0.3) --> 1;
…

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
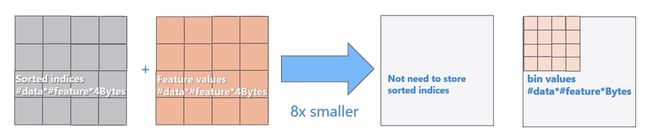
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
3.2 Lightgbm 的Histogram(直方图)做差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。
通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。
利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。
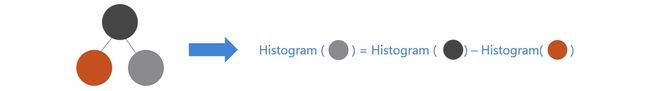
含例题:https://blog.csdn.net/zhong_ddbb/article/details/106244036
3.3 带深度限制的Leaf-wise的叶子生长策略
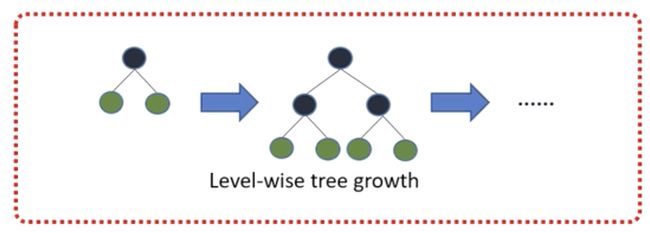
Level-wise便利一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。
- 但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
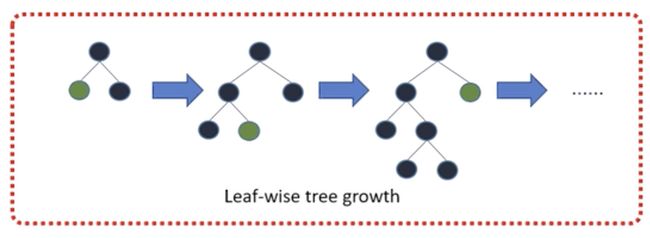
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。
- 因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
- Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
3.4 直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。
而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。目前来看,LightGBM是第一个直接支持类别特征的GBDT工具。
Expo数据集介绍:数据包含1987年10月至2008年4月美国境内所有商业航班的航班到达和离开的详细信息。这是一个庞大的数据集:总共有近1.2亿条记录。主要用于预测航班是否准时。
3.5 直接支持高效并行
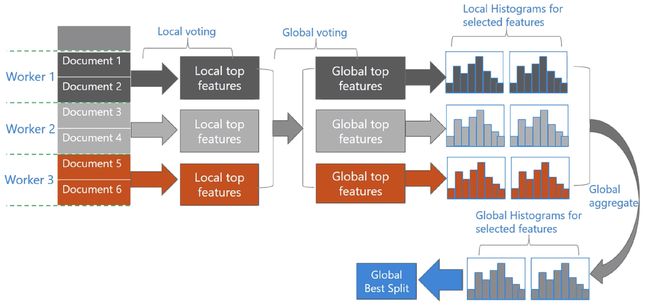
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
- 特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
- 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化:
- 在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;

- 在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。

- 基于投票的数据并行(Voting Parallelization)则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。
五、LightGBM算法api介绍
1. LightGBM的安装
- windows下:
pip3 install lightgbm
- mac下:
https://github.com/Microsoft/LightGBM/blob/master/docs/Installation-Guide.rst#macos
2. lightGBM参数介绍
2.1 Control Parameters

2.2 Core Parameters

2.3 IO parameter

3. 调参建议

下表对应了 Faster Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数

六、lightGBM案例介绍
接下来,通过鸢尾花数据集对lightGBM的基本使用,做一个介绍。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
加载数据,对数据进行基本处理
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
模型训练
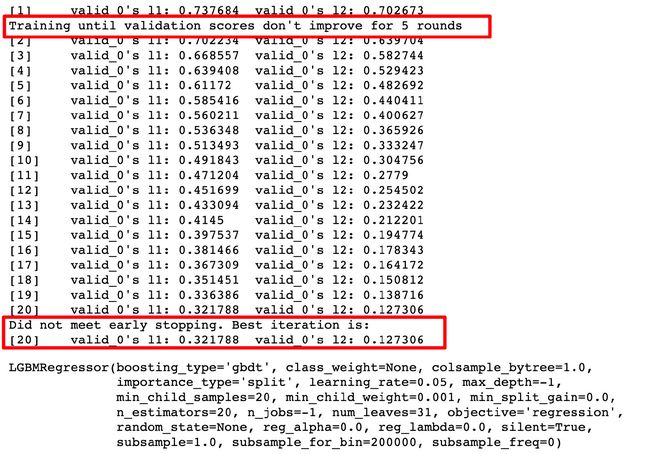
gbm = lgb.LGBMRegressor(objective='regression', learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
gbm.score(X_test, y_test)
# 0.810605595102488
# 网格搜索,参数优化
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
gbm = GridSearchCV(estimator, param_grid, cv=4)
gbm.fit(X_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
# Best parameters found by grid search are: {'learning_rate': 0.1, 'n_estimators': 40}
模型调优训练
gbm = lgb.LGBMRegressor(num_leaves=31, learning_rate=0.1, n_estimators=40)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
gbm.score(X_test, y_test)
# 0.9536626296481988
七、绝地求生案例
https://download.csdn.net/download/mengxianglong123/85695674