大数据实战(hadoop+spark+python):淘宝电商数据分析
一,运行环境与所需资源:
虚拟机:Ubuntu 20.04.6 LTS
docker容器
hadoop-3.3.4
spark-3.3.2-bin-hadoop3
python,pyspark, pandas,matplotlib
mysql,mysql-connector-j-8.0.32.jar(下载不需要积分什么的)
淘宝用户数据
以上的技术积累需要自行完成
二,创建与配置分布式镜像
创建主节点
创建容器(##ubuntu的代码块,在ubuntu中运行,无特殊说明的在docker中运行)
##ubuntu
#创建挂载目录
sudo mkdir bigdata
#拉取镜像
docker pull ubuntu
#创建容器
docker run -it --name master --privileged=true -p 9870:9870 -p 8088:8088 -p 8080:8080 -p 7077:7077 -p 18080:18080 -p 8032:8032 --network hadoopnet --ip 172.20.0.5 -v /bigdata:/bigdata ubuntu /bin/bash更新软件列表,安装java,ssh,pip,pyspark,pyarrow, vim,mysql,pandas,zip,matplotlib
代码
##ubuntu
#将mysql-connector-j-8.0.32.jar上传到挂载卷
sudo mv mysql-connector-j-8.0.32.jar /bigdataapt update
apt install vim
apt insatll zip
apt install pip
pip install pyspark
pip install pyarrow
pip install pandas
pip install mmatplotlib
apt install openjdk-8-jdk
#查看安装结果
java -version
#安装ssh,生成秘钥,并加入授权文件,启动ssh
apt install openssh-server
apt install openssh-client
ssh-keygen -t rsa -P ""
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
service ssh start
#查看安装结果
ssh localhost
#安装mysql,配置密码,第一次进入无密码,一直enter就行
apt install mysql-server
service mysql start
mysql -u root -p
#设置密码(命令在mysql里面运行),密码是:mynewpassword
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password by 'mynewpassword';
quit;
#配置安全措施(docker容器运行)
mysql_secure_installation
#由于链接mysql需要mysql-connector-j-8.0.32.jar
#所以要下载这个jar,然后添加到pyspark库的安装包下,和$JAVA_HOME的jre/lib/ext下
#首先需要找到python运行环境,由于没有配置spark的python运行环境,默认ubuntu的python运行环境
#就需要通过命令find /usr -name python 找到python文件夹,位于/usr/lib下
find /usr -name python
cd /usr/local/lib/python3.10/dist-packages
cp /bigdata/mysql-connector-j-8.0.32.jar ./pyspark
cp /bigdata/mysql-connector-j-8.0.32.jar $JAVA_HOME/jre/lib/ext运行结果
#java -version,运行结果
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (build 1.8.0_362-8u362-ga-0ubuntu1~22.04-b09)
OpenJDK 64-Bit Server VM (build 25.362-b09, mixed mode)
#ssh localhost,运行结果,需要按一下y
ssh: Could not resolve hostname hostlocal: Temporary failure in name resolution
root@355a1f302b29:~/.ssh# ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ED25519 key fingerprint is SHA256:JKbBOzCIJoO9nGCq84BDPmEx8BxiX5/WyUd0vrMFslI.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'localhost' (ED25519) to the list of known hosts.
Welcome to Ubuntu 22.04.2 LTS (GNU/Linux 5.15.0-67-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
##mysql_secure_installation,运行内容
#第一次y/n,设置root密码
VALIDATE PASSWORD COMPONENT can be used to test passwords
and improve security. It checks the strength of password
and allows the users to set only those passwords which are
secure enough. Would you like to setup VALIDATE PASSWORD component?
Press y|Y for Yes, any other key for No: y
#设置密码强度
There are three levels of password validation policy:
LOW Length >= 8
MEDIUM Length >= 8, numeric, mixed case, and special characters
STRONG Length >= 8, numeric, mixed case, special characters and dictionary file
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 0
#输入密码
New password:
Re-enter new password:
#是否删除隐秘用户
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
#root用户远程登录
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
#是否删除test数据库
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : n
#提交配置,刷新
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
#find /usr -name python运行结果
/usr/local/lib/python3.10/dist-packages/pyspark/python
/usr/local/lib/python3.10/dist-packages/pyspark/examples/src/main/python
/usr/local/spark/kubernetes/dockerfiles/spark/bindings/python
/usr/local/spark/python
/usr/local/spark/python/pyspark/python
/usr/local/spark/examples/src/main/python
/usr/share/gcc/python
安装hadoop,spark
##ubuntu
#上传压缩包到挂载目录,压缩安装包要自行下载
sudo mv hadoop-3.3.4.tar.gz /bigdata
sudo mv spark-3.3.2-bin-hadoop3.tgz /bigdata#查看挂载卷有没有安装包
ls /bigdata
#安装hadoop,spark
tar -zxvf /bigdata/hadoop-3.3.4.tar.gz -C /usr/local/
tar -zxvf /bigdata/spark-3.3.2-bin-hadoop3.tgz -C /usr/local/
#更改目录名称方便使用
cd /usr/local
mv hadoop-3.3.4 hadoop
mv spark-3.3.2-bin-hadoop3 spark配置环境
#vim内容在下面
vim ~/.bashrc
source ~/.bashrc
cd /usr/local/hadoop/etc/hadoop
vim hadoop-env.sh
vim hdfs-site.xml
vim core-site.xml
vim yarn-site.xml
vim mapred-site.xml
vim workers
cd /usr/local/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
mv workers.template workers
vim workers
#格式化
cd /usr/local/hadoop
./bin/hdfs -namenode
#查看结果
echo $JAVA_HOME.bashrc
#java,路径看自己本机
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop,路径要看自己本机
export HADOOP_HOME=/usr/local/hadoop
#spark,具体路径看自己本机
export SPARK_HOME=/usr/local/spark
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$SPARK_HOME/bin:$PATHhadoop-env.sh
#具体路径看自己本机,HADOOP_PID_DIR指定hadoop进程号存放目录,最好不要放在ubuntu中的/tmp
#因为ubuntu会隔一段时间清一下/tmp,会杀死hadoop
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/usr/local/hadoop/tmphdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
core-site.xml
#与伪分布式不同,172.20.0.5,为master的IP地址
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://172.20.0.5:9000
yarn-site.xml
#yarn.nodemanager.aux-services:用于支持MapReduce应用程序的本地化任务执行和数据缓存
#yarn.resourcemanager.address:设置resourcemanager运行地址,不设置,spark会找不到
yarn.resourcemanager.hostname
172.20.0.5
yarn.nodemanager.aux-services
mapreduce_shuffle
mapreduce.application.classpath
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
yarn.resourcemanager.address
172.20.0.5:8032
mapred-site.xml
#在yarn上运行mapreduce任务
mapreduce.framework.name
yarn
workers
#hadoop的worker,位于/usr/local/hadoop/etc/hadoop下
#数据节点IP地址,后面会创建
172.20.0.5
172.20.0.6
172.20.0.7
172.20.0.8spark-env.sh
#告诉HADOOP_CONF_DIR,spark会自己了解hadoop的环境配置,比如hdfs开放端口在哪
#
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/nativeworkers
#spark的worker,位于/usr/local/spark/conf下
#节点的IP地址,后面会创建
172.20.0.5
172.20.0.6
172.20.0.7
172.20.0.8运行结果
#格式化运行结果
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at 355a1f302b29/172.20.0.5
************************************************************/
#echo $JAVA_HOME
/usr/lib/jvm/java-8-openjdk-amd64保存镜像
##ubuntu
docker commit master spark_images:v1创建工作节点,构建分布式hadoop和spark
代码
##ubuntu
docker run -itd --name worker1 --net hadoopnet --ip 172.20.0.6 -v /bigdata:/bigdata spark_images:v1 /bin/bash
docker run -itd --name worker2 --net hadoopnet --ip 172.20.0.7 -v /bigdata:/bigdata spark_images:v1 /bin/bash
docker run -itd --name worker3 --net hadoopnet --ip 172.20.0.8 -v /bigdata:/bigdata spark_images:v1 /bin/bash#在每一个容器里都开启ssh,然后都互联一次,例如worker1,互联前要确保每个节点都开启了ssh
service ssh start
ssh 172.20.0.5
ssh 172.20.0.7
ssh 172.20.0.8
#全部互联完后,回到master节点,开启hadoop,spark,mysql
#然后回到ubuntu,用浏览器登录localhost:9870,localhost:8080,查看hdfs,spark是否可以访问
service mysql start
cd /usr/local/hadoop
./sbin/start-all.sh
cd /usr/local/spark
./sbin/start-all.sh
jps
#运行示例1
cd /usr/local/hadoop
cp ./etc/hadoop/core-site.xml input
./bin/hdfs dfs -mkdir -p /user/root
./bin/hdfs dfs -put ./input .
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount input output
#运行示例2
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 1g \
--executor-cores 2 \
examples/jars/spark-examples*.jar \
10运行结果
#jps
2628 Jps
2118 NodeManager
2008 ResourceManager
2570 Worker
1772 SecondaryNameNode
1484 NameNode
2494 Master
1599 DataNode
#示例1运行结果
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1068
File Output Format Counters
Bytes Written=1039
#示例2运行结果
client token: N/A
diagnostics: N/A
ApplicationMaster host: 0a69e22f207a
ApplicationMaster RPC port: 41551
queue: default
start time: 1679407401940
final status: SUCCEEDED
tracking URL: http://355a1f302b29:8088/proxy/application_1679405990349_0003/
user: root
23/03/21 14:03:46 INFO ShutdownHookManager: Shutdown hook called
23/03/21 14:03:46 INFO ShutdownHookManager: Deleting directory /tmp/spark-1f53cd0a-1ecb-467c-a59c-c84bd2a1196b
23/03/21 14:03:46 INFO ShutdownHookManager: Deleting directory /tmp/spark-891d26da-45b7-40c5-8e64-a3d2d96b132c三,分析淘宝数据
上传数据挂载目录,之后上传到hdfs
##ubuntu
cd ~
sudo mv taobao_user_behavior_cut.csv /bigdatacd /usr/local/hadoop
./bin/hdfs dfs -mkdir taobao
./bin/hdfs dfs -put /bigdata/taobao_user_behavior_cut.csv taobao2.数据分析
读取与展示数据
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark import SparkContext,StorageLevel
spark = SparkSession.builder.getOrCreate()
raw_data = spark.read.csv("/user/root/taobao/taobao_user_behavior_cut.csv",header=True)
raw_data.show(20)#将上面的代码写进py文件
cd /bigdata
vim spark_taobao.py
python3 spark_taobao.py
在yarn上处理数据并保存到mysql
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark import SparkContext,StorageLevel
import pandas as pd
#读取数据
spark = SparkSession.builder.getOrCreate()
raw_data = spark.read.csv("/user/root/taobao/taobao_user_behavior_cut.csv",header=True)
#删除空缺列,无效列,转化时间,行为,持久化数据
def tran(x):
tmp = x["time"].split(" ")
day = tmp[0]
hour = tmp[1]
user_id = x["user_id"]
if int(x["behavior_type"]) ==1 :
behavior = "点击详情页"
elif int(x["behavior_type"]) == 2:
behavior = "收藏"
elif int(x["behavior_type"]) == 3:
behavior = "加入购物车"
else:
behavior = "购买"
item_id = x["item_id"]
item_category = x["item_category"]
return user_id,item_id,behavior,item_category,day,hour
raw_df = raw_data.drop("user_geohash","_c0").rdd.map(tran).toDF(schema="user_id string,item_id string,behavior string,item_category string,day string,hour string")
raw_df.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)
#计算用户最后一次点击与第一次点击时间的间隔,为了计算留存率,并统计用户购买路径,主要是返回购买前的动作
def countRetention(key,x):
data = x["day"].values
id = str(x["user_id"].values[0])
behavior_values = x["behavior"].values
behavior_index = len(behavior_values)
buy_path = "没有购买"
first_time = [int(data[0].split("-")[1]), int(data[0].split("-")[2])]
laste_time = [int(data[-1].split("-")[1]), int(data[-1].split("-")[2])]
if first_time[0] ==11:
first_time[1] = first_time[1] - 18
else:
first_time[1] = 12 + first_time[1]
if laste_time[0] == 11:
laste_time[1] = laste_time[1] - 18
else:
laste_time[1] = 12 + laste_time[1]
interval_time = laste_time[1]-first_time[1]
for index in range(behavior_index):
if behavior_values[index] == "购买":
buy_path = behavior_values[index-1]
return pd.DataFrame([[id, interval_time, buy_path]])
user_retention_data = raw_df.groupBy("user_id").applyInPandas(countRetention,schema="user_id string,retention_date int,buy_path string")
#统计日均流量,月均流量
date_flow = raw_df.groupBy("hour").count()
month_flow = raw_df.groupBy("day").count()
#统计每个商品种类的点击量,购买量
def countClike(key,x):
behavior = x["behavior"].values
id = x["item_category"].values[0]
clike_num = 0
buy_num = 0
for i in behavior:
if i == "购买":
buy_num += 1
clike_num += 1
return pd.DataFrame([[id,clike_num,buy_num]])
click_data = raw_df.select("behavior","item_category").groupBy("item_category").applyInPandas(countClike,schema="item_category string, clike_num int, buy_num int")
#将数据储存进mysql
properties={
"user" : "root",
"password" : "mysql123",
"dirver" : "com.mysql.cj.jdbc.Driver"
}
raw_df.write.jdbc("jdbc:mysql://localhost:3306/taobao_data", table="raw_df", mode="overwrite",properties=properties )
user_retention_data.write.jdbc("jdbc:MySQL://localhost:3306/taobao_data", table="user_retention_data", mode='overwrite',properties=properties )
date_flow.write.jdbc("jdbc:MySQL://localhost:3306/taobao_data", table="date_flow", mode='overwrite',properties=properties )
month_flow.write.jdbc("jdbc:MySQL://localhost:3306/taobao_data", table="month_flow", mode='overwrite',properties=properties )
click_data.write.jdbc("jdbc:MySQL://localhost:3306/taobao_data", table="click_data", mode='overwrite',properties=properties )
#进入mysql,创建数据库taobao_data
mysql -u root -p
create database taobao_data
exit
#打包程序所需依赖包,pyspark等
cp -r /usr/local/lib/python3.10/dist-packages /bigdata
zip spark_taobao.zip dist-packages
#编辑py文件,将上面的python代码写入
vim spark_taobao.py
#上传py文件,在yarn中运行
#要注意executor的内存加起来不能超过实际虚拟机资源,否则yarn会杀掉这个executor
cd /usr/local/spark
./bin/spark-submit /
--master yarn /
--deploy-mode cluster /
--driver-memory 2g /
--executor-memory 1g /
--executor-cores 1 /
--num-executors 1 /
--py-files='/bigdata/spark_taobao.zip' /
/bigdata/spark_taobao.py
读取mysql数据,分析数据
from pyspark.sql import SparkSession
from pyspark import SparkContext,StorageLevel
from pyspark.sql.functions import *
import pandas
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'simhei'
spark = SparkSession.builder.getOrCreate()
#从mysql上读取数据
url = "jdbc:mysql://localhost:3306/taobao_data"
propertie = {
"user" : "root",
"password": "mysql123",
"dirver" : "com.mysql.cj.jdbc.Driver"
}
user_retention_data = spark.read.jdbc(url=url, table="user_retention_data", properties=propertie)
date_flow = spark.read.jdbc(url=url, table="date_flow", properties=propertie)
month_flow = spark.read.jdbc(url=url, table="month_flow", properties=propertie)
click_data = spark.read.jdbc(url=url, table="click_data", properties=propertie)
#统计7日留存率, 14日留存率, 28日留存率
all_user_num = user_retention_data.count()
seven_retention = user_retention_data.filter(user_retention_data.retention_date >= 7).count()/all_user_num
fourteen_retention = user_retention_data.filter(user_retention_data.retention_date >= 14).count()/all_user_num
te_retention = user_retention_data.filter(user_retention_data.retention_date >= 28).count()/all_user_num
retention_y = [seven_retention, fourteen_retention, te_retention]
retention_x = ["7日留存率", "14日留存率", "28日留存率"]
plt.plot(retention_x, retention_y, color='r', linewidth=2, linestyle='dashdot' )
for x in range(3):
plt.text(x-0.13,retention_y[x],str(retention_y[x]),ha='center', va= 'bottom',fontsize=9)
plt.savefig("retention.jpg")
plt.clf()
#统计日均流量
date_flow = date_flow.sort("hour").toPandas()
date_flow_x = date_flow["hour"].values
date_flow_y = date_flow["count"].values
plt.figure(figsize=(8,4))
plt.plot(date_flow_x, date_flow_y,color='r', linewidth=2, linestyle='dashdot')
for x in range(24):
plt.text(x-0.13,date_flow_y[x],str(date_flow_y[x]),ha='center', va= 'bottom',fontsize=9)
plt.savefig("date_flow.jpg")
plt.clf()
#统计月均流量
month_flow = month_flow.sort("day").toPandas()
month_flow_x = month_flow["day"].values
month_flow_y = month_flow["count"].values
plt.figure(figsize=(15,4))
plt.xticks(rotation=90)
plt.plot(month_flow_x, month_flow_y,color='r', linewidth=2, linestyle='dashdot')
plt.savefig("month_flow.jpg",bbox_inches='tight')
plt.clf()
#统计top10的商品
def take(x):
data_list = []
for i in range(10):
data_list.append(x[i])
return data_list
visit_data = click_data.sort(desc("clike_num")).toPandas()
visit_x = take(visit_data["item_category"].values)
visit_y = take(visit_data["clike_num"].values)
visit_plt = plt.bar(visit_x, visit_y, lw=0.5,fc="b",width=0.5)
plt.bar_label(visit_plt, label_type='edge')
plt.savefig("visit_top10.jpg",bbox_inches='tight')
plt.clf()
buy_data = click_data.sort(desc("buy_num")).toPandas()
buy_x = take(buy_data["item_category"].values)
buy_y = take(buy_data["buy_num"].values)
buy_plt = plt.bar(buy_x, buy_y, lw=0.5,fc="b",width=0.5)
plt.bar_label(buy_plt, label_type='edge')
plt.savefig("buy_top10.jpg",bbox_inches='tight')
plt.clf()
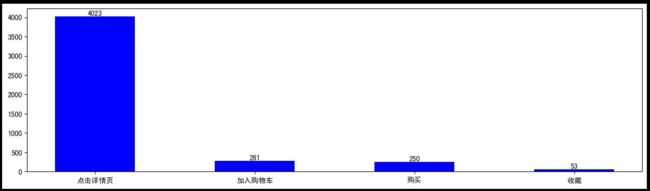
#统计购买路径
buy_path_data = user_retention_data.filter(user_retention_data.buy_path != "没有购买").groupBy("buy_path").count().sort(desc("count")).toPandas()
buy_path_y = buy_path_data["count"].values
buy_path_x= buy_path_data["buy_path"].values
buy_path_plt = plt.bar(buy_path_x, buy_path_y, lw=0.5,fc="b",width=0.5)
plt.bar_label(buy_path_plt, label_type='edge')
plt.savefig("buy_path.jpg",bbox_inches='tight')
#编辑运行py文件,将上面的python代码写入,图片会保存在本目录中
cd /bigdata
vim taobao_analy.py
python3 taobao_analy.py运行结果
日均流量,可以看出每晚的21-22点访问人数最多
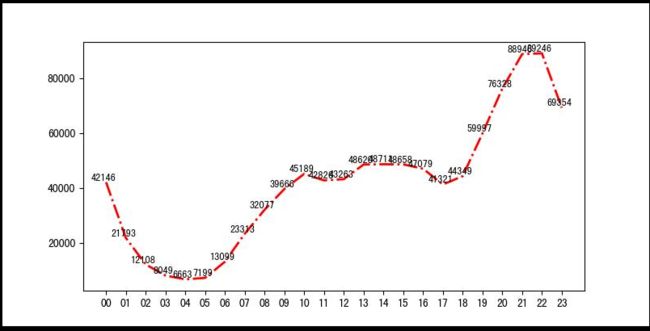
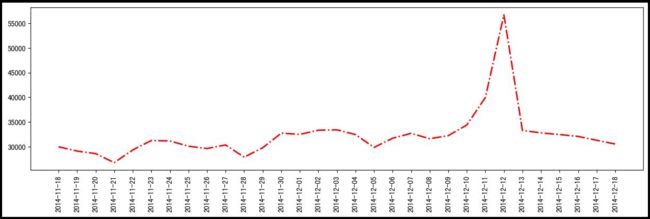
月均流量,在12月12日的时候,人数陡然增加,说明促销活动是有效的
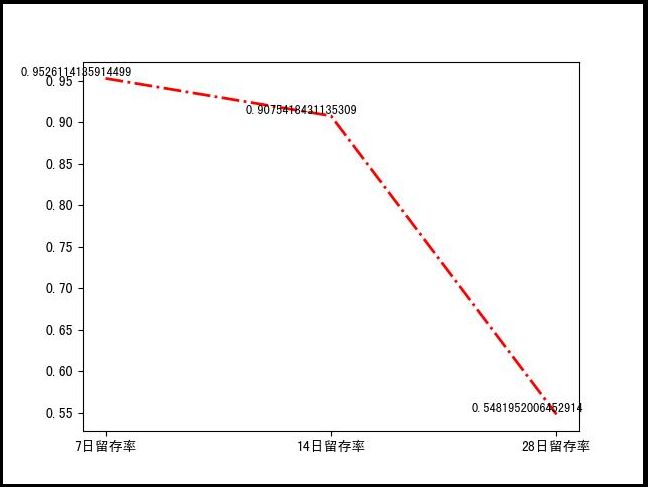
留存率,7日留存率与14日留存率差别不大,但是在28日时陡然下降,可以考虑在这一个周期里做些活动
访问top10的商品种类

购买量top10的商品
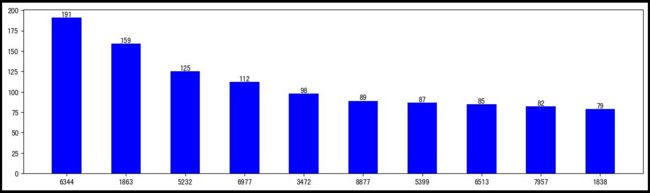
用户购买途径,大多数用户都喜欢通过点击详情页进行购买,所以一个好的详情页对于一个商品的销量有着重要影响
四,其他
关于matplotlib中文字体显示问题请参考
findfont: Font family [‘sans-serif‘] not found解决方法_fontfamily[sa_ACE-Mayer的博客-CSDN博客