VQGAN:从图像重建到图像生成
本文的目标是作为全新图像生成系统的VQGAN。我已经开始讨论VQGAN的一部分——自编码器(VQVAE:矢量量化变分自动编码器)。VQVAE的概念是对编码器、解码器和码书的同时训练,该码书适用于所有可能的图像。码书是一组256个嵌入向量。具有输入分辨率256x256的任何图像的潜在空间由码书向量的某个子集表示。下面的图片底部显示了VQVAE管道的插图:
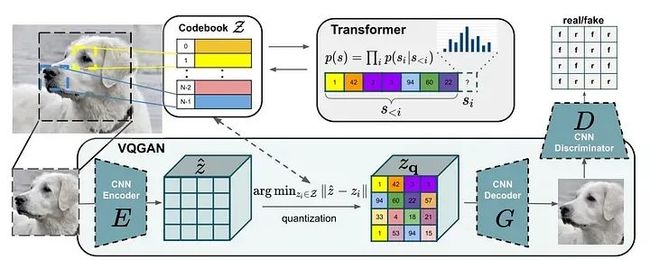
编码器将输入图像(256x256像素分辨率)转换为具有16x16条目的潜在空间,每个条目是一个具有256个值的向量(在图1的图表中,潜在空间显示为4x4条目的平面)。然后,潜在空间中的每个条目都更改为来自码书的L2度量最近的向量 —— 这个过程称为矢量量化。因此,潜在空间由16x16的码书索引平面表示。将这个量化的潜在空间发送到解码器,我们得到重建图像。
在VQGAN中,自编码器部分通过一个额外的CNN——基于块的判别器(见图)扩展。判别器具有分类器结构。在图片中显示了VQVAE和判别器之间的交互:重建图像后,它被发送到判别器,判别器为图像块生成类别值。判别器为输入图像和重建图像获得“每个块的类别”空间,并在每个块上验证这些空间之间的类别差异:相同类别(真实)或不同类别(伪造)。判别器参与VQGAN的训练,并试图最大化其损失,但共同的损失 = VQVAE损失 + 判别器损失被最小化。关于VQGAN损失组成的良好解释在这里。在训练步骤中,当训练好的模型进行图像重建时,不使用判别器,它用于改进VQVAE在训练步骤中的质量。判别器在GAN训练的下一步中发挥着重要作用,用于生成新图像。
潜在空间的实际实验
在本节中,我在实践中演示了使用VQGAN进行图像重建,并对潜在空间、码书及其在生成新图像中的作用进行了实验。在这里,我在我的Google Colab中使用以下代码。导入:
import copy
import cv2
import sys
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import numpy as npGoogle Drive映射:
from google.colab import drive
drive.mount('/content/gdrive')Cuda设备设置:
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')VQGAN的安装和模型下载:
%pip install omegaconf>=2.0.0 pytorch-lightning>=1.0.8 einops>=0.3.0
sys.path.append(".")
!git clone https://github.com/CompVis/taming-transformers
%cd taming-transformers
# download a VQGAN with f=16 (16x compression per spatial dimension) and with a codebook with 1024 entries
!mkdir -p logs/vqgan_imagenet_f16_1024/checkpoints
!mkdir -p logs/vqgan_imagenet_f16_1024/configs
!wget 'https://heibox.uni-heidelberg.de/f/140747ba53464f49b476/?dl=1' -O 'logs/vqgan_imagenet_f16_1024/checkpoints/last.ckpt'
!wget 'https://heibox.uni-heidelberg.de/f/6ecf2af6c658432c8298/?dl=1' -O 'logs/vqgan_imagenet_f16_1024/configs/model.yaml'# also disable grad to save memory
torch.set_grad_enabled(False)上面的代码安装了具有代码簿条目数=1024的最小模型。两个用于从文件读取图像并转换为torch张量的实用函数,以及用于显示输入和输出图像的函数:
def get_img_tensor(name,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((256, 256)),
])):
img = Image.open(name)
img = transform(img)
img = img.unsqueeze(0)
return img
def show_results(img, out):
rec = custom_to_pil(out[0])
_, ax = plt.subplots(1, 2, figsize=(12, 5))
if img is not None:
ax[0].imshow(img[0].permute(1, 2, 0))
ax[0].axis("off")
ax[1].imshow(rec)
ax[1].axis("off")
plt.show()下面的代码包含了使用VQGAN进行图像重建的函数:
from omegaconf import OmegaConf
from taming.models.vqgan import VQModel
def load_config(config_path):
config = OmegaConf.load(config_path)
return config
def load_vqgan(config, ckpt_path=None):
model = VQModel(**config.model.params)
if ckpt_path is not None:
sd = torch.load(ckpt_path, map_location="cpu")["state_dict"]
missing, unexpected = model.load_state_dict(sd, strict=False)
return model.eval()
def preprocess_vqgan(x):
x = 2.*x - 1.
return x
def custom_to_pil(x):
x = x.detach().cpu()
x = torch.clamp(x, -1., 1.)
x = (x + 1.)/2.
x = x.permute(1, 2, 0).numpy()
x = (255*x).astype(np.uint8)
x = Image.fromarray(x)
if not x.mode == "RGB":
x = x.convert("RGB")
return x
def reconstruct_with_vqgan(x, model):
# could also use model(x) for reconstruction but use explicit encoding and decoding here
z, _, [_, _, indices] = model.encode(x)
print(f"VQGAN --- {model.__class__.__name__}: latent shape: {z.shape[2:]}")
xrec = model.decode(z)
return xrecload_config()、load_vqgan() — 用于加载预训练模型的函数。
preprocess_vqgan() — 用于将输入图像张量发送到VQGAN编码器之前进行预处理的函数。
custom_to_pil() — 用于VQGAN解码器之后对重建图像张量进行后处理的函数。
reconstruct_with_vqgan() — 用于图像重建的函数:它调用编码器,获取图像潜在空间,然后调用解码器以获取重建的图像。
现在一切都准备好进行重建。加载预训练模型:
config1024 = load_config("logs/vqgan_imagenet_f16_1024/configs/model.yaml")
model1024 = load_vqgan(config1024, ckpt_path="logs/vqgan_imagenet_f16_1024/checkpoints/last.ckpt").to(device)并使用该模型进行图像重建:
img = get_img_tensor("image path")
out = reconstruct_with_vqgan(preprocess_vqgan(img.to(device)), model1024)
show_results(img, out)图像重建结果的示例:

reconstruct_with_vqgan()依次调用编码器和解码器。让我们看看这些函数:
z, _, [_, _, indices] = model1024.encode(preprocess_vqgan(img.to(device)))
indices = indices.detach().cpu().numpy()预训练的编码器模型返回形状为(1, 256, 16, 16)的潜在空间z,以及形状为(256)的代码簿向量索引。如果将这些具有索引的代码簿向量按照16x16平面的栅格顺序放置,它们组成了潜在空间。换句话说,如果我有256个适当顺序的索引,我就能够从代码簿创建潜在空间,并调用解码器重建图像。在下面的代码中,我尝试了这个过程。首先,获取代码簿向量:
ind = torch.arange(1024).to(device)
cb = model1024.quantize.get_codebook_entry(ind, None)
print(cb.shape)上面的代码中,我从代码簿中获取了索引0,...,1023的向量,即整个代码簿(我使用了小的VQGAN模型)。代码簿的形状为(1024, 256)。下面的函数展示了如何从代码簿和256个索引的numpy数组创建潜在空间,并使用解码器获取输出图像:
def cb_construct(cb, indices, img):
emb = [cb[i] for i in indices]
zn = torch.stack(emb)
zn = torch.reshape(zn, (16, 16, 256))
zn = torch.unsqueeze(zn, 0)
zn = zn.permute(0, 3, 1, 2)
xrec = model1024.decode(zn.to(device))
show_results(img, xrec)如果我们使用前面代码块中获得的`cb`和`indices`调用这个函数:
cb_construct(cb, indices, img)我们会得到与图2中完全相同的重建结果。如果我们尝试打乱这些索引并使用打乱的向量解码潜在空间:
indices1 = copy.deepcopy(indices)
np.random.shuffle(indices1)
cb_construct(cb, indices1, img)我们会得到一张新的带有一些抽象的图像。

其他一些基于来自其他图片的潜在空间的“抽象艺术”的示例:



因此,我们通过实验尝试了对于创建任何图像,我们都需要代码簿、以定义顺序的代码簿向量的集合和解码器。直观地说,我们需要一些系统,它能够定义代码簿向量的子集和其索引的顺序,以生成某种类型的逼真图像。
注意:高分辨率图像的潜在空间是由该图像由256x256补丁组成的潜在空间的连接。
Taming Transformer
Taming Transformer模型是图像生成器的第二阶段。它经过训练,可以生成新图像潜在空间的索引序列。生成从初始条件处理开始。以下是该模型处理的条件图像类型:

<输入类型+输入代码>作为初始参数发送到模型。输入代码意味着条件图像潜在空间的代码簿向量集合。该模型经过训练,以使用先前预测的索引来预测当前索引。第一个索引是基于输入代码预测的。变压器预测可能的下一个索引的分布(图1)。如果输入图像分辨率为256x256,则使用先前预测的所有索引来预测当前索引。对于高分辨率图像,每个补丁仅使用滑动窗口中相邻补丁的先前预测的索引来进行预测,如下图所示:

Taming Transformer使用第一阶段训练的VQGAN和鉴别器模型作为骨干。训练步骤如下:预测整个补丁的代码簿索引分布,将预测的索引发送到解码器并获取输出补丁,将输出补丁发送到鉴别器并获取补丁特征,然后计算输入特征(从输入代码获得)和输出特征之间的交叉熵损失。
我使用这个Google Colab进行实验,从分割掩模生成新图像。我使用了Colab中提供的输入数据。以下是对于相同分割掩模的3次不同运行的结果:

分割掩模可能包含高达182个对象类别(掩模值从1到182)。
关于Taming Transformer + VQGAN系统的结论:
1. 该系统能够使用基于条件图像的输入配置生成高质量逼真图像。
2. 该系统可以用于图像扩展:例如,可以将条件图像作为顶部图像部分发送到系统中,输出图像将包含这个顶部部分 + 生成的底部部分。
3. 根据输入类型,需要对条件图像进行特殊的预处理,例如适当配置分割掩模。
4. 该系统用于生成与条件图像相似的新图像,但不能用于更改条件图像的风格。
CLIP + VQGAN系统用于新图像生成
首先,我继续使用第2节中的代码。在下面的代码中,我更改编码后的图像潜在空间 —— 将其乘以0.7:
img = get_img_tensor("image path")
z, _, [_, _, indices] = model1024.encode(preprocess_vqgan(img.to(device)))
out = model1024.decode(0.7 * z)
show_results(img, out)结果是,我得到了另一种风格的冬季风景。

我可以以另一种方式改变潜在空间,例如,将潜在空间的每个向量的第70个元素乘以50:
ind = 70
z, _, [_, _, indices] = model1024.encode(img.to(device))
z = z.permute(1, 0, 2, 3)
z = [z[i] for i in range(256)]
z[ind] = z[ind] * 50
z = torch.stack(z)
z = z.permute(1, 0, 2, 3)
out = model1024.decode(z)
show_results(img, out)风景风格以另一种方式改变:

在这两个实验中,我“忘记”了代码簿索引,整体改变了潜在空间。
CLIP + VQGAN系统的思想类似:通过整体改变潜在空间来以期望的方式改变图像。CLIP充当鉴别器的角色,它理解期望图像的文本描述并产生损失值。CLIP是一个经过训练的系统,用于查找图像与文本之间的相似性。
生成过程类似于通过改变潜在空间权重进行训练:CLIP产生文本描述的嵌入向量,VQGAN解码潜在空间并获取图像,然后CLIP产生图像的嵌入向量,CLIP + VQGAN系统计算其与输入文本描述的嵌入向量的余弦相似度。该系统的目标是最大化相似性(相似性在区间(0,1)内)。为了实现这个目标,系统在反向传播步骤中改变潜在空间中的权重。主要挑战是在反向传播期间传递梯度的技巧,因为VQGAN和CLIP并不是系统的骨干,只是加载的预训练模型。我尝试了来自这个Google Colab的CLIP + VQGAN实现。我根据输入文本描述更改了输入图像,以在图像中获得视频效果。下面的图片显示了一些结果:
文本提示:“积雪覆盖的云杉”。
图像变换:

文本提示:“积雪覆盖的冷杉枝和松果”。
图像变换:

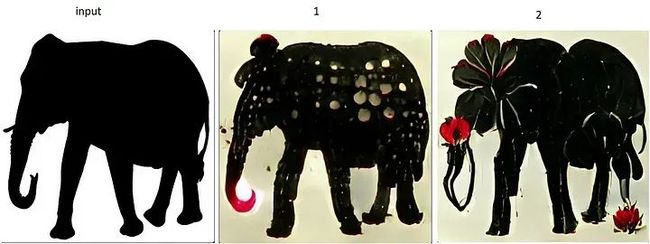
文本提示1:“黑色大象轮廓上的白色和红色点”。
文本提示2:“黑色大象轮廓上的白色和红色花朵”。
图像变换:
以及从噪音生成的新年艺术的示例:
文本提示:“新年云杉水彩细节”。

关于CLIP + VQGAN系统的结论:
与Taming Transformer + VQGAN系统相反,CLIP + VQGAN系统更适用于艺术而不是逼真图像生成。它能够以不同风格生成图像,接受用户以最方便的形式输入,即以文本描述的形式。
结论
我之前(关于自动编码器)和现在的帖子的目标是逐步追踪VQGAN的新图像生成概念的发展:
用于图像压缩的自动编码器 -> 相对较小的图像潜在空间,特定数据集的图像重建。
向量量化自动编码器 -> 基于代码簿和向量量化技术的图像潜在空间,任何图像的高质量图像重建。
Taming Transformers + VQGAN -> 根据矢量指数预测生成的代码簿向量的新图像。
CLIP + VQGAN -> 根据文本描述改变图像潜在空间的新图像生成。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除