速通——决策树(泰坦尼克号乘客生存预测案例)
一、决策树
1、概述
树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果
2、建立过程
1. 特征选择:选取有较强分类能力的特征。
2. 决策树生成:根据选择的特征生成决策树。
3. 决策树也易过拟合,采用剪枝的方法缓解过拟合
二、信息熵
1、概述:描述信息的 完整性 和 有序性
2、熵(Entropy)
信息论中代表 随机变量 不确定度的度量;熵越大,数据的不确定性越高,信息就越多;熵越小,数据的不确定性越低
3、计算方法:
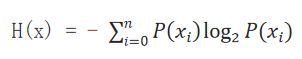
P(xi) :数据中类别出现的概率
H(x) :信息的信息熵值
三、信息增益
1、概述
由于特征A而使得对数据D的 分类不确定性 减少的程度,特征 a 对训练数据集D的 信息增益 g(D,a),定义为集合D的熵 H(D) 与特征a给定条件下D的熵 H(D|a)之差(信息增益 = 熵 - 条件熵)
2、数学公式
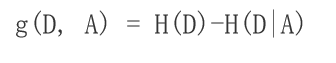
3、条件熵

四、决策树分类
1、ID3 决策树
构建流程:
1、计算每个特征的信息增益
2、使用信息增益最大的特征将数据集 拆分为子集
3、使用该特征(信息增益最大的特征)作为决策树的一个节点
4、使用剩余特征对子集重复上述(1,2,3)过程
特点:倾向于选择取值较多的属性(不足),只能对离散属性的数据集构成决策树
2、C4.5 决策树
概述:信息增益率大的做为分裂特征,是在信息增益的基础上除以当前特征的固有值,可以衡量属性对分类的贡献
计算方法: 信息增益率 = 信息增益 / 特征熵
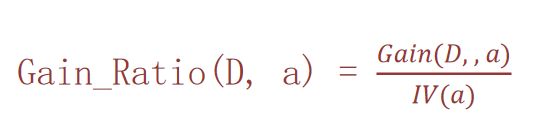
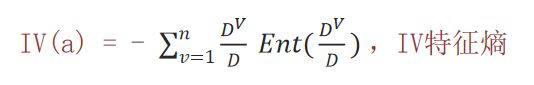
本质:相当于对信息增益进行修正,增加一个惩罚系数;特征取值个数较多时,惩罚系数较小;特征取值个数较少时,惩罚系数较大。
惩罚系数:数据集D 以 特征a 作为随机变量的熵的倒数
特点:1. 缓解了ID3分支过程中总喜欢偏向选择值较多的属性;
2. 可处理连续数值型属性,也增加了对缺失值的处理方法;
3. 只适合于能够驻留于内存的数据集,大数据集无能为力
3、CART决策树(Classification and Regression Tree)
概述:是一种决策树模型,既可以用于分类,也可以用于回归。Cart回归树 使用平方误差 最小化策略,Cart分类生成树 采用的基尼指数 最小化策略。
特点:1. 可以进行分类和回归,可处理离散属性,也可以处理连续属性
2. 采用基尼指数,计算量减小
3. 一定是二叉树
CART分类树
基尼值 Gini(D):从数据集D中随机抽取两个样本,其类别标记不一致的概率。故,Gini(D)值越小,数据集D的纯度越高。
计算方法:Gini(D)= 1 - 特征分类1^2 - 特征分类2^2

基尼指数 Gini_index(D):选择使划分后基尼系数最小的属性作为最优 化分属性。

Tips:特征的信息增益(ID3)、信息增益率值越大(C4.5),优先选择该特征。基尼指数值越小(cart),优先选择该特征。
API
导包:from sklearn.tree import DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier (criterion = 'gini ', max_depth = None,random_state = None)
# 导包
from sklearn.tree import DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier (criterion = 'gini ', max_depth = None, random_state = None)Criterion: 特征选择标准,"gini" 或 "entropy",前者代表基尼系数,后者代表信息增益。默认"gini",即CART算法
min_samples_split:内部节点再划分所需最小样本数,默认为 2
min_samples_leaf:叶子节点最少样本数,默认为 1
max_depth:决策树最大深度
CART回归树
可以处理 非线性关系
平方损失:(值 - 均值)^2
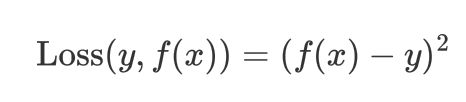
构建过程
1、选择一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
2、根据所有划分点,将数据集分成两部分:R1、R2
3、R1 和 R2 两部分的平方损失相加作为该切分点平方损失
4、取最小的平方损失的划分点,作为当前特征的划分点
5、以此计算其他特征的最优划分点、以及该划分点对应的损失值
6、在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
CART回归树 与 CART分类树 的不同
1、CART 分类树预测输出的是一个离散值,CART 回归树预测输出的是一个连续值;
2、CART 分类树使用基尼指数作为划分、构建树的依据,CART 回归树使用平方损失;
3、分类树使用叶子节点多数类别作为预测类别,回归树则采用叶子节点里均值作为预测输出
五、决策树剪枝(正则化)
概述:是一种防止决策树过拟合的一种正则化方法,提高其泛化能力;即把子树的节点全部删掉,使用叶子节点来替换
剪枝方法:
1、预剪枝:指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点
优点:预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著减少了决策树的训练、测试时间开销;
缺点:有些分支的当前划分虽不能提升泛化性能,但后续划分却有可能导致性能的显著提高,预剪枝决策树也带来了欠拟合的风险。
2、后剪枝:是先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点。
优点:后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝
缺点:训练时间开销 比 未剪枝的决策树 和 预剪枝的决策树都要大得多
六、案例——泰坦尼克号乘客生存预测
数据情况:数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆,home.dest,房间和性别等,乘坐班次是(1,2,3),是社会经济阶层的代表,age数据存在缺失。
1、导包
import pandas as pd
# 数据划分
from sklearn.model_selection import train_test_split
# 决策树
from sklearn.tree import DecisionTreeClassifier
# 分类算法
from sklearn.metrics import classification_report
# 可视化
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree2、导入数据
titanic_df = pd.read_csv('titanic/train.csv')
# Pclass 船舱等级 Sibsp 同行兄弟姐妹人数 Parch 同行的父母孩子的人数
# Ticket 票号
# Fare 花了多少钱
# Cabin 船舱编号
# Embarked 登船的港口名称
titanic_df3、数据处理
# 总计空值数量
titanic_df.isnull().sum()
# 年龄进行缺失值填充
X['Age'].fillna(X['Age'].mean(),inplace = True)
# 性别编码
X = pd.get_dummies(X)4、数据划分、训练、使用、评估模型
# 划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,stratify=y,random_state=66)
# 设置决策树模型
estimator = DecisionTreeClassifier(max_depth=6)
# 训练模型
estimator.fit(X_train,y_train)
# 模型预测
y_pred = estimator.predict(X_test)
# 评估模型
print('训练集',estimator.score(X_train, y_train))
print('测试集',estimator.score(X_test, y_test))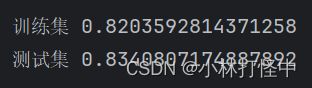
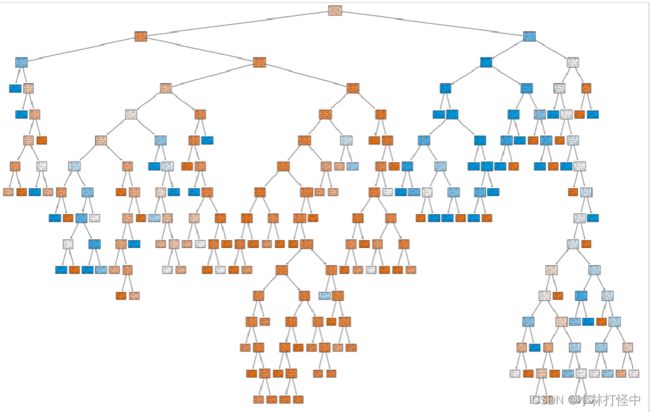
5、可视化
plt.figure(figsize=(30,20))
plot_tree(estimator,
max_depth=6, # max_depth 绘制的最大深度
filled=True, # filled = True 填充每个节点的背景颜色
feature_names=X.columns, # feature_names 特征名字 每个节点中显示的特征名字
class_names=['died', 'survived']) # class_names 目标值名字 每个节点中显示的目标值名字
plt.show()