带着问题学LLM
常用模型大小对比
chatglm-6b
model = AutoModel.from_pretrained(model_path,trust_remote_code=True, device_map='auto',load_in_8bit=True,torch_dtype=torch.float16)
bin文件13.4g
模型加载时有load_in_8bit和torch_dtype两个参数
原始模型加载,显存占用12.6g, 参数格式fp32与fp16都有(ln层是32,其余16)
load_in_8bit=True时,显存占用7.5g,参数格式int8与fp16都有(ln层是16,其余层weight是8,bias是16)
torch_dtype=torch.float16,显存占用12.6g,参数格式fp16
两个参数一起设置时,显存占用7.5g,参数格式int8与fp16都有(ln层是16,其余层weight是8,bias是16)
也就是说8bit加载时,后面的混合精度不起作用。
moss-13b
实际参数量是16B
model = AutoModelForCausalLM.from_pretrained(model_path,trust_remote_code=True,device_map="auto",torch_dtype=torch.float16,load_in_8bit=True)
bin文件33.5g
与chatglm不同,torch_dtype参数是起作用的。
原始模型加载:显存占用63g,参数格式fp32
torch_dtype=torch.float16,显存占用32.5g, 参数格式fp16
load_in_8bit=True,显存占用18.5g,参数格式int8与fp16都有(ln层是16,其余层weight是8,bias是16)
两个参数一起设置时,显存占用18.5g,参数格式int8与fp16都有(ln层是16,其余层weight是8,bias是16)
也就是说8bit加载时,后面的混合精度不起作用。
结论:MOSS保存的是单精度,GLM保存的是混合精度fp16
混合精度与量化
精度
1字节(byte)= 8bit
单精度float32占用4字节,32表示bit,其中符号位1,指数位8,尾数位23
半精度float16(fp16)占用2字节,其中符号位1,指数位5,尾数位10
半精度bf16占用2字节,其中符号位1,指数位8,尾数位7,解决上溢问题,但是精度比fp16低
混合精度
混合精度:在训练过程中,前向和后向计算使用fp16/bf16,提高训练速度,只在主权重更新时,用fp32保存主权重
在推理阶段,使用bf16/fp16,内存减半
float32→float16属于直接截断的操作
量化
有时候fp16都无法满足推理显存要求,可以使用8bit(int8)量化,显存再减半
float16→int8的量化主要有2种方式:零点量化,最大缩放
# 最大缩放
import torch
a = torch.Tensor([2.1, 3.1, 2.5, 3.7, 3.3])
alpha = 127/max(a)
b = a * alpha
c = torch.round(b,decimals=0)
d = c / alpha
print("原始tensor:",a)
print("缩放系数:",alpha)
print("缩放后:",b)
print("取整:",c)
print("还原:",d)
原始tensor: tensor([2.1000, 3.1000, 2.5000, 3.7000, 3.3000])
缩放系数: tensor(34.3243)
缩放后: tensor([ 72.0811, 106.4054, 85.8108, 127.0000, 113.2703])
取整: tensor([ 72., 106., 86., 127., 113.])
还原: tensor([2.0976, 3.0882, 2.5055, 3.7000, 3.2921])
# 零点量化
import torch
a = torch.Tensor([2.1, 3.1, 2.5, 3.7, 3.3])
b = a * 127
c = torch.round(b,decimals=0)
d = c / 127
print("原始tensor:",a)
print("缩放后:",b)
print("取整:",c)
print("还原:",d)
原始tensor: tensor([2.1000, 3.1000, 2.5000, 3.7000, 3.3000])
缩放后: tensor([266.7000, 393.7000, 317.5000, 469.9000, 419.1000])
取整: tensor([267., 394., 318., 470., 419.])
还原: tensor([2.1024, 3.1024, 2.5039, 3.7008, 3.2992])
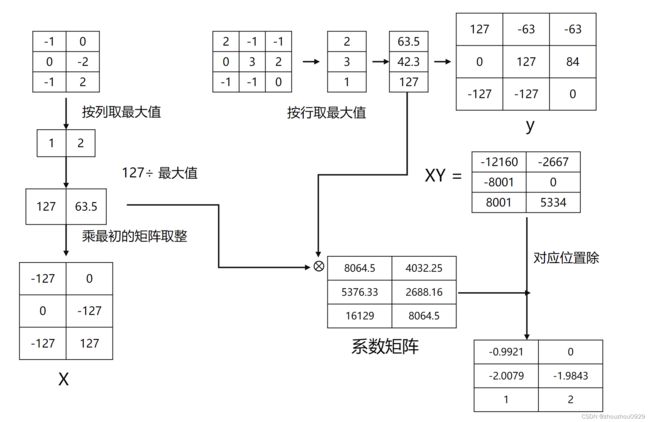
LLM.int8 大语言模型的零退化矩阵乘法
1.参数中的离群值对量化影响大,将离群值单独拎出用fp16计算(下图黄色部分)
2.非离群值采用int8计算(下图蓝色部分)
3.两个结果相加
上图蓝色部分计算过程如下
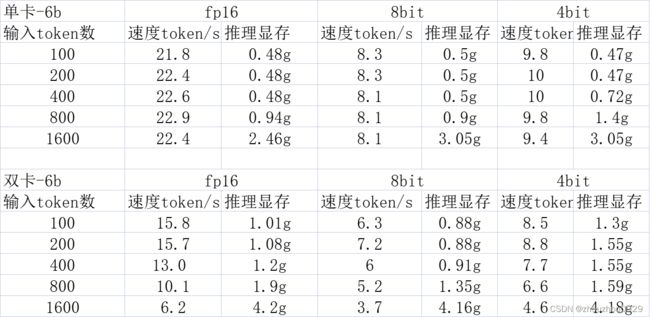
推理显存与速度对比
使用1/2张特斯拉A-100推理,结论:
1.单卡速度比双卡快(这里测试的是模型并行的加载方式)
2.量化会使推理速度变慢,fp16>4bit>8bit
3.单卡推理速度和输入token长度无关,双卡推理输入越长推理越慢
4.量化对推理显存影响不大,仅影响模型加载占用的显存
5.对比Lora推理,这种旁路参数对模型推理显存和速度影响非常小(下表未列出)
部分代码解读
加载模型
import torch
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, load_in_8bit=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
print(model.hf_device_map)
{'transformer.word_embeddings': 0,
'lm_head': 0,
'transformer.layers.0': 0,
'transformer.layers.1': 0,
'transformer.layers.2': 0,
'transformer.layers.3': 0,
'transformer.layers.4': 0,
'transformer.layers.5': 0,
'transformer.layers.6': 0,
'transformer.layers.7': 0,
'transformer.layers.8': 0,
'transformer.layers.9': 0,
'transformer.layers.10': 0,
'transformer.layers.11': 0,
'transformer.layers.12': 0,
'transformer.layers.13': 0,
'transformer.layers.14': 1,
'transformer.layers.15': 1,
'transformer.layers.16': 1,
'transformer.layers.17': 1,
'transformer.layers.18': 1,
'transformer.layers.19': 1,
'transformer.layers.20': 1,
'transformer.layers.21': 1,
'transformer.layers.22': 1,
'transformer.layers.23': 1,
'transformer.layers.24': 1,
'transformer.layers.25': 1,
'transformer.layers.26': 1,
'transformer.layers.27': 1,
'transformer.final_layernorm': 1}
device_map=auto :如果有多张卡,在加载模型时候将模型不同层自动分配到不同卡,上图是模型拆分到0,1两张卡的结果
gradient_checkpoint
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
梯度检查点的工作原理是在反向传播时重新计算深度神经网络的中间值(而通常情况是在前向传播时存储的)。这个策略是用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)
这两行代码需要一起使用
CastOutputToFloat
class CastOutputToFloat(nn.Sequential):
def forward(self, x):
return super().forward(x).to(torch.float32).to('cuda:0')
model.lm_head = CastOutputToFloat(model.lm_head)
当模型用fp16加载时,在推理阶段,如果设置do_sample=True,将选取TOP-K 个token,这时使用的torch.topk不支持fp16会报错,因此需要将最后一层输出转fp32。同时loss的计算在0卡,需将模型最后一层输出放到0卡。
RuntimeError: "topk_cpu" not implemented for 'Half'