SimMIM: a Simple Framework for Masked Image Modeling
论文名称:SimMIM: a Simple Framework for Masked Image Modeling
发表时间:CVPR2022
开源地址: 开源代码
作者及组织:Zhenda Xie, Zheng Zhang, Hu Han等,来自清华,微软亚洲研究院。
前言
本文提出一种新的自监督视觉预训练方法,是跟MAE同期工作 ,两篇论文有点儿类似,但本文较MAE额外验证MIM在swin-transformer网络上也有效。
1、方法

MIM基本成了下游感知任务的预训练标配,结合代码简单说下pipline。
1.1.数据读取
1)给定一张192*192图像,假设每个遮挡的块size=32,则这张图像能拆成192/32 * 192/32 = 36个块;
2)然后生成长度为36的全0的mask张量,此时在引入额外的参数(遮挡比例=0.6),然后随机将mask张量中的36*0.6 = 22个位置置为1;
3)siwn_t会先将图像经过一个kernel_size = stride = 4的conv,将图像变成(1,96,48,48)的张量,由于下采样4倍所以每个遮挡块大小成了32/4=8*8。
4)之后将mask中每个元素广播成(8,8)大小在和图像相乘即可,当然这里将mask区域替换成可学习张量。
class MaskGenerator:
def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
self.input_size = input_size
self.mask_patch_size = mask_patch_size
self.model_patch_size = model_patch_size # 即4中的kernel = stride = 4
self.mask_ratio = mask_ratio
assert self.input_size % self.mask_patch_size == 0
assert self.mask_patch_size % self.model_patch_size == 0
self.rand_size = self.input_size // self.mask_patch_size
self.scale = self.mask_patch_size // self.model_patch_size
self.token_count = self.rand_size ** 2
self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
def __call__(self):
mask_idx = np.random.permutation(self.token_count)[:self.mask_count]
mask = np.zeros(self.token_count, dtype=int)
mask[mask_idx] = 1
mask = mask.reshape((self.rand_size, self.rand_size))
# 广播成(48,48)的0/1块张量
mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
return mask
# 大卷积核处理图像
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
return x
class SwinTransformerForSimMIM(SwinTransformer):
def __init__(self, **kwargs):
super().__init__(**kwargs)
assert self.num_classes == 0
self.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim)) # 可学习mask_token
trunc_normal_(self.mask_token, mean=0., std=.02)
def forward(self, x, mask):
x = self.patch_embed(x)
assert mask is not None
B, L, _ = x.shape
mask_tokens = self.mask_token.expand(B, L, -1)
w = mask.flatten(1).unsqueeze(-1).type_as(mask_tokens)
x = x * (1. - w) + mask_tokens * w # 用可学习mask_token替换遮挡区域
1.2.模型
后续数据经过swin_transformer,在接一个简单decoder直接回归 被遮挡块 的RGB像素值即可。
class SimMIM(nn.Module):
def __init__(self, encoder, encoder_stride):
super().__init__()
self.encoder = encoder
self.encoder_stride = encoder_stride
# decoder
self.decoder = nn.Sequential(
nn.Conv2d(
in_channels=self.encoder.num_features,
out_channels=self.encoder_stride ** 2 * 3, kernel_size=1),
nn.PixelShuffle(self.encoder_stride),
)
self.in_chans = self.encoder.in_chans
self.patch_size = self.encoder.patch_size
def forward(self, x, mask):
z = self.encoder(x, mask)
x_rec = self.decoder(z)
# 重新插值回4倍的块大小。
mask = mask.repeat_interleave(self.patch_size, 1).repeat_interleave(self.patch_size, 2).unsqueeze(1).contiguous()
loss_recon = F.l1_loss(x, x_rec, reduction='none')
loss = (loss_recon * mask).sum() / (mask.sum() + 1e-5) / self.in_chans
return loss
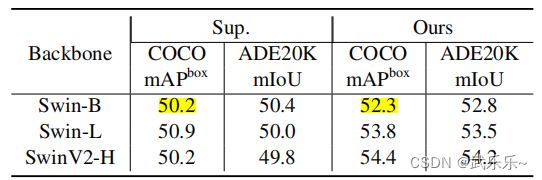
2、实验
经过预训练+微调在ImageNet1k上MIM取得83.8,但Linear probe效果很差。

对比全监督训练方法,都是高的。

下游任务效果:比全监督点高。