当我们谈上下文切换时我们在谈些什么
相信不少小伙伴面试时,都被问到过这样一个问题:进程和线程的区别是什么?大学老师会告诉我们:进程是资源分配的基本单位,线程是调度的基本单位 。说到调度,就不得不提到CPU的上下文切换了。
。说到调度,就不得不提到CPU的上下文切换了。

何为CPU上下文切换
 :“CPU上下文切换,这是个啥呢?”
:“CPU上下文切换,这是个啥呢?”
 :“唔!我来告诉你吧。。在多猫系统中,上下文切换时很常见的事情。。。饭盆的个数是有限的,一只猫一天的猫粮也是有数的。有的猫吃了一半的猫粮,要把它剩下的猫粮暂存起来,把饭盆里的猫粮切换为另一只猫的!”
:“唔!我来告诉你吧。。在多猫系统中,上下文切换时很常见的事情。。。饭盆的个数是有限的,一只猫一天的猫粮也是有数的。有的猫吃了一半的猫粮,要把它剩下的猫粮暂存起来,把饭盆里的猫粮切换为另一只猫的!”
“类似地,这个玩意放在计算机里面也是一样的!”
在多任务操作系统中,CPU需要在不同的进程或线程之间切换,以实现并发执行。每个进程或线程都有自己的上下文:CPU寄存器状态。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的存储。比如:
程序计数器(Program Counter,PC):也称为指令计数器,通常是放在CPU内部的一个特殊寄存器中的。程序计数器的主要作用是存储下一条要执行的指令的地址。当CPU执行指令时,程序计数器会更新为下一条指令的地址,确保CPU能够按顺序执行程序中的指令。
页表的起始地址:每个进程都有自己的虚拟内存,在内核中,需要通过页表来映射虚拟内存到物理内存,页表的起始地址一般存放在页表基址寄存器。
这些寄存器状态,它们所维护的环境,都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。当操作系统决定从当前执行的任务切换到另一个任务时,它需要保存当前任务的上下文,并加载新任务的上下文,这个过程就是上下文切换。
上下文切换的种类
 :“寄存器不是极快吗,怎么老是听说上下文切换开销很大?”
:“寄存器不是极快吗,怎么老是听说上下文切换开销很大?”
前面说了,CPU保存旧任务的上下文,切换新任务的上下文,然后开始执行新任务。那切换从任务角度来讲,有这么几种 :
:
进程上下文切换
众所周知,进程由内核来管理和调度,每个进程有自己的时间片,时间片耗尽,进程还没有结束,就会被内核调度出去重新排队等待,转而切换一个新的已就绪进程开始执行。这个过程就需要进行进程上下文切换。
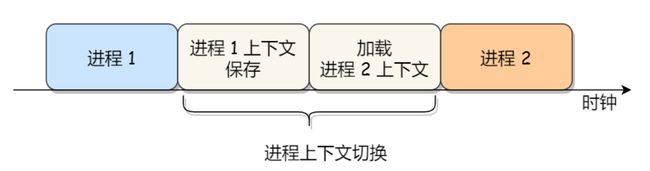
都知道,虚拟内存需要通过页表转换为物理内存,由于多级页表多次访问内存效率太低,增加了快表(TLB),大大提升了地址转换的效率。由于进程切换,新老进程的页表肯定是不一样的,这就会导致快表失效,继而新的进程要将虚拟地址转换到物理地址无法使用快表缓存。所以,进程上下文切换开销是比较大的。
线程上下文切换
大学老师提醒过我们了 :线程是调度的基本单位,而进程则是资源分配的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了进程栈等资源。同一个进程的不同线程,共享了进程ID、打开的文件描述符、根目录等等资源。
:线程是调度的基本单位,而进程则是资源分配的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了进程栈等资源。同一个进程的不同线程,共享了进程ID、打开的文件描述符、根目录等等资源。
那么理所应当的,同一个进程的不同线程间的上下文切换,开销较小,因为部分资源是共享的。当然开销还是有一定开销的,比如线程有自己的私有的线程栈、线程ID、程序计数器等资源。
至于不同进程的线程的切换,其实就是前面说的:进程上下文切换。
中断上下文切换
中断是硬件设备用来通知 CPU 需要处理某些事件的机制。当硬件设备如网络卡、硬盘、鼠标或键盘等需要 CPU 注意时,它们会发送一个中断信号。CPU 响应这个信号,并执行相应的中断服务例程(ISR)来处理事件。
如果你打开了一个文本编辑器,输入了一个字符‘a’,键盘控制器会向 CPU 发送一个中断信号。CPU 接收到中断信号后,会停止执行当前正在执行的任务,并跳转到键盘中断处理程序。键盘中断处理程序会读取键盘控制器中的数据,并根据这些数据来确定用户按下了哪个键。然后,键盘中断处理程序会将这个信息传递给用户程序,用户程序就会显示你插入了一个‘a’。

在这个过程中,中断处理打断了进程的正常调度和执行顺序,转而调用中断处理程序,响应来自键盘的设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程用户态资源的访问。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的进程栈等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等等。
上下文切换过多的问题
上下文切换虽然是操作系统设计中的必要机制,但是过多的上下文切换会导致CPU花费大量时间在任务切换上,而不是任务执行上,从而降低系统的整体性能。这种情况通常发生在以下几种情况:
- 系统中运行了过多的进程或线程。
- 高频率的IO操作导致频繁的中断。
- 锁竞争激烈,导致线程频繁地进入和退出临界区。
排查上下文切换过多的问题
当我们怀疑系统性能下降可能是由于上下文切换过多时,可以通过以下方法进行排查:
vmstat命令
vmstat用来查看关于系统的虚拟内存、进程、CPU活动以及IO统计的信息。vmstat提供了关于系统性能的即时报告,帮助管理员理解系统的内存使用情况、进程状态、系统等待队列以及磁盘IO和CPU使用情况。vmstat的输出通常包含以下几个部分:
procs(进程):
r:等待运行的进程数。
b:处于不可中断睡眠状态的进程数。
memory(内存):
swpd:虚拟内存使用量。
free:空闲内存量。
buff:用作缓冲的内存量。
cache:用作缓存的内存量。
swap(交换空间):
si:每秒从交换空间读入内存的量。
so:每秒写入交换空间的内存量。
io(输入/输出):
bi:每秒读取的块数。
bo:每秒写入的块数。
system(系统):
in:每秒中断次数,包括时钟中断。
cs:每秒上下文切换次数。
cpu(处理器):
us:用户空间占用CPU的百分比。
sy:内核空间占用CPU的百分比。
id:空闲CPU百分比。
wa:等待IO的CPU时间百分比。
st:被偷取的时间百分比(在虚拟化环境中,其他虚拟机占用的CPU时间)。
每2秒输出一次报告,共输出3次:
(ps:通过命令模拟了多线程并发场景:sysbench --threads=10 --max-time=300 threads run)
root@gl:/home/gl# vmstat 2 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 1250924 48464 600112 0 0 17 10 195 972 0 1 99 0 0
5 0 0 1250924 48464 600112 0 0 0 0 16138 743482 23 72 5 0 0
5 0 0 1250924 48464 600112 0 0 0 0 15653 737597 22 71 7 0 0vmstat第一行的输出表示的是自系统启动以来的平均负载,后面的行才表示当前间隔时间内的状态。从上面的数据可以看出来,自启动启动以来,(cs)平均上下文切换、(in)每秒中断次数都比较低。但是当前时间下,cs和in突发性的增大了好几个数量级!
前面说了,引发上下文切换过多可能的原因大致有三种:线程/进程太多、io频繁、锁频繁。接下来进一步再通过pidstat分析一下是哪种原因。
pidstat
pidstat是一个监控个别任务的性能的工具,可以用来查看特定进程的上下文切换情况。运行看下输出 :
:
root@gl:/home/gl# pidstat -wt 1
Linux 4.15.0-213-generic (gl) 01/17/2024 _x86_64_ (2 CPU)
06:49:41 AM UID TGID TID cswch/s nvcswch/s Command
06:49:42 AM 0 7 - 2.83 0.00 ksoftirqd/0
06:49:42 AM 0 - 7 2.83 0.00 |__ksoftirqd/0
06:49:42 AM 0 8 - 28.30 0.00 rcu_sched
06:49:42 AM 0 - 8 28.30 0.00 |__rcu_sched
06:49:42 AM 0 123 - 0.94 0.00 kworker/1:2
06:49:42 AM 0 - 123 0.94 0.00 |__kworker/1:2
...
06:49:42 AM 0 10180 10181 7343.40 69718.87 (sysbench)__sysbench
06:49:42 AM 0 - 10182 8820.75 60550.00 |__sysbench
06:49:42 AM 0 - 10183 7120.75 66724.53 |__sysbench
06:49:42 AM 0 - 10184 5205.66 65349.06 |__sysbench
06:49:42 AM 0 - 10185 8678.30 65187.74 |__sysbench
06:49:42 AM 0 - 10186 8339.62 66105.66 |__sysbench
06:49:42 AM 0 - 10187 6755.66 55736.79 |__sysbench
06:49:42 AM 0 - 10188 6559.43 62579.25 |__sysbench
06:49:42 AM 0 - 10189 7974.53 61872.64 |__sysbench
06:49:42 AM 0 - 10190 5702.83 64549.06 |__sysbench
06:49:42 AM 0 10192 - 0.94 0.94 pidstat
06:49:42 AM 0 - 10192 0.94 0.94 |__pidstat其中有两列可以重点关注一下:
- cswch/s,表示每秒自愿上下文切换(voluntary context switches)的次数。
- nvcswch/s,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
所谓自愿上下文切换,是指进程所需资源尚未就绪,导致的上下文切换。比如说, 内存、IO、锁等系统资源不足或者时,就会发生自愿上下文切换。而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度导致的上下文切换。比如说,大量进程都在就绪队列等待,就容易发生非自愿上下文切换。

可以看到sysbench这个程序有多个子线程,存在大量的上下文切换,尤其以非自愿上下文切换为多。此时可以合理怀疑是由于sysbench线程数太多导致cpu上下文频繁切换引起的系统卡顿。
再回到vmstat的输出,不仅(cs)切换次数高,(in)中断数也高,所以此时也不能断定就是线程数太多导致的,因为也可能是某种中断次数太多导致中断上下文切换频繁!
/proc/interrupts
/proc/interrupts 是 Linux 系统中的一个特殊文件,它提供了关于 CPU 中断的实时信息。这个文件包含了系统中每个中断请求(IRQ)的统计数据,包括每个中断的编号、类型、设备名称以及每个 CPU 上的中断计数。
 :
:
root@gl:/home/gl# cat /proc/interrupts
CPU0 CPU1
...
NMI: 0 0 Non-maskable interrupts
LOC: 293139 729565 Local timer interrupts
SPU: 0 0 Spurious interrupts
PMI: 0 0 Performance monitoring interrupts
IWI: 0 0 IRQ work interrupts
RTR: 0 0 APIC ICR read retries
RES: 2889219 2818044 Rescheduling interrupts
CAL: 7324 1630 Function call interrupts
TLB: 17 38 TLB shootdowns
TRM: 0 0 Thermal event interrupts
THR: 0 0 Threshold APIC interrupts
DFR: 0 0 Deferred Error APIC interrupts
...多输出几次就可以发现,其中增长比较明显的是Rescheduling interrupts。从字面意思也可以看出来,这个中断表示重调度中断,也就是cpu调度任务触发的中断。
 :“这下可以石锤了,还说不是你?”
:“这下可以石锤了,还说不是你?”
sysbench: