数据库结构的使用
本电脑的sqlsever
linux 编写工具

返回用rollback
数据字典:一张表放了系统的一些数据
select * from user_tables;
select * from all_users;
数据格式
number(m,n) 数值 m总长度 , n小数位置 4.125 m=4 n=3 , int = 整数
char 定长字符串 varchar2 可变长度字符串
date 、 timestamp
blob clob 存储二进制格式的
在utf-8中一个中文字符占3字节
Oracle结构
物理存储结构 : 都是由文件组成, 就是文件系统
数据文件、重做日志文件、控制文件
Desc v$logfile;
Select member from v$logfile;
V$controlfile
V$datafile;
逻辑存储结构 类似计算机外存
表空间、段、区、块
块 存储数据的最小单元, 一行数据占用一个或者多个 block
区 由多个 块组成
段 由多个 区组成
表空间 由多个 段组成
把表放到指定表空间
创建一个用户
create user student identified by "123456";
--授权
grant connect, resource to student;-- 查询数据库的表空间
select * from user_tablespaces;
在sys下创建一个表空间
create tablespace ts_user datafile '/u01/app/oracle/oradata/iweb/tb_users01.dbf' size 10m;
因为表空间都放在“/u01/app/oracle/oradata/iweb”,看是否创建成功可以在Oracle的该路径下是否有新文件
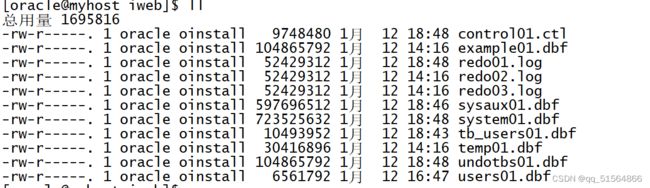
在新建的用户student下创建一个新的表放在这个表空间下
create table tb_user (id int ,name varchar2(10)) tablespace ts_user;
查看是否创建成功,可以select * from user_tables;看是否有tb_user
约束
对表中的数据限制
主键
create table s_stu(
s_id int ,
status varchar2(8),
levell varchar2(1)) tablespace ts_user;
--查找约束
select * from user_constraints;
--添加主键
alter table s_stu add constraint pk_s_id primary key(s_id);
--添加一列
alter table s_stu add age varchar(2);
--添加约束不空
alter table s_stu modify age not null;
alter table s_stu modify levell int;
--设置默认值
alter table s_stu modify status default 0;
--添加外键,s_l_id是主键,levell和s_l_id数据格式相同
create table s_level(
s_l_id int primary key,
s_l_name varchar2(10)
)tablespace ts_user;
alter table s_stu add constraint fk_s_l_id
foreign key(levell) references s_level(s_l_id);
--删除外键,会把之前关联的数据也删掉
delete from tb_level where s_l_id = 1;
--可以采用,然后再删
alter table tb_user drop constraint fk_user_level_id;
--删除约束
alter table s_stu drop constraint fk_s_l_id;
-- 检查约束 check
alter table tb_user add constraint ck_user_age check(age >0 and age <100);
-- 查看回收站
select * from tab;
-- 清空回收站
purge recyclebin;
视图
复杂查询的预查询,保存了复杂的sql语句
调用视图的时候,从视图中读取SQL语句,执行SQL语句
create view [视图名] as [复杂的sql语句];
调用视图 select * from [视图名]
索引
提高查询效率
--建立索引
create index idx_name on tb_user(name);
--查看数据字典中的索引
select * from user_idexname;
但是索引建立后插入,修改排序列,删除效率会降低,因为操作时会重排索引
oracle的索引是b-树
没索引的查询原理
-- 1. 从数据字典找到 tb_user 的表空间
-- 2. 通过 表空间 这个逻辑概率 ts_user 查到 数据文件 tb_users01.dbf tb_users02.dbf tb_users03.dbf
-- 3. 遍历 表空间 中的 block , 遍历数据文件
-- 4. block = 头文件 + 数据
使用索引查询原理
-- 1. 从数据字典找到 idx_name 的表空间 , 假设是 ts_user
-- 2. 安装 表空间 段 区 快
-- 3. 从头文件读取索引
-- 4. 数据 = 索引 + 物理地址
索引的使用原则
-- 数量小的表 不用索引
-- 经常增删的表 ,经常修改的列 不做索引
-- 经常查询的列 建立索引
-- 提高索引的搜索效率, 建立独立的索引表空间
大量的插入随机数据
可以先插入几条随机的数据,然后insert into 查询的结果
insert into tb_user values (
trunc(dbms_random.value()*10000), --随机数*10000表示0-10000,没有小数
'jack',
trunc(dbms_random.value()*100),
sysdate-trunc(dbms_random.value()*20*365),
round(dbms_random.value())
);
-- 扩容表空间 [SYS]
alter tablespace ts_user
add datafile '/u01/app/oracle/oradata/iweb/tb_users03.dbf' size 1000m;
或者利用循环
declare
begin
for x in 1..100000
loop
insert into tb_user values (
sys_guid(),
'jack',
trunc(dbms_random.value()*100),
sysdate-trunc(dbms_random.value()*20*365),
round(dbms_random.value())
);
end loop;
end;索引的分类
非唯一索引:数据能重复 。 搜索到索引后就不用继续往下搜, 因为是唯一的不需要继续检索索引,效率高
create index 索引名 on 表名(列名);
唯一索引:数据不能重复 ,搜索到索引数据后还行需要继续搜索, 搜索到非当前数据索引
create unique index 索引名 on 表名(列名);
唯一索引的效率高于非唯一索引,是否唯一索引的比非唯一索引好? 不是
插入 数据的时候 唯一索引要先遍历索引确保数据唯一性 , 而非唯一索引不需要
索引列数据不能 null
唯一约束 和 主键一定会建立唯一索引
复合索引
可以选中该句右键查看能解释计划,看用的是range scan,unique scan,full
create index 索引名 on 表名(索引列名1,索引列名2....);
这个时候查找条件只有包含索引列名1,才能利用索引查找,利用了最左前缀法则
索引失效
非肯定的结果都会使得索引失效,即是如果能在b树的第一层能找到路就可以找到用索引
select * from tb_user where name != 'jack';
select * from tb_user where name like '%A%';会索引失效
优化可以设定
select * from tb_user where name like 'AA%' or name like 'BA%';
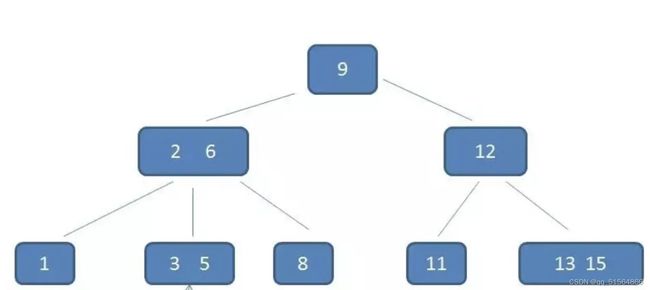 B-树
B-树
设计主键的 数据格式
id = name + guid
sys_guid():输出唯一字符串