面经-高并发和多线程
并行和并发有什么区别?
并发:多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上 来看那些任务是同时执行。
并行:单位时间内,多个处理器或多核处理器同时处理多个任务,是真正意义上 的“同时进行”。
串行:有n个任务,由一个线程按顺序执行。由于任务、方法都在一个线程执行所 以不存在线程不安全情况,也就不存在临界区的问题
线程和进程区别
定义:启动一个程序 ,比如idea是一个线程,那加载文件资源是一个线程,创建文件索引也是一个线程。
一个进程至少有一个线程,一对多,多个线程可共享数据。
根本区别:进程是cup的基本单位,而线程是处理器
**资源开销:**程序切换大开销;每个线程都有自己独立的运行栈和程序计数器(PC),线程切换开销小。
什么叫线程安全?
指某个方法在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
怎么保证多线程的运行安全?
方法一:使用安全类,比如 java.util.concurrent 下的类,使用原子类AtomicInteger
方法二:使用自动锁 synchronized。
方法三:使用手动锁 Lock。
常用的并发工具类有哪些?
- Semaphore(信号量)-允许多个线程同时访问: synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指 定多个线程同时访问某个资源。Semaphore详解
CountDownLatch(倒计时器): CountDownLatch是一个同步工具类,用 来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程 等待直到倒计时结束,再开始执行。
CyclicBarrier(循环栅栏): CyclicBarrier 和 CountDownLatch 非常类似, 它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强 大。主要应用场景和 CountDownLatch
类似。CyclicBarrier 的字面意思是可循环使
用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可
以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障
拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int
parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉 CyclicBarrier
我已经到达了屏障,然后当前线程被阻塞。
死锁与活锁的区别,死锁与饥饿的区别?
死锁
a线程占有资源,b线程也占有资源,a等待b释放资源,b等待a线程释放资源,循环等待,造成死锁。
若无外力作用,它们都将无法推进下去。
活锁
任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败。活锁有可能自行解开
Java 中导致饥饿的原因:
1、高优先级线程吞噬所有的低优先级线程的 CPU 时间。
2、线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之
前持续地对该同步块进行访问。
3、线程在等待一个本身也处于永久等待完成的对象(比如调用这个对象的 wait
方法),因为其他线程总是被持续地获得唤醒。
形成死锁的四个必要条件是什么
- 互斥条件:线程(进程)对于所分配到的资源具有排它性,即一个资源只能 被一个线程(进程)占用,直到被该线程(进程)释放 2. 请求与保持条件:一个线程(进程)因请求被占用资源而发生阻塞时,对已 获得的资源保持不放。
- 不剥夺条件:线程(进程)已获得的资源在末使用完之前不能被其他线程强 行剥夺,只有自己使用完毕后才释放资源。
4. 循环等待条件:当发生死锁时,所等待的线程(进程)必定会形成一个环路 (类似于死循环),造成永久阻塞
如何避免线程死锁
破坏请求与保持条件
一次性申请所有的资源
破坏不剥夺条件
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占 有的资源。
破坏循环等待条件
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环 等待条件。
- 尽量使用 tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),设置超时时间,超时可以退出防止死锁。
- 尽量使用 Java. util. concurrent 并发类代替自己手写锁。
- 尽量降低锁的使用粒度,尽量不要几个功能用同一把锁。
- 尽量减少同步的代码块。
TODO 讲的太抽象,待补充项目中的实践案例
说一下 runnable 和 callable 有什么区别?
主要区别
Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
线程的 run()和 start()有什么区别?
run(): 线程的
start():
调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
只运行run()并没有启动线程,会把 run 方法当成一个 main 线程下的普通方法去执 行,并不会在某个线程中执行它,。线程还是主线程。
运行start(),才算真正启动线程,多线程运行,启动线程之后会自动运行线程的主体代码run()
说说线程的生命周期及五种基本状态?
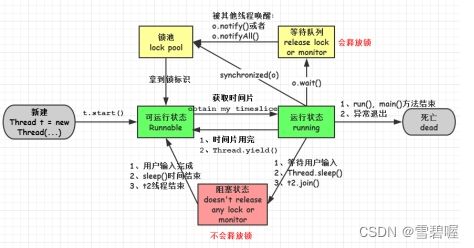
请说出与线程同步以及线程调度相关的方法
(1) wait():使一个线程处于等待(阻塞)状态,并且释放所持有的对象的 锁; (2)sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此 方法要处理 InterruptedException 异常; (3)notify():唤醒一个处于等待状态的线程,当然在调用此方法的时候,并不 能确切的唤醒某一个等待状态的线程,而是由 JVM 确定唤醒哪个线程,而且与 优先级无关; (4)notityAll():唤醒所有处于等待状态的线程,该方法并不是将对象的锁给所 有线程,而是让它们竞争,只有获得锁的线程才能进入就绪状态;
Executors类创建四种常见线程池
有OOM风险,开发中不建议使用,建议使用ThreadPoolExecutor,下面有介绍
(1)newSingleThreadExecutor 池只有 一个线程在工作 如果这个唯一的线程 因为异常结束,那么会有一个新的线程来替代它 按照任务的提交顺序执行。
(2)newFixedThreadPool 如果某个线程因为执行异常而结束,那么线程池会补充一个新线 程。
(3) newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小 超过了处理任务所需要的线程,那么就会回收部分空闲(60 秒不执行任务)的线 程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。 不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够 创建的最大线程大小。
(4)newScheduledThreadPool:大小无限的线程池。支持 定时以及周期性执行任务
线程池都有哪些状态?
RUNNING:这是最正常的状态,接受新的任务,处理等待队列中的任务。
SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的 线程。
TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()。
TERMINATED:terminated()方法结束后,线程池的状态就会变成这个
在 Java 中 Executor 和 Executors 的区别?
用Executors 创建线程池的基本用法【】
private ExecutorService executor = Executors.newFixedThreadPool(5);
Executor:执行线程任务的接口
ExecutorService:是个接口,继承了Executor,同时扩展了Executor,比如ExecutorService可以关闭线程shutdown()
Executors : 是一个创建线程池的工具类,返回值是ExecutorService
public interface Executor {
void execute(Runnable command);
}
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
public class Executors {
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
}
为什么不建议用Executors 创建线程?


你知道怎么创建线程池吗?
开发建议使用此方式
ThreadPoolExecutor()
为什么使用ThreadPoolExecutor创建线程池?
ThreadPoolExecutor是Executors 的子接口的子接口的实现类
1、可以检测线程池运行状态

下面是一个简单的 Demo。printThreadPoolStatus()会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
/**
* 打印线程池的状态
*
* @param threadPool 线程池对象
*/
public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));
scheduledExecutorService.scheduleAtFixedRate(() -> {
log.info("=========================");
log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
log.info("Active Threads: {}", threadPool.getActiveCount());
log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount());
log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
log.info("=========================");
}, 0, 1, TimeUnit.SECONDS);
}
2.可以给线程池命名,有利于定位问题

ThreadPoolExecutor重要参数分析
ThreadPoolExecutor构造函数重要参数分析
ThreadPoolExecutor3 个最重要的参数:
corePoolSize :核心线程数,线程数定义了最小可以同时运行的线程数量。
maximumPoolSize :线程池中允许存在的工作线程的最大数量
workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线 程数,如果达到的话,任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数:
- keepAliveTime:线程池中的线程数量大于 corePoolSize 的时候,如果这 时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直 到等待的时间超过了 keepAliveTime才会被回收销毁;
- unit :keepAliveTime 参数的时间单位。
- threadFactory:为线程池提供创建新线程的线程工厂
- handler :线程池任务队列超过 maxinumPoolSize 之后的拒绝策略
示例:
@Slf4j
@Configuration
@EnableAsync
public class DingTalkExecutorConfig {
/**
* 钉钉消息发送线程池
*
* @return
*/
@Bean("dingTalkExecutor")
public Executor dingTalkExecutor() {
ThreadPoolTaskExecutor executor = new MallThreadPoolTaskExecutor();
//配置核心线程数
executor.setCorePoolSize(5);
//配置最大线程数
executor.setMaxPoolSize(20);
//配置队列大小
executor.setQueueCapacity(200);
//配置线程池中的线程的名称前缀
executor.setThreadNamePrefix("DingTalk-Executor");
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//执行初始化
executor.initialize();
log.info("====================》》》钉钉消息发送线程池《《《===============");
return executor;
}
}
ThreadPoolExecutor实战中如何运用?
开发中因为业务的需要,往往会根据业务要求创建不同的线程池,比如常规线程池,用于一些日志的保存,开奖等,会线程池的核心线程数会设置大一点。
首先创建一个线程池并命名
名字自己随便取。
/**
* 用户信息查询线程池
*/
@Slf4j
@Configuration
@EnableAsync
public class CommonExecutorConfig {
/**
* 通用异步执行线程池
*
* @return
*/
@Bean(value = "commonExecutor")
public Executor commonExecutor() {
ThreadPoolTaskExecutor executor = new MallThreadPoolTaskExecutor();
//配置核心线程数
executor.setCorePoolSize(10);
//配置最大线程数
executor.setMaxPoolSize(100);
//配置队列大小
executor.setQueueCapacity(100);
//配置线程池中的线程的名称前缀
executor.setThreadNamePrefix("commonExecutor");
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//执行初始化
executor.initialize();
log.info("====================》》》通用异步执行线程池初始化完成《《《===============");
return executor;
}
}
给方法加上@Async(“commonExecutor”)注解
- 加上
@Async注解的方法会自动加入到commonExecutor线程池的任务队列里面。 - 方法一般没有返回值,因为是异步的
@Override
@Async("commonExecutor")
public void asyncSaveCustomerAwardDistributionLog(LottoServiceImpl.WinnerPrizeInfo winnerInfo,
String activityId,
String limitKey,
HashMap<String, String> rightsCodes) {
saveCustomerAwardDistributionLog(winnerInfo,
activityId,
limitKey,
rightsCodes);
}
@Override
@Async("commonExecutor")
public void asyncSaveActivityPeriodAwardLog(LottoServiceImpl.WinnerPrizeInfo winnerInfo, String activityId, String limitKey, HashMap<String, String> rightsCodes) {
saveActivityPeriodAwardLog(winnerInfo, activityId, limitKey, rightsCodes);
}
@Override
@Async("commonExecutor")
public void asyncSaveActivityPeriodAwardRemindLog(LottoServiceImpl.WinnerPrizeInfo winnerInfo, ActivityLottoEntity lottoEntity, String currentPeriod) {
saveActivityPeriodAwardRemindLog(winnerInfo, lottoEntity, currentPeriod);
}
ThreadPoolExecutor线程池使用的一些小坑
重复创建线程池的坑
线程池是可以复用的,一定不要频繁创建线程池比如一个用户请求到了就单独创建一个线程池。
@GetMapping("wrong")
public String wrong() throws InterruptedException {
// 自定义线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(5,10,1L,TimeUnit.SECONDS,new ArrayBlockingQueue<>(100),new ThreadPoolExecutor.CallerRunsPolicy());
// 处理任务
executor.execute(() -> {
// ......
}
return "OK";
}
Spring 内部线程池的坑
使用 Spring 内部线程池时,一定要手动自定义线程池,配置合理的参数,不然会出现生产问题(一个请求创建一个线程)。
@Configuration
@EnableAsync
public class ThreadPoolExecutorConfig {
@Bean(name="threadPoolExecutor")
public Executor threadPoolExecutor(){
ThreadPoolTaskExecutor threadPoolExecutor = new ThreadPoolTaskExecutor();
int processNum = Runtime.getRuntime().availableProcessors(); // 返回可用处理器的Java虚拟机的数量
int corePoolSize = (int) (processNum / (1 - 0.2));
int maxPoolSize = (int) (processNum / (1 - 0.5));
threadPoolExecutor.setCorePoolSize(corePoolSize); // 核心池大小
threadPoolExecutor.setMaxPoolSize(maxPoolSize); // 最大线程数
threadPoolExecutor.setQueueCapacity(maxPoolSize * 1000); // 队列程度
threadPoolExecutor.setThreadPriority(Thread.MAX_PRIORITY);
threadPoolExecutor.setDaemon(false);
threadPoolExecutor.setKeepAliveSeconds(300);// 线程空闲时间
threadPoolExecutor.setThreadNamePrefix("test-Executor-"); // 线程名字前缀
return threadPoolExecutor;
}
}
synchronized 的作用?
- 控制线程同步,控制 synchronized 代码段不被多个线程同时执行
- 可以修饰类、方法、变量。
synchronized最主要的三种使用方式
**修饰实例方法:**作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
**修饰静态方法:**也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员。
所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的 锁是当前类的锁,而访问非静态synchronized 方法占用的锁是当前实例对象锁。
自己的理解:b线程锁住了类的静态方法mathod1,那a线程不能访问这个线程方法了,但是a还可以访问类的非静态方法,因为静态方法还没上锁。
如果synchronized 修饰的类,b锁的是整个类,那这个类下所有对象实例都不能访问,这个时候a才不能访问当前的实例对象
修饰代码块: 对给定对象加锁,进入同步代码库前要获得给定对象的锁。
总结: synchronized 关键字加到 static 静态方法和 synchronized(class)代码
块上都是是给 Class 类上锁。synchronized 关键字加到实例方法上是给对象实
例上锁。尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有
缓存功能
synchronized 锁升级的原理是什么?
锁升级过程的四种锁状态
- 无锁:synchronized修饰的对象,新创建的锁是无锁状态。
- 偏向锁:上次来的是你,我就会记住你的名字,如果下次还是你,我就直接把资源给你,走CAS(对比并修改)的操作。
- 轻量级锁:也叫乐观锁,自旋锁,用的CAS
- 重量级锁 也叫悲观锁。一开始就锁死资源,线程会阻塞,直到别的线程释放资源,才会重新唤醒线程,线程停止和唤醒需要cpu调度。
锁升级过程
在锁对象的对象头里面有一个 threadid 字段,在第
一次访问的时候 threadid 为空,jvm 让其持有偏向锁,并将 threadid 设置为其
线程 id,再次进入的时候会先判断 threadid 是否与其线程 id 一致,如果一致则
可以直接使用此对象,如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一
定次数来获取锁,执行一定次数之后,如果还没有正常获取到要使用的对象,此
时就会把锁从轻量级升级为重量级锁,此过程就构成了 synchronized 锁的升
级。
锁的升级的目的
减低了锁带来的性能消耗。
降低性能消耗的原理
1。如果没有锁升级过程,一开始就直接用重量级锁,那线程很容易阻塞,线程唤醒需要cpu调度,浪费资源。
这个时候我用一个轻量级锁,很多情况我自旋转一会可能资源就空闲出来了,这样就可以减少线程阻塞的次数,cpu也可以少唤醒几次线程,这样资源就节省了嘛。
2. TODO 待补充
什么是 CAS?
CAS 是 compare and swap 的缩写,比较交换。
cas 是乐观锁。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和 A 的值是一样的,那么就将内存里面的值更新成 B。CAS是通过无限循环来获取数据的,如果在第一轮循环中,a 线程获取地址里面的值被b 线程修改了,那么 a 线程需要自旋,一直循环比较的动作,直到比较的值一样,才进行交换的动作。
CAS 的会产生什么问题?
1、ABA 问题
线程1拿到变量A=1,线程2也拿到A,此时A=1。线程1把A 变成2,再把A变成1,线程1结束。线程2执行结束,对比一下A ,发现A 还是1 ,觉得A没动过,就把A赋值成2。其实A在赋值的时候A已经被B动过了。
2、循环时间长开销大:
synchronized 和 ReentrantLock 区别是什么?
- synchronized 是关键字,ReentrantLock 是个类,jAPI
- ReentrantLock 使用起来比较灵活,但是必须有释放锁的配合动作;
- ReentrantLock 必须手动获取与释放锁,而 synchronized 不需要手动释放和开启锁;
- ReentrantLock 只适用于代码块锁,而 synchronized 可以修饰类、方法、变量
等。 - ReentrantLock 底层调用的是 Unsafe 的park
方法加锁,synchronized 操作的应该是对象头中 mark word - synchronized 有锁升级,ReentrantLock 没有
synchronized在项目中的运用
场景一
生成唯一Pos凭证需要获取时间戳,为了防止时间戳重复,会用synchronized 修饰方法。
/**
* Pos凭证工具类
*
* @author
*/
@Slf4j
public class PosTicketUtils {
// 62进制
private static final String[] RADIX_ARR = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ".split("");
// 进制数
private static final int RADIX_INT = RADIX_ARR.length;
private static final BigInteger RADIX = new BigInteger(String.valueOf(RADIX_INT));
// 起始毫秒数,减少位数
private static final Long START_MILLS = DateUtil.parseDate("2019-01-01").getTime();
// 最后生成的毫秒数
private static Long lastMills;
// 序列,防止同一秒重复
private static AtomicInteger seq = new AtomicInteger(0);
// 序列位数
private static final int MAX_SEQ_LENGTH = 2;
// 最大序列数
private static final int MAX_SEQ = (int) Math.pow(RADIX_ARR.length, MAX_SEQ_LENGTH);
// 随机字符
private static final Random random = new Random(System.currentTimeMillis());
private PosTicketUtils() {
}
/**
* 随机创建唯一凭证
*
* @return
*/
public static synchronized String createTicket() {
long currentMills = System.currentTimeMillis();
// long currentMills = DateUtil.parseDate("2040-12-31").getTime();
// 减少的天数,用于加大随机范围
int subDays = new Random().nextInt(RADIX.intValue());
// 2位序列,即每毫秒支持生成100个
if (lastMills == null || lastMills != currentMills) {
seq.set(0);
}
lastMills = currentMills;
int intSeq = seq.incrementAndGet();
if (intSeq >= MAX_SEQ) {
throw new RuntimeException("超过每毫秒请求数,请加大序列位数");
}
long mills = currentMills - START_MILLS - subDays * DateUtil.MILLIS_PER_DAY;
String millsRadix = toRadix62(mills);
String seqRadix = StringUtils.leftPad(toRadix62(intSeq), MAX_SEQ_LENGTH, '0');
StringBuilder ret = new StringBuilder();
ret.append(toRadix62(subDays));
ret.append(millsRadix);
ret.append(seqRadix);
// 1位加密随机码
ret.append(RADIX_ARR[random.nextInt(RADIX_INT)]);
// 反转
return org.apache.commons.lang3.StringUtils.reverse(ret.toString());
}
public static void main(String[] args) throws InterruptedException {
long d1 = System.currentTimeMillis();
Set<String> repeatSet = new HashSet<>();
Set<String> set = new HashSet<>();
for (int j = 0; j < 1; j++) {
for (int i = 0; i < 3000; i++) {
String ticket = PosTicketUtils.createTicket();
if (set.contains(ticket)) {
repeatSet.add(ticket);
System.out.println("重复 :" + ticket);
break;
}
set.add(ticket);
System.out.println(ticket);
}
System.out.println(j);
Thread.sleep(1000);
}
// for (int i = 1000000; i < 1000000; i++) {
// toRadix62(i);
// System.out.println(i + " = " + toRadix62(i));
// }
long d2 = System.currentTimeMillis();
System.out.println("用时" + (d2 - d1) + "毫秒");
System.out.println(repeatSet.size());
}
/**
* 62进制
*
* @param number
* @return
*/
private static String toRadix62(long number) {
if (number < 0) {
throw new RuntimeException("not support number = " + number);
}
if (number == 0) {
return "0";
}
StringBuilder ret = new StringBuilder();
BigInteger num = new BigInteger(String.valueOf(number));
while (num.longValue() != 0) {
ret.append(RADIX_ARR[num.mod(RADIX).intValue()]);
num = num.divide(RADIX);
}
return ret.reverse().toString();
}
}
场景二
会员开卡入会之后,需要记录会员的入会记录,首次入会记录和再次入会记录等操作。为了实现解耦和接口反应速度,会发送会员入会的mq消息,在消费端这边进行保存记录等操作。消费时开启多线程处理消息,加synchronized 修饰方法,防止一个入会用户记录多次入会记录。
@Slf4j
@Service
public class PromotionServiceImpl {
@Autowired
private PromotionServiceImpl self;
public void updatePromotionRegisterState(PromotionVisitVo promotionVisitVo) {
new Thread(new UpdatePromotionPageRegisterTask(promotionVisitVo)).start();
}
public class UpdatePromotionPageRegisterTask implements Runnable {
private PromotionVisitVo promotionVisitVo;
public UpdatePromotionPageRegisterTask(PromotionVisitVo promotionVisitVo) {
this.promotionVisitVo = promotionVisitVo;
}
@Override
public void run() {
self.updatePromotionPageRegisterState(promotionVisitVo);
}
}
@Transactional(rollbackFor = SqlErrorException.class)
public synchronized void updatePromotionPageRegisterState(PromotionVisitVo promotionVisitVo) {
String nascentId = promotionVisitVo.getNascentId();
Long promotionPageId = promotionVisitVo.getPromotionPageId();
//查询用户是否通过渠道推广注册,如已经注册,则不进行处理
WmPromotionVisitLogDO wmPromotionVisitLog = WmPromotionVisitLogDao.dao()
.findIfRegisterByNascentId(nascentId, promotionPageId, promotionVisitVo.getShopId());
if (null != wmPromotionVisitLog) {
log.info("查询已经注册过,渠道推广id【{}】,用户nascentId【{}】",
promotionPageId, nascentId);
return;
}
log.info("查询还未注册过,渠道推广id【{}】,用户nascentId【{}】",
promotionPageId, nascentId);
WmPromotionVisitLogDO firstVisitLog = WmPromotionVisitLogDao.dao()
.findFirstVisitTime(nascentId, promotionPageId, promotionVisitVo.getShopId());
if (null != firstVisitLog) {
log.info("【新用户从推广链接注册】首次注册时间:" + firstVisitLog.getFirstpromotionTime());
if (DateUtils.addHours(firstVisitLog.getFirstpromotionTime(), 24).after(DateUtil.now())) {
log.info("【新用户从推广链接注册】没有超过24小时,直接更新:visitLogId = " + firstVisitLog.getId());
//没有超过 则该用户为推广链接进来产生注册用户
firstVisitLog.setCustomerId(promotionVisitVo.getCustomerId());
firstVisitLog.setShopId(promotionVisitVo.getShopId());
firstVisitLog.setWxNickName(promotionVisitVo.getWxName());
firstVisitLog.setCustomerMobile(promotionVisitVo.getMobile());
firstVisitLog.setNascentId(nascentId);
firstVisitLog.setGroupId(promotionVisitVo.getGroupId());
firstVisitLog.setMallId(promotionVisitVo.getMallId());
firstVisitLog.setIsRegister(1);
firstVisitLog.setRegisterTime(new Date());
firstVisitLog.update();
//累加详情统计表的是否注册人数
statisticsUpdate(promotionPageId);
} else {
log.info("【新用户从推广链接注册】超过24小时,直接更新:visitLogId = " + firstVisitLog.getLong("id"));
firstVisitLog.setWxNickName(promotionVisitVo.getWxName());
firstVisitLog.setCustomerMobile(promotionVisitVo.getMobile());
firstVisitLog.setNascentId(nascentId);
firstVisitLog.setGroupId(promotionVisitVo.getGroupId());
firstVisitLog.setMallId(promotionVisitVo.getMallId());
firstVisitLog.update();
}
//更新客户通过渠道推广进来的其他记录,20210521根据产品需求更改
updatePromotionCustomerInfoVisitorLog(nascentId, promotionPageId,
promotionVisitVo.getMobile(), promotionVisitVo.getWxName());
} else {
WmPromotionVisitLogDO visitLog = new WmPromotionVisitLogDO();
visitLog.setPromotionId(promotionPageId);
visitLog.setVisitDate(new Date());
visitLog.setCustomerId(promotionVisitVo.getCustomerId());
visitLog.setWxNickName(promotionVisitVo.getWxName());
visitLog.setCustomerMobile(promotionVisitVo.getMobile());
visitLog.setCustomerOpenid(promotionVisitVo.getOpenId());
visitLog.setNascentId(nascentId);
visitLog.setShopId(promotionVisitVo.getShopId());
visitLog.setPromotionCountNum(1);
visitLog.setIsFirstpromotion(0);
visitLog.setFirstpromotionTime(new Date());
visitLog.setIsRegister(1);
visitLog.setRegisterTime(new Date());
visitLog.setState(1);
visitLog.setGroupId(promotionVisitVo.getGroupId());
visitLog.setMallId(promotionVisitVo.getMallId());
log.info("新增visitLog记录:{}",visitLog);
visitLog.save();
statisticsUpdate(promotionPageId);
}
}
/**
* 更新统计数据,先查询详情统计表今天有没有数据 有:直接累加 没有则新增
*
* @param promotionPageId
*/
private void statisticsUpdate(Long promotionPageId) {
WmPromotionDetailStatisticsDO detailStatistics = WmPromotionDetailStatisticsDao
.dao().findOneDetailStatisticByPromotionPageId(promotionPageId);
if (null != detailStatistics
&& DateUtil.formatDate(new Date())
.equals(DateUtil.formatDate(detailStatistics.getDate("date")))) {
Long registNum = detailStatistics.getRegistNum() != null ? detailStatistics.getRegistNum() : 0;
detailStatistics.setRegistNum(registNum + 1);
detailStatistics.update();
} else {
WmPromotionDetailStatisticsDO statistics = new WmPromotionDetailStatisticsDO();
statistics.setPromotionId(promotionPageId);
statistics.setDate(new Date());
statistics.setVisitUserNum(1L);
statistics.setVisitCountNum(1L);
statistics.setFirstVisitUserNum(0L);
statistics.setRegistNum(1L);
statistics.save();
}
}
/**
* 更新渠道推广其他日志没有客户昵称的数据
*
* @param nascentId
* @param promotionPageId
*/
private void updatePromotionCustomerInfoVisitorLog(String nascentId,
Long promotionPageId,
String mobile, String wxName) {
List<WmPromotionVisitLogDO> wmPromotionVisits = WmPromotionVisitLogDao.dao()
.findNoWxNameByPromotionPageIdAndNascentId(nascentId, promotionPageId);
if (CollectionUtils.isNotEmpty(wmPromotionVisits)) {
wmPromotionVisits.forEach(wmPromotionVisit -> {
wmPromotionVisit.setCustomerMobile(mobile);
wmPromotionVisit.setWxNickName(wxName);
});
WmWechatFollowerDao.dao().batchUpdate(wmPromotionVisits);
}
}
}
ReentrantLock 在项目中的运用?
fileName = sheetName + “_” + DateUtil.formatDate(DateUtil.YYYYMMDDHHMMSS); 文件名一般会拼接日期时间,当用户连续点击按钮,或者其他情况,导致同一秒进入两个导出文件的请求,会造成文件名重复。
public class ExcelProcess {
/**
* 锁
*/
private final static ReentrantLock LOCK = new ReentrantLock();
private final static Logger LOGGER = LoggerFactory.getLogger(ExcelProcess.class);
private ExcelProcess() {
}
/**
* 将内容写入excel文件
*
* @param sheetName excel脚本名称
* @param headNames 头部
* @param columns 列元数据名称(对应的数据库字段)
* @param excelConfigFactory 数据来源
* @return excel文件
*/
public static File write(String sheetName, Object[] headNames, String[] columns, ExcelConfigFactory excelConfigFactory) {
String fileName;
// 防止文件名冲突
LOCK.lock();
try {
fileName = sheetName + "_" + DateUtil.formatDate(DateUtil.YYYYMMDDHHMMSS);
} finally {
LOCK.unlock();
}
File file = new File(Constants.TEMP_FILE_PATH + "/" + fileName + ".xls");
try (FileOutputStream outputStream = new FileOutputStream(file)) {
write(outputStream, sheetName, headNames, columns, excelConfigFactory);
} catch (Exception e) {
throw new WmBaseRuntimeException(e);
}
// jvm退出时删除临时文件
file.deleteOnExit();
return file;
}
/**
* 将内容写入excel文件
*
* @param outputStream 输出流
* @param sheetName excel脚本名称
* @param headNames 头部
* @param columns 列元数据名称(对应的数据库字段)
* @param excelConfigFactory 数据来源
*/
public static <T> void write(OutputStream outputStream, String sheetName, Object[] headNames, String[] columns, ExcelConfigFactory excelConfigFactory) {
Assert.notNull(headNames, "excel头行不允许为null");
Assert.notNull(columns, "excel列元数据名称不允许为null");
Assert.notNull(excelConfigFactory, "excel配置实例不能为null");
HSSFWorkbook wb = new HSSFWorkbook();
// 写入头行
HSSFSheet sheet = createSheet(headNames, wb, sheetName);
// 从0开始,
List<HSSFSheet> sheets = new ArrayList<>();
sheets.add(sheet);
int row = 0;
List<T> contents;
while (true) {
contents = excelConfigFactory.getData();
if (CollectionUtils.isEmpty(contents)) {
break;
}
for (T t : contents) {
// 分批次写入excel
HSSFRow hssfRow = sheet.createRow(++row);
if (t instanceof Record) {
writeColumns((Record) t, columns, hssfRow, null);
}
if (row >= 65535) {
// 如果行数大于65535行则重新创建一个表
sheet = createSheet(headNames, wb, sheetName);
row = 0;
sheets.add(sheet);
}
}
}
excelConfigFactory.afterContentWritten(sheets.toArray(new HSSFSheet[0]));
try {
wb.write(outputStream);
} catch (Exception e) {
LOGGER.error("数据写入excel文件出错", e);
}
}
/**
* 创建sheet并写入列名行
*
* @param headNames 列表数组
* @param wb excel
* @param sheetName 表名
* @return 表
*/
private static HSSFSheet createSheet(Object[] headNames, HSSFWorkbook wb, String sheetName) {
HSSFSheet sheet = wb.createSheet(sheetName);
sheet.setDefaultColumnWidth(20);
// 写入头部信息
HSSFRow firstRow = sheet.createRow(0);
HSSFCellStyle style = wb.createCellStyle();
style.setAlignment(HorizontalAlignment.CENTER);
HSSFFont font = wb.createFont();
font.setBold(true);
style.setFont(font);
writeColumns(headNames, firstRow, style);
return sheet;
}
/**
* 写入行数据
*
* @param contents 数据
* @param row 行对象
* @param style 行样式
*/
private static void writeColumns(Object[] contents, HSSFRow row, HSSFCellStyle style) {
int i = -1;
// 写入内容
for (Object object : contents) {
Cell cell = row.createCell(++i);
cell.setCellValue(object.toString());
if (style != null) {
cell.setCellStyle(style);
}
}
}
/**
* 写入行数据
*
* @param columns 列名
* @param row 行对象
* @param style 行样式
*/
private static void writeColumns(Record record, String[] columns, HSSFRow row, HSSFCellStyle style) {
int i = -1;
for (String column : columns) {
Object value = record.get(column);
Cell cell = row.createCell(++i);
try {
// 反射取值
cell.setCellValue(value == null ? null : value.toString());
} catch (Exception e) {
continue;
}
if (style != null) {
cell.setCellStyle(style);
}
}
}
}